目录
一、线程间共享数据
1.数据共享和条件竞争
2.避免恶性条件竞争
二、用互斥量来保护共享数据
1. 互斥量机制
2.mutex头文件介绍
三、C++中使用互斥量mutex
1. 互斥量mutex使用
2.mutex类成员函数
① 构造函数
② lock()
③ unlock()
④ try_lock()
四、使用std::lock_guard
五、使用std::unique_lock
六、接口间的条件竞争
七、死锁问题
一、线程间共享数据
1.数据共享和条件竞争
如果共享数据是只读的,那么所有线程都会获得相同的数据,因为不会涉及对数据的修改。但是,当一个线程或多个线程去修改共享数据时,需要考虑到共享数据的一致性问题。
当一个线程对共享数据进行修改的同时有其他线程对该共享数据进行读取或修改操作,可能得到的并不是期望的结果,这是常见的错误:条件竞争。
并发中竞争条件的形成,取决于一个以上线程的相对执行顺序,每个线程都抢着完成自己的任务。大多数情况下,即使改变执行顺序,也是良心竞争,其结果可以接受。例如:有两个线程同时执行读取任务,只要完成相应读取任务就可以了,谁先谁后这时的竞争是没有影响的。
恶性条件竞争通常发生于完成对多余一个的数据块的修改时。
2.避免恶性条件竞争
①对数据结构采用某种保护机制,确保只有进行修改的线程才能看到不变量被破坏时的中间状态。从其他访问线程的角度来看,修改不是已经完成了,就是还没开始。(例如:线程A对变量a=0进行+10操作,线程B读到了A线程中a=10,a已经改变,但是A的线程最后把a重新-10,实际对a没有修改。线程B访问到线程A的变量的中间状态)
②对数据结构和不变量的设计进行修改,修改完的结构必须能完成一系列不可分割的变化,也就是保证每个不变量保持稳定的状态,这就是所谓的无锁编程。
③使用事务的方式去处理数据结构的更新。所需的一些数据和读取都存储在事务日志中,然后将之前的操作合为一步,再进行提交。当数据结构被另一个线程修改后,或处理已经重启的情况下,提交就会无法进行,这称作为“软件事务内存”(software transactional memory (STM))。(例如:线程A对变量a的前后两次修改,修改合成一步,当成事务提交,线程B访问时就只能看到a最后的修改状态)
二、用互斥量来保护共享数据
1. 互斥量机制
当访问共享数据前,将数据锁住,在访问结束后,再将数据解锁。线程库需要保证,当一个线程使用特定互斥量锁住共享数据时,其他的线程想要访问锁住的数据,都必须等到之前的线程对数据解锁后,才能进行访问。这就保证了所有线程都能看到共享数据,并不破坏不变量。
2.mutex头文件介绍
C++ 11中与 mutex 相关的类(包括锁类型)和函数都声明在 <mutex> 头文件中,所以如果你需要使用 std::mutex,就必须包含 <mutex> 头文件。
Mutex 系列类(四种)
- std::mutex,最基本的 Mutex 类。
- std::recursive_mutex,递归 Mutex 类。
- std::time_mutex,定时 Mutex 类。
- std::recursive_timed_mutex,定时递归 Mutex 类。
Lock 类(两种)
- std::lock_guard,与 Mutex RAII 相关,方便线程对互斥量上锁。
- std::unique_lock,与 Mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制。
其他类型
- std::once_flag
- std::adopt_lock_t
- std::defer_lock_t
- std::try_to_lock_t
函数
- std::try_lock,尝试同时对多个互斥量上锁。
- std::lock,可以同时对多个互斥量上锁。
- std::call_once,如果多个线程需要同时调用某个函数,call_once 可以保证多个线程对该函数只调用一次。
三、C++中使用互斥量mutex
1. 互斥量mutex使用
C++中通过实例化 std::mutex 创建互斥量实例,通过成员函数 lock()对互斥量上锁,unlock()进行解锁。实践中不推荐直接调用成员函数,调用成员函数意味着,必须在每个函数出口去调用unlock(),也包括异常的情况。
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
class Test
{
private:
std::mutex tmutex;
public:
void add(int& num) {
tmutex.lock();//上锁
++num;
cout << num << endl;
tmutex.unlock();//解锁
}
};
int main()
{
int num = 100;
Test t;
std::thread thread01(&Test::add,&t, std::ref(num));
std::thread thread02(&Test::add,&t, std::ref(num));
thread01.join();
thread02.join();
}2.mutex类成员函数
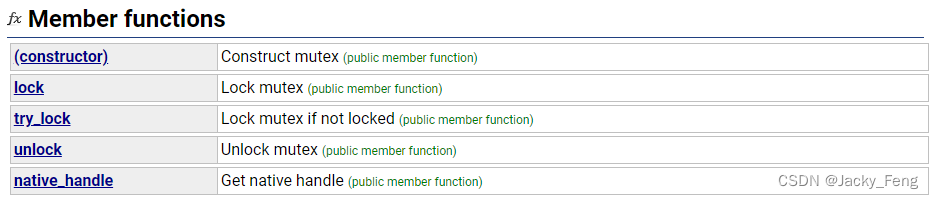
① 构造函数
作用:构造一个互斥量对象。该对象处于未锁定状态。
互斥对象不能被复制/移动(该类型的拷贝构造函数和赋值操作符都被删除)。
② lock()
作用:互斥量上锁。
线程调用该函数会发生下面 3 种情况:
(1)如果互斥锁当前没有被任何线程锁定,则调用线程将其锁定(从此时开始,直到调用其成员unlock,该线程拥有互斥锁)。
(2)如果互斥锁当前被另一个线程锁定,则调用线程的执行将被阻塞,直到被另一个线程解锁(其他未锁定的线程继续执行)。(3)如果互斥锁当前被调用该函数的同一个线程锁定,则会产生死锁(带有未定义的行为)。
③ unlock()
作用:互斥量解锁,释放互斥量的所有权。
如果其他线程在试图锁定同一个互斥量时被阻塞,其中一个线程将获得该互斥锁的所有权并继续执行。
互斥量的所有上锁和解锁操作都遵循单一的总顺序,对同一对象的上锁操作和解锁操作之间是同步的。
如果互斥锁当前未被调用线程锁定,则会导致未定义的行为。
④ try_lock()
作用:尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞。
线程调用该函数也会出现3 种情况:
(1)如果互斥量当前没有被任何线程锁定,则调用线程将其锁定(从此时开始,直到调用其成员unlock,该线程拥有互斥锁)。
(2)如果互斥锁当前被另一个线程锁定,则函数失败并返回false,但不会阻塞(调用线程继续执行)。
(3)如果互斥锁当前被调用该函数的同一个线程锁定,则会产生死锁(带有未定义的行为)。
四、使用std::lock_guard
C++标准库为互斥量提供了一个RAII语法的模板类 std::lock_guard,它通过让互斥对象始终处于锁定状态来管理它的对象。
在构造时,互斥对象被调用线程锁定,在析构销毁时,互斥对象被解锁。它是特别适用于具有自动持续时间直到其上下文结束的对象。通过这种方式,它保证在抛出异常时正确解锁互斥对象。
但是请注意,lock_guard对象并不以任何方式管理互斥对象的生命周期:互斥对象的持续时间应该至少延长到锁定它的lock_guard被销毁为止。
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
class Test
{
private:
std::mutex tmutex;
public:
void add(int& num) {
lock_guard<std::mutex> guard(tmutex);//构造时上锁
++num;
cout << num << endl;
}//析构时解锁
};
int main()
{
int num = 100;
Test t;
std::thread thread01(&Test::add,&t, std::ref(num));
std::thread thread02(&Test::add,&t, std::ref(num));
thread01.join();
thread02.join();
}定义lock_guard的时候调用构造函数加锁,大括号结束调用析构函数解锁。
【注意】在使用互斥量来保护数据时,要注意检查指针和引用。切勿将受保护数据的指针或引用传递到互斥锁作用域之外,无论是函数返回值,还是存储在外部可见内存,亦或是以参数的形式传递到用户提供的函数中去。只要没有成员函数通过返回值或者输出参数的形式,向其调用者返回指向受保护数据的指针或引用,数据就是安全的。
缺陷:在定义lock_guard的地方会调用构造函数加锁,在离开定义域的话lock_guard就会被销毁,调用析构函数解锁。这就产生了一个问题,如果这个定义域范围很大的话,那么锁的粒度就很大,很大程序上会影响效率。
所以为了解决lock_guard锁的粒度过大的原因,unique_lock就出现了。
五、使用std::unique_lock
unique_lock会在这个构造函数加锁,然后可以利用unique.unlock()来解锁,所以当你觉得锁的粒度太多的时候,可以利用这个来中途解锁,而析构的时候会判断当前锁的状态来决定是否解锁,如果当前状态已经是解锁状态了,那么就不会再次解锁,而如果当前状态是加锁状态,就会自动调用unique.unlock()来解锁。而lock_guard在析构的时候一定会解锁,也没有中途解锁的功能。
方便肯定是有代价的,unique_lock内部会维护一个锁的状态,所以在效率上肯定会比lock_guard慢。
unique_lock是管理的互斥对象在锁定和解锁两种状态下都具有唯一的所有权。
在构造(或通过对其移动赋值)时,对象获得一个互斥对象,对其锁定和解锁操作。
这个类保证销毁时的状态为解锁(即使没有显式调用)。因此,它作为具有自动持续时间的对象特别有用,因为它保证在抛出异常时正确解锁互斥对象。
请注意,unique_lock对象并不以任何方式管理互斥对象的生命周期:互斥对象的持续时间至少应该延长到管理它的unique_lock被销毁为止。
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::unique_lock
void print_block (int n, char c) {
std::unique_lock<std::mutex> lck (mtx);
for (int i=0; i<n; ++i) {
std::cout << c;
}
std::cout << '\n';
}
int main ()
{
std::thread th1 (print_block,50,'*');
std::thread th2 (print_block,50,'$');
th1.join();
th2.join();
return 0;
}六、接口间的条件竞争
因为使用了互斥量或其他机制保护了共享数据,就不必再为条件竞争所担忧吗?
并不是,你依旧需要确定数据是否受到了保护。例如:
构建一个类似于std::stack结构的栈,除了构造函数和swap()以外,需要对std::stack提供五个操作:push()一个新元素进栈,pop()一个元素出栈,top()查看栈顶元素,empty()判断栈是否是空栈,size()了解栈中有多少个元素。即使修改了top(),使其返回一个拷贝而非引用,对内部数据使用一个互斥量进行保护,不过这个接口仍存在条件竞争。这个问题不仅存在于基于互斥量实现的接口中,在无锁实现的接口中,条件竞争依旧会产生。这是接口的问题,与其实现方式无关。
七、死锁问题
死锁是指多个进程循环等待彼此占有的资源而无限期的僵持等待下去的局面。(一对线程需要对他们所有的互斥量做一些操作,其中每个线程都有一个互斥量,且等待另一个解锁。这样没有线程能工作,因为他们都在等待对方释放互斥量。这种情况就是死锁,它的最大问题就是由两个或两个以上的互斥量来锁定一个操作。)
死锁产生的四个条件:
- 互斥性:线程对资源的占有是排他性的,一个资源只能被一个线程占有,直到释放。
- 请求和保持条件:一个线程对请求被占有资源发生阻塞时,对已经获得的资源不释放。
- 非抢占:一个线程在释放资源之前,其他的线程无法剥夺占用。
- 循环等待:发生死锁时,线程进入死循环,永久阻塞。
避免死锁的方法:
(1)避免嵌套锁
一个线程已获得一个锁时,再别去获取第二个。因为每个线程只持有一个锁,锁上就不会产生死锁。即使互斥锁造成死锁的最常见原因,也可能会在其他方面受到死锁的困扰(比如:线程间的互相等待)。当你需要获取多个锁,使用一个std::lock来做这件事(对获取锁的操作上锁),避免产生死锁。
(待完善)