目录
一、前言
二、总线基础知识概述
(1)、总线在芯片中的角色
(2)、总线的类型
(3)、总线的指标
(4)、AHB和APB
三、总线框架结构
(1)、结构类型
(2)、总线模块
(3)、总线交互
四、总结
一、前言
本篇介绍STM32芯片内部的总线系统结构,嵌入式芯片内部的总线和计算机总线类似,先来看一下通常定义下计算机总线定义,即计算机的总线是一种内部结构,它是cpu、内存、输入、输出设备传递信息的公用通道,主机的各个部件通过总线相连接,外部设备通过相应的接口电路再与总线相连接,从而形成了计算机硬件系统。在计算机系统中,各个部件之间传送信息的公共通路叫总线,微型计算机是以总线结构来连接各个功能部件的。
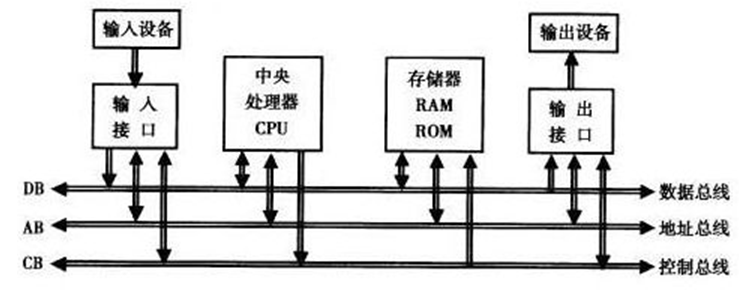
图1 计算机总线结构
计算机设备和设备之间传输信息的公共数据通道。总线是连接计算机硬件系统内多种设备的通信线路,它的一个重要特征是由总线上的所有设备共享,可以将计算机系统内的多种设备连接到总线上。如果是某两个设备或设备之间专用的信号连线,就不能称之为总线。
因此STM32这类嵌入式芯片的总线可概括理解为:是各种信号线的集合,总线可以划分为数据总线、地址总线和控制总线,分别用来传输数据、数据地址和控制信号。
二、总线基础知识概述
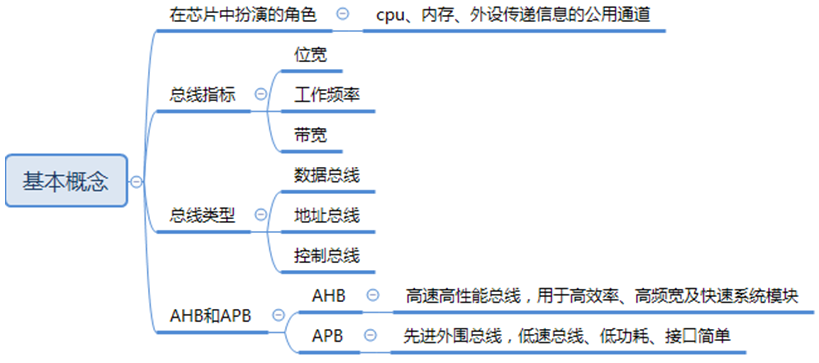
图2 总线基础知识
(1)、总线在芯片中的角色
ARM公司负责提供设计内核,而其他外设则为芯片商设计并使用,ARM收取其专利费用而不参与其他经济活动,半导体芯片厂商拿到内核授权后,根据产品需求,添加各类组件,生产芯片售卖。图3为STM32的组成示意图,其中Cortex-M3内核、调试系统都是ARM公司设计,内部总线、外设、存储、时钟复位等都由ST公司开发。由图3中可以明显看出总线是cpu、内存、外设传递信息的公用通道,芯片上的各个部件通过总线相连接。
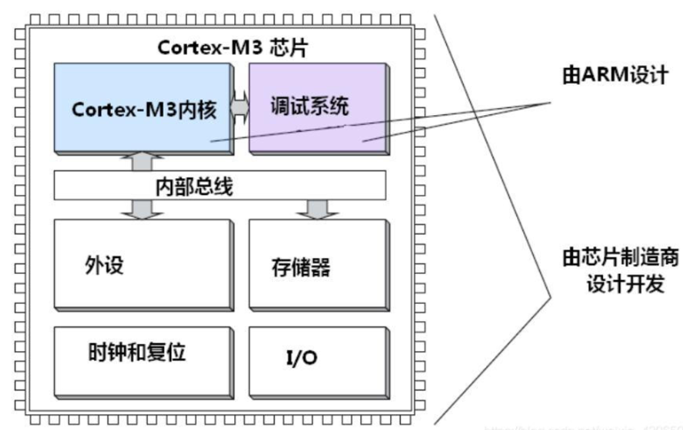
图3 STM32芯片简要结构图
(2)、总线的类型
A、数据总线DB用来传送数据信息,是双向的。CPU既可通过DB从内存或输入设备读入数据,又可通过DB将内部数据送至内存或输出设备。DB的宽度决定了CPU和计算机其他设备之间每次交换数据的位数。数据总线的位数是微型计算机的一个重要指标,通常与微处理的字长相一致。需要指出的是,数据的含义是广义的,它可以是真正的数据,也可以是指令代码或状态信息,有时甚至是一个控制信息,因此,在实际工作中,数据总线上传送的并不一定仅仅是真正意义上的数据。
B、地址总线AB用于传送CPU发出的地址信息,是单向的。传送地址信息的目的是指明与CPU交换信息的内存单元或I/O设备。存储器是按地址访问的,所以每个存储单元都有一个固定地址,要访问1MB存储器中的任一单元,需要给出1M个地址,即需要20位地址(2^20=1M)。一般来说,若地址总线为n位,则可寻址空间为2^n字节。因此,地址总线的宽度决定了CPU 的最大寻址能力。
C、控制总线CB用来传送控制信号、时序信号和状态信息等,是双向的。其中有的是CPU向内存或外部设备发出的信息,如读/写信号,片选信号、中断响应信号等;有的是内存或外部设备向CPU发出的信息,中断申请信号、复位信号、总线请求信号、设备就绪信号等。显然,CB中的每一条线的信息传送方向是一定的、单向的,但作为一个整体则是双向的。所以,凡涉及到控制总线CB,均是以双向线表示。
(3)、总线的指标
A、总线的位宽
总线的位宽指的是总线能同时传送的二进制数据的位数,或数据总线的位数,即32位、64位等总线宽度的概念。总线的位宽越宽,每秒钟数据传输率越大,总线的带宽越宽。
B、总线的工作频率
总线的工作时钟频率以MHZ为单位,工作频率越高,总线工作速度越快,总线带宽越宽。
C、总线的带宽(总线数据传输速率)
总线的带宽指的是单位时间内总线上传送的数据量,即每秒钟传送MB的最大稳态数据传输率 。与总线密切相关的两个因素是总线的位宽和总线的工作频率,它们之间的关系:
总线的带宽=总线的工作频率*总线的位宽/8
或者 总线的带宽=(总线的位宽/8)/总线周期
(4)、AHB和APB
AMBA(Advanced Microprocessor Bus Architecture)是ARM公司提出的一种开放性的SoC总线标准,现在已经广泛的应用于RISC的内核上了。AMBA定义了一种多总线系统(multilevel busing system),包括系统总线和等级稍低的外设总线。 AMBA支持32位、64位、128位的数据总线,和32位的地址总线,同时支持byte和half-word设计。 它定义了两种总线:
AHB(Advanced High-performance Bus)先进的高性能总线,也叫做ASB(Advanced System Bus)。APB(Advanced peripheral Bus)先进的外设总线 AHB和ASB其实是一个东西,是高速总线, AHB总线的强大之处在于它可以将微控制器(CPU)、高带宽的片上RAM、高带宽的外部存储器接口、DMA总线、各种拥有AHB接口的控制器等等连接起来构成一个独立的完整的SOC系统,不仅如此,还可以通过AHB-APB桥来连接APB总线系统。AHB可以成为一个完整独立的SOC芯片的骨架。
APB是低速总线,主要负责外设接口 ,低速且低功率的外围设备,用于低带宽的周边外设之间的连接,例如UART、SPI等,可针对外围设备作功率消耗及复杂接口的最佳化。AHB和APB之间是通过Bridge(桥接器)连接的 。
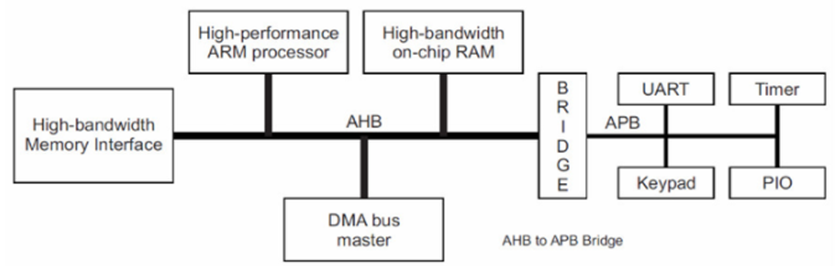
图4 AHB和APB连接关系
三、总线框架结构

图5 总线框架结构内容
如图6,以STM32F42XXX和STM32F43XXX器件总线系统架构为例。
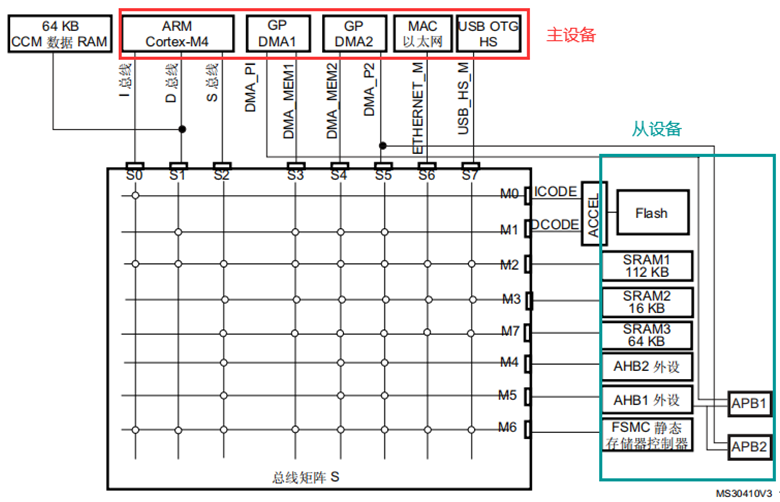
图6 STM32F42xxx和STM32F43xxx的总线系统架构
(1)、结构类型
STM32芯片是属于哈佛架构,即数据和程序指令分别存储,总线设计有一条指令总线(I-Bus)、一条数据总线(D-Bus),地址总线则与所有IO和外设相连,按照内核架构统一的存储器映射表分配对应地址。
哈佛架构与冯诺依曼的最大区别在于:哈佛架构的数据总线,指令总线是分开独立的,CPU通过Icode从Flash中取指令,再译码,得到数据的地址,再通过Dcode总线和SRAM进行数据交互。
哈佛架构的优势:并行体系结构,将程序指令和数据存储在不同的存储空间中,每个存储器独立编址、独立访问。哈佛架构的微处理器通常具有较高的执行效率,其程序指令和数据指令分开组织和储存的,执行时可以预先读取下一条指令。
(2)、总线模块
A、总线矩阵
图6中S是主控总线,M是被控总线,总线矩阵用于主控总线之间的访问仲裁管理,仲裁采用循环调度算法。有了总线矩阵,就可以让主设备和从设备进行并行访问,提升了访问效率,同时也降低了功耗。
需要注意的是,虽然总线矩阵使得多个主设备可以并行访问不同的从设备,但在一个定义的时间段内,只有一个主设备拥有总线矩阵的控制权,如果有多个主设备同时出现总线请求时就得进行仲裁。所以有了总线仲裁器,就能保证每个时刻只有一个主设备通过总线矩阵对从设备进行访问。
因为总线矩阵的存在,使得多个主设备可以并行访问不同的从设备,增强了数据传输能力,提升了访问效率,同时也改善了功耗性能。为了确保每个主设备访问从设备的延迟尽量短,在总线矩阵里实行循环调度优先级方案:
• 循环调度仲裁策略使总线带宽合理分配。
• 限定最大延时。
• 循环调度以1次传输为单位。
图中纵横交错的就是多层AHB总线矩阵,负责把上方主设备跟右边从设备互联起来。所谓AHB主设备是指CPU或DMA,由它们启动总线访问,即读写操作。那些响应主设备读写访问的设备就是AHB从设备,比如存储器、各类外设等。注意并非所有主设备访问从设备都得经过总线矩阵,如图中,有些主设备和从设备间有直通通道。
B、八条主控总线
CCM(Core Coupled Memory)是给F4内核专用的全速64KB RAM, 它们没有经过总线矩阵, F4内核与之直接相连, 地址空间在0x1000_0000 ~ 0x1000_FFFF。可以用作堆栈以及高速运算的数据缓存;
I总线:此总线用于将 Cortex-M4F 内核的指令总线连接到总线矩阵。内核通过此总线获取指令。此总线访问的对象是包含代码的存储器(内部 Flash/SRAM 或通过 FSMC 的外部存储器);
D总线:此总线用于将 Cortex-M4F 数据总线和 64 KB CCM 数据 RAM 连接到总线矩阵。内核通过此总线进行立即数加载和调试访问。此总线访问的对象是包含代码或数据的存储器(内部Flash 或通过 FSMC 的外部存储器);
S总线:此总线用于将 Cortex-M4F 内核的系统总线连接到总线矩阵。此总线用于访问位于外设或 SRAM中的数据。也可通过此总线获取指令(效率低于 ICode)。此总线访问的对象是112 KB、 64 KB 和 16 KB 的内部 SRAM、包括 APB 外设在内的 AHB1 外设、 AHB2 外设以及通过 FSMC 的外部存储器;
S3,S4:DMA存储器总线:此总线用于将 DMA 存储器总线主接口连接到总线矩阵。DMA 通过此总线来执行存储器数据的传入和传出。此总线访问的对象是数据存储器:内部 SRAM( 112 KB、 64 KB、 16 KB)以及通过 FSMC 的外部存储器;
S5:DMA外设总线,此总线用于将 DMA 外设主总线接口连接到总线矩阵。DMA 通过此总线访问 AHB 外设或执行存储器间的数据传输。此总线访问的对象是 AHB 和 APB 外设以及数据存储器:内部SRAM以及通过 FSMC 的外部存储器;
S6:以太网 DMA 总线,此总线用于将以太网 DMA 主接口连接到总线矩阵。以太网 DMA通过此总线向存储器存取数据。此总线访问的对象是数据存储器:内部 SRAM( 112 KB、 64 KB和 16 KB)以及通过FSMC的外部存储器;
S7: USB OTG HS DMA 总线,此总线用于将 USB OTG HS DMA 主接口连接到总线矩阵。USB OTG DMA 通过此总线向存储器加载/存储数据。此总线访问的对象是数据存储器:内部 SRAM(112 KB、 64 KB 和 16 KB)以及通过 FSMC 的外部存储器。
C、七条被控总线
内部 FLASH ICode 总线:是内核与内部闪存存储器(FLASH)指令接口之间的连接的总线,实现指令的预取功能;
内部 FLASH DCode 总线:将内核与内部闪存存储器(FLASH)的数据接口连接起来的总线,实现数据读取;
主要内部 SRAM1(112KB);
辅助内部 SRAM2(16KB);
辅助内部 SRAM3(64KB) (仅适用 STM32F42xx 和 STM32F43xx 系列器件);
AHB1外设和AHB2外设:不同时钟频率的用于高性能模块(如CPU、DMA和DSP等)之间的连接总线;
FSMC可变静态存储控制器:是STM32系列采用的一种新型的存储器扩展技术,FSMC能够根据不同的外部存储器类型,发出相应的数据/地址/控制信号类型以匹配信号的速度,从而使得STM32系列微控制器不仅能够应用各种不同类型、不同速度的外部静态存储器,而且能够在不增加外部器件的情况下同时扩展多种不同类型的静态存储器,满足系统设计对存储容量、产品体积以及成本的综合要求。能够与同步或异步存储器和 16 位 PC 存储器卡连接,STM32的 FSMC接口支持包括 SRAM、NAND FLASH、NOR FLASH 和 PSRAM 等存储器。
(3)、总线交互
指令总线和数据总线如6图所示只会负责对应存储地址范围内的传输,剩下片内外设和外界设备则是需要通过系统总线(AHB)进行数据的传输,对于低速外设则是挂载在相对较慢的外设总线(APB)总线,APB总线通过一个桥接器最终还是会挂载到AHB总线上。
主设备和从设备通过各自的总线两两相交连接,图6中两条总线相交且为圆圈的地方,表示这两条总线对应的主设备可以访问从设备,如I总线(指令总线),只有跟 M0、M2和M6这三根被控总线交叉的时候才有圆圈,就表示I总线只能跟这三根被控总线通信,这样就可以知道stm32f4的启动有三种分别是FLASH、内部SRAM、外部存储FSMC。
当多个AHB主设备试图同时访问同一个AHB从设备时,总线矩阵仲裁器介入以解决访问冲突。在下面的例子中CPU和DMA1均试图访问SRAM1以读取数据。
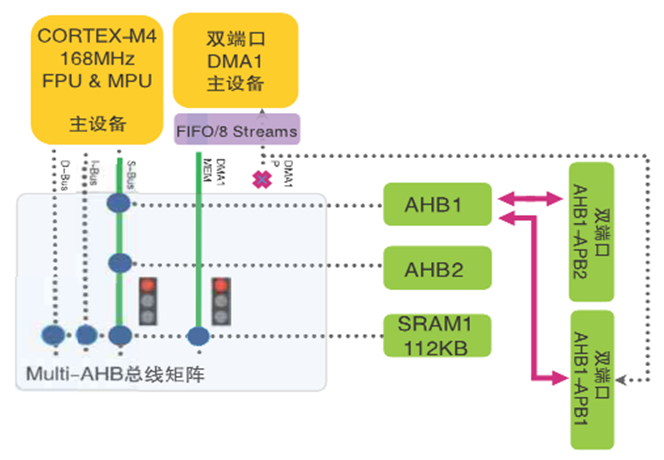
图7 CPU和DMA1请求访问SRAM1
如上述示例总线访问请求同时发生的情况下,就需要总线矩阵仲裁。为了解决这种问题,需要应用循环调度策略:如果本次最后赢得总线控制权的主设备是CPU,则在下一次访问中DMA1将赢得总线控制权并首先访问SRAM1。CPU随后方可有权访问SRAM1。
这就表明,一个主设备的传输延时取决于其它等待请求访问AHB从设备的主设备数量。下面的例子是五个主设备试图同时访问SRAM1的情形:
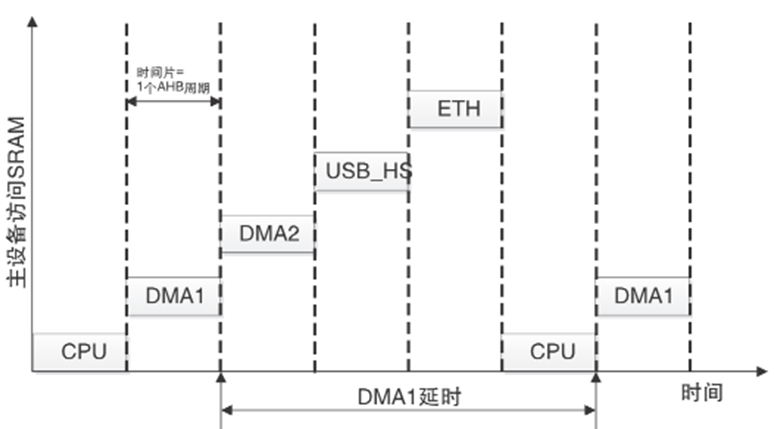
图8 五个主设备请求SRAM
DMA1再次获得总线矩阵访问权并访问SRAM1的延时等于其它等待请求的所有主设备的执行时间之和。
我们再来看看进行总线矩阵仲裁可能导致的DMA传输延时最差情况。主设备DMA端口进行一次数据传输会遭遇的延时取决于其它主设备的传输类型和长度。比如,我们结合上面的DMA1 & CPU的例子,它们并行访问SRAM。DMA传输延时将随着CPU数据传输事务长度而变化。如果总线访问首先给予CPU且不是执行单次数据加载/存储,DMA访问SRAM的等待时间可能从一个AHB周期(单次数据加载/存储时间)延长为N个AHB周期,这里N为CPU数据传输事务中数据的数量。
CPU锁定AHB 总线以保持其访问总线的所有权,减少了多次加载/ 存储操作过程中的延时以及进入中断的延时。这提高了固件的响应能力,但是可能导致DMA数据传输事务的延迟。
DMA1与CPU并行访问SRAM的延时取决于传输类型:
• 中断(上下文保护)发起的CPU传输:8个AHB周期;
• LDM/STM 指令发起的CPU传输:14个AHB周期;
---在多达14 个寄存器与存储器之间进行传输;

图9 中断发起的传输带来的DMA传输延时
上图详细描述了一个因中断进入而导致DMA多周期传输延迟的情形。DMA存储器端口被触发,发出存储器访问请求。经过仲裁, AHB总线未授权DMA1存储器端口访问,而由CPU来访问总线。可以看到在服务DMA请求之前有一段额外的延时。这段中断发起的CPU传输,耗时为8个AHB周期。
不难理解,当同时对一个从设备进行寻址且数据传输事务长度不是一个数据单元时,其他主设备(如DMA2,USB_HS, Ethernet…)也会碰到类似情形。所以,为了提高DMA对总线矩阵的访问性能,要尽量回避总线竞争。
四、总结
本篇对STM32芯片内部的总线机制进行了一系列的介绍,部分信息来源自STM32的官方资料中对芯片系统架构的介绍。通过对总线概念的阐述可以去更好的为进一步认识STM32内部总线框架提供基础,从STM32的总线框架中,可以了解到STM32芯片内部总线的设计模型和基本的工作原理,从而对STM32的芯片总线内部结构有一个初步的认知。
↓↓↓更多技术内容和书籍资料获取,入群技术交流敬请关注“明解嵌入式”↓↓↓