💖作者:小树苗渴望变成参天大树🎈
🎉作者宣言:认真写好每一篇博客💤
🎊作者gitee:gitee✨
💞作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法🎄如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!

文章目录
- 前言
- 一、源码理解
- 二、模拟实现
- 2.1成员属性
- 2.2计算大小相关的函数
- 2.3resize和reserve函数
- 2.4operator[]函数
- 2.5insert和erase函数
- 2.6push_back和pop_back函数
- 2.7构造函数和析构函数
- 2.8swap函数
- 2.9赋值运算符函数
- 三、全部代码
- 四、总结
前言
今天来带大家看看vector的模拟实现,思路来说还是比较简单的,vector本身也是一个动态可变的顺序表,常见功能大家还是熟悉的,接下来我先通过源码来带大家看看,然后再进行模拟实现,这样大家就会理解很多。
一、源码理解
我们看一个类首先看他的属性再看成员函数:
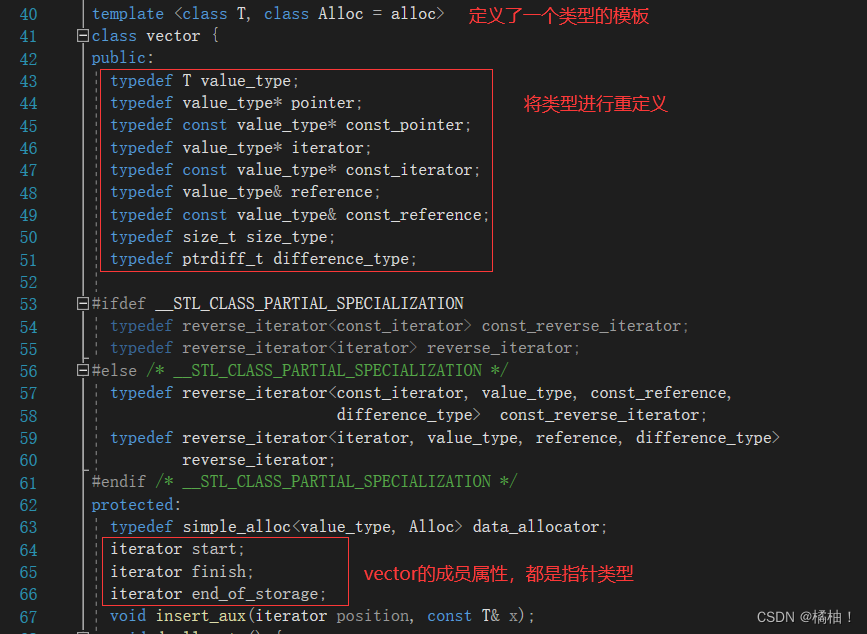
首先我圈出来的部分大家还是可以看懂的吧,我们vector不是像顺序表一样的通过size,capacity的这种方式来访问大小和容量了,而是通过两个指针与起始位置的差值来访问大小和容量了,为了适应任意类型,采取模板的形式,也将迭代器类型重命名出来了,我们来看看书上怎么说的


接下来我们看看他的构造函数:

也是有四个,到时候模拟实现也是按照这四个进行模拟的,还有一个析构函数
计算大小和容量的一些函数

改变有效大小和容量函数:

插入删除函数:

大致就这些函数,大家大致框架应该可以看懂,里面涉及到一些空间配置器的问题(内存池),大家目前不需要理解,我们模拟实现的是使用new就行了,接下来我们来看看模拟实现吧
二、模拟实现
根据源码我们需要把源码定义出来,为了和库里面的vector发生命名冲突,我将模拟实现的vector放在一个命名空间域中,再定义两个文件:(模板的定义和声明不能分离)
2.1成员属性
#include<iostream>
#include<vector>
using namespace std;
#include<assert.h>
#include<string.h>
namespace xdh
{
template <class T>
class vector {
public:
typedef T* iterator;
typedef const T* const_iterator;
private:
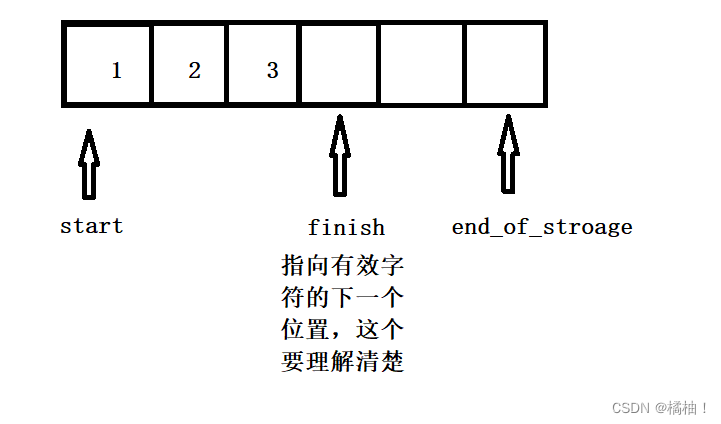
iterator start=nullptr;//指向目前使用空间的开头
iterator finish=nullptr;//指向目前使用空间的结尾
iterator end_of_storage=nullptr;//指向目前可用空间的尾
};
}
2.2计算大小相关的函数
iterator begin() { return start; }
iterator end() { return finish; }
const_iterator cbegin()const { return start; }
const_iterator cend() const { return finish; }
size_t size()const { return finish - start; }
size_t capacity()const { return end_of_storage - start; }
bool empty() { return begin() == end(); }
这些函数大家一眼就能看懂,我就不做具体讲解了
2.3resize和reserve函数
这两个函数要先实现reserve函数,因为resize函数可能会涉及到扩容,要复用reserve函数
void reserve(size_t n)
{
if (n > capacity())//其他情况也要扩容,所以要检查
{
size_t oldsize = size();//记录原数组有效位置到其实位置的距离
T* tmp = new T[n];
if (start)//原数组不为空,将原数组的数据拷贝到新数组上
{
//思考:使用memcpy(tmp,start,sizeof(T)*size())可不可以
for(size_t i = 0; i < oldsize; i++)
{
tmp[i] = start[i];
}
delete[] start;//将原来的空间先进行释放
}
start = tmp;//改变其实位置
finish = start + oldsize;//改变有效位置
end_of_storage = start + n;//改变最终位置
}
}
思考:使用memcpy(tmp,start,sizeof(T)*size())可不可以
void resize(size_t n, const T& val = T())
{
if (n <= size())//改变的大小小于原数组的的大小,直接改变有效位置的指针
{
finish = start + n;
return;
}
if (n > capacity())//先检查是否需要扩容
{
reserve(n);
iterator it = finish;
finish = start + n;
while (it != finish)
{
*it = val;//将默认值放在数组的后面
it++;
}
}
}
我们看到resize需要提供默认值,方便初始化, 我们使用匿名对象,这样初始化就是调用T类型的默认构造,给T()进行初始化,然后通过T类型的赋值运算符给val赋值,就达到初始化任务了,这里面有两个注意的点,我们的自定义类型T必须要有自己的默认构造,可以帮助自己完成默认初始化,而且还必须有默认的赋值运算,涉及到深拷贝问题,赋值运算符还要自己实现才行。
我们是内置类型就会出现const int& val=int();这种情况,C++对于这块给我们做了优化
int a=int()加相当于int a=0;
int a=int(1)加相当于int a=1;
int a=int(2)加相当于int a=3;
其余内置类型也是一样的道理
2.4operator[]函数
我们有两种,一种是const的,一种是非const的,因为我们也重命名了两种迭代器
T& operator[](size_t pos)
{
assert(pos < size());
return start[pos];
}
const T& operator[](size_t pos)const
{
assert(pos < size());
return start[pos];
}
2.5insert和erase函数
这两个函数可以说是vector比较常用的函数了,也是比较关键的函数,我们再vector使用的时候介绍了有三种insert和两种erase,博主都给实现了一遍:
iterator insert(iterator position, const T& val)
{
assert(position <= finish);//检查下标合理性
if (finish == end_of_storage)//扩容
{
size_t n = position-start;//记录插入位置和起始位置的距离,到时候再新数组好定位到position
size_t newcapacity= capacity() == 0 ? 4 : capacity() * 2;//一开始为空就扩容4个,不为空就扩容两倍
reserve(newcapacity);
//要进行重置,不然pos还是指向原来数组的地址
position = start + n;
}
iterator end = finish-1;//finish是执行那个数组的下一个位置,所以减1指向最后一个数组
while (end >=position)
{
*(end + 1) = *end;//一个一个往后面移,把position位置空出来,给要插入的元素
--end;
}
*position = val;
++finish;//最终插入了一个位置,finish加1就可以了
return position;//返回迭代器的值,防止迭代器失效
}
iterator insert(iterator position, size_t n, const T& val)
{
assert(position <= finish);
if (finish == end_of_storage)
{
size_t n1 = position - start;
reserve((capacity() == 0) ? 4 : capacity() + n);
//要进行重置,不然pos还是指向原来数组的地址
position = start + n1;
}
iterator end = finish-1;
while (end >= position)
{
*(end + n) = *end;//一次往往后面移n个位置,从position位置往后空出来n个位置
end--;
}
finish += n;
while (n--)//再把插入的元素插进来
{
*(++end) = val;
}
return position;
}
template <class Input>
iterator insert(iterator position, Input first, Input last)
{
assert(position <= finish);
int n = last - first;
if (size() == capacity())
{
size_t n1 = position - start;
reserve((capacity() == 0) ? 4 : capacity() + n+1);
//要进行重置,不然pos还是指向原来数组的地址
position = start + n1;
}
iterator end = finish - 1;
while (end >= position)
{
*(end + n) = *end;
end--;
}
finish +=n;
while (first<last)
{
*(position++) = (*first++);
}
return position;
}
iterator erase(iterator position)
{
assert(position <= finish);//检查下标合法性
iterator begin = position;
while (begin < finish)
{
*(begin) = *(begin+1);//从前往后覆盖
begin++;
}
--finish;
return position;
}
iterator erase(iterator first, iterator last)
{
assert(first<= finish);//检查合法性
int n = last - first+1;
iterator begin = first + n;
while (begin != finish)
{
*(begin - n) = *begin;
begin++;
}
finish-=n;
return first;
}
注释我已经标识好了,大家不理解的画个图理解一下:对于为什么要使用返回值,就是要考虑迭代器可能会失效,再vector的使用已经讲解过了,可以画两块空间的图,一个新空间,一个就空间,看看再扩容的时候,此时的迭代器指向那个位置。就可以理解了。
2.6push_back和pop_back函数
这是一个尾插和尾删的函数,我们之前实现了insert和erase函数,之间复用就好了
void push_back(const T& val)
{
insert(end(), val);
}
void pop_back()
{
erase(end());
}
2.7构造函数和析构函数
我为什么要把构造函数放在后面呢??原因就是我们要实现四个构造函数,有两个构造函数要复用前面的插入函数,每个构造函数的特点之前介绍过,这里就不做过多解释了
//1.默认构造器
vector()
:start(nullptr)
,finish(nullptr)
,end_of_storage(nullptr)
{
}
//2.传个数的初始化
vector(size_t n, const T& val = T())
:start(nullptr)
, finish(nullptr)
, end_of_storage(nullptr)
{
reserve(n);
while (n--)
{
push_back(val);
}
}
template <class InputIterator>
//3.传其他迭代器进来初始化
vector(InputIterator first, InputIterator last)
:start(nullptr)
, finish(nullptr)
, end_of_storage(nullptr)
{
int n = last - first;
reserve(n);
while (n--)
{
push_back(*(first++));
}
}
//4.传vector进来构造(拷贝构造)
vector(const vector<T>& x)
:start(nullptr)
, finish(nullptr)
, end_of_storage(nullptr)
{
size_t n = x.size();
T* tmp = new T[n];
for (int i = 0; i < n; i++)
{
tmp[i] = x[i];
}
start = tmp;
finish = end_of_storage=start+n;
}
~vector()
{
delete[] start;
start = finish = end_of_storage = nullptr;
}
我们发现我们写的所有构造里面都有初始化列表,而且都使用的是默认值nullptr,为什么要进行默认值呢,原因是再介绍构造函数那篇博客中介绍过,不写有的编译器不做处理,那么里面就是随机值,再C++11中打了这个补丁,我们再成员变量的时候就给缺省值就可以了,上面这些初始化列表都可以不用写。
我们来看一下第二个构造函数和第三个构造函数
我们看到我是想通过第二个构造函数进行初始化,但是看到报错信息和第三个构造函数报错了,这是为什么?很简单,我们的(10,2)这个参数再匹配模板的时候都会默认解释成int,说明第三个构造函数和它最匹配,上面图解也解释了,你的模板被解释成int了,而第二个构造函数再进行匹配的时候,第一个参数解释成size_t,第二个参数解释成int,显然没有第三个构造函数全部解释成int好,所有优先匹配了第三个构造函数,因为里面有解引用,所以出现了对非法地址的间接寻址
有两种解决办法
1.再传参的时候将类型规定好(10u,2)因为第三个构造函数只有一个模板,不可能解释成两个不太类型,这样只能匹配到第二个构造函数
2.将第二个构造函数的size_t改成int就可以,读者下来可以自己去看看
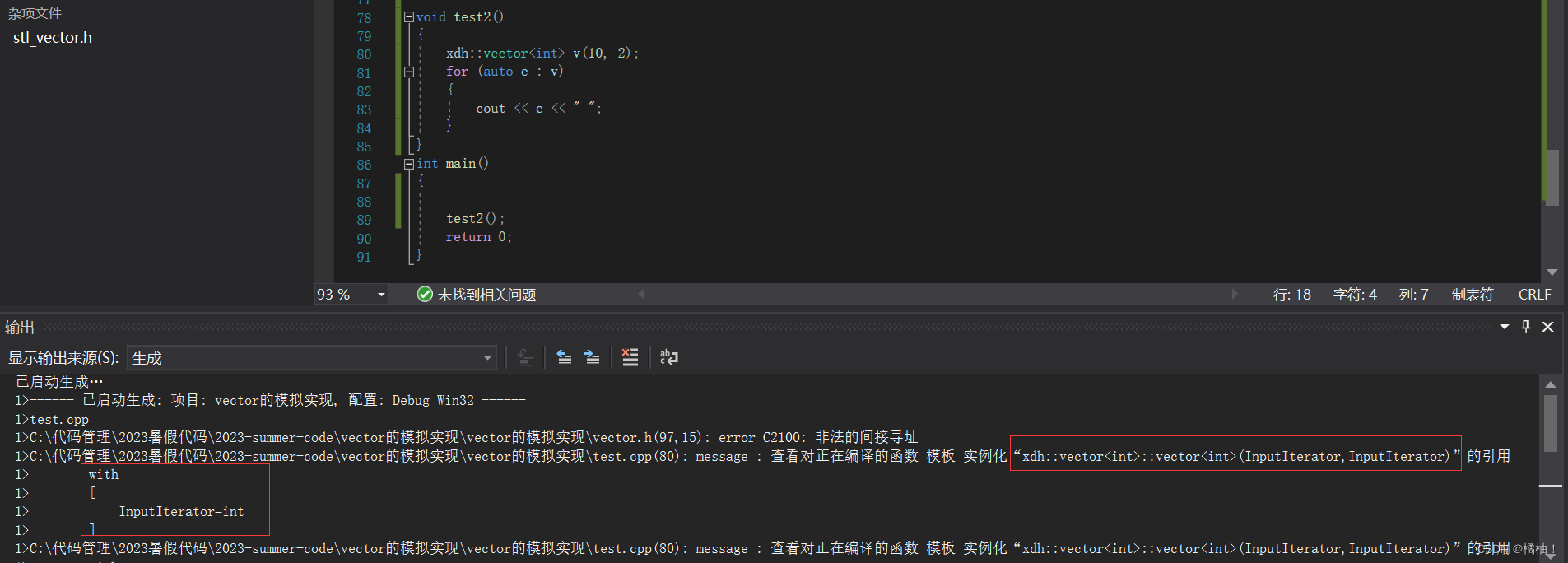
注意:这种情况再insert的第二个和第三个函数也出现过,我没有做修改,希望大家可以回过头来看看。
2.8swap函数
实现两个vector之间的交换,只需要交换三个属性就可以了
void swap(vector<T>& v)
{
std::swap(start, v.start);
std::swap(finish, v.finish);
std::swap(end_of_storage, v.end_of_storage);
}
2.9赋值运算符函数
vector<T>& operator=(vector<T>& x)
{
vector<T>tmp(x);
swap(tmp);
return *this;
}
vector<T>& operator=(vector<T> x)
{
swap(x);
return *this;
}
这两种都可以,我们按照原始的办法就要开辟空间进行拷贝,但我们发现这个方法拷贝构造已经帮我们实现了,第一种就直接通过拷贝构造来创建一个tmp对象,然后交换就可以了,第二种是再传参的时候就会调用拷贝构造,函数体里面之间交换就可以了,反正改变不了外面的实参
至此我们的模拟实现就到这里结束了,来解决一下刚才的思考:我们再reserve函数里面进行memcpy(tmp,start,sizeof(T)*size()),将原数组的值赋值到新数组上可以不可以??我们来看事例:
我们发现传自定义类型的参数,程序就报错了了,我只把赋值换成了memcpy函数,说明肯定是memcpy出现了错误,我们来看看为什么会出现错误:
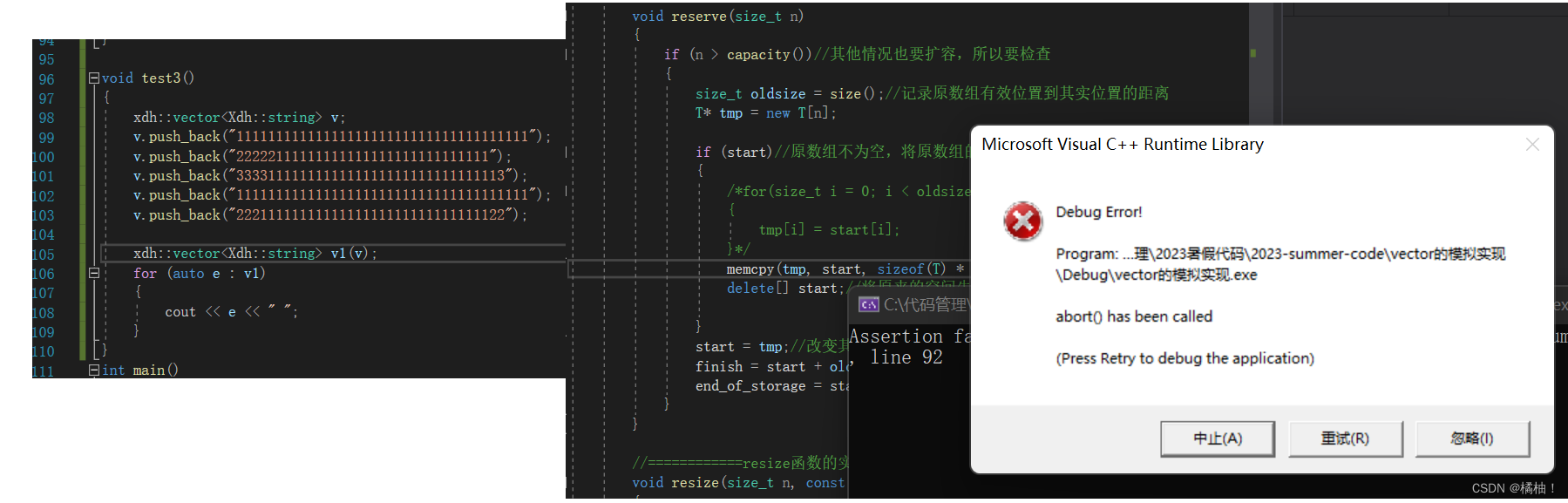
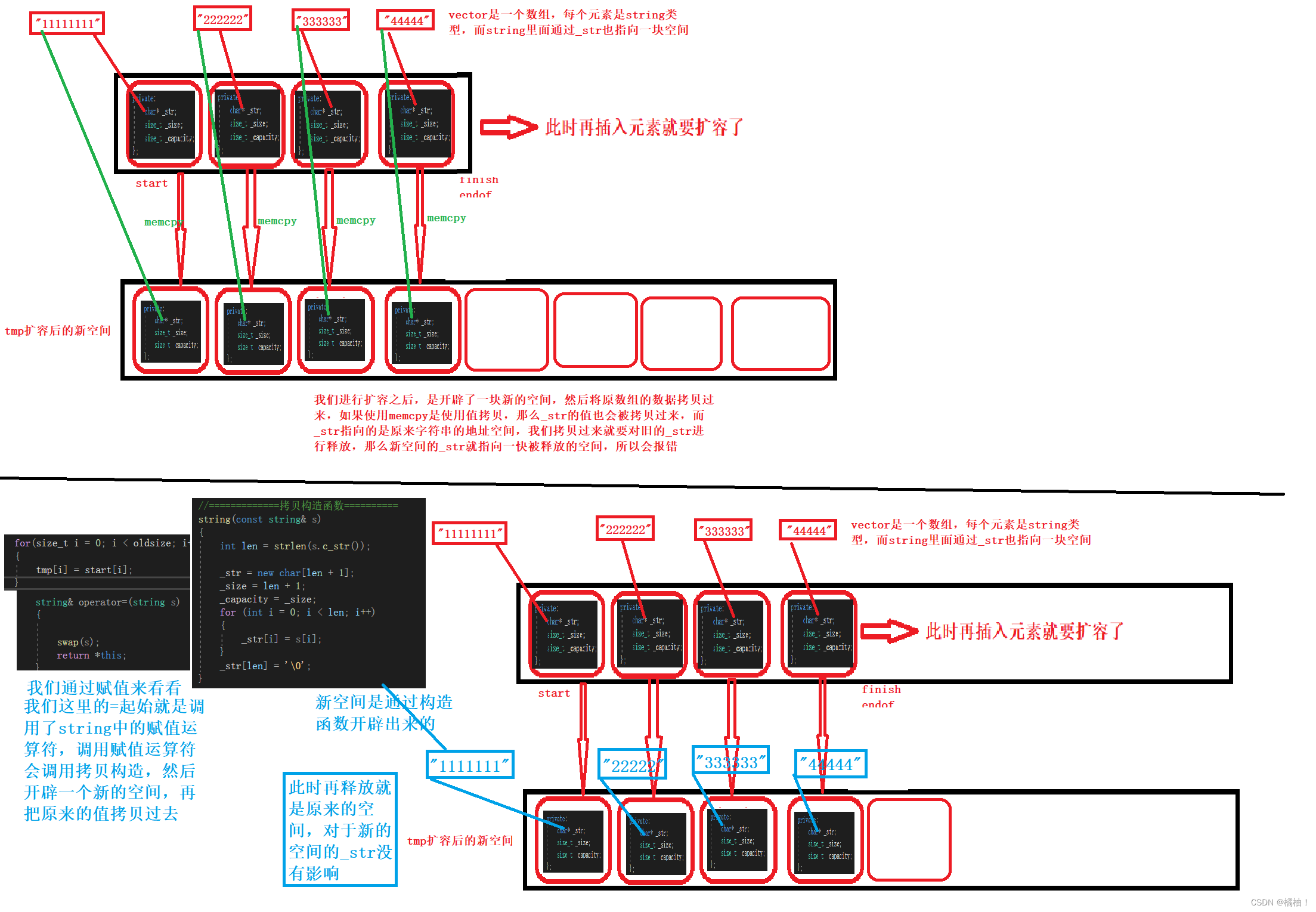
- memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中
- 如果拷贝的是自定义类型的元素,memcpy既高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
此时再理解这句话是不是容易多了,对于内置类型或者自定义类型中没有涉及到空间问题,那么使用memcpy和赋值没有任何区别,涉及到空间问题,就是有可能指向释放的空间,导致出错,所以大家使用memcpy的使用要注意有没有刚才说的情况。这样才不会出现
三、全部代码
vector.h
#pragma once
#include<iostream>
#include<vector>
using namespace std;
#include<assert.h>
#include<string.h>
namespace xdh
{
template <class T>
class vector {
public:
typedef T* iterator;
typedef const T* const_iterator;
iterator begin() { return start; }
iterator end() { return finish; }
const_iterator cbegin()const { return start; }
const_iterator cend() const { return finish; }
size_t size()const { return finish - start; }
size_t capacity()const { return end_of_storage - start; }
bool empty() { return begin() == end(); }
//==============reserse函数的实现=================
void reserve(size_t n)
{
if (n > capacity())//其他情况也要扩容,所以要检查
{
size_t oldsize = size();//记录原数组有效位置到其实位置的距离
T* tmp = new T[n];
if (start)//原数组不为空,将原数组的数据拷贝到新数组上
{
for(size_t i = 0; i < oldsize; i++)
{
tmp[i] = start[i];
}
//memcpy(tmp, start, sizeof(T) * oldsize);
delete[] start;//将原来的空间先进行释放
}
start = tmp;//改变其实位置
finish = start + oldsize;//改变有效位置
end_of_storage = start + n;//改变最终位置
}
}
//============resize函数的实现=============
void resize(size_t n, const T& val = T())
{
if (n <= size())//改变的大小小于原数组的的大小,直接改变有效位置的指针
{
finish = start + n;
return;
}
if (n > capacity())//先检查是否需要扩容
{
reserve(n);
iterator it = finish;
finish = start + n;
while (it != finish)
{
*it = val;//将默认值放在数组的后面
it++;
}
}
}
//==============构造器============
//1.默认构造器
vector()
:start(nullptr)
,finish(nullptr)
,end_of_storage(nullptr)
{
}
//2.传个数的初始化
vector(size_t n, const T& val = T())
:start(nullptr)
, finish(nullptr)
, end_of_storage(nullptr)
{
reserve(n);
while (n--)
{
push_back(val);
}
}
template <class InputIterator>
//3.传其他迭代器进来初始化
vector(InputIterator first, InputIterator last)
:start(nullptr)
, finish(nullptr)
, end_of_storage(nullptr)
{
int n = last - first;
reserve(n);
while (n--)
{
push_back(*(first++));
}
}
//4.传vector进来构造(拷贝构造)
vector(const vector<T>& x)
:start(nullptr)
, finish(nullptr)
, end_of_storage(nullptr)
{
size_t n = x.size();
T* tmp = new T[n];
for (int i = 0; i < n; i++)
{
tmp[i] = x[i];
}
start = tmp;
finish = end_of_storage=start+n;
}
//============operator=函数的实现==========
vector<T>& operator=(vector<T>& x)
{
vector<T>tmp(x);
swap(tmp);
return *this;
}
vector<T>& operator=(vector<T> x)
{
swap(x);
return *this;
}
//============析构函数=========
~vector()
{
delete[] start;
start = finish = end_of_storage = nullptr;
}
//===========operator[]函数的实现==========
T& operator[](size_t pos)
{
assert(pos < size());
return start[pos];
}
const T& operator[](size_t pos)const
{
assert(pos < size());
return start[pos];
}
//==============insert函数的实现============
iterator insert(iterator position, const T& val)
{
assert(position <= finish);//检查下标合理性
if (finish == end_of_storage)//扩容
{
size_t n = position-start;//记录插入位置和起始位置的距离,到时候再新数组好定位到position
size_t newcapacity= capacity() == 0 ? 4 : capacity() * 2;//一开始为空就扩容4个,不为空就扩容两倍
reserve(newcapacity);
//要进行重置,不然pos还是指向原来数组的地址
position = start + n;
}
iterator end = finish-1;//finish是执行那个数组的下一个位置,所以减1指向最后一个数组
while (end >=position)
{
*(end + 1) = *end;//一个一个往后面移,把position位置空出来,给要插入的元素
--end;
}
*position = val;
++finish;//最终插入了一个位置,finish加1就可以了
return position;//返回迭代器的值,防止迭代器失效
}
void insert(iterator position, int n, const T& val)
{
assert(position <= finish);
if (finish == end_of_storage)
{
size_t n1 = position - start;
reserve((capacity() == 0) ? 4 : capacity() + n);
//要进行重置,不然pos还是指向原来数组的地址
position = start + n1;
}
iterator end = finish-1;
while (end >= position)
{
*(end + n) = *end;//一次往往后面移n个位置,从position位置往后空出来n个位置
end--;
}
finish += n;
while (n--)//再把插入的元素插进来
{
*(++end) = val;
}
}
template <class Input>
void insert(iterator position, Input first, Input last)
{
assert(position <= finish);
int n = last - first;
if (size() == capacity())
{
size_t n1 = position - start;
reserve((capacity() == 0) ? 4 : capacity() + n+1);
//要进行重置,不然pos还是指向原来数组的地址
position = start + n1;
}
iterator end = finish - 1;
while (end >= position)
{
*(end + n) = *end;
end--;
}
finish += n;
while (first<last)
{
*(position++) = (*first++);
}
}
//==============erase的函数实现===============
iterator erase(iterator position)
{
assert(position <= finish);//检查下标合法性
iterator begin = position;
while (begin < finish)
{
*(begin) = *(begin+1);//从前往后覆盖
begin++;
}
--finish;
return position;
}
iterator erase(iterator first, iterator last)
{
assert(first<= finish);//检查合法性
int n = last - first+1;
iterator begin = first + n;
while (begin != finish)
{
*(begin - n) = *begin;
begin++;
}
finish-=n;
return first;
}
//==============push_back和pop_back函数的实现=============
void push_back(const T& val)
{
insert(end(), val);
}
void pop_back()
{
erase(end());
}
//==============swap函数的实现====================
void swap(vector<T>& v)
{
std::swap(start, v.start);
std::swap(finish, v.finish);
std::swap(end_of_storage, v.end_of_storage);
}
private:
iterator start;//指向目前使用空间的开头
iterator finish;//指向目前使用空间的结尾
iterator end_of_storage;//指向目前可用空间的尾
};
}
四、总结
我们的vector模拟实现总算讲完了,里面要注意的细节还是非常多,所以说C++没学好,里面的坑还是非常多的,博主自己再实现的时候也出现了很多错误,一定要写一个功能旧测试一个,不然出错了就很痛苦,那我们这篇就说到这里,下篇我们开始介绍list,这个容器难度就上来了,因为涉及到带头双向循环链表的结构,不用担心,跟着博主走,没有难的事。