文章目录
- 前言
- 一、安装
- 二、时间序列格式
- 2.1 格式化时间序列
- 2.2 读取标准数据集
- 三、机器学习算法
- 3.1 分类
- 3.2 回归
- 3.3 最近邻搜索
- 3.4 聚类
前言
tslearn快速入门学习。官网:tslearn quick-start
一、安装
采用pip install安装tslearn库
pip install tslearn
二、时间序列格式
2.1 格式化时间序列
通过to_time_series函数对一个时间序列列表进行格式化。
from tslearn.utils import to_time_series
#to_time_series格式化时间序列
time_series=[3,4,2,1]
format_time_series=to_time_series(time_series)
print(format_time_series)
print(format_time_series.shape)
若存在多个时间序列,可以通过to_time_series_dataset将多个时间序列格式化为一个数据集。若多个时间序列的时间长度不相同(例如:一个时间序列长度为5,一个时间序列长度为4,则自动填充长度为4的时间序列NAN将其长度扩充为5)
from tslearn.utils import to_time_series_dataset
first_time_series=[4,6,3,2,1]
second_time_series=[3,5,7,2]
time_series_dataset=to_time_series_dataset([first_time_series,second_time_series])
time_series_dataset

2.2 读取标准数据集
第一种:官方自带数据集
#读取标准数据集
from tslearn.datasets import UCR_UEA_datasets
X_train, y_train, X_test, y_test = UCR_UEA_datasets().load_dataset("TwoPatterns")
print(X_train.shape)
第二种:通过txt文件导入时间序列数据集
txt存储时间序列数据的格式如下:
- 每一行表示一组时间序列
- 每一组时间序列的不同特征通过|进行分割
- 每一组时间序列的每一种特征之间的数据通过空格分割
#读取txt文件时间序列
from tslearn.utils import save_time_series_txt, load_time_series_txt
"""
文件内容:
1.0 0.0 2.5|3.0 2.0 1.0
1.0 2.0|4.333 2.12
"""
#加载数据
time_series_dataset = load_time_series_txt(r"C:\Users\Dell\Desktop\test.txt")
#保存数据为txt
save_time_series_txt("path/to/another/file.txt", time_series_dataset)

三、机器学习算法
3.1 分类
作用:将时间序列按照标签进行分类
采用函数:
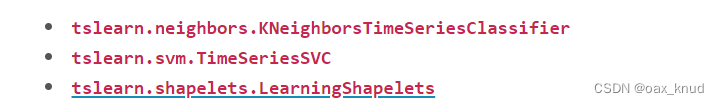
from tslearn.utils import to_time_series_dataset
#时间序列
X = to_time_series_dataset([[1, 2, 3, 4], [1, 2, 3], [2, 5, 6, 7, 8, 9]])
#标签
y = [0, 0, 1]
#KNN分类
from tslearn.neighbors import KNeighborsTimeSeriesClassifier
knn = KNeighborsTimeSeriesClassifier(n_neighbors=2)
knn=knn.fit(X, y)
#预测位置时间序列类别
knn.predict([1,2,3,4,5])
#SVM分类
from tslearn.svm import TimeSeriesSVC
clf = TimeSeriesSVC(C=1.0, kernel="gak")
clf.fit(X, y)
#Shapelets分类
from tslearn.shapelets import LearningShapelets
clf = LearningShapelets(n_shapelets_per_size={3: 1})
clf.fit(X, y)
3.2 回归
特定于时间序列的支持向量回归器:tslearn.svm.TimeSeriesSVR
from tslearn.svm import TimeSeriesSVR
clf = TimeSeriesSVR(C=1.0, kernel="gak")
y_reg = [1.3, 5.2, -12.2]
clf.fit(X, y_reg)
3.3 最近邻搜索
查找距离某一个时间序列最相近的时间序列:tslearn.neighbors.KNeighborsTimeSeries
from tslearn.neighbors import KNeighborsTimeSeries
knn = KNeighborsTimeSeries(n_neighbors=2)
knn.fit(X)
knn.kneighbors() # Search for neighbors using series from `X` as queries
knn.kneighbors(X2) # Search for neighbors using series from `X2` as queries
3.4 聚类

from tslearn.clustering import KernelKMeans
gak_km = KernelKMeans(n_clusters=2, kernel="gak")
labels_gak = gak_km.fit_predict(X)
from tslearn.clustering import TimeSeriesKMeans
km = TimeSeriesKMeans(n_clusters=2, metric="dtw")
labels = km.fit_predict(X)
km_bis = TimeSeriesKMeans(n_clusters=2, metric="softdtw")
labels_bis = km_bis.fit_predict(X)
from tslearn.clustering import TimeSeriesKMeans, silhouette_score
km = TimeSeriesKMeans(n_clusters=2, metric="dtw")
labels = km.fit_predict(X)
silhouette_score(X, labels, metric="dtw")