- 尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】
- 视频地址:尚硅谷大数据Flink1.17实战教程从入门到精通_哔哩哔哩_bilibili
- 尚硅谷大数据Flink1.17实战教程-笔记01【Flink概述、Flink快速上手】
- 尚硅谷大数据Flink1.17实战教程-笔记02【Flink部署】
- 尚硅谷大数据Flink1.17实战教程-笔记03【Flink运行时架构】
- 尚硅谷大数据Flink1.17实战教程-笔记04【】
- 尚硅谷大数据Flink1.17实战教程-笔记05【】
- 尚硅谷大数据Flink1.17实战教程-笔记06【】
- 尚硅谷大数据Flink1.17实战教程-笔记07【】
- 尚硅谷大数据Flink1.17实战教程-笔记08【】
目录
基础篇
第04章-Flink部署
P023【023_Flink运行时架构_系统架构】07:13
P024【024_Flink运行时架构_核心概念_并行度】06:45
P025【025_Flink运行时架构_核心概念_并行度设置&优先级】18:40
P026【026_Flink运行时架构_核心概念_算子链】08:34
P027【027_Flink运行时架构_核心概念_算子链演示】17:11
P028【028_Flink运行时架构_核心概念_任务槽】09:52
P029【029_Flink运行时架构_核心概念_任务槽的共享组】07:59
P030【030_Flink运行时架构_核心概念_slot与并行度的关系&演示】21:27
P031【031_Flink运行时架构_提交流程_Standalone会话模式&四张图】09:49
P032【032_Flink运行时架构_提交流程_Yarn应用模式】05:18
基础篇
第04章-Flink部署
P023【023_Flink运行时架构_系统架构】07:13
Flink运行时架构——Standalone会话模式为例
P024【024_Flink运行时架构_核心概念_并行度】06:45
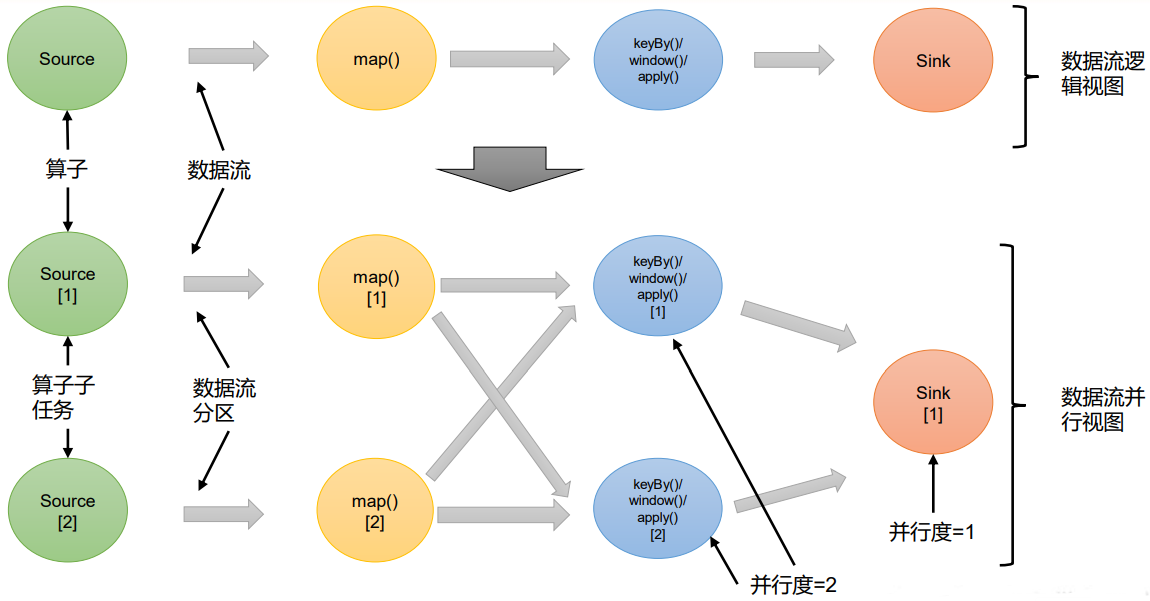
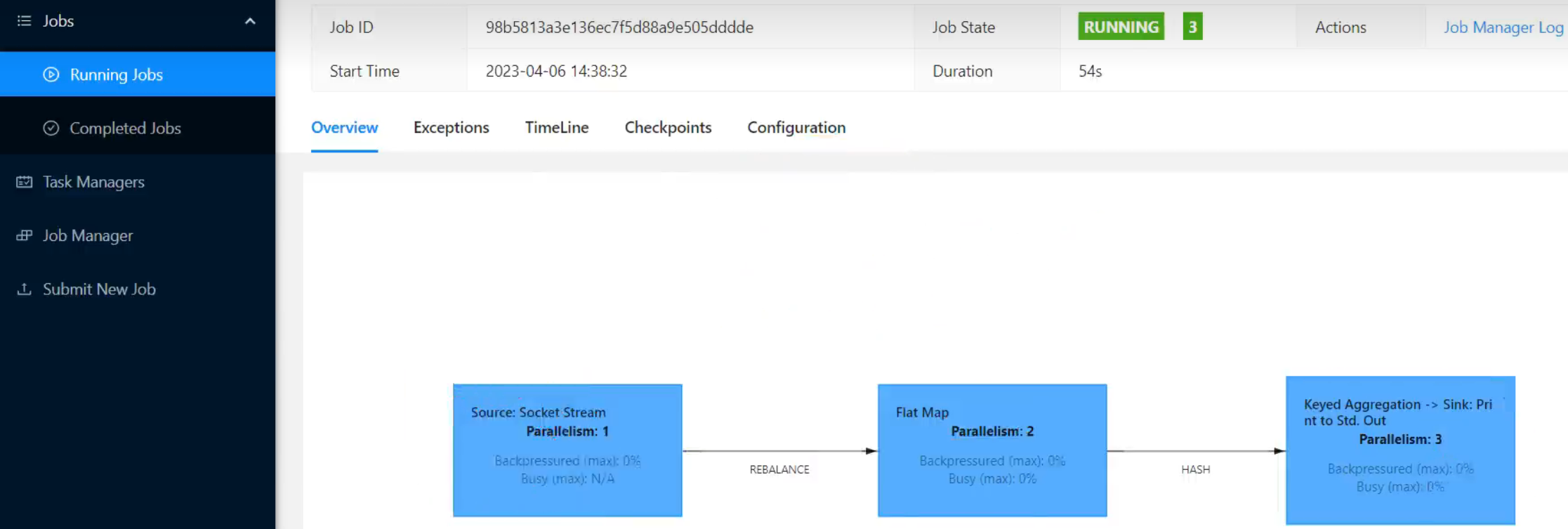
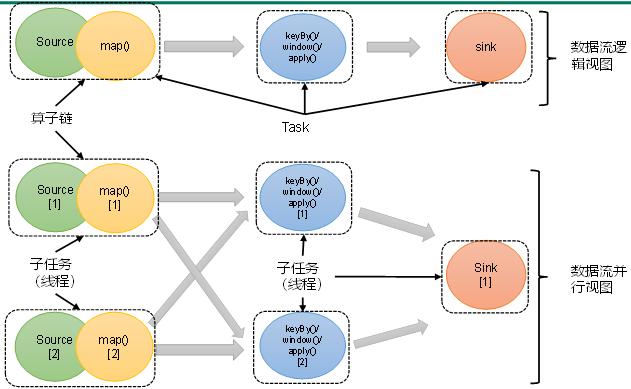
- 一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
- 例如:如上图所示,当前数据流中有source、map、window、sink四个算子,其中sink算子的并行度为1,其他算子的并行度都为2。所以这段流处理程序的并行度就是2。
P025【025_Flink运行时架构_核心概念_并行度设置&优先级】18:40
4.2.1 并行度(Parallelism)
2)并行度的设置
在Flink中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
(1)代码中设置
我们在代码中,可以很简单地在算子后跟着调用setParallelism()方法,来设置当前算子的并行度:
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
这种方式设置的并行度,只针对当前算子有效。
另外,我们也可以直接调用执行环境的setParallelism()方法,全局设定并行度:
env.setParallelism(2);
这样代码中所有算子,默认的并行度就都为2了。我们一般不会在程序中设置全局并行度,因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。
这里要注意的是,由于keyBy不是算子,所以无法对keyBy设置并行度。
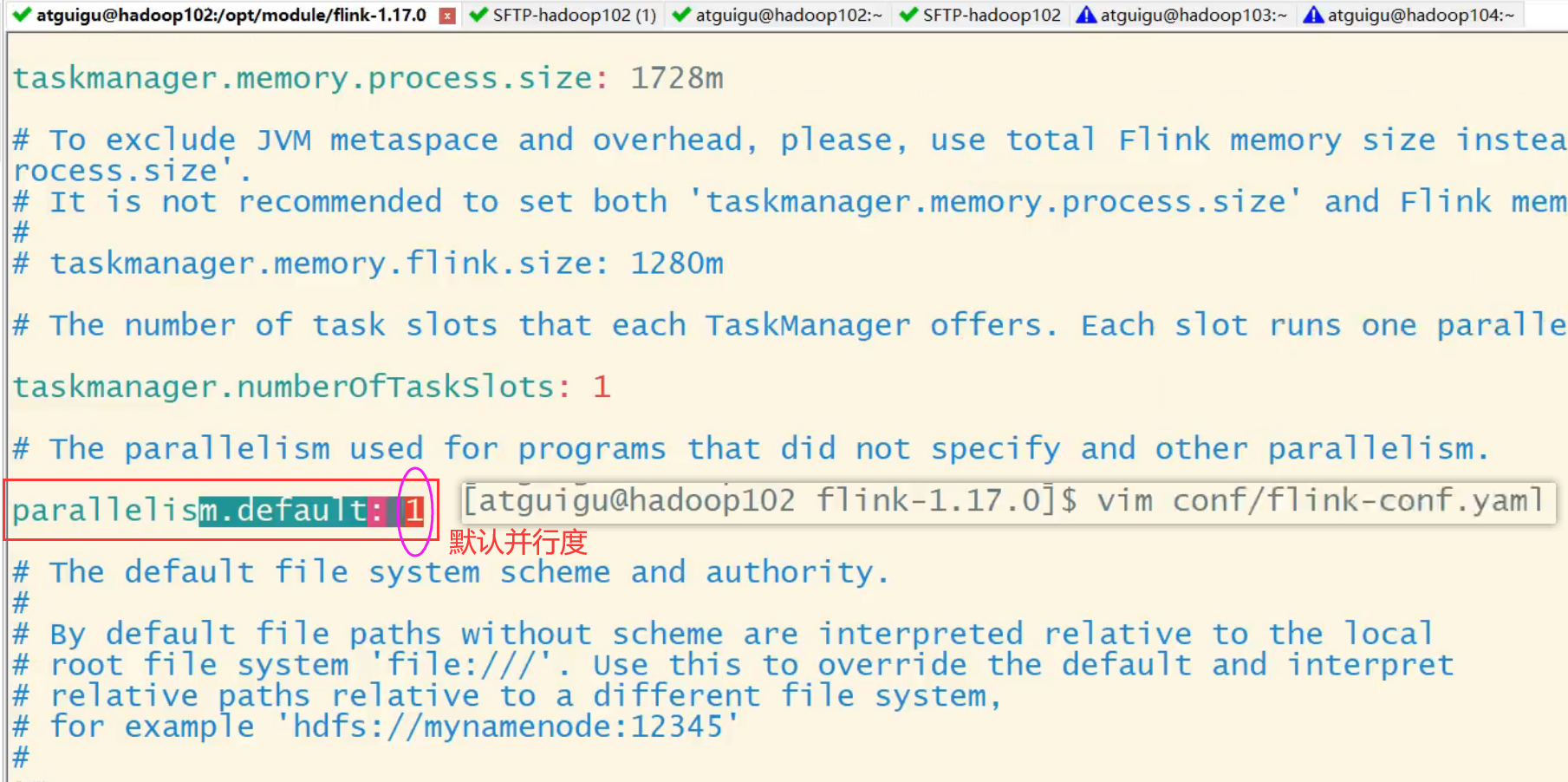
(2)提交应用时设置
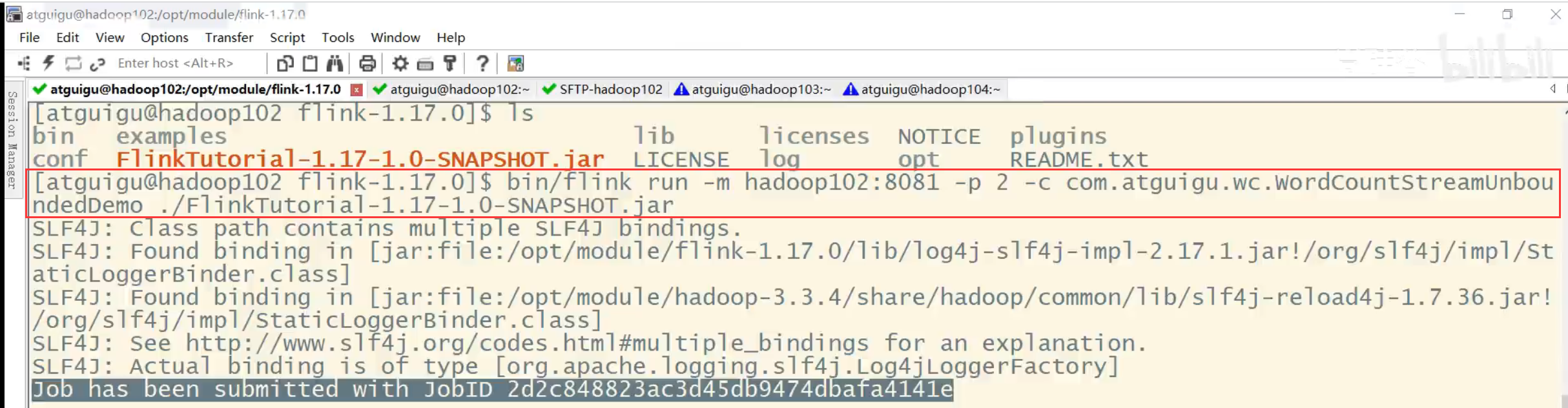
在使用flink run命令提交应用时,可以增加-p参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置:
bin/flink run –p 2 –c com.atguigu.wc.SocketStreamWordCount
./FlinkTutorial-1.0-SNAPSHOT.jar
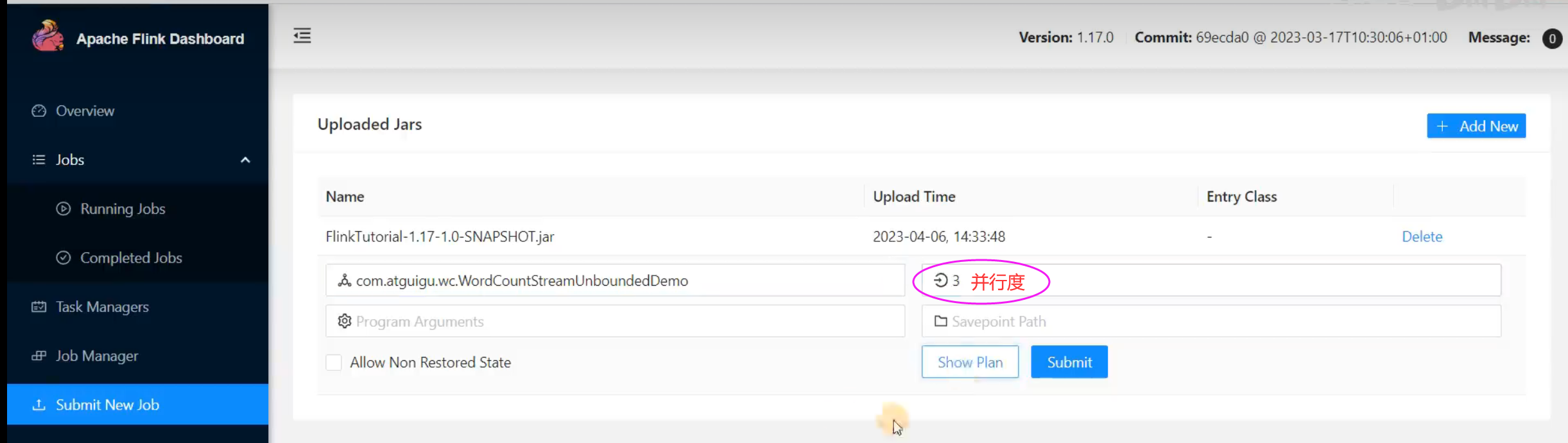
如果我们直接在Web UI上提交作业,也可以在对应输入框中直接添加并行度。
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
* @author
* @version 1.0
*/
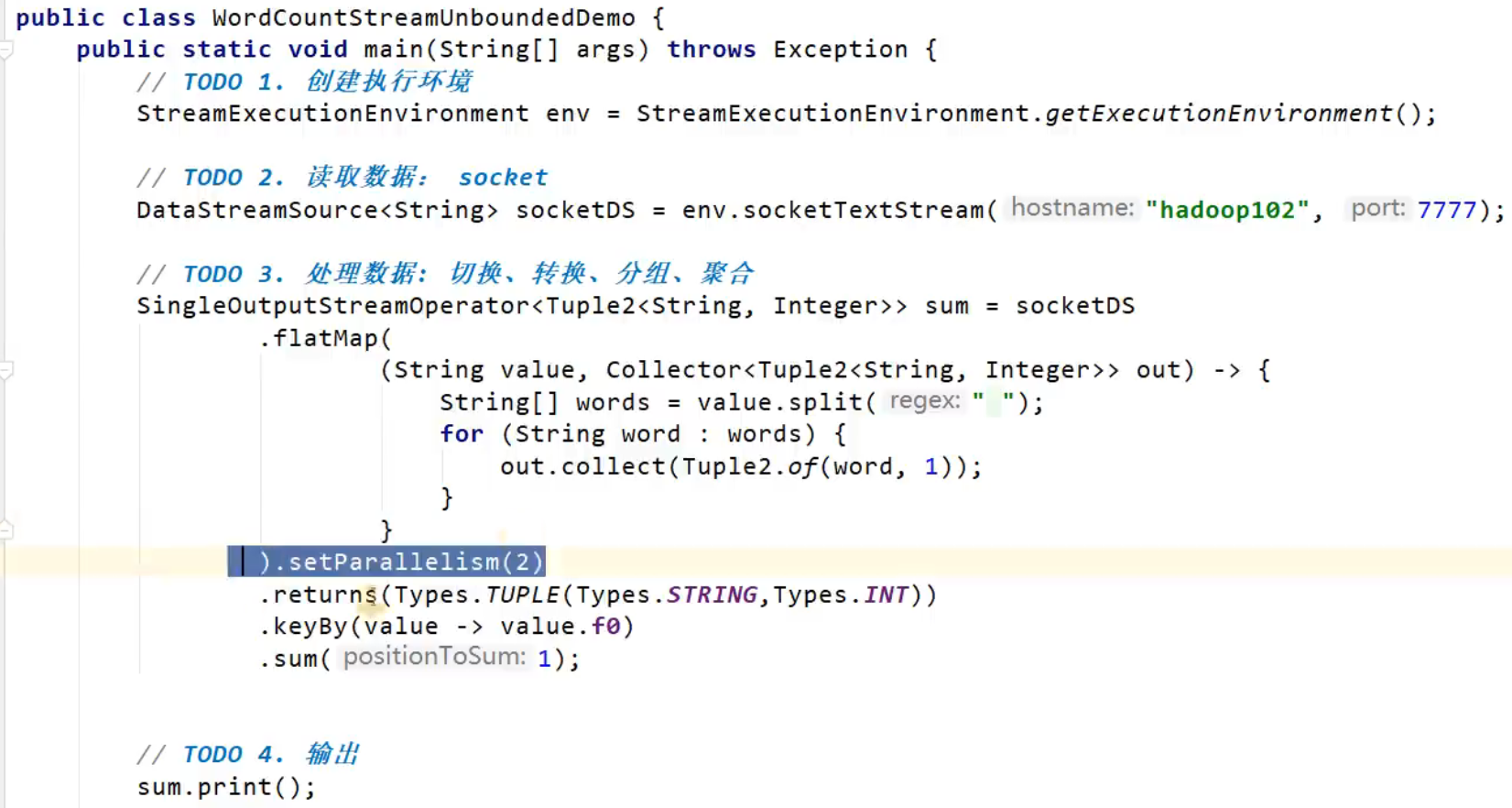
public class WordCountStreamUnboundedDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// IDEA运行时,也可以看到webui,一般用于本地测试
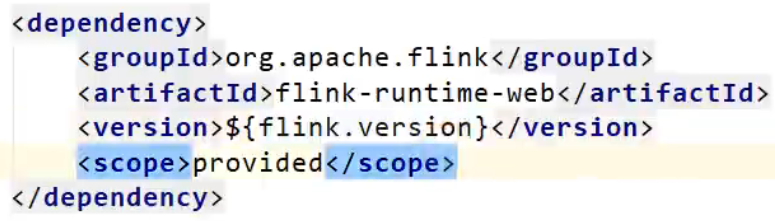
// 需要引入一个依赖 flink-runtime-web
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(3);
// TODO 2.读取数据: socket
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3.处理数据: 切换、转换、分组、聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS
.flatMap(
(String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
.setParallelism(2)
.returns(Types.TUPLE(Types.STRING,Types.INT))
// .returns(new TypeHint<Tuple2<String, Integer>>() {})
.keyBy(value -> value.f0)
.sum(1);
// TODO 4.输出
sum.print();
// TODO 5.执行
env.execute();
}
}
/**
并行度的优先级:
代码:算子 > 代码:env > 提交时指定 > 配置文件
*/并行度优先级:代码:算子 > 代码:全局env > 提交时指定命令 > 配置文件。
P026【026_Flink运行时架构_核心概念_算子链】08:34
4.2.2 算子链(Operator Chain)
2)合并算子链
在Flink中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如下图所示。每个task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
P027【027_Flink运行时架构_核心概念_算子链演示】17:11
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
* @author
* @version 1.0
*/
public class OperatorChainDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// IDEA运行时,也可以看到webui,一般用于本地测试
// 需要引入一个依赖 flink-runtime-web
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
env.setParallelism(1);
// 全局禁用 算子链
//env.disableOperatorChaining();
// TODO 2.读取数据:socket
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3.处理数据: 切换、转换、分组、聚合
SingleOutputStreamOperator<Tuple2<String,Integer>> sum = socketDS
//.disableChaining()
.flatMap(
(String value, Collector<String> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
)
.startNewChain()
//.disableChaining()
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1))
.returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy(value -> value.f0)
.sum(1);
// TODO 4.输出
sum.print();
// TODO 5.执行
env.execute();
}
}
/**
1、算子之间的传输关系:
一对一
重分区
2、算子 串在一起的条件:
1) 一对一
2) 并行度相同
3、关于算子链的api:
1)全局禁用算子链:env.disableOperatorChaining();
2)某个算子不参与链化: 算子A.disableChaining(), 算子A不会与 前面 和 后面的算子 串在一起
3)从某个算子开启新链条: 算子A.startNewChain(), 算子A不与 前面串在一起,从A开始正常链化
*/P028【028_Flink运行时架构_核心概念_任务槽】09:52
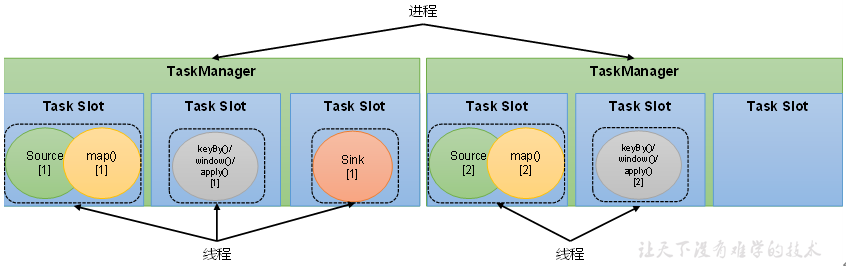
4.2.3 任务槽(Task Slots)
P029【029_Flink运行时架构_核心概念_任务槽的共享组】07:59
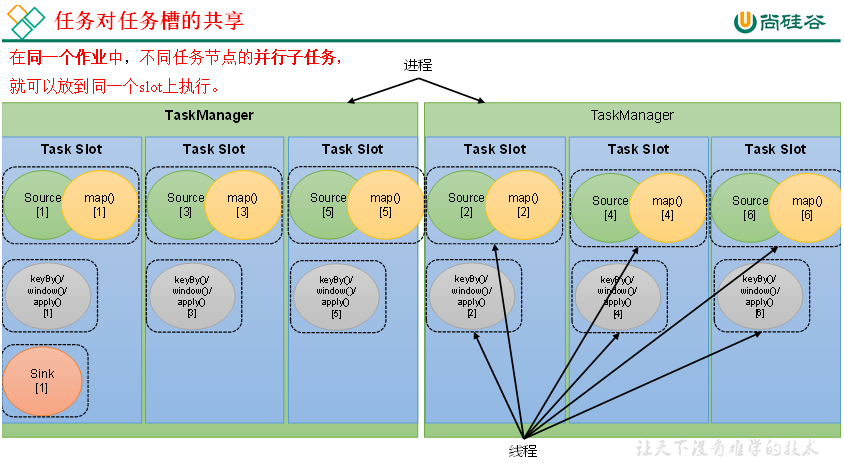
3)任务对任务槽的共享
默认情况下,Flink是允许子任务共享slot的。如果我们保持sink任务并行度为1不变,而作业提交时设置全局并行度为6,那么前两个任务节点就会各自有6个并行子任务,整个流处理程序则有13个子任务。如上图所示,只要属于同一个作业,那么对于不同任务节点(算子)的并行子任务,就可以放到同一个slot上执行。所以对于第一个任务节点source→map,它的6个并行子任务必须分到不同的slot上,而第二个任务节点keyBy/window/apply的并行子任务却可以和第一个任务节点共享slot。
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
* @author
* @version 1.0
*/
public class SlotSharingGroupDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// IDEA运行时,也可以看到webui,一般用于本地测试
// 需要引入一个依赖 flink-runtime-web
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
env.setParallelism(1);
// TODO 2.读取数据:socket
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3.处理数据: 切换、转换、分组、聚合
SingleOutputStreamOperator<Tuple2<String,Integer>> sum = socketDS
.flatMap(
(String value, Collector<String> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
)
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1)).slotSharingGroup("aaa")
.returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy(value -> value.f0)
.sum(1);
// TODO 4.输出
sum.print();
// TODO 5.执行
env.execute();
}
}
/**
1、slot特点:
1)均分隔离内存,不隔离cpu
2)可以共享:
同一个job中,不同算子的子任务 才可以共享 同一个slot,同时在运行的
前提是,属于同一个 slot共享组,默认都是“default”
2、slot数量 与 并行度 的关系
1)slot是一种静态的概念,表示最大的并发上限
并行度是一种动态的概念,表示 实际运行 占用了 几个
2)要求: slot数量 >= job并行度(算子最大并行度),job才能运行
TODO 注意:如果是yarn模式,动态申请
--> TODO 申请的TM数量 = job并行度 / 每个TM的slot数,向上取整
比如session: 一开始 0个TaskManager,0个slot
--> 提交一个job,并行度10
--> 10/3,向上取整,申请4个tm,
--> 使用10个slot,剩余2个slot
*/P030【030_Flink运行时架构_核心概念_slot与并行度的关系&演示】21:27
4.2.4 任务槽和并行度的关系
任务槽和并行度都跟程序的并行执行有关,但两者是完全不同的概念。简单来说任务槽是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
slot数量 与 并行度 的关系
1)slot是一种静态的概念,表示最大的并发上限
并行度是一种动态的概念,表示 实际运行 占用了 几个2)要求: slot数量 >= job并行度(算子最大并行度),job才能运行
TODO 注意:如果是yarn模式,动态申请
--> TODO 申请的TM数量 = job并行度 / 每个TM的slot数,向上取整
比如session: 一开始 0个TaskManager,0个slot
--> 提交一个job,并行度10
--> 10/3,向上取整,申请4个tm
--> 使用10个slot,剩余2个slot
P031【031_Flink运行时架构_提交流程_Standalone会话模式&四张图】09:49
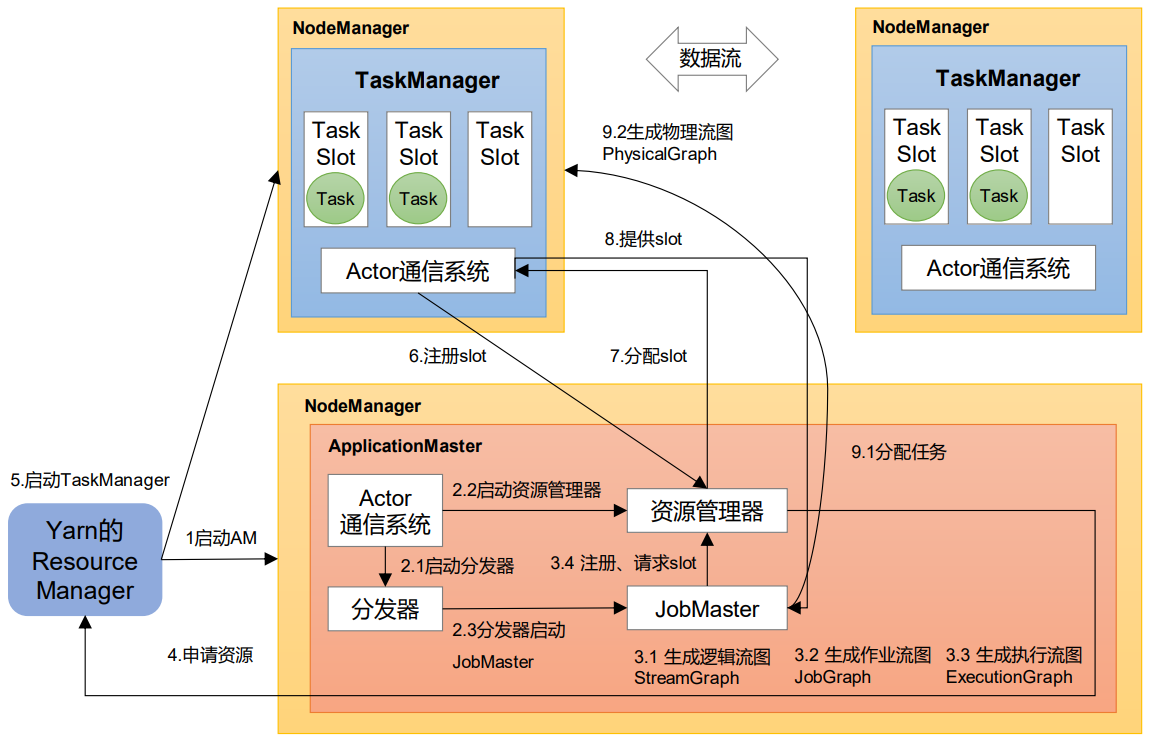
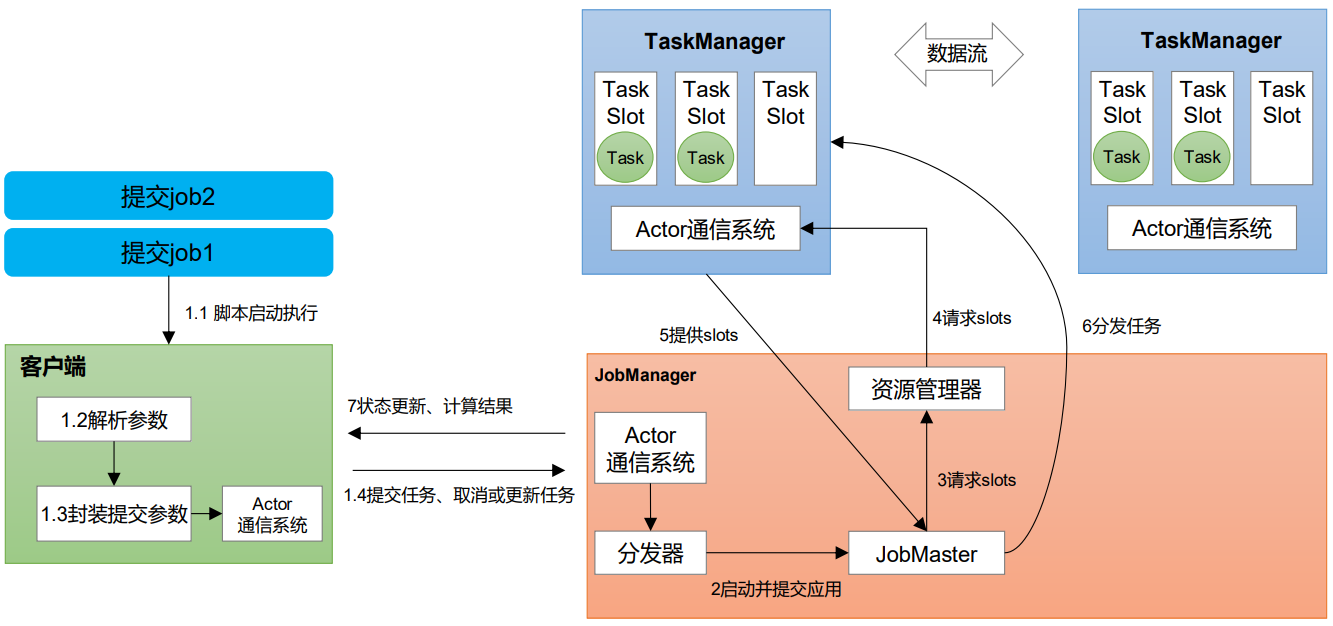
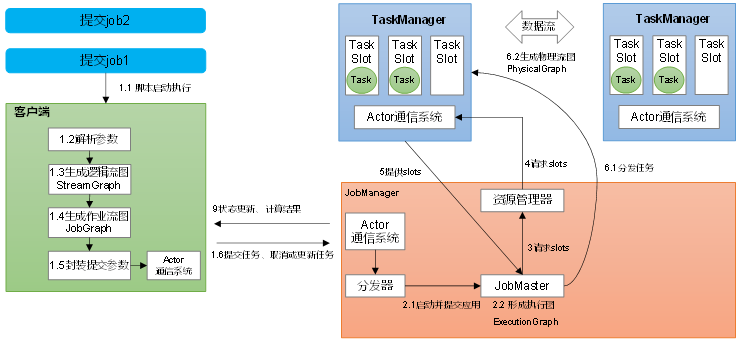
4.3 作业提交流程
4.3.1 Standalone会话模式作业提交流程
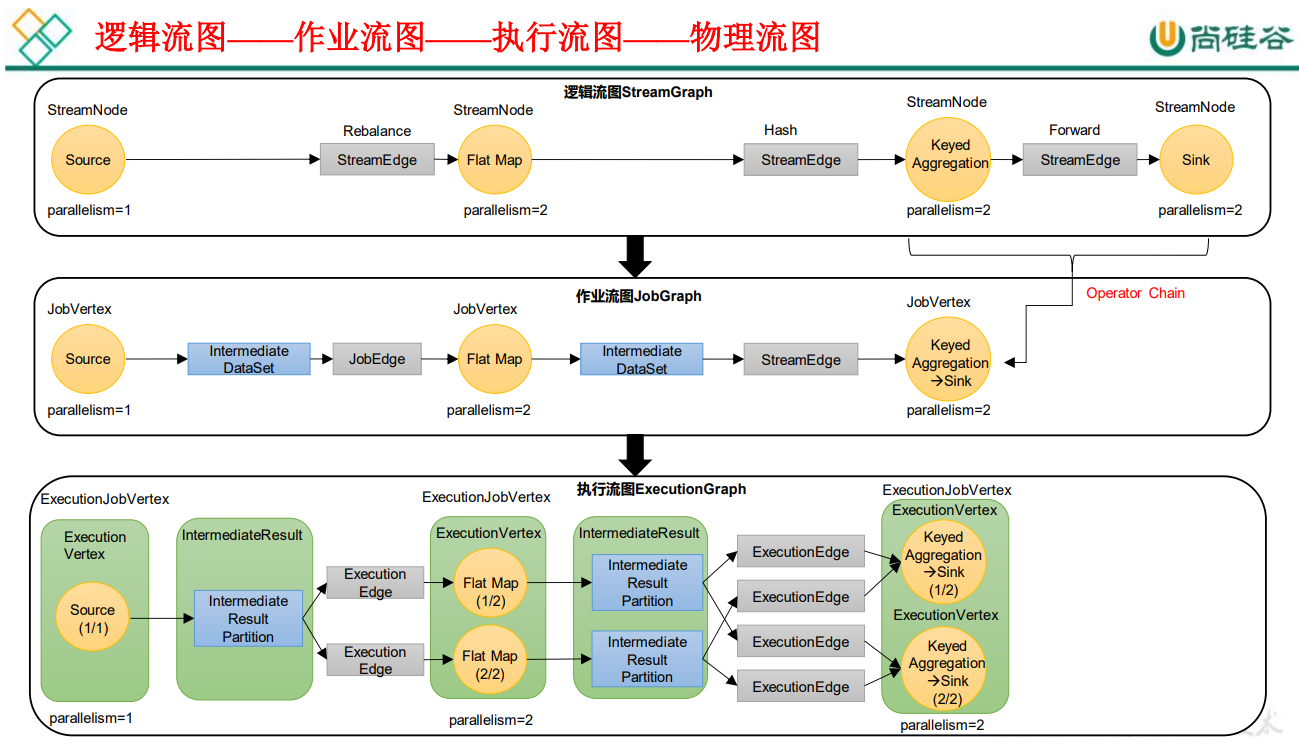
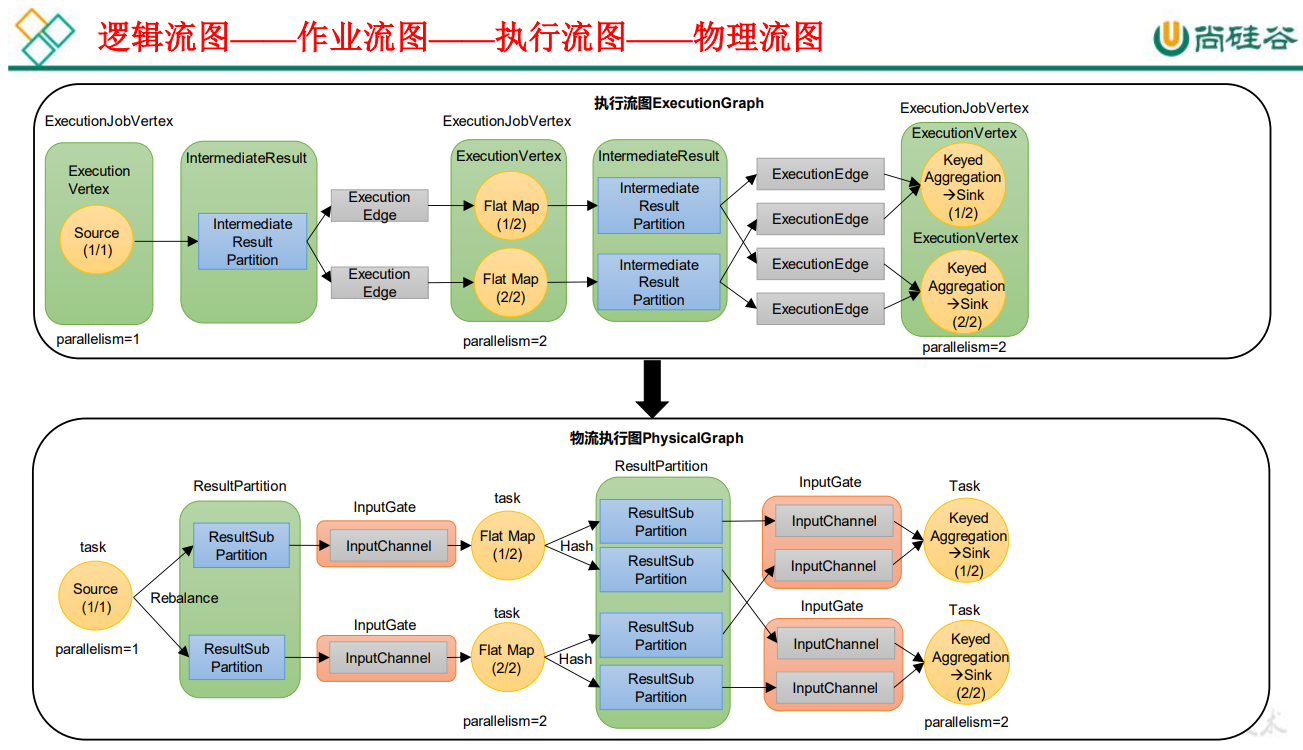
4.3.2 逻辑流图/作业图/执行图/物理流图
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)。
P032【032_Flink运行时架构_提交流程_Yarn应用模式】05:18
4.3.3 Yarn应用模式作业提交流程