SpectFormer: Frequency and Attention is what you need in a Vision Transformer, arXiv2023
频域混合注意力SpectFormer 2023
论文:https://arxiv.org/abs/2304.06446
代码:https://badripatro.github.io/SpectFormers/
摘要视觉变压器已经成功地应用于图像识别任务中。已有类似于原文模型的基于多头自注意的研究(ViT[14]、DeIT[53]),或最近基于谱层的研究(Fnet[29]、GFNet[47]、AFNO[17])。我们假设谱注意力和多头注意力都起主要作用。我们通过这项工作研究了这一假设,并观察到谱和多头注意层的结合确实提供了更好的变压器架构。因此,我们提出了一种结合了频谱层和多头注意层的变压器的新频谱结构。我们相信结果表示允许转换器适当地捕获特征表示,并且它比其他转换器表示产生更好的性能。例如,与GFNet-H和LiT相比,它在ImageNet上提高了2%的top-1精度。specformer - s在ImageNet- 1k上达到了84.25%的top-1精度(小版本的最新水平)。
此外,specformer - l达到了85.7%,这是同类基础版变压器的最新水平。我们进一步确保在其他场景中获得合理的结果,例如在标准数据集(如CIFAR-10、CIFAR-100、Oxford-IIIT-flower和stanford Car数据集)上的迁移学习。然后,我们研究了它在MS-COCO数据集上的下游任务(如对象检测和实例分割)中的使用情况,并观察到specformer显示出与最佳骨干网相当的一致性能,并且可以进一步优化和改进。因此,我们认为结合光谱层和注意层是视觉变压器所需要的。
在文本模型中,既有类似于原始工作的基于多头自我注意的(ViT,DeIT),也有最近基于光谱层的(Fnet,GFNet,AFNO)。受光谱和层次Transformer相关工作的启发,论文观察到光谱和多头注意力层的结合能提供更好的Transformer架构,因此提出SpectFormer,使用傅立叶变换实现的光谱层来捕捉架构初始层中的相关特征。 此外,在网络的深层使用多头自我注意。 SpectFormer架构简单,它将图像标记转换到傅立叶域,然后使用可学习的权重参数应用门控技术,最后进行傅立叶逆变换以获取信号。 SpectFormer结合了光谱注意力和多头注意力。
网络结构

总
SpectFormer架构包括贴片嵌入层,后面是位置嵌入层,然后是变换器块,然后是分类头。Transformer块包括一系列光谱层,后面是关注层。图像被分割成一系列补丁,得到使用线性投影层的贴片嵌入。其中,位置嵌入使用标准的位置编码层。
其实这里我觉得网络总体跟Vit是类似的,中间的Transformer Block块有很大的改变。
Spectral Block
光谱层的目的是捕捉图像的不同频率分量,以理解局部频率。这可以使用频谱门控网络来实现,该频谱门控网络包括快速傅立叶变换(FFT)层,然后是加权门控,然后是逆FFT层。频谱层使用FFT将物理空间转换为频谱空间。使用可学习的权重参数来确定每个频率分量的权重,以便适当地捕捉图像的线条和边缘。频谱层使用快速傅立叶逆变换(IFFT)将频谱空间带回物理空间。在IFFT之后,频谱层具有用于信道混合的层归一化和多层感知器(MLP)块,而令牌混合使用spectral门控技术来完成。
Attention Block
SpectFormer的注意力层是一个标准的注意力层,包括层规范化,然后是多头自注意(MHSA),然后是层规范化和MLP。MHSA架构与DeIT注意力架构的相似之处在于,MHSA用于注意力层中的令牌混合,MLP用于信道混合。
SpectFormer Block
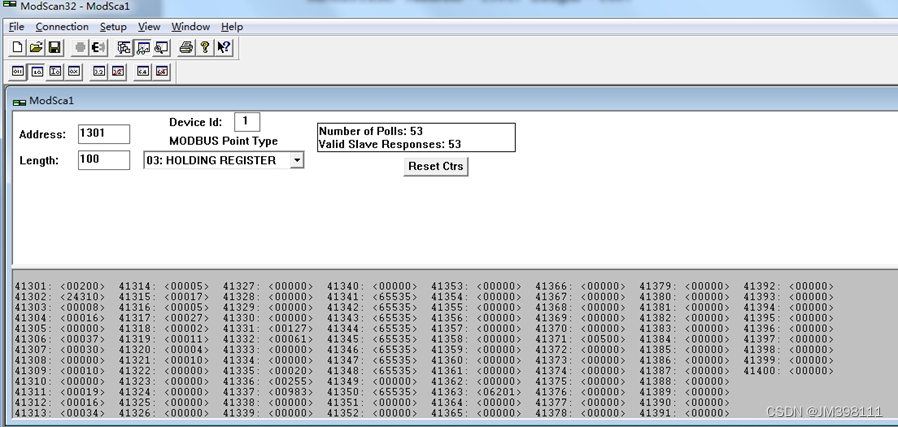
SpectFormer块如图1所示,处于分阶段体系结构中。在SpectFormer块中引入了一个因子,它控制光谱层和注意力层的数量。如果α=0,SpectFormer包括所有注意力层,类似于DeIT-s,而当α值为12时,SpectFormer变得类似于GFNet,具有所有光谱层。必须注意的是,所有注意力层都具有无法准确捕捉局部特征的缺点。类似地,所有光谱层都具有全局图像属性或语义特征无法准确处理的缺点。SpectFormer提供了改变光谱和注意力层数量的灵活性,这有助于准确捕捉全局属性和局部特征。SpectFormer考虑了局部特征,这有助于捕获初始层中的局部频率以及更深层中的全局特征。
概述:本文分别探索了频域和多头自注意力层的作用效果。之前的Transformer网络要么只使用全注意力层,要么只使用频域层,在图像特征提取方面存在各自的局限性。本文提出了一种新型的混合Transformer架构,即将这两个方面结合起来,提出了Spectformer模型。Spectformer显示出比先前模型更加稳定的性能。除了在传统的视觉任务上可以获得SOTA性能之外(在ImageNet-1K数据集上实现了85.7%的Top-1识别准确率),作者还认为,将Spectformer应用到一些频域信息更加丰富的领域上(例如遥感和医学图像数据),可能会激发出混合频域层和注意力层更大的潜力。
DilateFormer Multi-Scale Dilated Transformer for Visual Recognition
DilateFormer:用于视觉识别的多尺度扩张变换器 TMM 2023
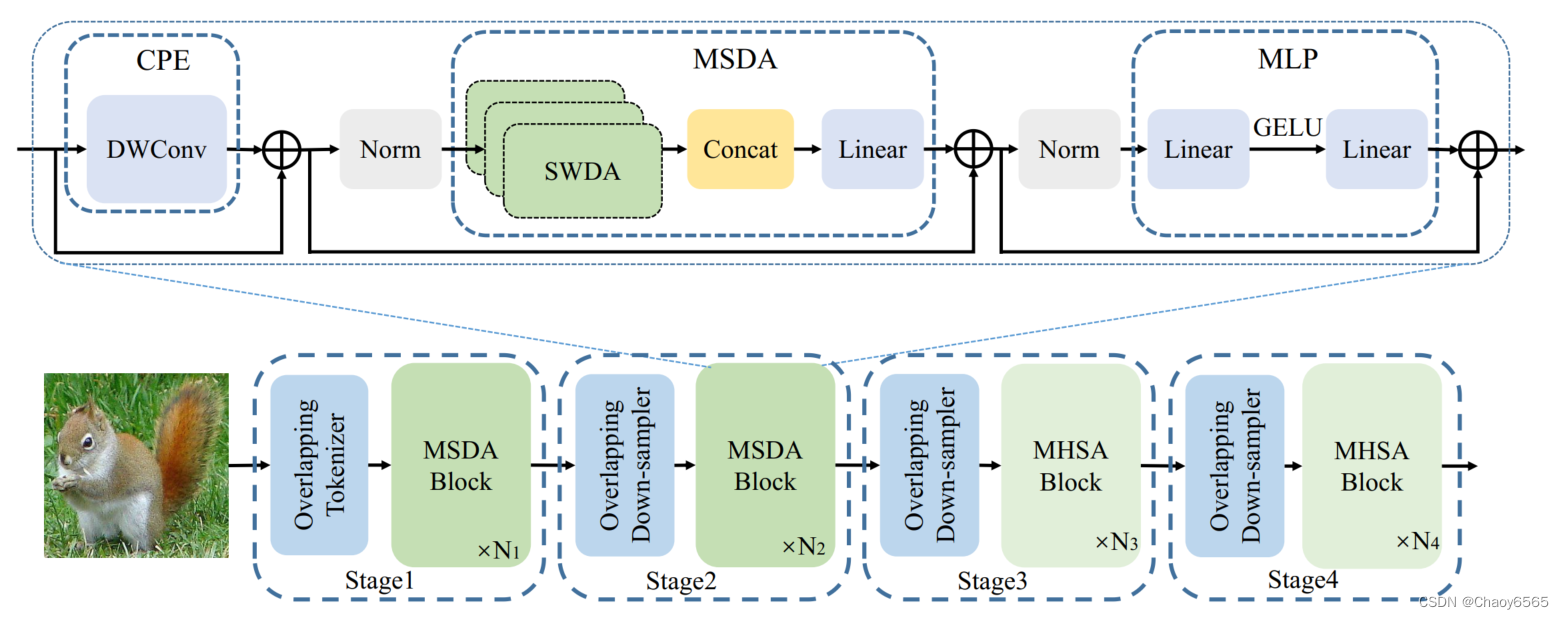
作为一个事实上的解决方案,香草视觉变换器(ViTs)被鼓励在任意图像斑块之间建立长距离的依赖关系,而全局关注的接受场会导致二次计算成本。视觉变换器的另一个分支是利用CNN启发的局部注意,它只对小范围内的斑块之间的相互作用进行建模。虽然这样的解决方案降低了计算成本,但它自然会受到小的受体场的影响,这可能会限制性能。在这项工作中,我们探索了有效的视觉变换器,以便在计算复杂性和出席的感受区的大小之间寻求一个理想的权衡。通过分析ViTs中全局注意力的补丁交互,我们观察到浅层中的两个关键属性,即局部性和稀疏性,表明ViTs浅层中全局依赖性建模的冗余性。因此,我们提出了多尺度扩张注意(MSDA)来模拟滑动窗口内的局部和稀疏的斑块互动。通过金字塔结构,我们在低级阶段堆叠MSDA块,在高级阶段堆叠全局多头自我注意块,从而构建了一个多尺度稀释变换器(DilateFormer)。
通过分析传统ViT全局注意力中Image Patch的相互作用,作者发现网络浅层的注意力矩阵有2个特点:局部性、稀疏性。
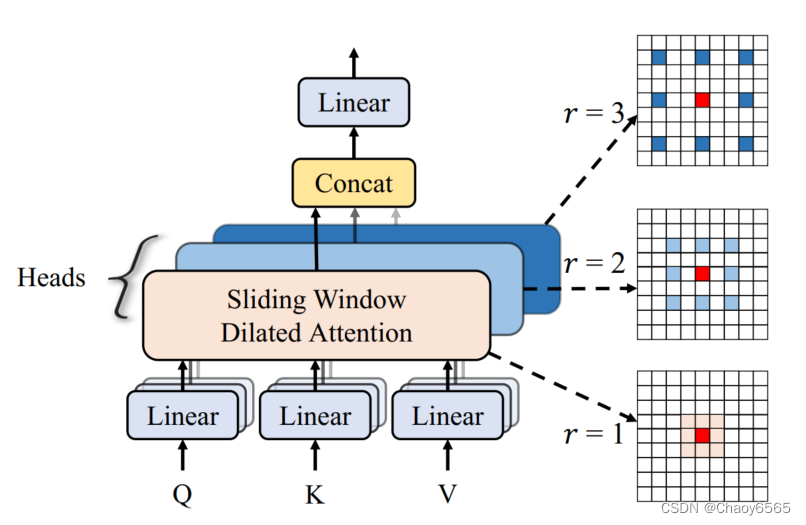
滑窗空洞注意力(Sliding Window Dilated Attention,SWDA)
滑窗空洞注意力思想非常简单,主要是受空洞卷积的启发,以Query为中心,并利用空洞方式进行采样Key和Value,从而既扩大了窗口注意力感受野,又不增加计算成本。公式如下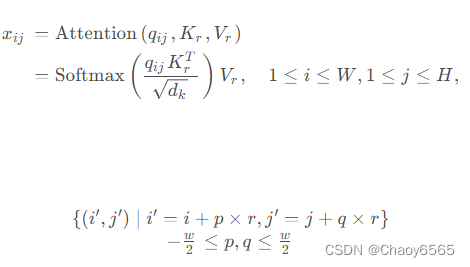
多尺度空洞注意力(Multi-Scale Dilated Attention,MSDA)

网络结构
个人感觉就就是对原始的多头注意力的输入k、v用空洞卷积再送入多头注意力。然后使用不同的空洞率,对输出结果进行cat,再降维。还没看代码,不一定对。
ShadowFormer: Global Context Helps Image Shadow Removal
AAAI 2023
引入了一种基于Retinex的阴影模型,提出了一种新的基于多尺度通道注意力框架的阴影去除Transformer(ShadowFormer)。
网络结构:总体架构是一个Encoder-Decoder的结构,在Encoder和Decoder都堆叠使用通道注意力来获得多尺度特征。同时在中间使用提出的Shadow-Interaction Module,每次特征图大小缩小到一半,通道数扩大一倍。
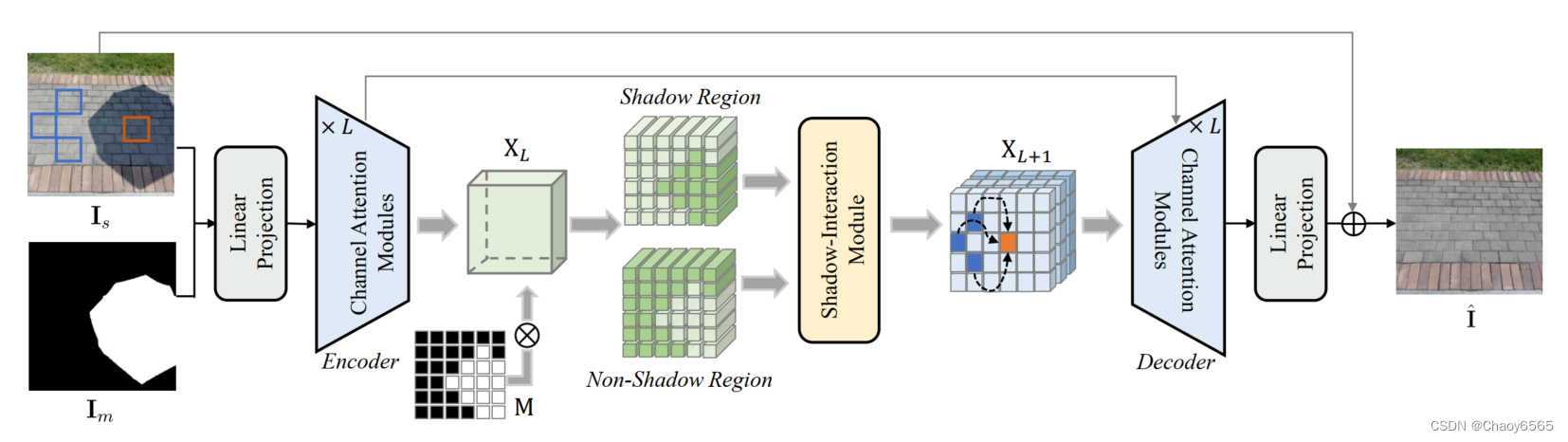
对输入带阴影的图像Is(Is ∈ R3×H×W )和阴影区域掩码Im(Im ∈ RH×W ),经过一个线性投影LinearProj(·)得到输入的底层特征嵌入,记为 X0 ∈ RC×H×W,其中C为嵌入维数。然后将嵌入的X0输入到基于CAtransformer的encoder/decoder中,每个encoder由L个CA模块组成,用于堆叠多尺度全局特征。每个CA模块包括两个CA块,以及编码器中的下采样层或解码器中的上采样层,如下图a所示。CA块通过CA依次压缩空间信息,并通过前馈MLP捕获远程相关性。
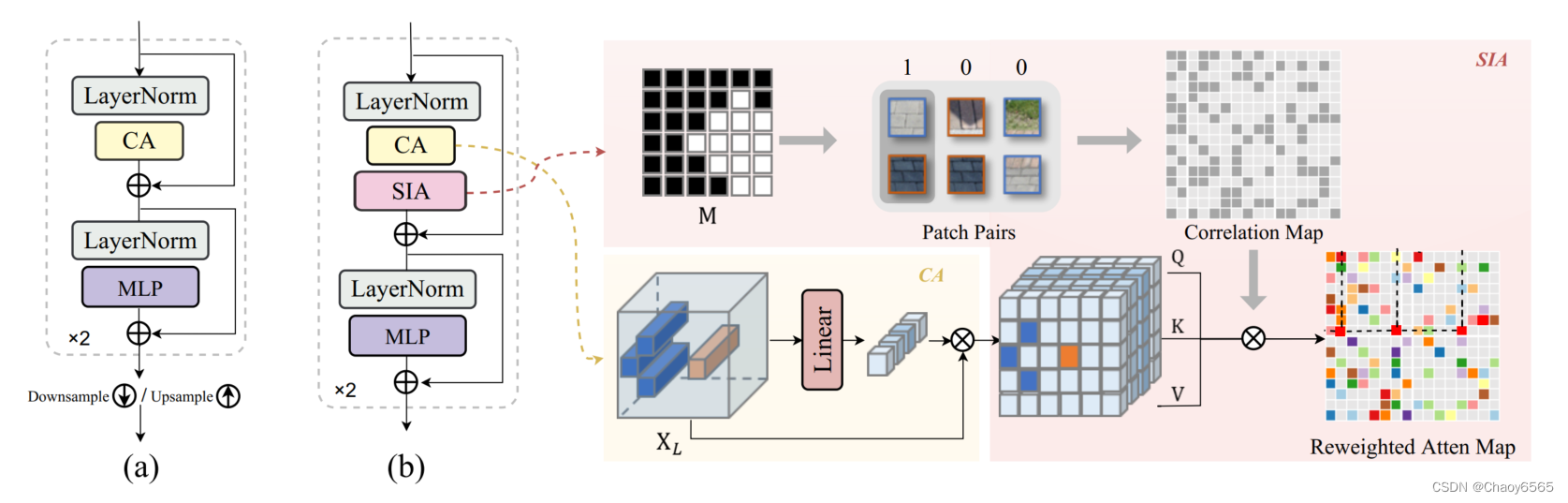
Shadow-Interaction Module模块中采用了类似窗口注意力的架构,使用池化操作减少了计算量,使用了异或操作来帮助获得更显著的权重。