前言
这是一个我个人在工作和学习中使用过以数据集的一部分,有语义分割,目标识别,人像抠图等几个大类,这只是我用过数据集中的一部分,这些数据集有小一部分是来源自网络,很大一部分都是我自己收集。
一、语义分割
1.书本
这个数据集标注了书本的中线与边缘的数据集,数据是用labelme标注的,数据集有2500张图像,是用来训练文档扫描的边缘检测与中线识别的。之前用ENet训练过,效果还蛮可以的。数据集标注样例如下:


2.皮肤
2.1 皱纹和眼袋(164张图像)
数据集标注了皱纹和眼袋的位置,数据集有转换好的mask图,可用于医美的皮肤皱纹检测与眼袋检测分割。训练方法和效果可参考我之前的博客:
基于语义分割实现人脸图像的皱纹检测定位与分割_皱纹检测算法_知来者逆的博客-CSDN博客

2.2 痘痘、红斑、雀斑(221张)
数据集 包含了痘痘、红斑、雀斑这几种标注,可用来训练实实例分割,每个目标都有唯一的ID。
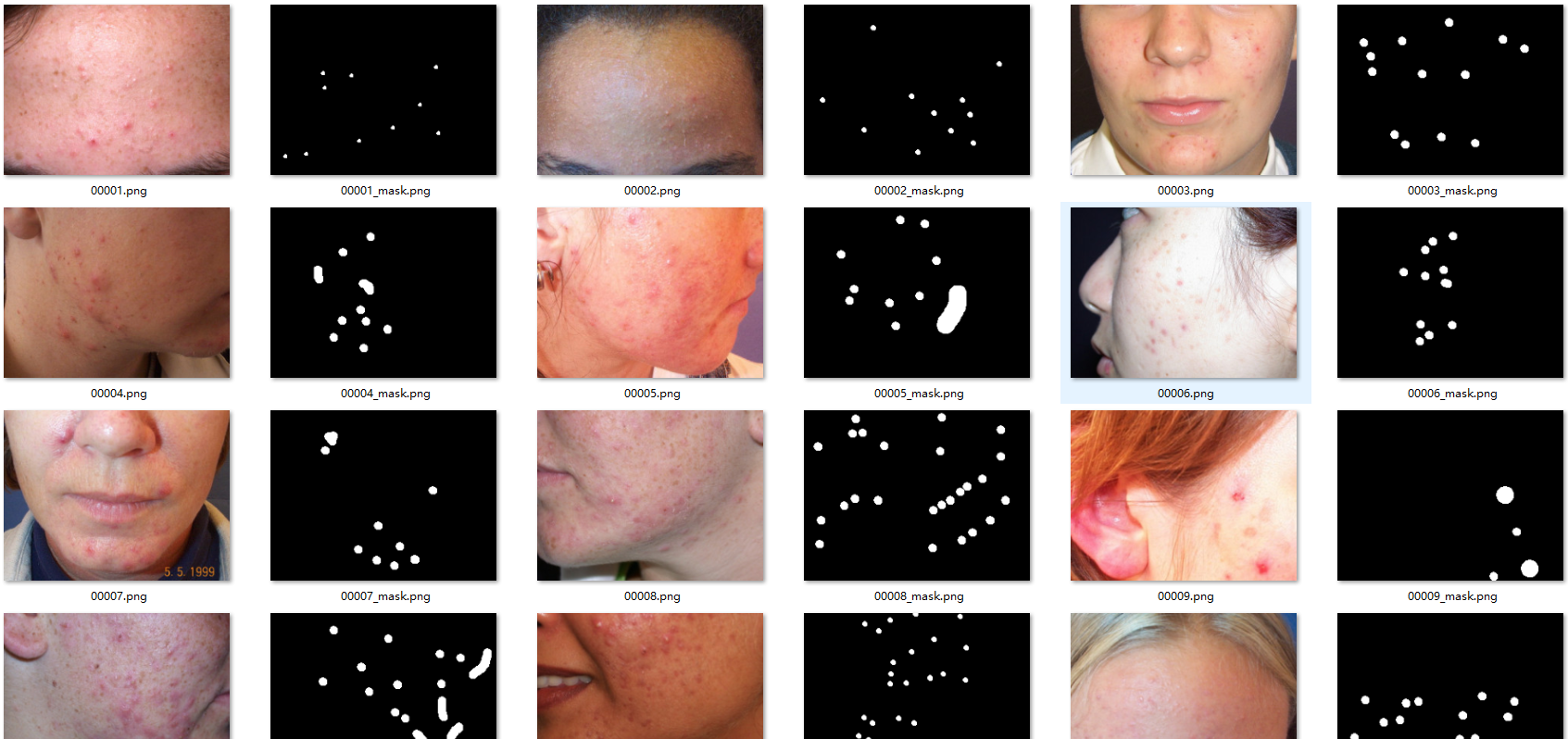
痘痘
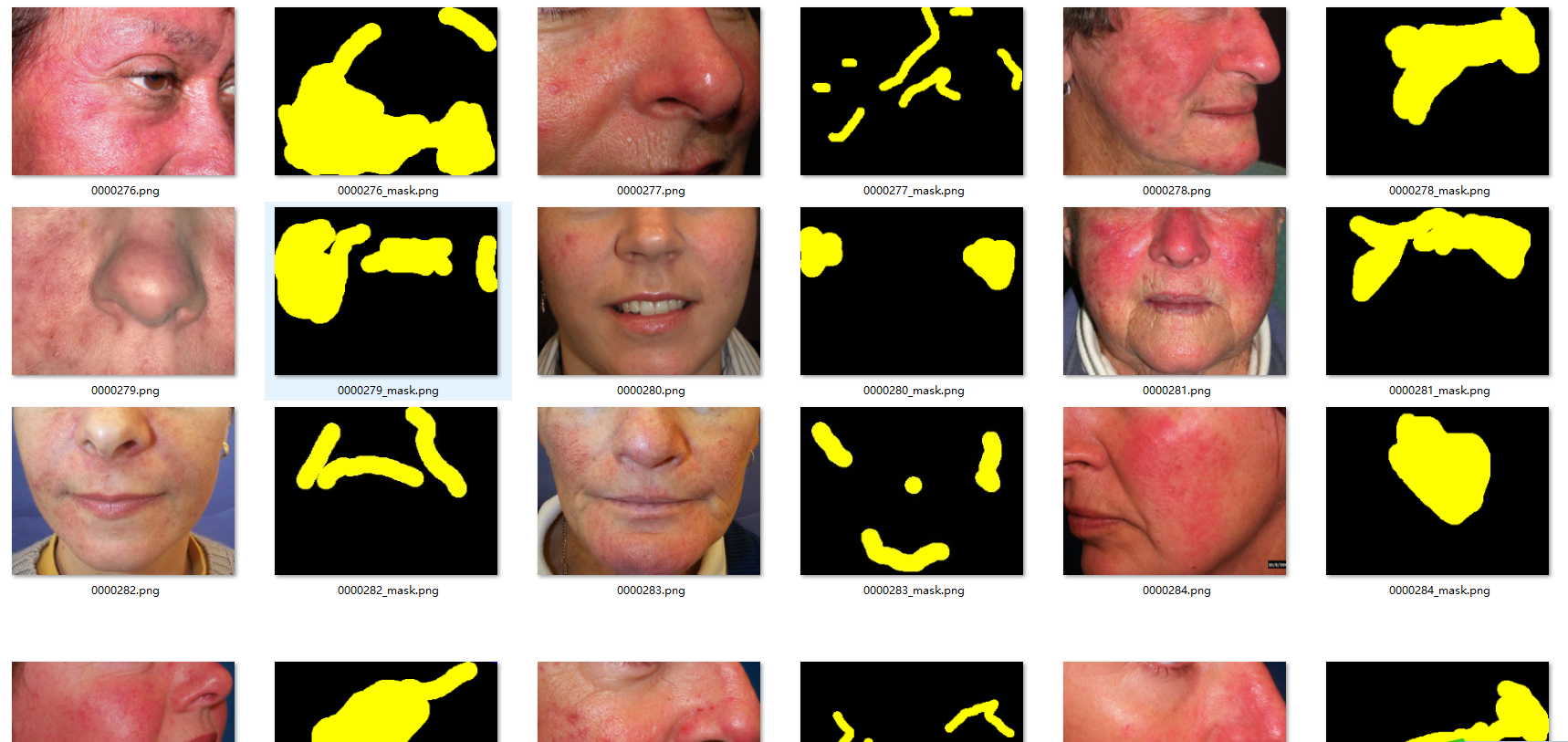 红斑
红斑
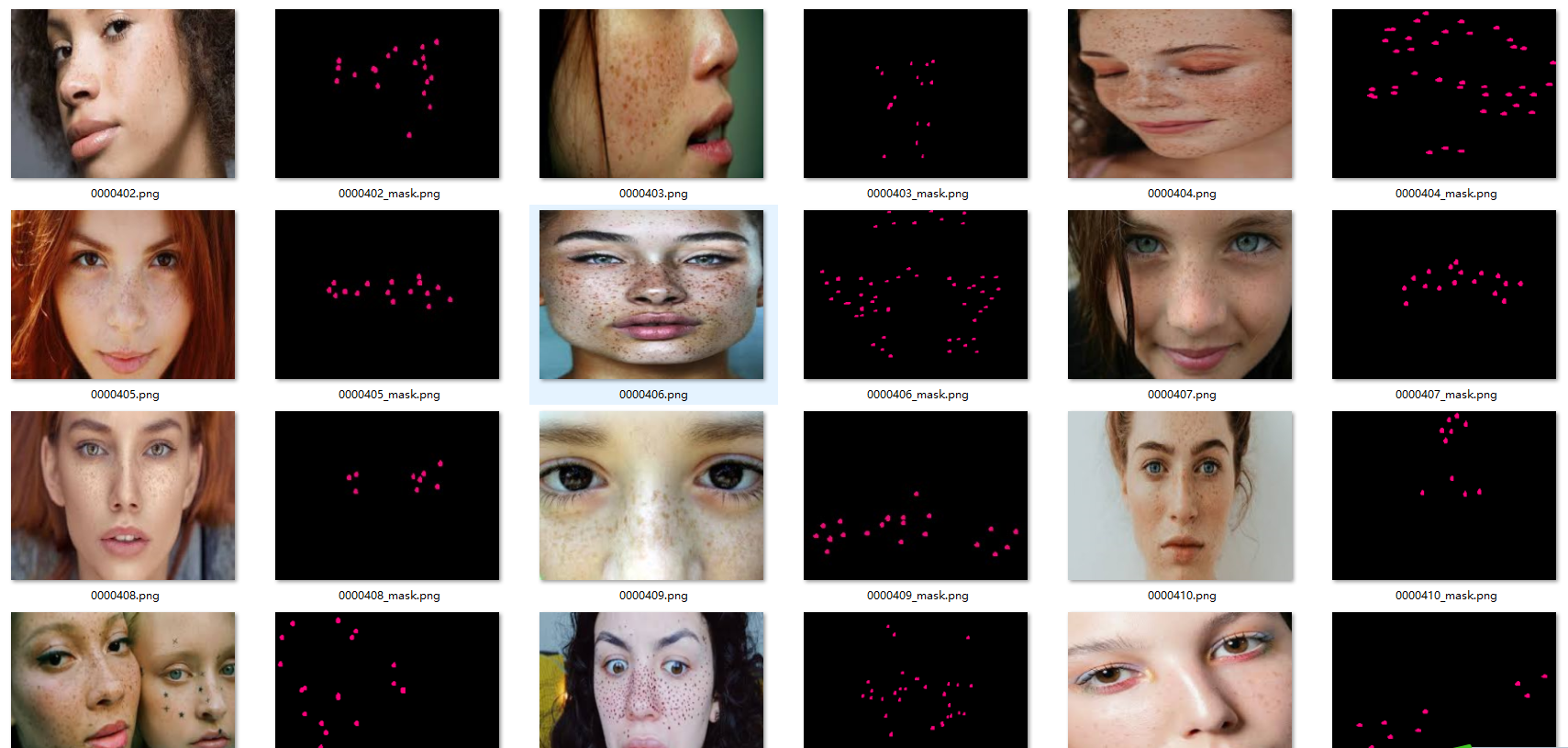 雀斑
雀斑
2.3 毛孔
毛孔的数据集里面只有毛孔,只能用于训练语义分割。

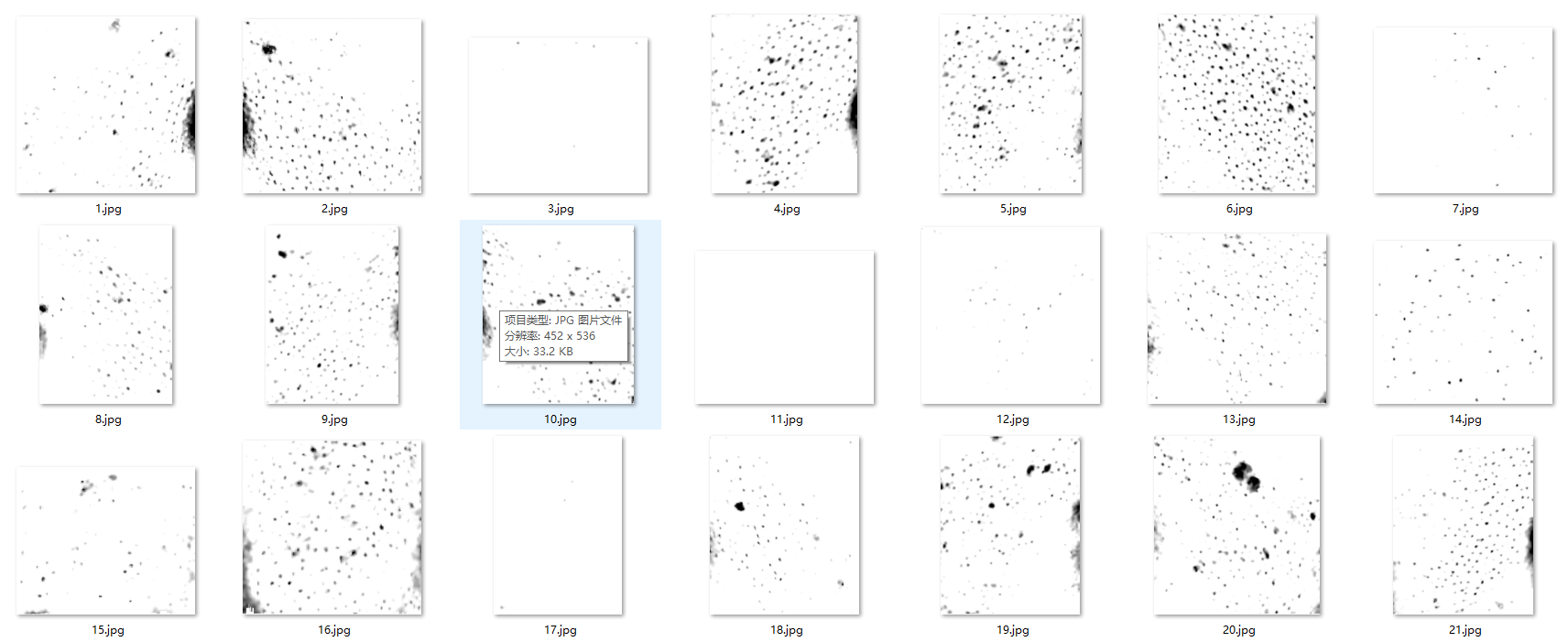
3. 拍照文档清晰二值
数据集是用于文档拍照清晰二值化,在某些APP里,这个功能叫省墨模式,样本是用来训练该滤镜的,训练的效果可以参与我之前的博客:
使用深度学习解决拍照文档复杂背景二值化问题_背景较深的图像怎么二值化_知来者逆的博客-CSDN博客


4.拍照文档阴影检测分割
数据集是用labelme标注的,标注了拍照文档的阴影部分,用来做拍照文档扫描的阴影检测去祛除用的,总共有1000张图像。


二、目标识别
1.智慧城市
1.1 手机
标注的是手机,数据格式是xml和转过的yolo的txt格式,有2000张。

1.2 安全帽
数据标注了戴安全的人头和不带安全帽的人头,数据格式是xml和转过的yolo的txt格式,总共有7800张图像。训练效果可参考我之前的博客:
安全帽佩戴检测——从数据处理、训练数据到模型部署落地(带有数据集、训练代码,可使用GPU的C++模型部署代码)_c++ ipc检测安全帽_知来者逆的博客-CSDN博客

1.3 烟火
数据标注了明火和起烟两个标签,数据格式是xml和转过的yolo的txt格式,总共有7600张图像。训练效果可参考我之前的博客:
基于Yolov5的烟火检测——模型训练与C++实现部署_yolov5 c++部署_知来者逆的博客-CSDN博客

1.4 抽烟
数据标注了人头和抽烟两个标签,数据格式是xml和转过的yolo的txt格式,总共有4800张图像。
1.5 文档
文档的目标检测检测了两个目标,双开的书与单张的文档。标注工具是labelImg,数据格式是xml和yolo的txt。
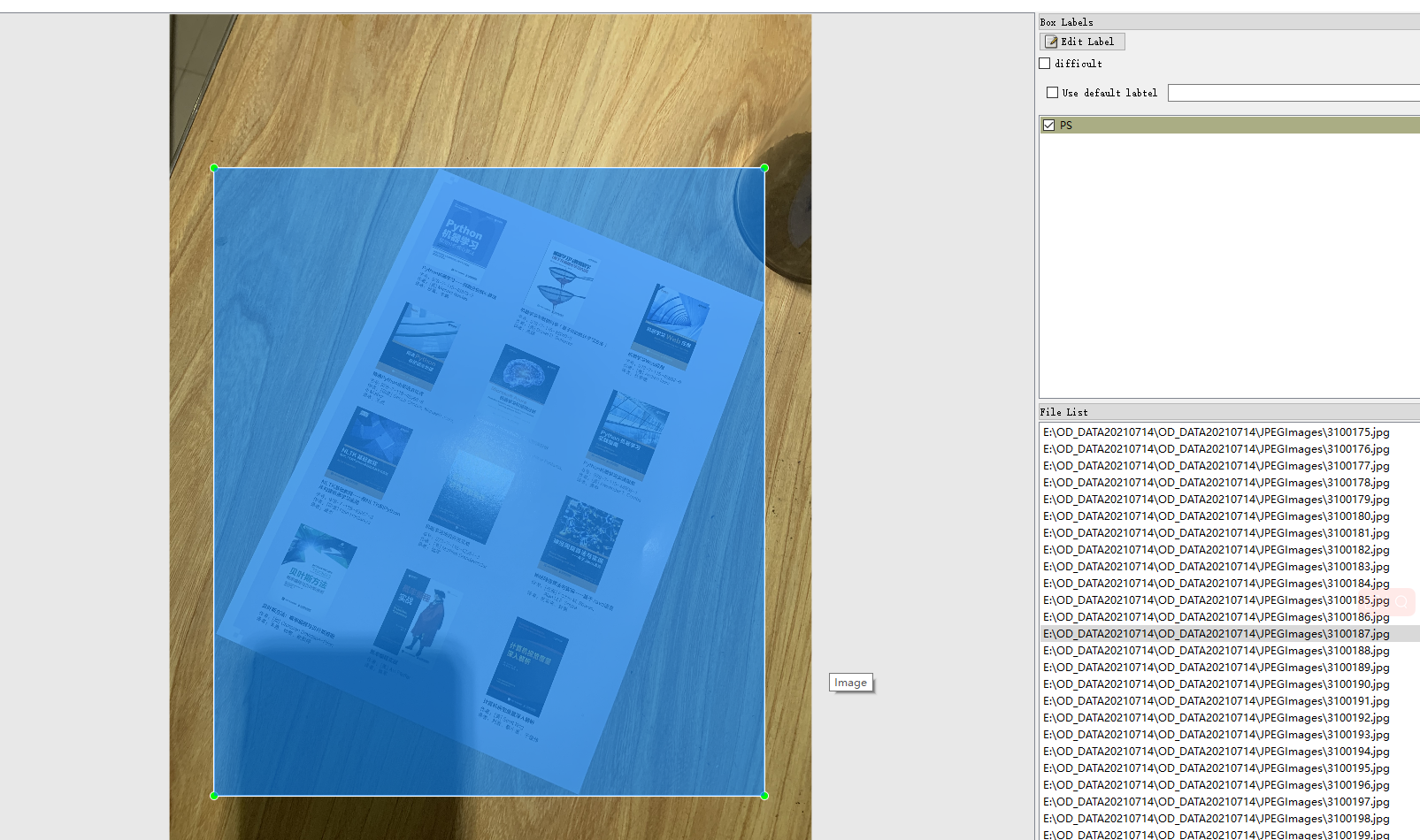
单张的文档
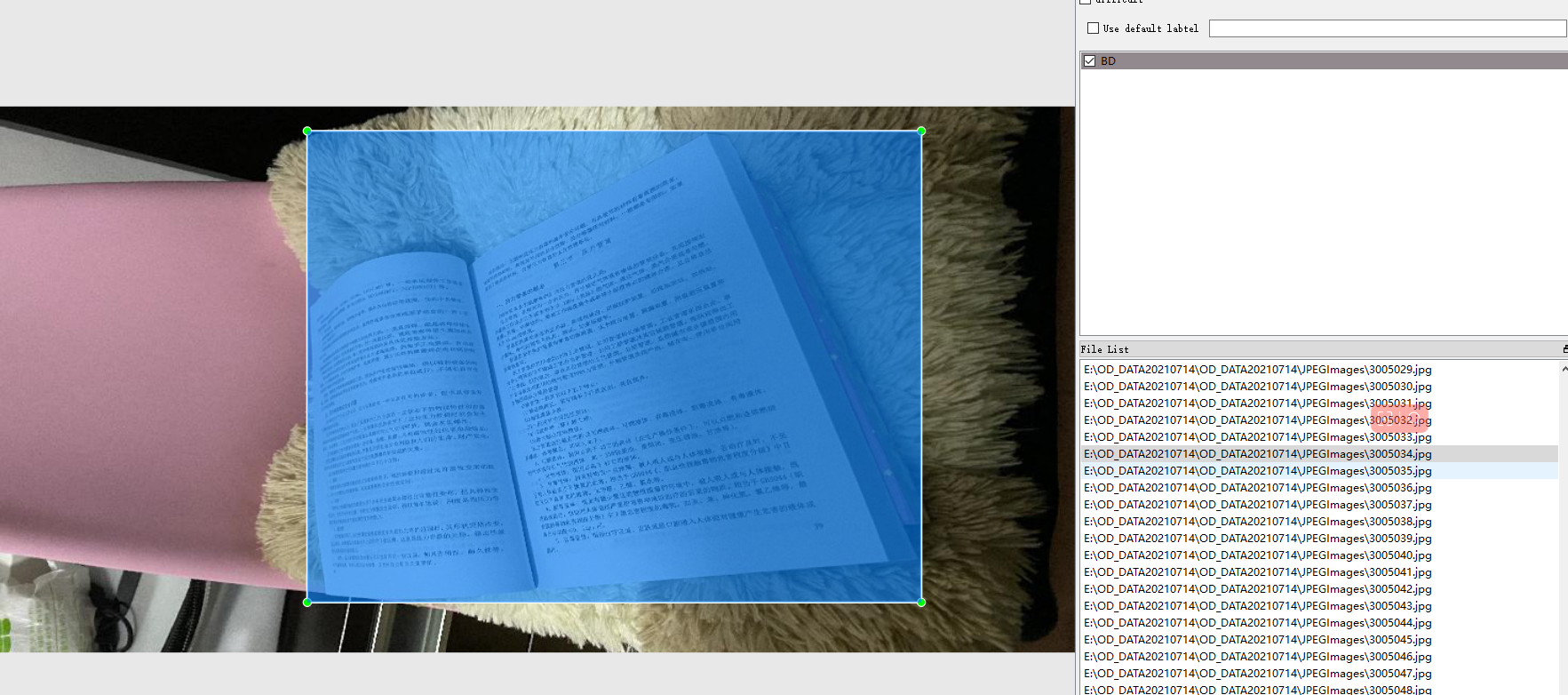
双张的书本
1.6 身份证
数据集包含了身份证正面和身份背面,身份证正面标注了正面和头像,身份证背面标注了背面和国徽,总共四个目标。标注工具是labelImg,数据格式是xml和yolo的txt。训练效果可以参考我之后的博客:
证件拍照扫描——基于C++与深度神经网络实现证件识别扫描并1比1还原证件到A4纸上_知来者逆的博客-CSDN博客


1.7 银行卡
数据集包含了银行正面和银行背面,银联logo,IC芯片,总共四个目标。标注工具是labelImg,数据格式是xml和yolo的txt。


1.8 护照
护照标注了护照翻开的第一页和人物头像,总共两个目标。标注工具是labelImg,数据格式是xml和yolo的txt。
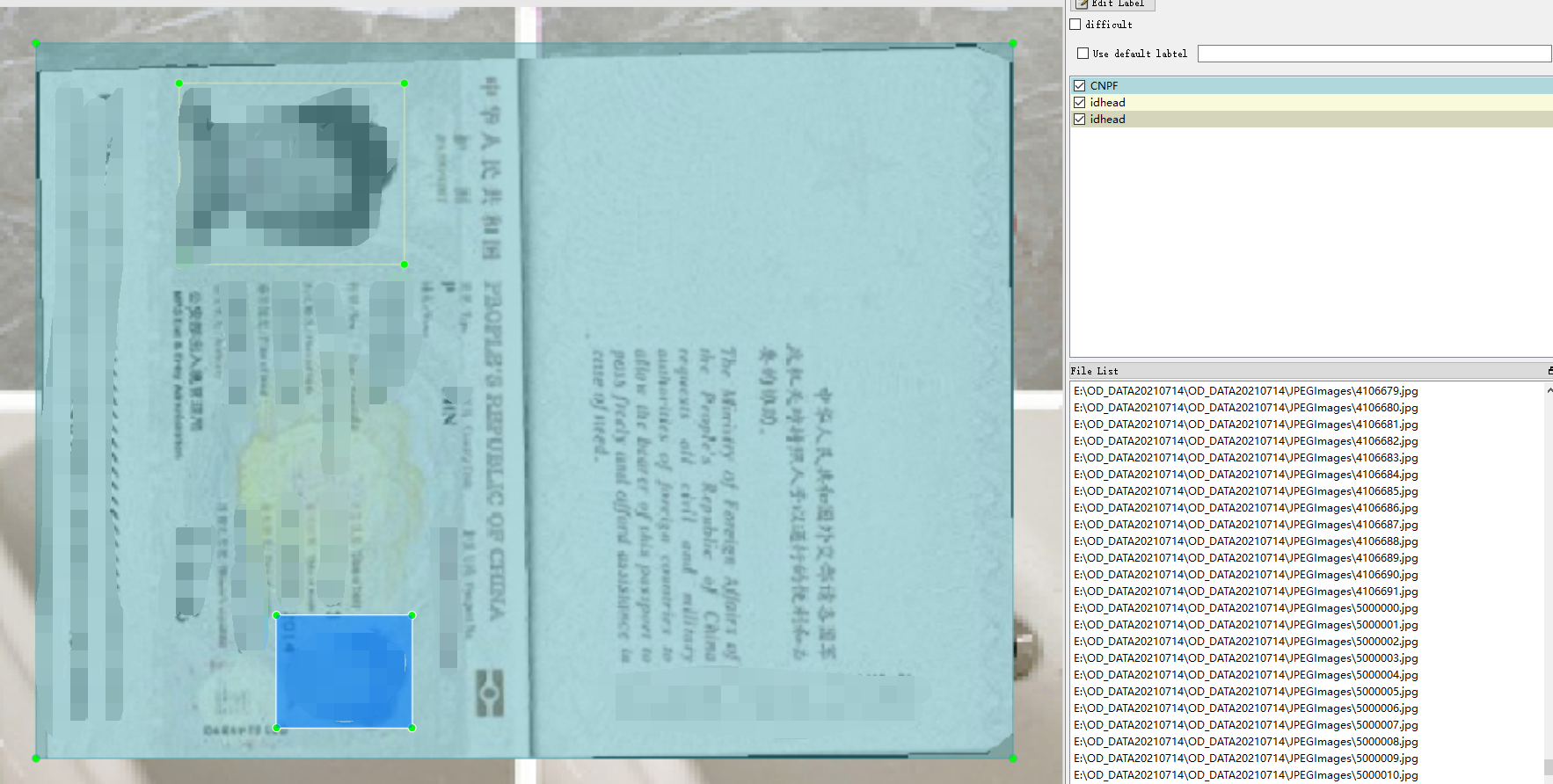
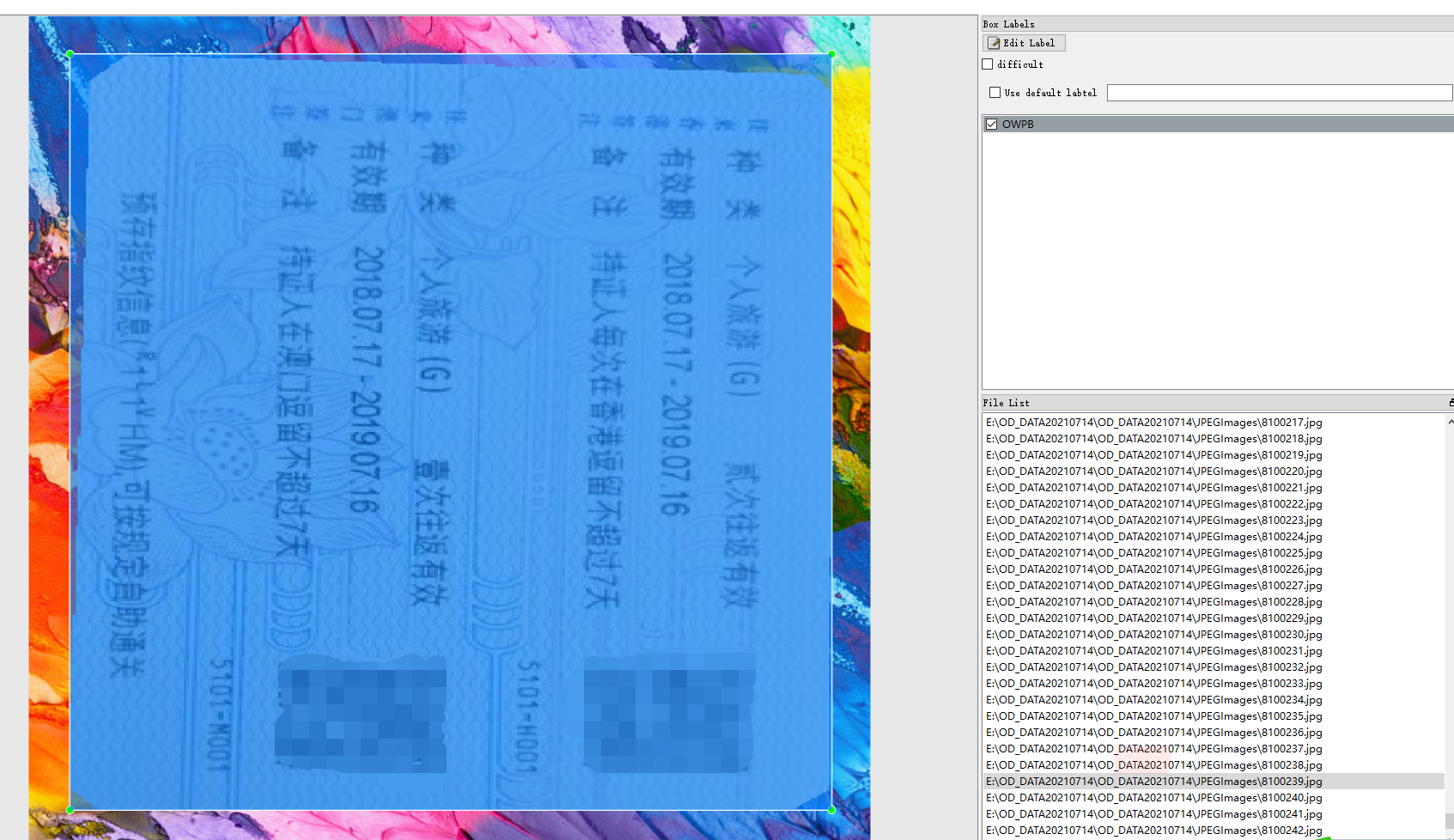
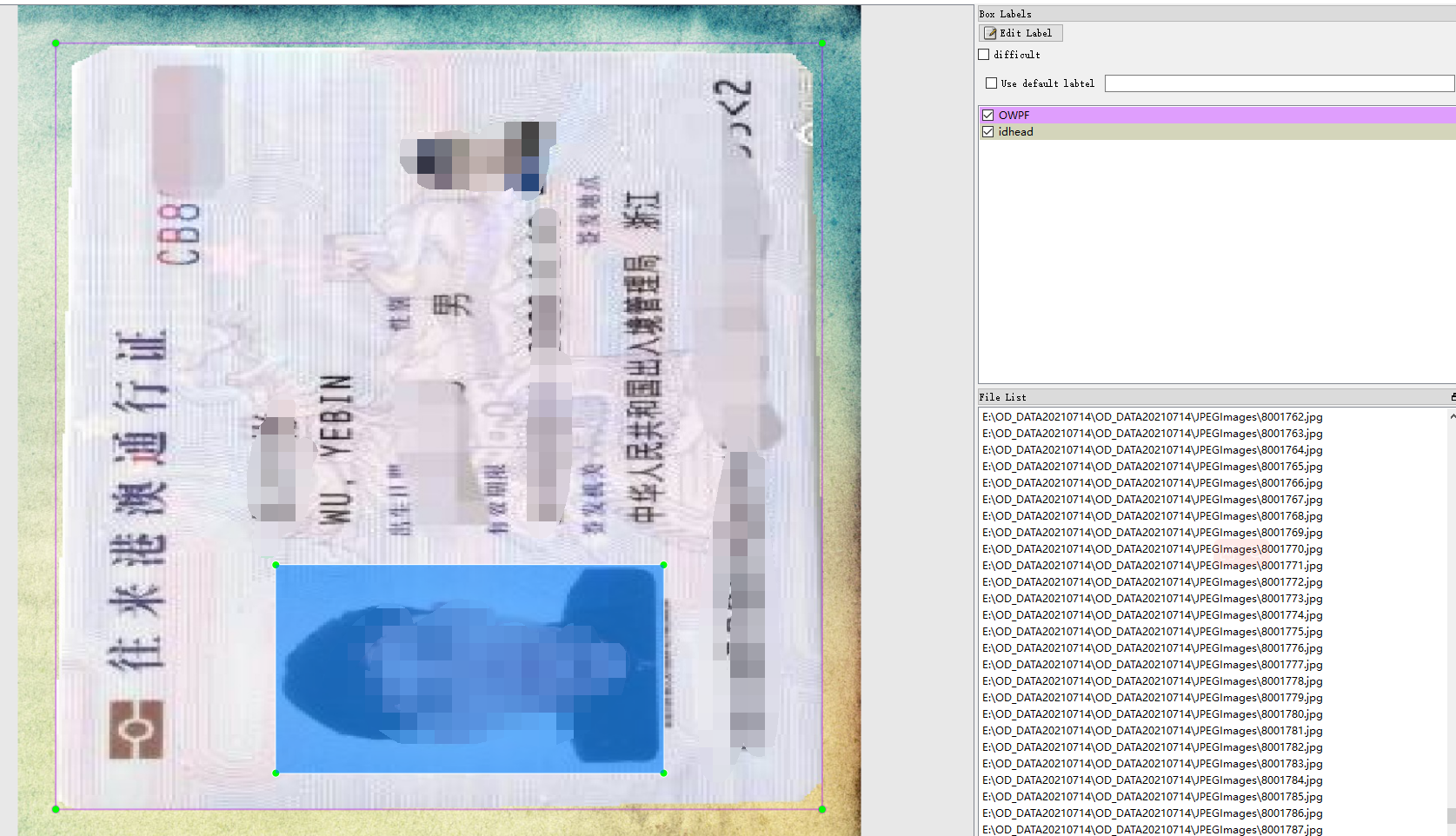
1.9 港澳通行证
港澳通行证标注了护正面、头像、背面,总共三个目标。标注工具是labelImg,数据格式是xml和yolo的txt。
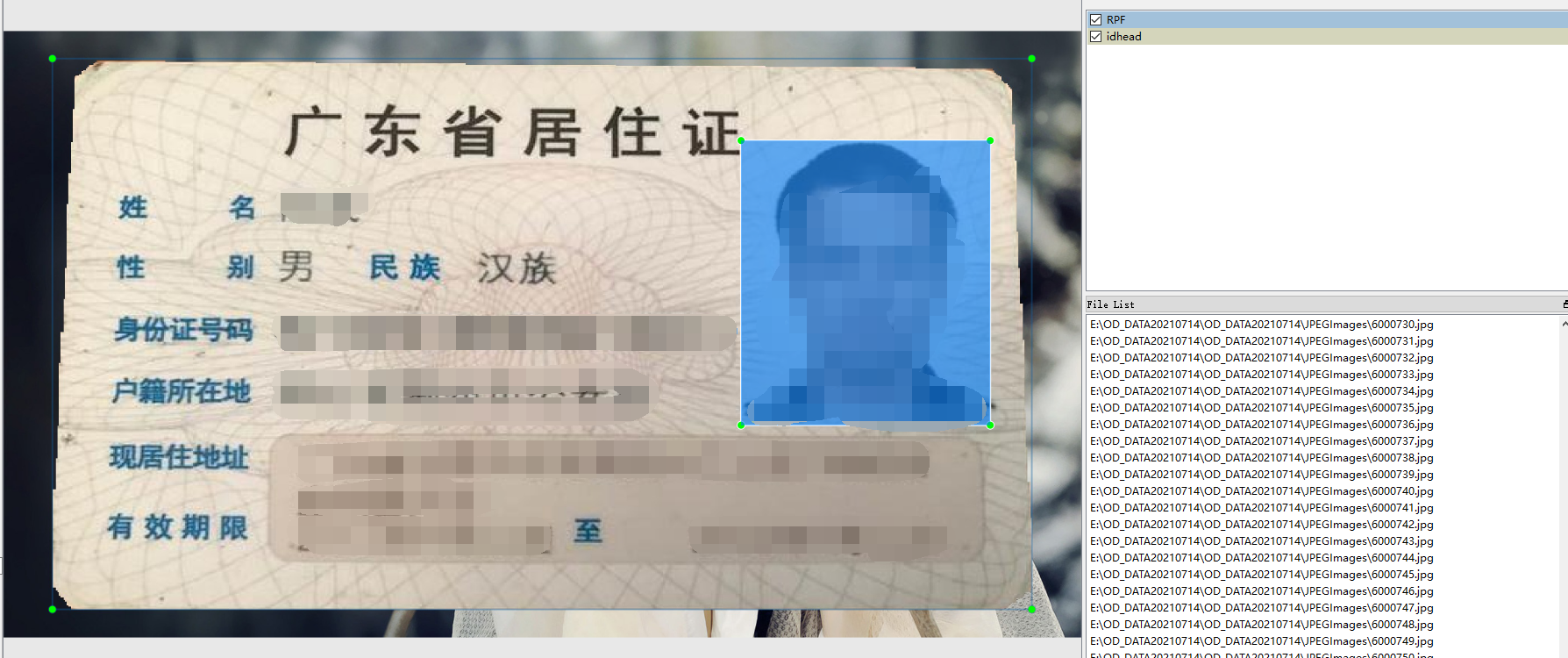
1.10 居住证
居住证标注了护正面、头像,总共两个目标。标注工具是labelImg,数据格式是xml和yolo的txt。
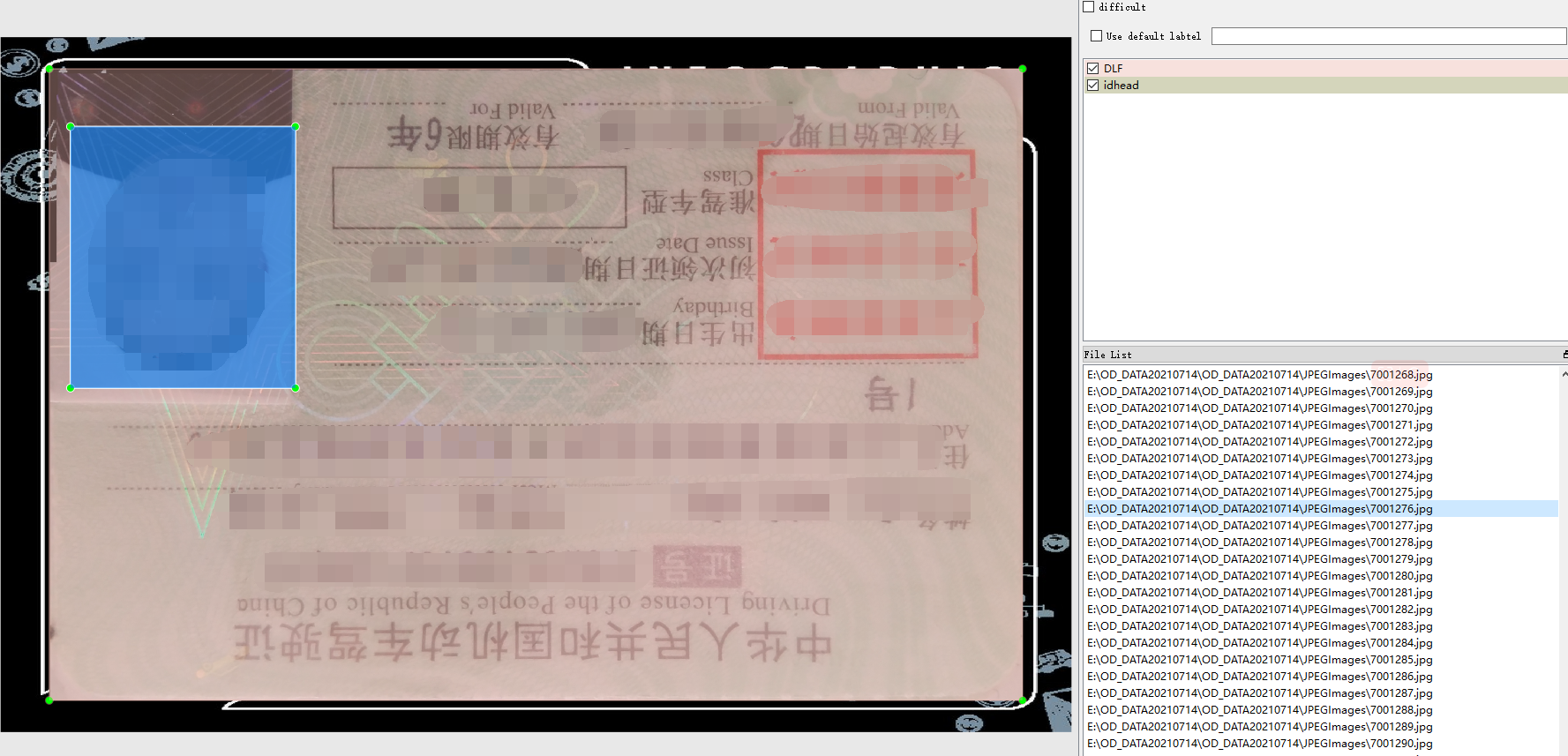
1.11 驾驶证
驾驶证标注了护正面、头像,总共两个目标。标注工具是labelImg,数据格式是xml和yolo的txt。
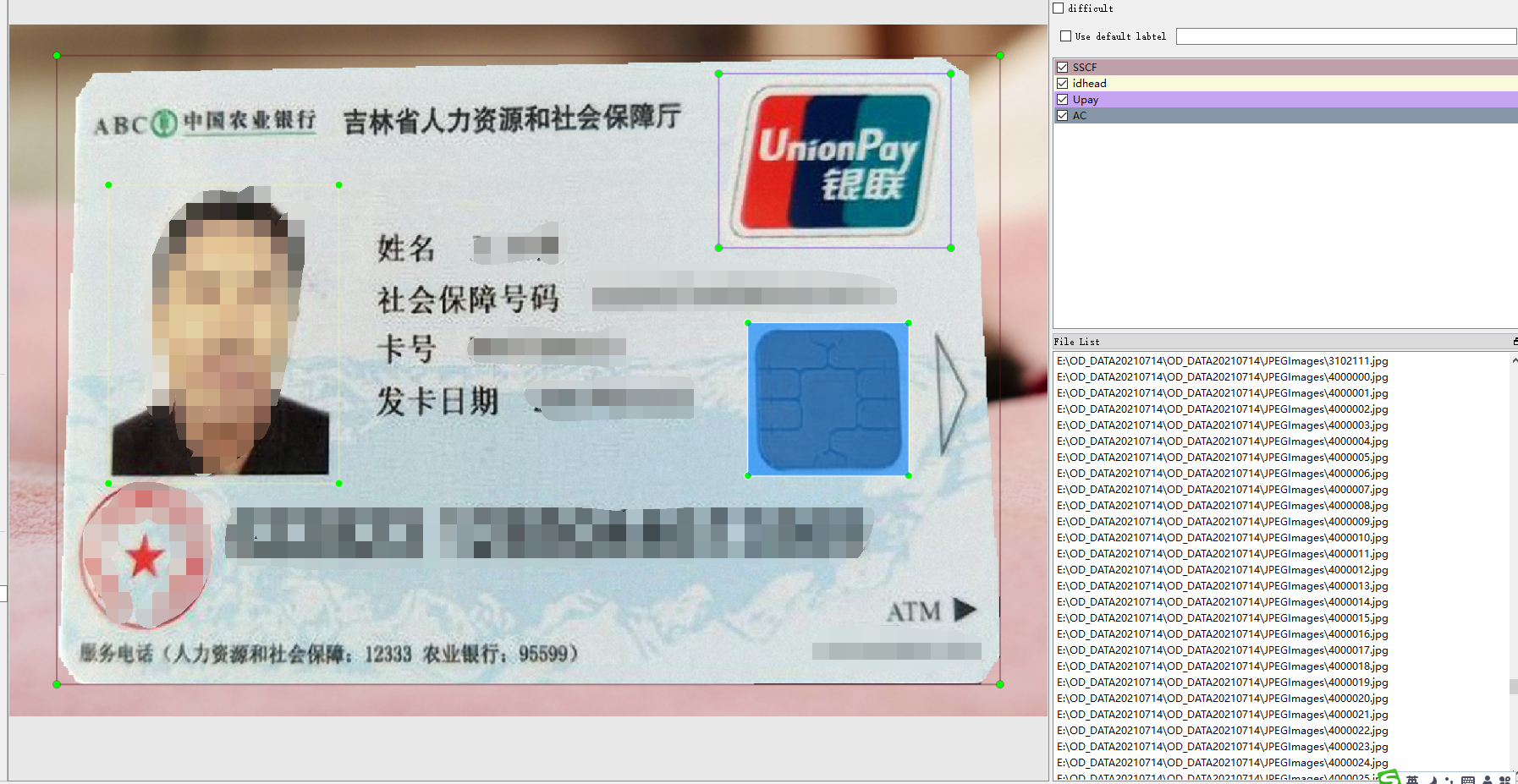
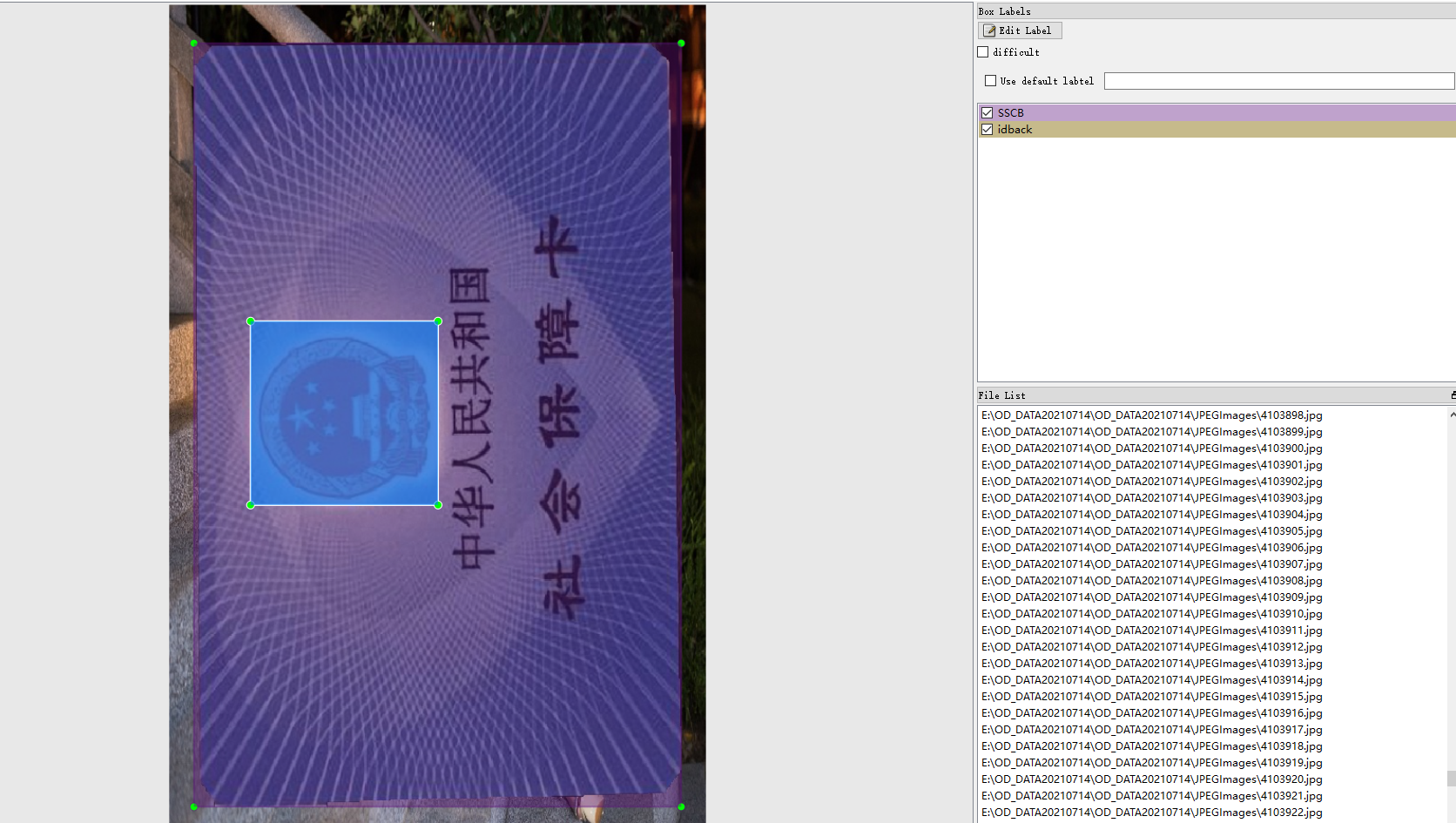
1.12 社保卡
社保卡标注了头像,银联logo,IC卡,社保卡正面,社保卡反面,国徽总共五个目标。标注工具是labelImg,数据格式是xml和yolo的txt。
三、抠图
1.人像抠图
人像抠图有半身抠图,大概5万张左右,格式是mask图,这个是之前用于智能证件照。

待续更新................................