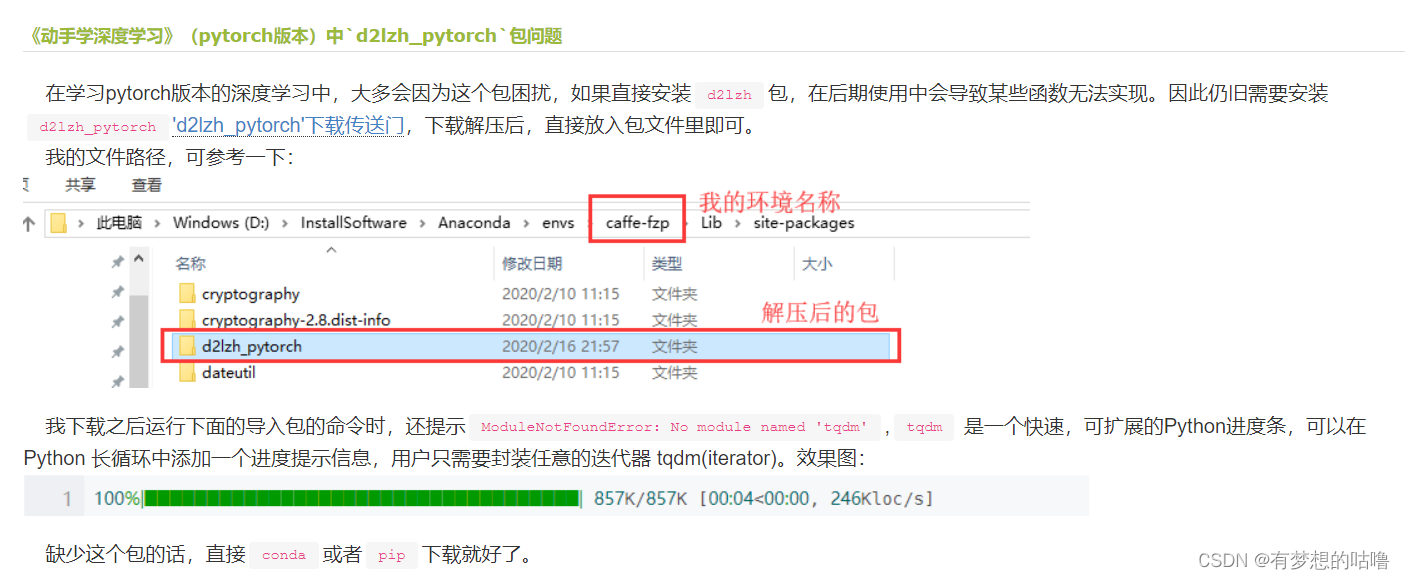
CatBoost是顶尖的机器学习模型之一。凭借其梯度增强技术以及内置函数,可以在不做太多工作的情况下生成一些非常好的模型。SHAP (SHapley Additive exPlanation)是旨在解释具有独特视觉效果和性能价值的机器学习模型的输出。CatBoost和SHAP结合在一起构成了一个强大的组合,可以产生一些非常准确并且可以进行解释的结果。

本文将展示如何一起使用它们来解释具有多分类数据集的结果。
数据集
数据集是一个从Kaggle中获得的12列乘13393行的集合。它包含物理结果以及物理测试的性能结果。目标评分是一个基于A-D的多分类系统。

依赖包
我们需要导入下面的包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
import seaborn as sns
from sklearn import metrics
import plotly.express as px
from sklearn.pipeline import Pipeline
#models
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import BernoulliNB
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import SGDClassifier
from xgboost import XGBClassifier
from catboost import CatBoostClassifier
import xgboost as xgb
import catboost
from sklearn.model_selection import train_test_split
#scoring
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score, precision_score, recall_score, average_precision_score, roc_auc_score, precision_recall_curve, roc_curve, auc
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
import shap
数据清理/ EDA
数据集没有缺失值,所以我们直接进行EDA查看特征的分布并检查异常值。




然后做一下简单的处理,将极端的值删除:
df = df[df['height_cm'] > 130]
df = df[df['weight_kg'] < 120]
数据分割和测试
然后创建了训练/测试分割,并构建了一个管道,并比较了5个分割交叉验证中选择的所有模型。
X = df.drop('class', axis=1)
y = df[['class']]
y = y.values.ravel()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=46)
下面是一些sklearn中常见的模型,我们都直接使用了,作为比较:
#Build pipeline for models
pipeline_lr = Pipeline([('lr_classifier',LogisticRegression())])
pipeline_dt = Pipeline([('dt_classifier',DecisionTreeClassifier())])
pipeline_gbcl = Pipeline([('gbcl_classifier',GradientBoostingClassifier())])
pipeline_rf = Pipeline([('rf_classifier',RandomForestClassifier())])
pipeline_knn = Pipeline([('knn_classifier',KNeighborsClassifier())])
pipeline_bnb = Pipeline([('bnb_classifer',BernoulliNB())])
pipeline_bag = Pipeline([('bag_classifer',BaggingClassifier())])
pipeline_ada = Pipeline([('bnb_classifer',AdaBoostClassifier())])
pipeline_gnb = Pipeline([('gnb_classifer',GaussianNB())])
pipeline_mlp = Pipeline([('mlp_classifer',MLPClassifier())])
pipeline_sgd = Pipeline([('sgd_classifer',SGDClassifier())])
pipeline_xgb = Pipeline([('xgb_classifer',XGBClassifier())])
pipeline_cat = Pipeline([('cat_classifier',CatBoostClassifier(verbose=False))])
# List of all the pipelines
pipelines = [pipeline_lr, pipeline_dt, pipeline_gbcl, pipeline_rf, pipeline_knn, pipeline_bnb, pipeline_bag, pipeline_ada, pipeline_gnb, pipeline_mlp, pipeline_sgd, pipeline_xgb, pipeline_cat]
# Dictionary of pipelines and classifier types for ease of reference
pipe_dict = {0: 'Logistic Regression', 1: 'Decision Tree', 2: 'Gradient Boost', 3:'RandomForest', 4: 'KNN', 5: 'BN', 6:'Bagging', 7:'Ada Boost', 8:'GaussianNB', 9:'MLP Classifier', 10:'SGD Classifier', 11:'XG Boost', 12:'Cat Boost'}
# Fitting the pipelines
for pipe in pipelines:
pipe.fit(X_train, y_train)
列出所有结果以确定最佳模型
cv_results_accuracy = []
for i, model in enumerate(pipelines):
cv_score = cross_val_score(model, X_train,y_train, cv=5)
cv_results_accuracy.append(cv_score)
print("%s: %f " % (pipe_dict[i], cv_score.mean()))

可以看到,虽然CatBoost在CV比较中得分不是最高,虽然CatBoost比XGB低一些,但是它的速度却比XGB快很多,所以我们在这个项目中使用它。
这里还有个信息就是,基本上树形模型得分都很高,也侧面说明了目前树形模型还是处理表格数据的最佳选择。
模型结果
model = CatBoostClassifier(verbose=False)
model.fit(X_train, y_train)
#Print scores for Multiclass
y_test_pred = model.predict(X_test)
y_test_prob = model.predict_proba(X_test)
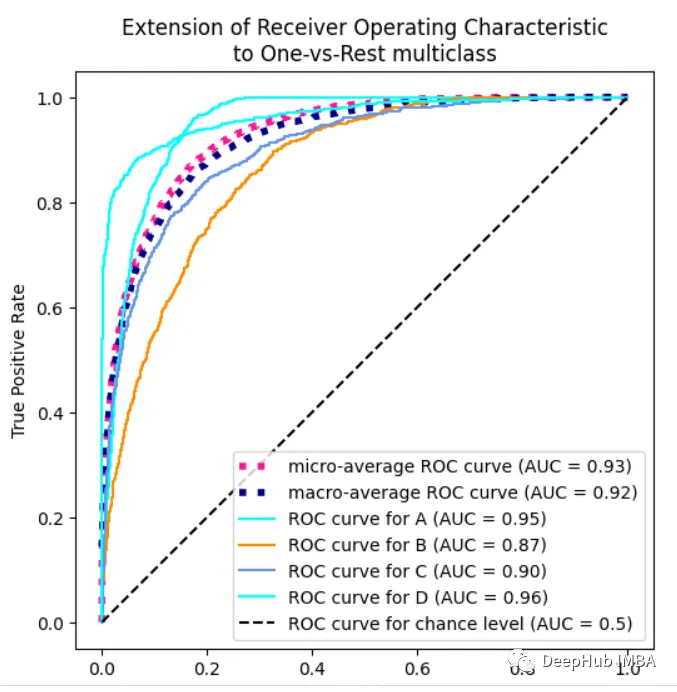
print(metrics.classification_report(y_test, y_test_pred, digits=3))
print('Accuracy score: ', accuracy_score(y_test, y_test_pred))
print('Roc auc score : ', roc_auc_score(y_test, y_test_prob, multi_class='ovr'))
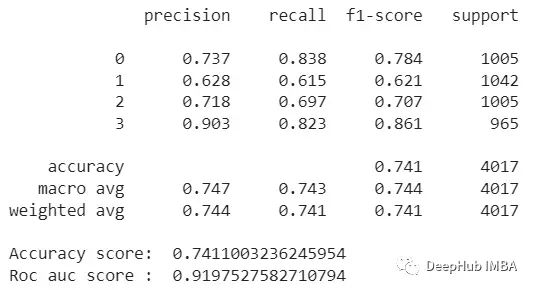
混淆矩阵:
confusion = confusion_matrix(y_test, y_test_pred)
fig = px.imshow(confusion, labels=dict(x="Predicted Value", y="Actual Vlaue"), x=[1,2,3,4],y=[1,2,3,4],text_auto=True, title='Confusion Matrix')
fig.update_layout(title_x=0.5)
fig.show()
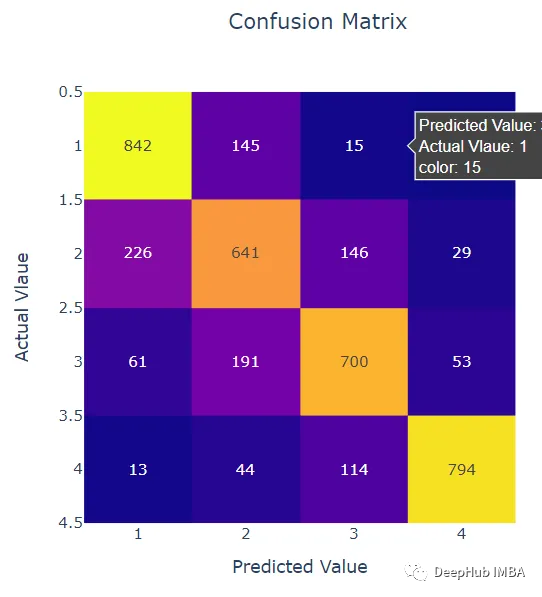
分类的ROC曲线
from itertools import cycle
fig, ax = plt.subplots(figsize=(6, 6))
plt.plot(
fpr["micro"],
tpr["micro"],
label=f"micro-average ROC curve (AUC = {roc_auc['micro']:.2f})",
color="deeppink",
linestyle=":",
linewidth=4,
)
plt.plot(
fpr["macro"],
tpr["macro"],
label=f"macro-average ROC curve (AUC = {roc_auc['macro']:.2f})",
color="navy",
linestyle=":",
linewidth=4,
)
colors = cycle(["aqua", "darkorange", "cornflowerblue"])
for class_id, color in zip(range(n_classes), colors):
RocCurveDisplay.from_predictions(
y_onehot_test[:, class_id],
y_test_prob[:, class_id],
name=f"ROC curve for {target_names[class_id]}",
color=color,
ax=ax,
)
plt.plot([0, 1], [0, 1], "k--", label="ROC curve for chance level (AUC = 0.5)")
plt.axis("square")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Extension of Receiver Operating Characteristic\nto One-vs-Rest multiclass")
plt.legend()
plt.show()
可以看到CatBoost模型的得分非常高,以上都是我们建模的基本操作,下面我们开始加上SHAP
SHAP
为了利用SHAP,我们需要创建一个二元模型,这样它们就可以给出一个明确的方向。所以编写一个新的结果列,将分数从a - d更改为0和1。
def class2(score):
if score > 1:
return 1
else:
return 0
df['class2'] = df['class'].apply(class2)
接下来,要为这个新的二元分数创建一个新的训练/测试分割和CatBoost模型。
下面是二元模型的结果
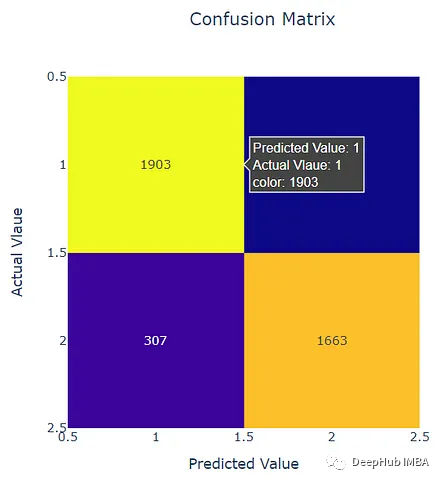
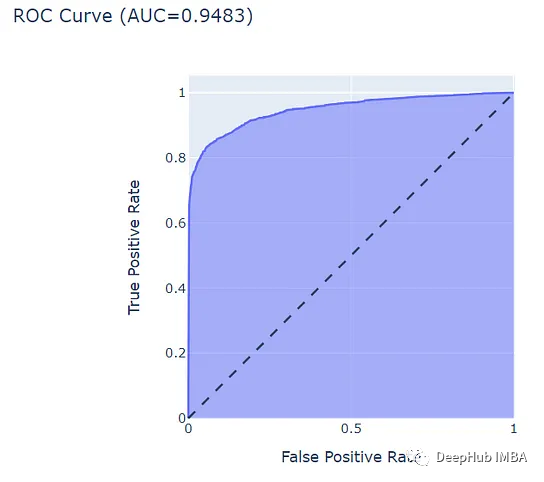
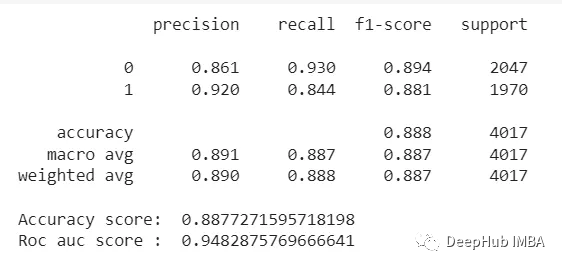
可以看到,结果是优于多分类评分模型的。
下面我们开始使用SHAP。首先是特性重要性,这显示了模型上每个特征的强度。
#Create list for cat features
cat_features = list(range(0, X.shape[1]))
print(cat_features)
#Create feature importance
featurep = model.get_feature_importance(prettified=True)
SHAP特征重要性的结果如下:
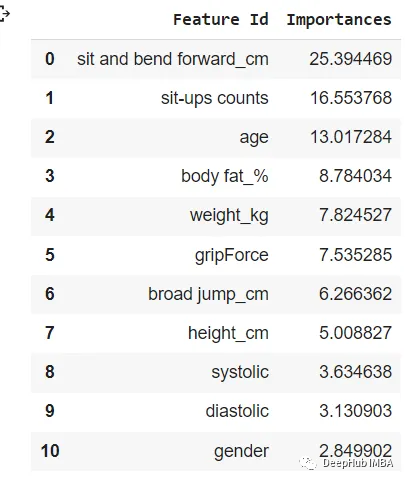
通过可视化可以非常清晰的看到哪些值对模型的影响最大
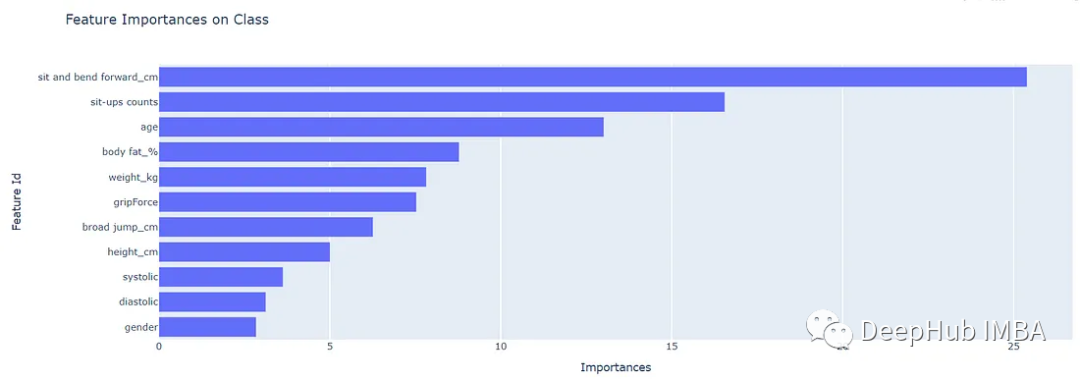
虽然不是每个特征在一个方向上都有重要性那么简单,但它的重要性可以直接分布在每个方向的某个阶段。
我们再看看beeswarm图:
#Create explainer and shap values from model
explainer = shap.Explainer(model2)
shap_values = explainer(X_test2)
#Plot shap beesworm
shap.plots.beeswarm(shap_values)

这是beeswarm分布图。它可以从两个方向显示每个特征和对模型的影响的图(见下图)。并且它还通过颜色和右边的刻度显示了影响,以及通过大小显示的影响的体积。这让我们能够看到每个特征是如何影响分数的,以及在每个特定方向上的影响程度。
我们还可以创建SHAPs决策树图。
#Plot shap decision tree
expected_values = explainer.expected_value
shap_array = explainer.shap_values(X_test2)
shap.decision_plot(expected_values, shap_array[0:10],feature_names=list(X.columns))
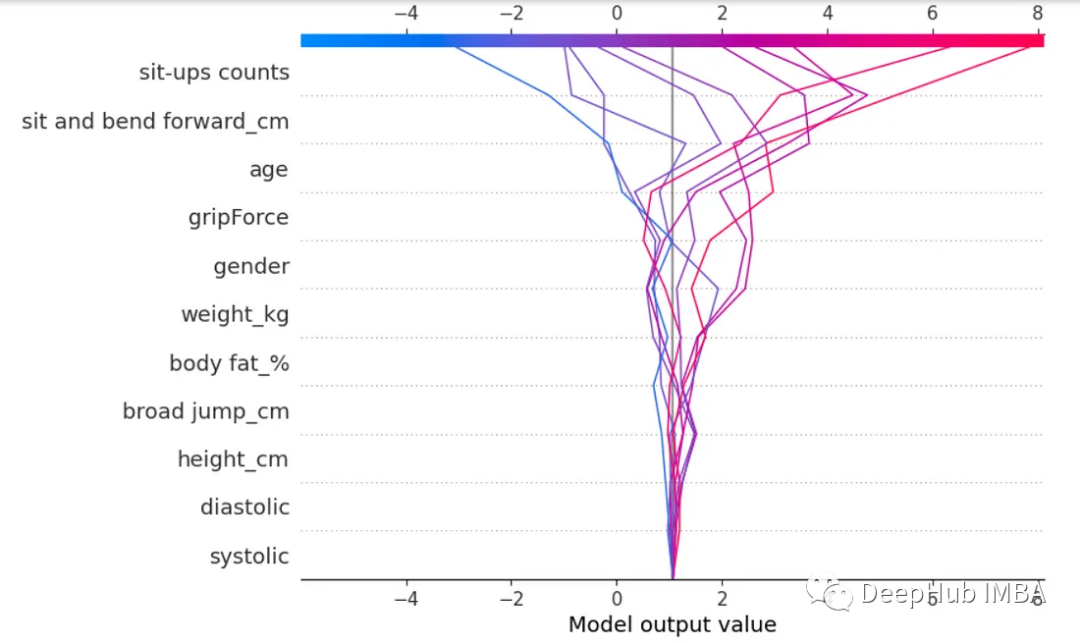
SHAPs的瀑布图显示了单个预测,以及它们如何受到每个特征及其得分的影响。这个瀑布图显示了当每个特征得分被应用时,它们是如何在每个方向上偏离的。这使我们能够看到每个特征对预测的影响。
底部在所有的预测中都没有偏离,但当我们往上看时,可以看到最后几个特征在每个方向上都显著移动。这是观察每个特征如何影响预测/分数的好方法。
我们还可以显示单个预测的瀑布图。下面我们将展示2个预测,一个是正面得分,一个是负面得分。
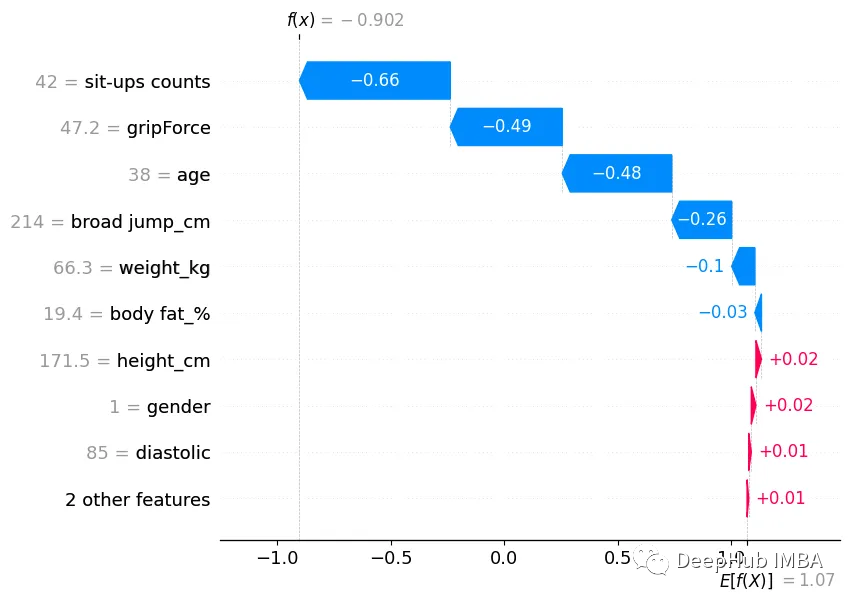
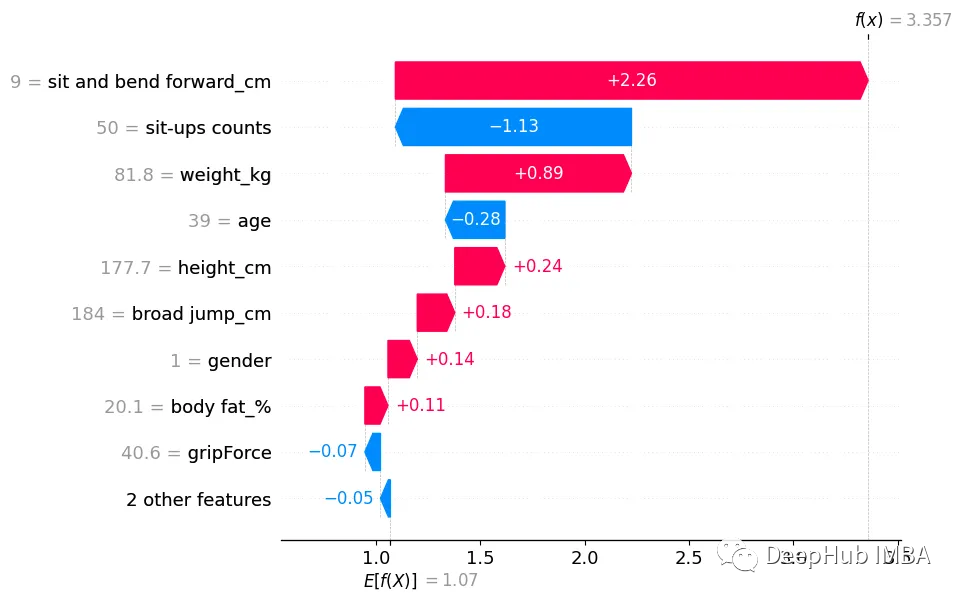
这两个独立的预测瀑布图可以让我们更深入地了解每个特征是如何影响预测分数的。它为我们提供了每个特征的SHAP值和范围以及方向。它还在左侧显示了每个特征的得分。这让我们能够分解每个特征对单个分数或预测的影响。
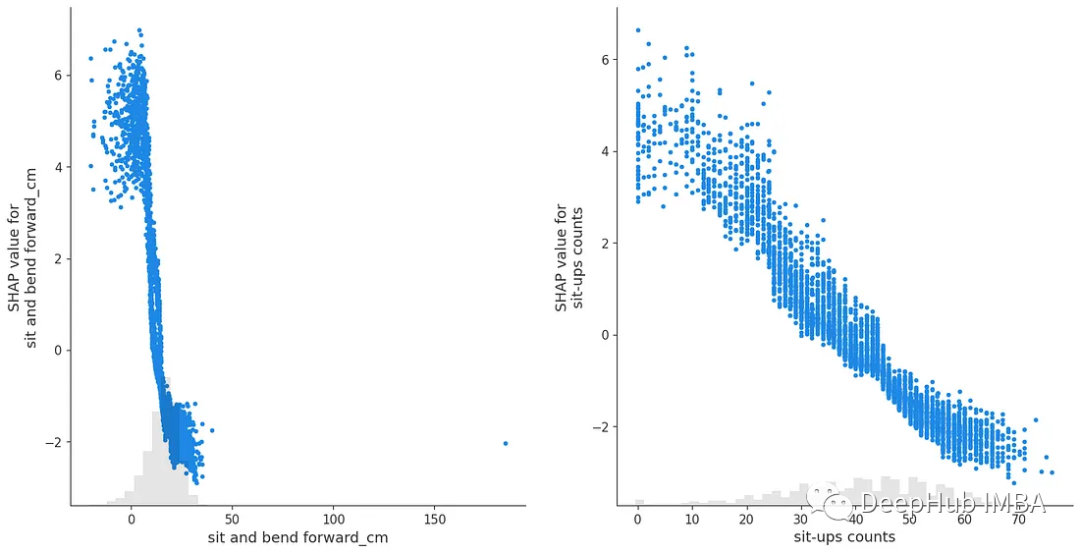
为了更好地了解每个特性,我们还可以使用每个特征的SHAP值创建散点图。
#Create shap scatterplots for important features
fig, ax = plt.subplots(nrows=1, ncols=2,figsize=(16,8))
#SHAP scatter plots
shap.plots.scatter(shap_values[:,"sit and bend forward_cm"],ax=ax[0],show=False)
shap.plots.scatter(shap_values[:,"sit-ups counts"],ax=ax[1])
shap.plots.scatter(shap_values[:,"weight_kg"],ax=ax[0],show=False)
shap.plots.scatter(shap_values[:,"gender"],ax=ax[1])
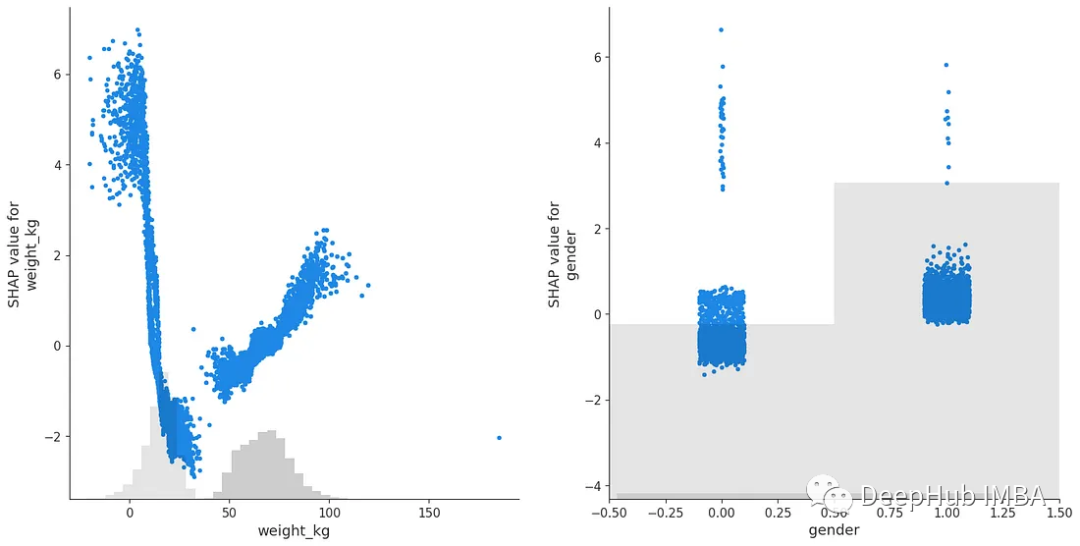
SHAP值的散点图在x轴上显示特征的分数,在y轴上显示其SHAP值。这让我们可以看到特征在其SHAP值的每个方向上的得分。
我们可以看到,SHAP值的散点图可能看起来非常不同,并且可以向我们展示关于每个属性如何对总分做出贡献的许多不同类型的见解。
总结
本文的示例展示了CatBoost的强大功能,它可以轻松创建一个良好的评分模型。但是更重要的是我们展示了SHAP在分析模型特征方面的强大功能。它允许我们从许多不同的角度来看特征,而不是我们可以用普通的EDA和相关性来探索。它确实名副其实的附加解释,可以通过模型进行预测建模,让我们深入了解特征本身。
完整代码:
https://avoid.overfit.cn/post/e0b9e5e6712048dba754cae5c1269b9b
作者:lochie links