相关文章:
Django实现接口自动化平台(十)自定义action names【持续更新中】_做测试的喵酱的博客-CSDN博客
本章是项目的一个分解,查看本章内容时,要结合整体项目代码来看:
python django vue httprunner 实现接口自动化平台(最终版)_python+vue自动化测试平台_做测试的喵酱的博客-CSDN博客
官方文档:
Serializers - Django REST framework
一、Projects 相关接口
项目数据的基本增删改查
| 请求方式 | URI | 对应action | 实现功能 |
| GET | /projects/ | .list() | 查询project列表 |
| POST | /projects/ | .create() | 创建一条数据 |
| GET | /projects/{id}/ | .retrieve() | 检索一条project的详细数据 |
| PUT | /projects/{id}/ | update() | 更新一条数据中的全部字段 |
| PATCH | /projects/{id}/ | .partial_update() | 更新一条数据中的部分字段 |
| DELETE | /projects/{id}/ | .destroy() | 删除一条数据 |
| GET | /projects/names/ | .names() 自定义 | 查询project列表 |
本章节,只是单纯的实现了项目接口的增删改查,后续扩展功能在其他章节
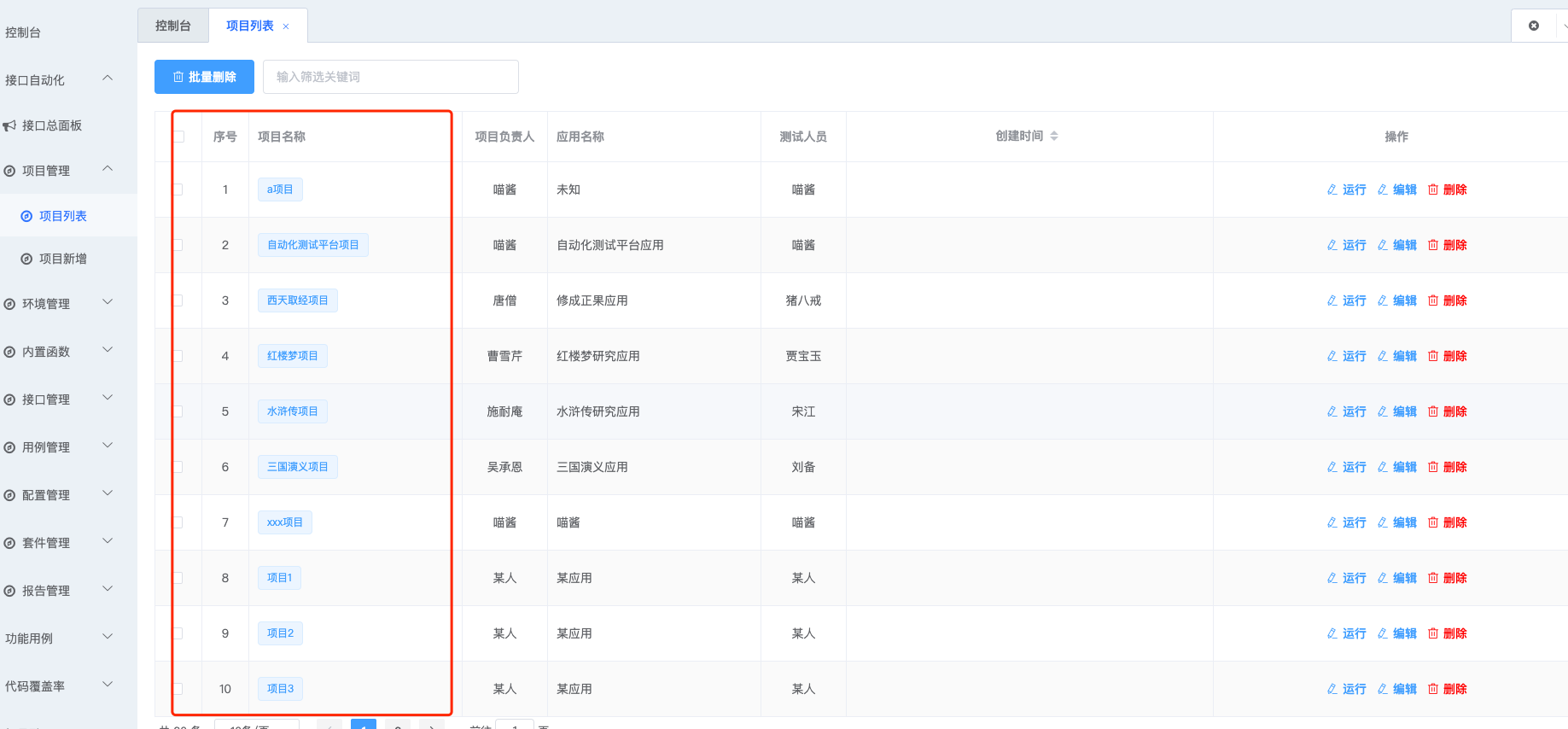
1.1 项目列表 查询peoject列表 .list()
| GET | /projects/ | .list() | 查询project列表 |
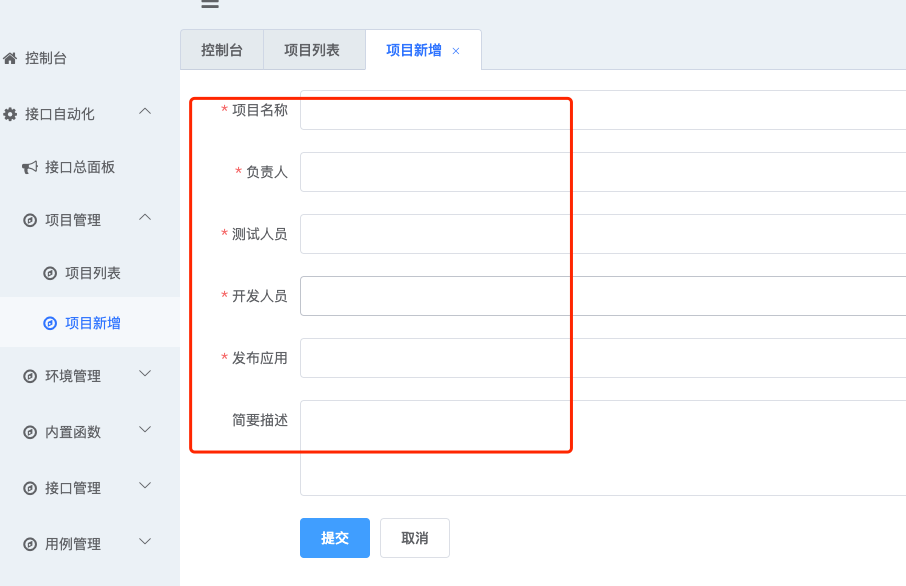
1.2 创建一条project .create()
| POST | /projects/ | .create() | 创建一条数据 |
1.3 查看详情/更新项目 retrieve() update() .partial_update()
查看详情与编辑
- 查看详情 .retrieve()
- 更新 update() partial_update()
1.4 项目列表 自定义action names
| GET | /projects/names/ | .names() 自定义 | 查询project列表 |
应用场景:
在创建接口时,需要调用项目列表。设置该接口归属为哪个项目。
这里的项目列表,只展示项目的id 与 name,其他字段都不展示的。
names() 列表 与 list() 列表,对应的序列化器是不一样的。

二、Projects 数据库模型model
projects项目表的字段
from django.db import models
from utils.base_models import BaseModel
class Projects(BaseModel):
id = models.AutoField(verbose_name='id主键', primary_key=True, help_text='id主键')
name = models.CharField('项目名称', max_length=200, unique=True, help_text='项目名称')
leader = models.CharField('负责人', max_length=50, help_text='项目负责人')
tester = models.CharField('测试人员', max_length=50, help_text='项目测试人员')
programmer = models.CharField('开发人员', max_length=50, help_text='开发人员')
publish_app = models.CharField('发布应用', max_length=100, help_text='发布应用')
desc = models.CharField('简要描述', max_length=200, null=True, blank=True, default='', help_text='简要描述')
update_datetime = models.DateTimeField(auto_now=True, null=True, blank=True, help_text="修改时间",
verbose_name="修改时间")
create_datetime = models.DateTimeField(auto_now_add=True, null=True, blank=True, help_text="创建时间",
verbose_name="创建时间")
class Meta:
db_table = 'tb_projects'
verbose_name = '项目信息'
verbose_name_plural = verbose_name
ordering = ('id',)
def __str__(self):
return self.nameid、项目名称、负责人、测试人员、开发人员、应用名称、描述、修改时间、创建时间。
详解:
1、表名:db_table = 'tb_projects'
2、数据排序:ordering = ('id',)
三、序列化器serializer
# -*- coding: utf-8 -*-
from rest_framework import serializers
from .models import Projects
class ProjectModelSerializer(serializers.ModelSerializer):
class Meta:
model = Projects
exclude = ('update_datetime', )
extra_kwargs = {
"create_datetime": {
"read_only": True,
"format": "%Y年%m月%d日 %H:%M:%S"
}
}
# names action的序列化器
class ProjectsNamesModelSerailizer(serializers.ModelSerializer):
class Meta:
model = Projects
fields = ('id', 'name')一共两个序列化器
1、正常的序列化器,包含全部的字段
2、 names action 对应的序列化器,只展示id 与name
四、视图views.py
import logging
from rest_framework import filters
from rest_framework import viewsets
from rest_framework import permissions
from .models import Projects
from . import serializers
from utils.mixins import NamesMixin
logger = logging.getLogger('backend')
class ProjectViewSet(NamesMixin, viewsets.ModelViewSet):
"""
list:
获取项目列表数据
retrieve:
获取项目详情数据
update:
更新项目信息
names:
获取项目名称
"""
queryset = Projects.objects.all()
serializer_class = serializers.ProjectModelSerializer
filter_backends = [filters.SearchFilter, filters.OrderingFilter]
search_fields = ['=name', '=leader', '=id']
ordering_fields = ['id', 'name', 'leader']
permission_classes = [permissions.IsAuthenticated]
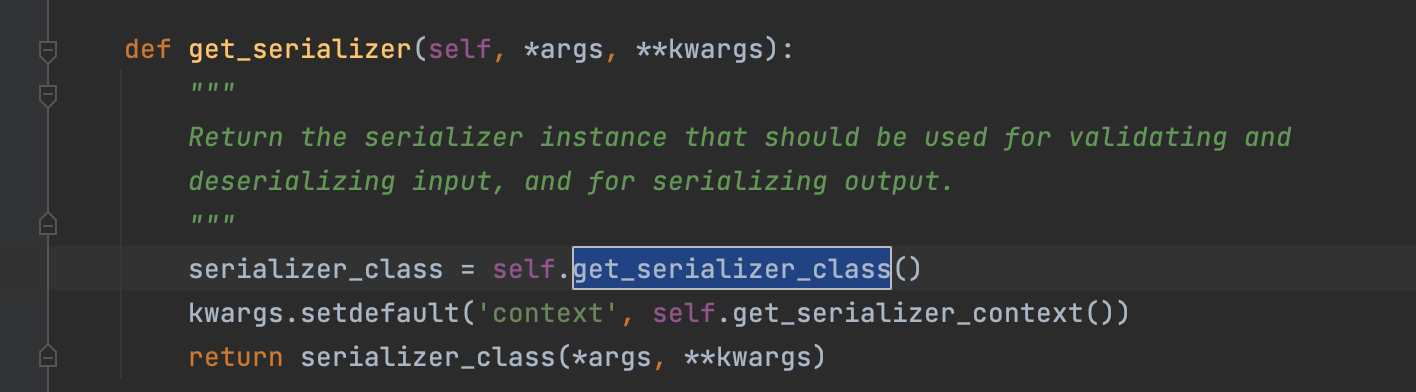
def get_serializer_class(self):
"""
a.可以重写父类的get_serializer_class方法,用于为不同的action提供不一样的序列化器类
b.在视图集对象中可以使用action属性获取当前访问的action方法名称
:return:
"""
if self.action == 'names':
return serializers.ProjectsNamesModelSerailizer
else:
return super().get_serializer_class()
1、names接口,由NamesMixin 提供
2、基础的增删改查,由viewsets.ModelViewSet 提供
3、get_serializer_class 重写的, ModelViewSet->GenericViewSet->GenericAPIView 类下的方法。
def get_serializer_class(self):
"""
a.可以重写父类的get_serializer_class方法,用于为不同的action提供不一样的序列化器类
b.在视图集对象中可以使用action属性获取当前访问的action方法名称
:return:
"""
if self.action == 'names':
return serializers.ProjectsNamesModelSerailizer
else:
return super().get_serializer_class()重写后,当action为names时,返回序列化器为serializers.ProjectsNamesModelSerailizer
get_serializer_class 源码: