RANKX这个函数,白茶之前已经写过很多期了,本期是对RANKX函数一个细节问题的补充。
我们常见的数据类型有很多,用来聚合的主要有三种数据类型:文本、整数、小数。
在大部分场合,小数是实际FACT数据中最为常见的数据类型,当小数与RANKX函数组合的时候,会产生意想不到的小问题。
案例数据:
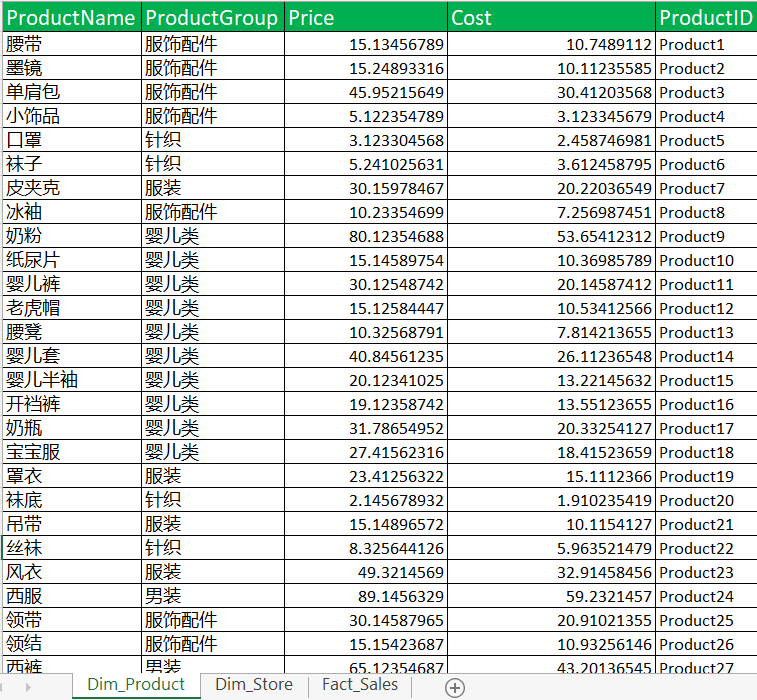
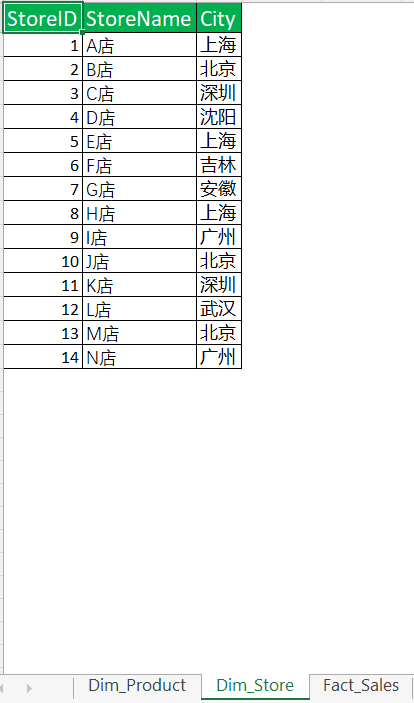
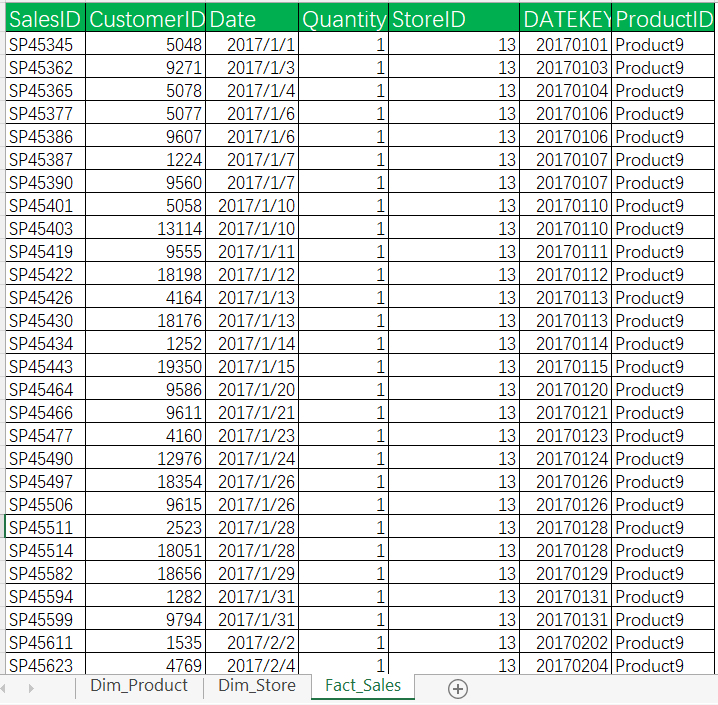
案例数据比较简单,分别是产品表、分店表、销售事实表。
细心的小伙伴可能已经发现了,产品表中的价格和成本并不是整数,而是位数较多的小数。
将其导入到PowerBI中模型如下:

构建基础指标:
1.销售金额:
001.SalesAmount =
SUMX ( 'Fact_Sales', 'Fact_Sales'[Quantity] * RELATED ( Dim_Product[Price] ) )
2.销售成本:
002.SalesCost =
SUMX ( 'Fact_Sales', 'Fact_Sales'[Quantity] * RELATED ( Dim_Product[Cost] ) )
3.销售毛利:
003.SalesProfit =
[001.SalesAmount] - [002.SalesCost]
4.在分店表维度下,进行排名:
004.ProfitRankx =
IF (
HASONEFILTER ( Dim_Store[City] ),
RANKX ( ALLSELECTED ( 'Dim_Store' ), [003.SalesProfit] )
)
展示效果如下:
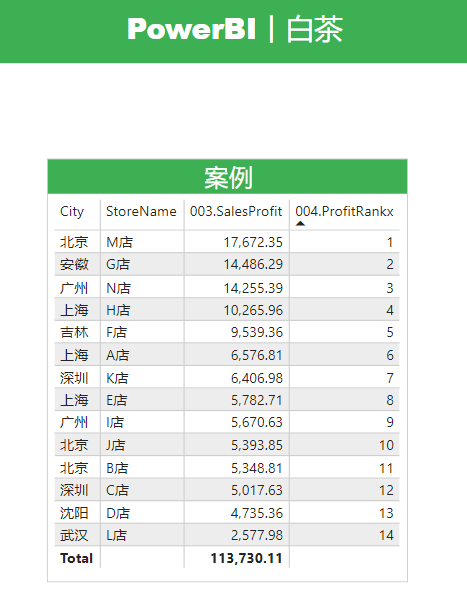
看到这里小伙伴会说,这不是挺正常的嘛,没看出来哪里不对啊。
别急,我们添加一个切片器,来查看一下筛选的效果。
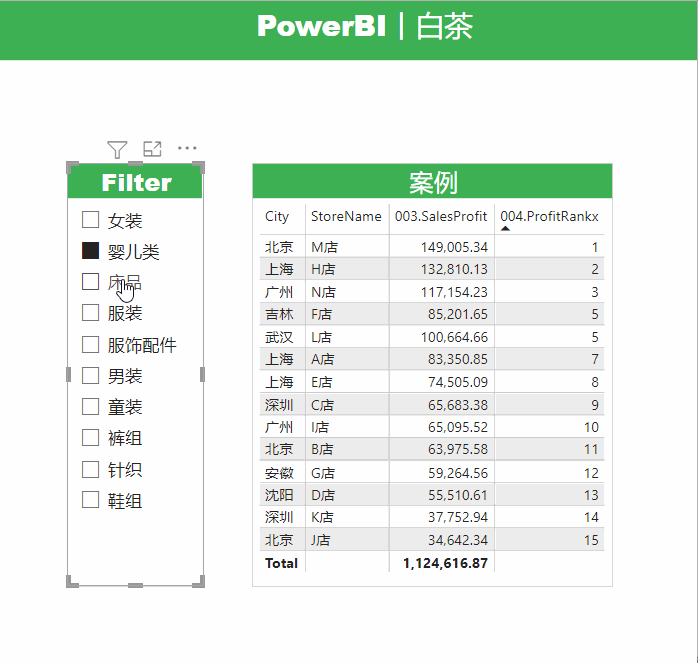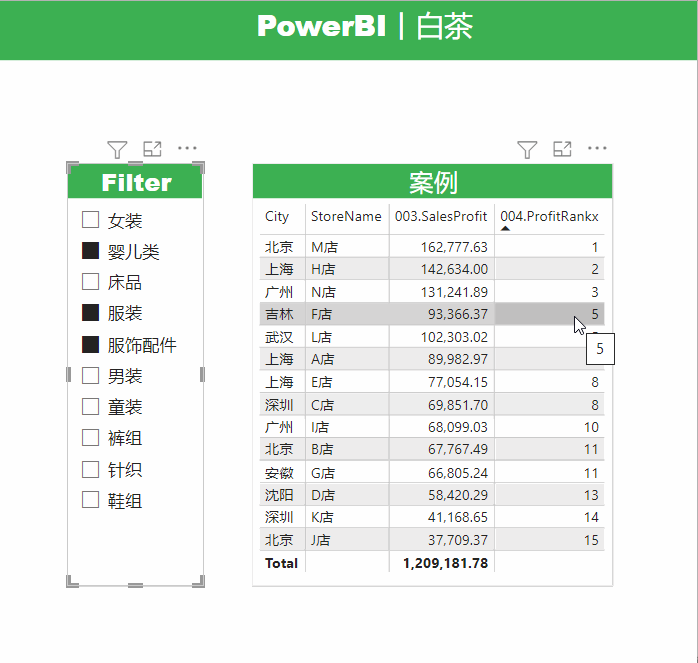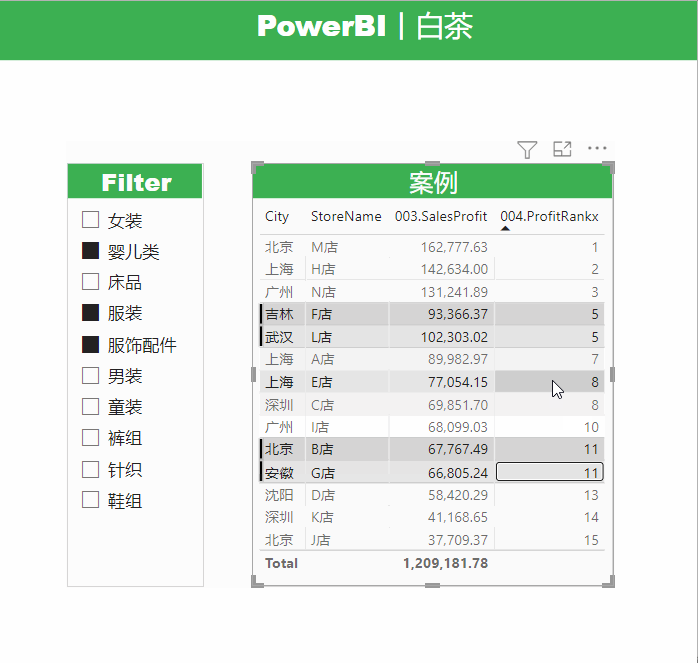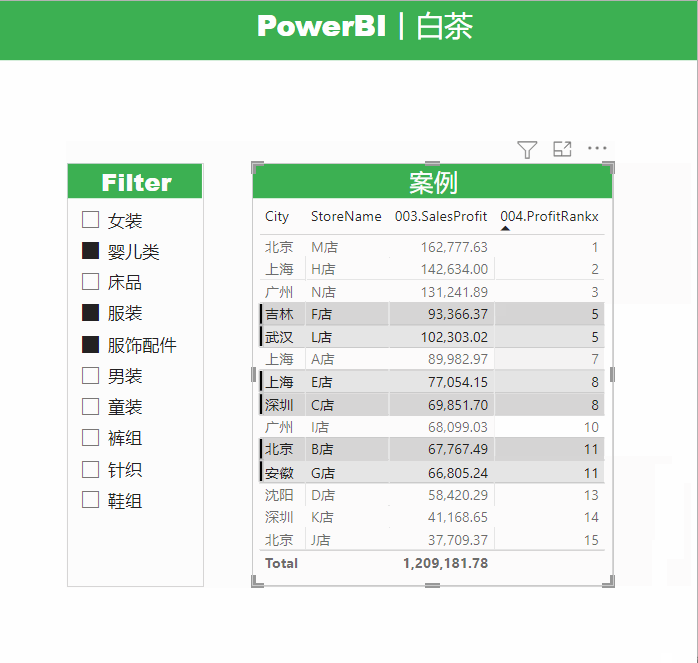
问题描述:
这里有一个很明显的问题,就是白茶RANKX函数内部使用的是ALLSELECTED函数,那么我们得到的排名结果应该是相对排名。
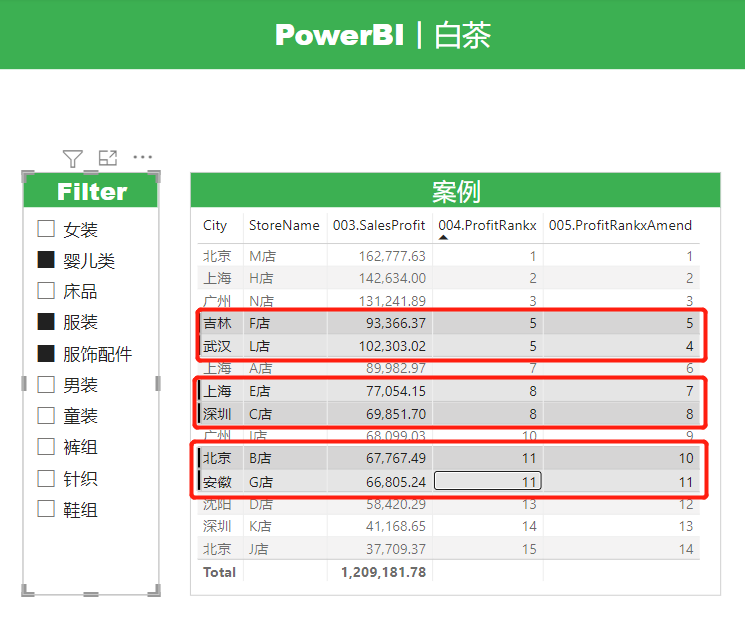
不添加切片器筛选的时候,总体排名和绝对排名是一样的,看起来没什么问题,但是一旦我们添加了切片器筛选,就会明显的看到,两个数值不同的度量值排名居然是一样的。
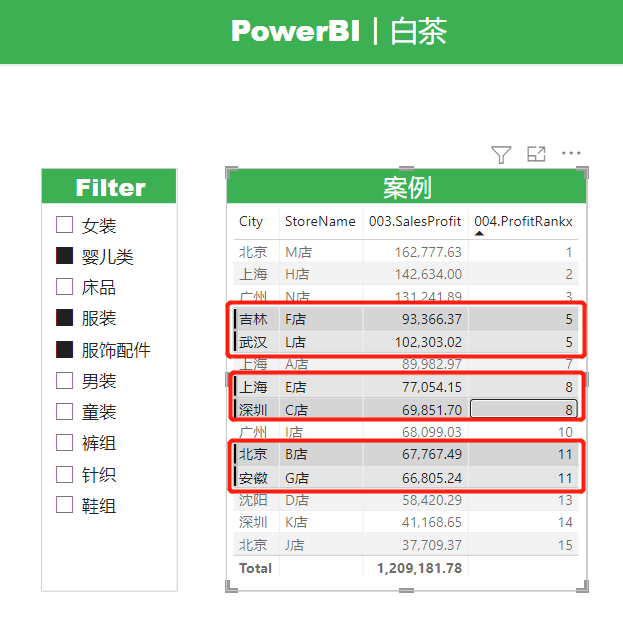
这个问题产生的原因在于,我们计算依据的物理列价格和成本是包含小数的,多组小数格式数据计算会产生浮点数据,因此在底层逻辑转化过程中会造成数据的精度丢失。
因此解决办法有两种:
1.数据进入到PowerQuery中时,我们进行数据截断;
2.在计算结果上进行数据截断。
白茶推荐大家使用第二种方式,毕竟在PowerQuery中修改数据格式再进行数据UAT测试的时候,是很容易造成上下游数据偏差的。
修改RANKX度量值如下:
005.ProfitRankxAmend =
IF (
HASONEFILTER ( Dim_Store[City] ),
RANKX ( ALLSELECTED ( 'Dim_Store' ), ROUND ( [003.SalesProfit], 2 ) )
)
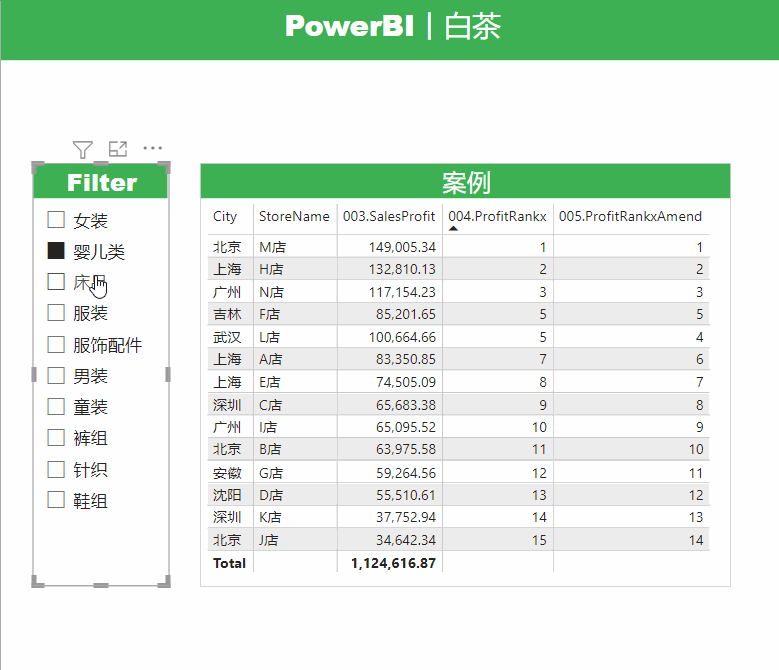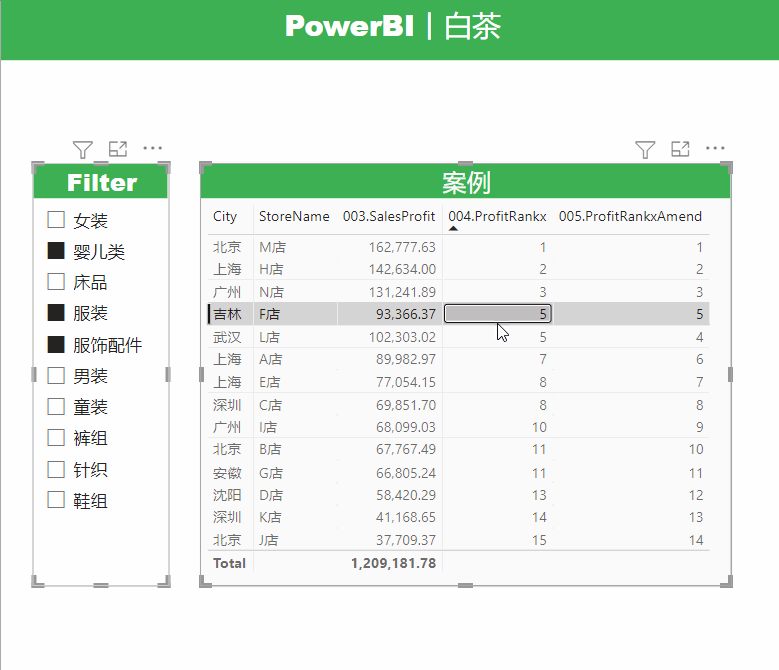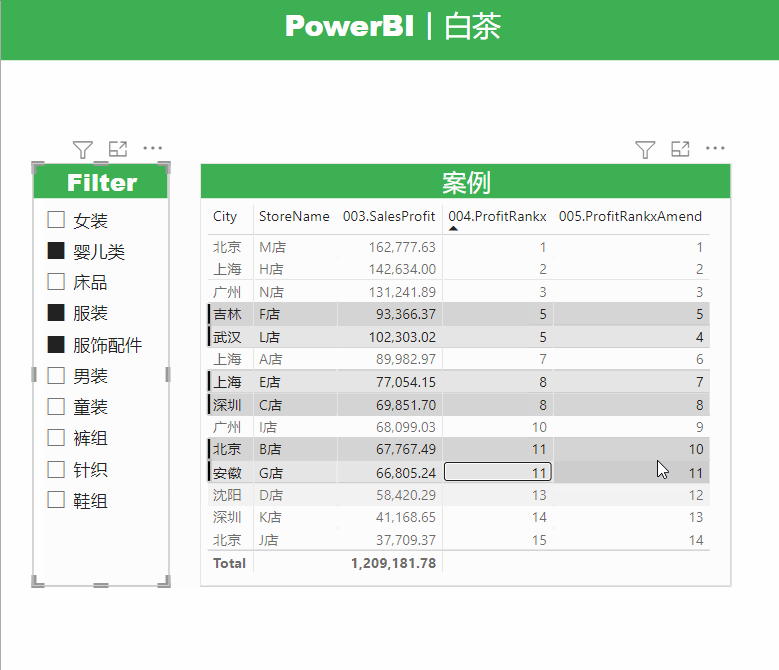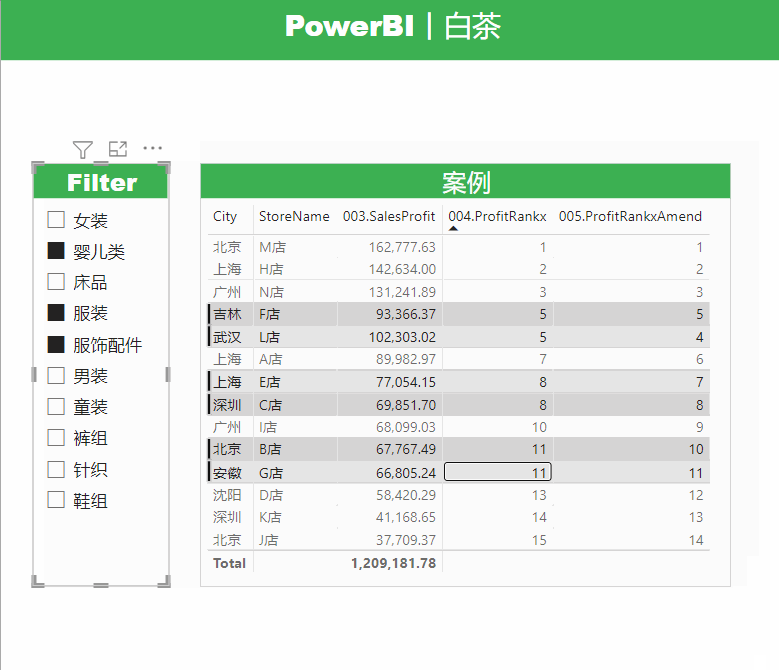
展示效果如下:


这里是白茶,一个PowerBI的初学者。

![[1180]clickhouse查看数据库和表的容量大小](https://img-blog.csdnimg.cn/img_convert/56b53a32fe40a2a8bdc8f293ee985b83.png)
![[附源码]Python计算机毕业设计SSM基于健身房管理系统(程序+LW)](https://img-blog.csdnimg.cn/1135b2990be1437db0cbb7f10e7ee178.png)








![[附源码]JAVA毕业设计小说阅读网站(系统+LW)](https://img-blog.csdnimg.cn/051397adba5d4a5a9be3ce0a8d91ec47.png)

