一、ChatYuan-large-v2 模型
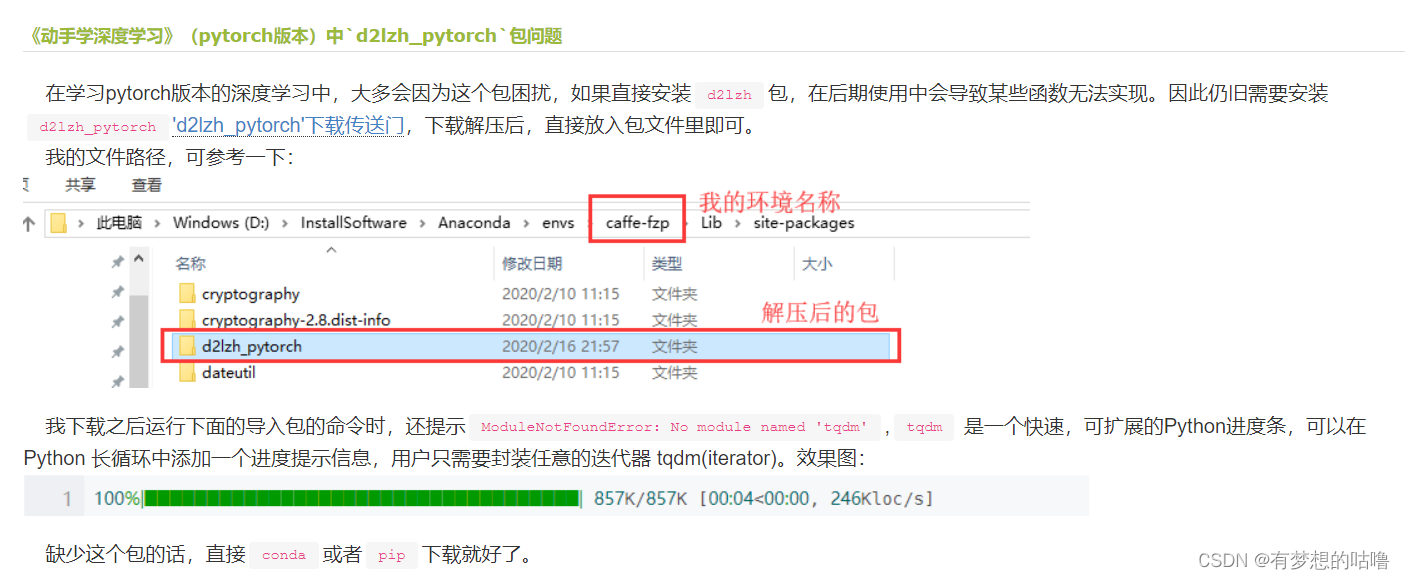
ChatYuan-large-v2是一个开源的支持中英双语的功能型对话语言大模型,与其他 LLM 不同的是模型十分轻量化,并且在轻量化的同时效果相对还不错,仅仅通过0.7B参数量就可以实现10B模型的基础效果,正是其如此的轻量级,使其可以在普通显卡、 CPU、甚至手机上进行推理,而且 INT4 量化后的最低只需 400M 。
v2 版本相对于以前的 v1 版本,是使用了相同的技术方案,但在指令微调、人类反馈强化学习、思维链等方面进行了优化,主要优化点如下所示:
- 增强了基础能力。原有上下文问答、创意性写作能力明显提升。
- 新增了拒答能力。对于一些危险、有害的问题,学会了拒答处理。
- 新增了代码生成功能。对于基础代码生成进行了一定程度优化。
- 新增了表格生成功能。使生成的表格内容和格式更适配。
- 增强了基础数学运算能力。
- 最大长度
token数从1024扩展到4096。 - 增强了模拟情景能力。
- 新增了中英双语对话能力。
ChatYuan-large-v2 模型已经发布到了 huggingface 中:
https://huggingface.co/ClueAI/ChatYuan-large-v2
开源项目地址:
https://github.com/clue-ai/ChatYuan
二、AutoModel 调用示例
由于ChatYuan-large-v2 已经发布到 huggingface 中 ,因此在可以先使用 transformers 中的 AutoTokenizer 和 AutoModel 进行调用体验。
首先将下面链接中的文件下载到本地磁盘中:
https://huggingface.co/ClueAI/ChatYuan-large-v2/tree/main
调用实例:
# -*- coding: utf-8 -*-
from transformers import AutoTokenizer, AutoModel
import os
# 这里是模型下载的位置
model_dir = 'D:\\AIGC\\model\\ChatYuan-large-v2'
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True)
history = []
while True:
query = input("\n用户:")
if query == "stop":
break
if query == "clear":
history = []
os.system('clear')
continue
response, history = model.chat(tokenizer, query, history=history)
print(f"小元:{response}")
测试:
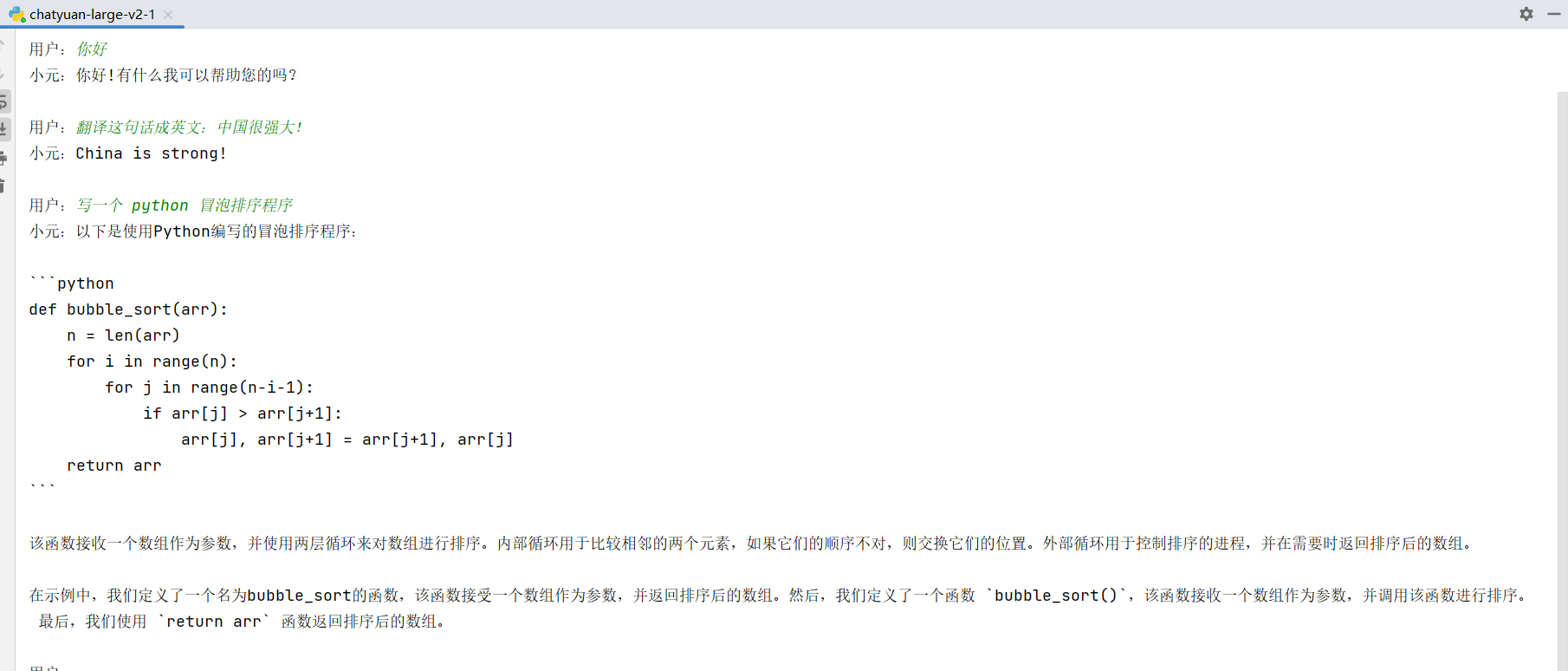
从上面的演示可以看到一些常见的对话都是OK的,也可以为我们写一些代码,下面将上面的程序转化为 Langchain 中的 LLM 进行使用。
三、LangChain 集成
在 LangChain 中为我们提供了一个 HuggingFacePipeline 工具,可以轻松的将 HuggingFace 中的 pipeline 转为 langchain 中的 LLM,下面是调用实例:
# -*- coding: utf-8 -*-
from transformers import AutoTokenizer, AutoModel, pipeline
from langchain import HuggingFacePipeline
from langchain import PromptTemplate
import os
model_dir = 'D:\\AIGC\\model\\ChatYuan-large-v2'
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True)
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=512,
temperature=0.8,
top_p=1,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)
template = "用户:{query} \n 小元:"
prompt = PromptTemplate(
input_variables=["query"],
template=template,
)
while True:
query = input("\n用户:")
if query == "stop":
break
if query == "clear":
os.system('clear')
continue
response = llm(prompt.format(query=query))
print(f"小元:{response}")
测试效果:

四、场景使用探索
4.1 实体识别
提取文本中的 企业 和 地址 实体:
根据文本内容,提取出"公司"、“地址” 信息, 文本内容:阿里巴巴在江苏南京有分公司吗?

4.2 情感分析
根据文本内容,判断情感是正向还是负向, 文本内容:前台服务非常好,再接再厉!
根据文本内容,判断情感是正向还是负向, 文本内容:饭菜口味很难吃!

4.3 文章分类
根据文本内容进行文章分类,分类如下: 新闻、体育、美食、健身, 文本内容:苏州的饭菜非常好吃,下次继续来吃。
根据文本内容进行文章分类,分类如下: 新闻、体育、美食、健身, 文本内容:好久没运动了,我准备每天跑步。

4.4 文章生成
写一个文章,内容是关于美食的。