CS 144 Lab One
- 实验结构
- 环境配置
- 如何调试
- StreamReassembler 实现
对应课程视频: 【计算机网络】 斯坦福大学CS144课程
Lab 1 对应的PDF: Lab Checkpoint 1: stitching substrings into a byte stream
实验结构
这幅图完整的说明了CS144 这门实验的结构:
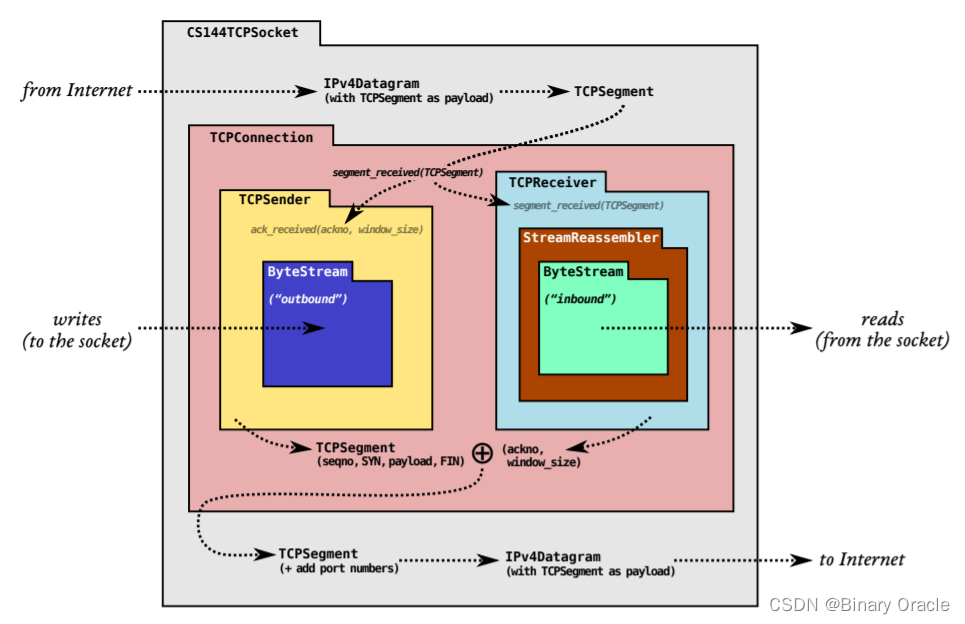
其中, ByteStream 是我们已经在 Lab0 中实现完成的。
我们将在接下来的实验中分别实现:
- Lab1
StreamReassembler:实现一个流重组器,一个将字节流的字串或者小段按照正确顺序来拼接回连续字节流的模块 - Lab2
TCPReceiver:实现入站字节流的TCP部分。 - Lab3
TCPSender:实现出站字节流的TCP部分。 - Lab4
TCPConnection: 结合之前的工作来创建一个有效的 TCP 实现。最后我们可以使用这个 TCP 实现来和真实世界的服务器进行通信。
该实验引导我们以模块化的方式构建一个 TCP 实现。
流重组器在 TCP 起到了相当重要的作用。迫于网络环境的限制,TCP 发送者会将数据切割成一个个小段的数据分批发送。但这就可能带来一些新的问题:数据在网络中传输时可能丢失、重排、多次重传等等。而TCP接收者就必须通过流重组器,将接收到的这些重排重传等等的数据包重新组装成新的连续字节流。
环境配置
当前我们的实验代码位于 master 分支,而在完成 Lab1 之前需要合并一些 Lab1 的依赖代码,因此执行以下命令:
git merge origin/lab1-startercode
之后重新 make 编译即可。
如何调试
先 cmake && make 一个 Debug 版本的程序。
所有的评测程序位于build/tests/中,先一个个手动执行过去。
若输出了错误信息,则使用 gdb 调试一下。
StreamReassembler 实现
在我们所实现的流重组器中,有以下几种特性:
-
接收子字符串。这些子字符串中包含了一串字节,以及该字符串在总的数据流中的第一个字节的索引。
-
流的每个字节都有自己唯一的索引,从零开始向上计数。
-
StreamReassembler 中存在一个 ByteStream 用于输出,当重组器知道了流的下一个字节,它就会将其写入至 ByteStream中。
需要注意的是,传入的子串中:
-
子串之间可能相互重复,存在重叠部分
- 但假设重叠部分数据完全重复。
- 不存在某些 index 下的数据在某个子串中是一种数据,在另一个子串里又是另一种数据。
- 重叠部分的处理最为麻烦。
-
可能会传一些已经被装配了的数据
-
如果 ByteStream 已满,则必须暂停装配,将未装配数据暂时保存起来
除了上面的要求以外,容量 Capacity 需要严格限制:
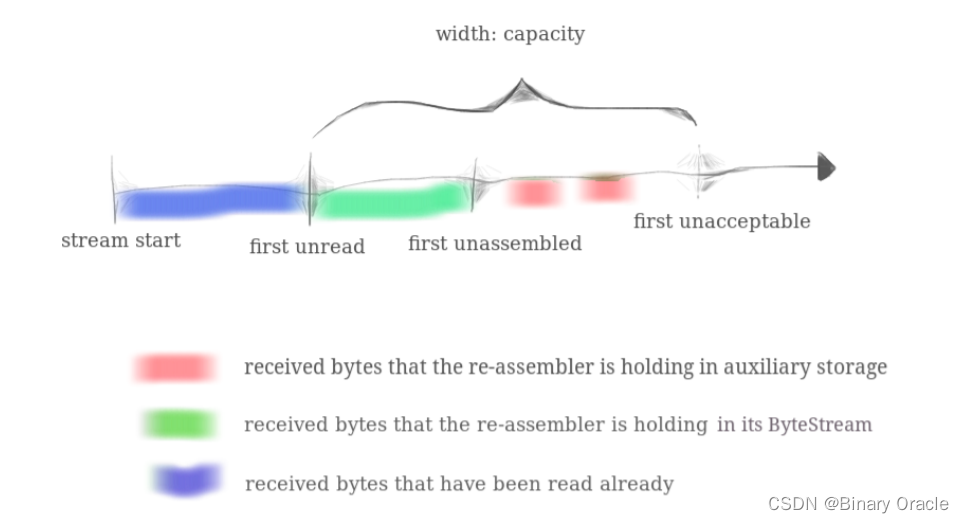
为了便于说明,将图中的绿色区域称为 ByteStream,将图中存放红色区域的内存范围(即 first unassembled - first unacceptable)称为 Unassembled_strs。
CS144 要求将 ByteStream + Unassembled_strs 的内存占用总和限制在 Reassember 中构造函数传入的 capacity 大小。因此我们在构造 Reassembler 时,需要既将传入的 capacity 参数设置为 ByteStream的缓冲区大小上限,也将其设置为first unassembled - first unacceptable的范围大小,以避免极端情况下的内存使用。
注意:first unassembled - first unacceptable的范围大小,并不等同于存放尚未装配子串的结构体内存大小上限,别混淆了。
Capacity 这个概念很重要,因为它不仅用于限制高内存占用,而且它还会起到流量控制的作用(见 lab2)。
代码实现如下:
- stream_reassembler.hh
//! \brief A class that assembles a series of excerpts from a byte stream
//! (possibly out of order, possibly overlapping) into an in-order byte stream.
class StreamReassembler {
private:
// Your code here -- add private members as necessary.
struct Datum {
char ch = 0;
bool valid = false;
};
std::vector<Datum> buffer_; // buffer to store unassembled data.
size_t buffer_header_; // pointer to the begining of the unssembled bytes in
// buffer.
size_t unassembled_bytes_;
size_t eof_byte_;
bool is_eof_set_; // true if read the eof
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
public:
//! \brief Construct a `StreamReassembler` that will store up to
//! `capacity` bytes. \note This capacity limits both the bytes that
//! have been reassembled, and those that have not yet been
//! reassembled.
StreamReassembler(const size_t capacity);
//! \brief Receive a substring and write any newly contiguous bytes
//! into the stream.
//!
//! The StreamReassembler will stay within the memory limits of the
//! `capacity`. Bytes that would exceed the capacity are silently
//! discarded.
//!
//! \param data the substring
//! \param index indicates the index (place in sequence) of the first
//! byte in `data` \param eof the last byte of `data` will be the last
//! byte in the entire stream
void push_substring(const std::string &data, const uint64_t index, const bool eof);
//! \name Access the reassembled byte stream
//!@{
const ByteStream &stream_out() const { return _output; }
ByteStream &stream_out() { return _output; }
//!@}
//! The number of bytes in the substrings stored but not yet
//! reassembled
//!
//! \note If the byte at a particular index has been pushed more than
//! once, it should only be counted once for the purpose of this
//! function.
size_t unassembled_bytes() const;
//! \brief Is the internal state empty (other than the output stream)?
//! \returns `true` if no substrings are waiting to be assembled
bool empty() const;
};
- stream_reassembler.cc
#include "stream_reassembler.hh"
#include <cassert>
// For Lab 1, please replace with a real implementation that passes the
// automated checks run by `make check_lab1`.
// You will need to add private members to the class declaration in
// `stream_reassembler.hh`
using namespace std;
StreamReassembler::StreamReassembler(const size_t capacity)
: buffer_(capacity)
, buffer_header_(0)
, unassembled_bytes_(0)
, eof_byte_(0)
, is_eof_set_(false)
, _output(capacity)
, _capacity(capacity) {}
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
if (_output.input_ended())
return;
const size_t max_byte = _output.bytes_read() + _capacity;
const size_t index_start = std::max(_output.bytes_written(), index);
size_t index_end = std::min(max_byte, index + data.length());
// check for eof
if (eof) {
is_eof_set_ = true;
eof_byte_ = index + data.length();
}
if (is_eof_set_)
index_end = std::min(index_end, eof_byte_);
// buffer the data
for (size_t write_index = index_start; write_index < index_end; write_index++) {
size_t cache_index = (buffer_header_ + write_index - _output.bytes_written()) % _capacity;
assert(!(buffer_[cache_index].valid && buffer_[cache_index].ch != data[write_index - index]));
if (!buffer_[cache_index].valid)
unassembled_bytes_++;
buffer_[cache_index].valid = true;
buffer_[cache_index].ch = data[write_index - index];
}
// write the data.
while (buffer_[buffer_header_].valid) {
buffer_[buffer_header_].valid = false;
_output.write_char(buffer_[buffer_header_].ch);
unassembled_bytes_--;
buffer_header_ = (buffer_header_ + 1) % _capacity;
}
if (is_eof_set_ && _output.bytes_written() >= eof_byte_)
_output.end_input();
}
size_t StreamReassembler::unassembled_bytes() const { return unassembled_bytes_; }
bool StreamReassembler::empty() const { return unassembled_bytes_ == 0; }
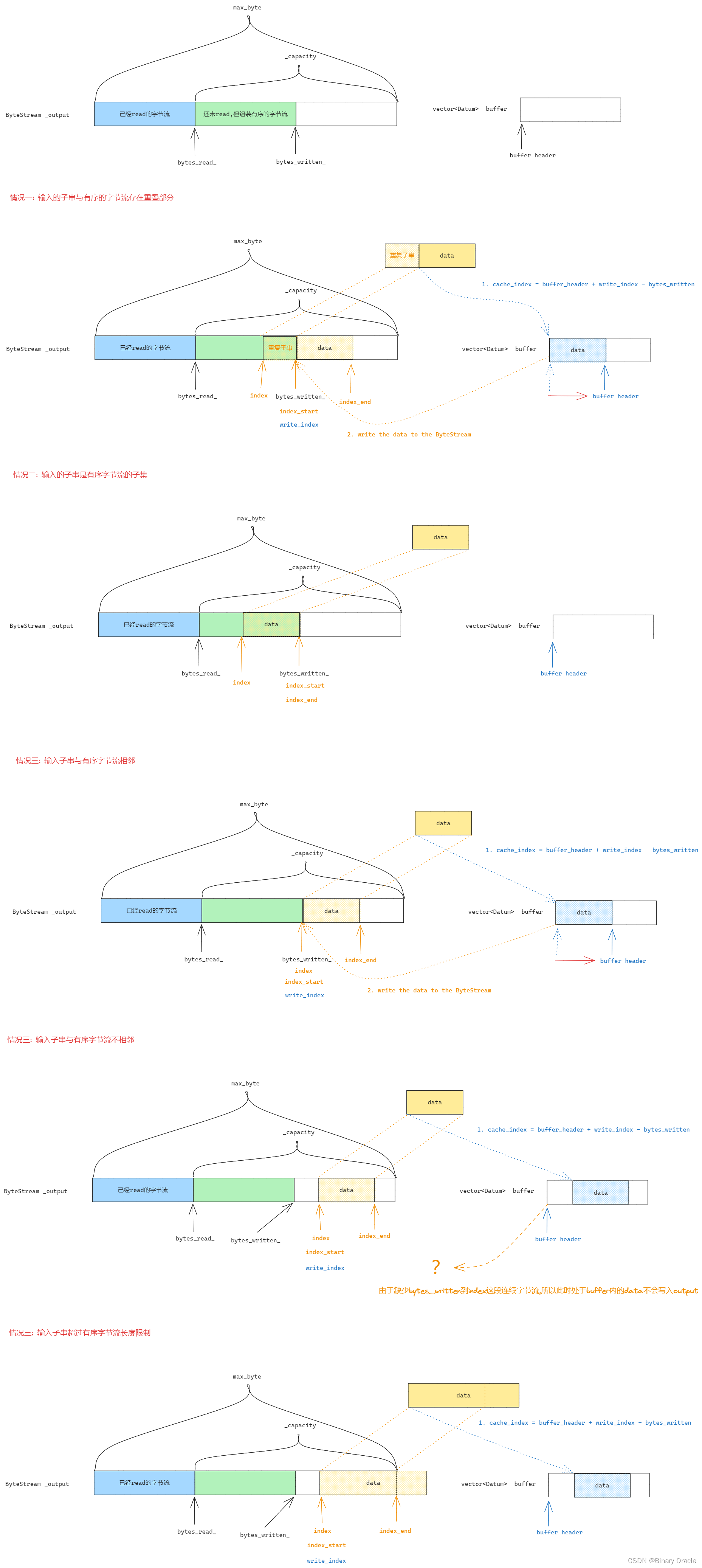
代码可能不太容易理解,但是大家对照下图,把几种可能出现的情况看明白,再回去看代码,相信就不难了:
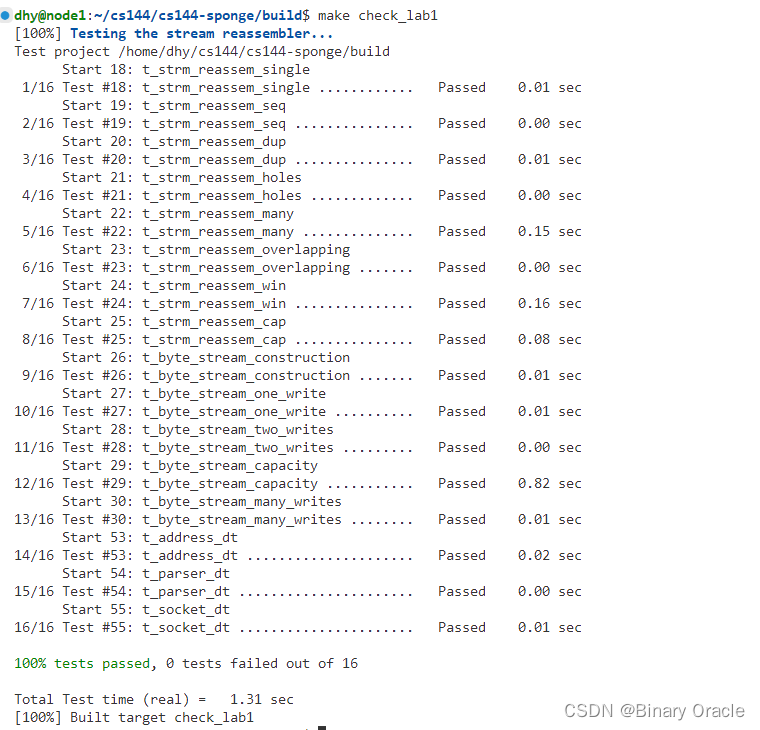
测试代码正确性: