零样本语音转换在转换时只需目标说话人的一段语音,更适合实际应用需求,具有广泛应用前景。 现有工作只考虑内容和音色表征的解耦,没有考虑与语音旋律相关的 韵律 和 音高 表征,导致与音高和韵律相关的信息泄露到音色中。 本文利用互信息解耦韵律、音高、内容和音色四个表征,通过对抗学习改善解耦性能和鲁棒性。 在VCTK数据集上的实验表明,所提模型在自然度和可懂度方面达到最优的零样本语音转换性能,其梅尔倒谱失真(MCD)为5.23dB、字符错误率(CER)为9.60%、单词错误率(WER)为14.81%、F0的皮尔逊相关系数(PCC)为0.768。 基于本文所提方法,在音色、音高和韵律上均能实现零样本语音转换。
扫码阅读论文
https://arxiv.org/abs/2208.08757
合成样例试听
https://im1eon.github.io/IS2022-SRDVC/
01 背景动机
语音转换(voice conversion, VC)是研究如何将一个人的声音转换为另一个人的声音,同时保留源说话人的语言内容的任务。 零样本语音转换在推理阶段只使用目标说话人的一段话语。 由于零样本VC仅需要目标说话人少量的数据,所以更适合实际应用的需要。 与传统的VC相比,零样本VC更具挑战性。 由于语音表征分离(speech representation disentanglement, SRD)能够解耦潜空间,许多零样本VC的工作都是基于SRD,其目的是尽可能地将说话人信息与语音内容分离。
语音信息可以被分解成四个部分: 内容、音色、音高和韵律。 韵律的特点是说话者说出每个音节的速度。 音高是声音的一个重要组成部分。 显然,韵律和音高的表示与内容有关,是提高转换后语音自然度的重要的语音表示。 现有VC的相关工作只考虑了内容和音色表征的解耦,而没有考虑与语音的旋律相关的韵律和音高表征,这可能导致与音高和韵律相关的信息泄露到音色中。
最近的研究开始研究VC中的音高和韵律,如SpeechSplit, SpeechSplit2.0和MAP网络。 然而,它们在零样本VC中的性能仍然需要进一步改善。 最近的VQMIVC提供了音高信息,以保留源音高的变化,从而获得高质量的零样本VC。 然而,它没有考虑韵律的解耦,导致音高和韵律仍然耦合在一起。
02 贡献
本文提出了基于对抗互信息学习特征解耦的零样本语音转换模型。 具体来说,我们首先将语音解耦为四个表征: 韵律、音高、内容和音色。 然后,我们提出一个基于对抗互信息学习特征解耦的零样本语音转换模型,由四个部分组成: (1) 对音高和内容进行沿时间维度的随机重采样操作,以消除韵律信息; (2) 对音色使用普通分类器,以提取与说话人身份有关的特征,对与说话人无关的信息(内容、音高和韵律)使用基于梯度反转层(gradient reversal layer, GRL)的对抗性分类器,以消除潜空间中的说话人信息。 (3) 不同表征之间的相互信息(mutual information, MI)的变异对数上界(variational contrastive log-ratio upper bound, vCLUB)被用来将说话人无关的信息相互分离; (4) 使用音高解码器来重建归一化音高轮廓,并采用语音解码器来重建Mel谱图。 我们工作的主要贡献是: (1) 将内容、音色、韵律和音高与语音解耦实现零样本VC,确保音高、韵律和内容与说话者无关,使音色与说话者更相关。 (2) 在不依赖文本的情况下,应用基于vCLUB和GRL的对抗互信息学习的SRD。 实验表明,通过应用对抗相互信息学习,可以有效缓解信息泄露问题。
03 解决方案
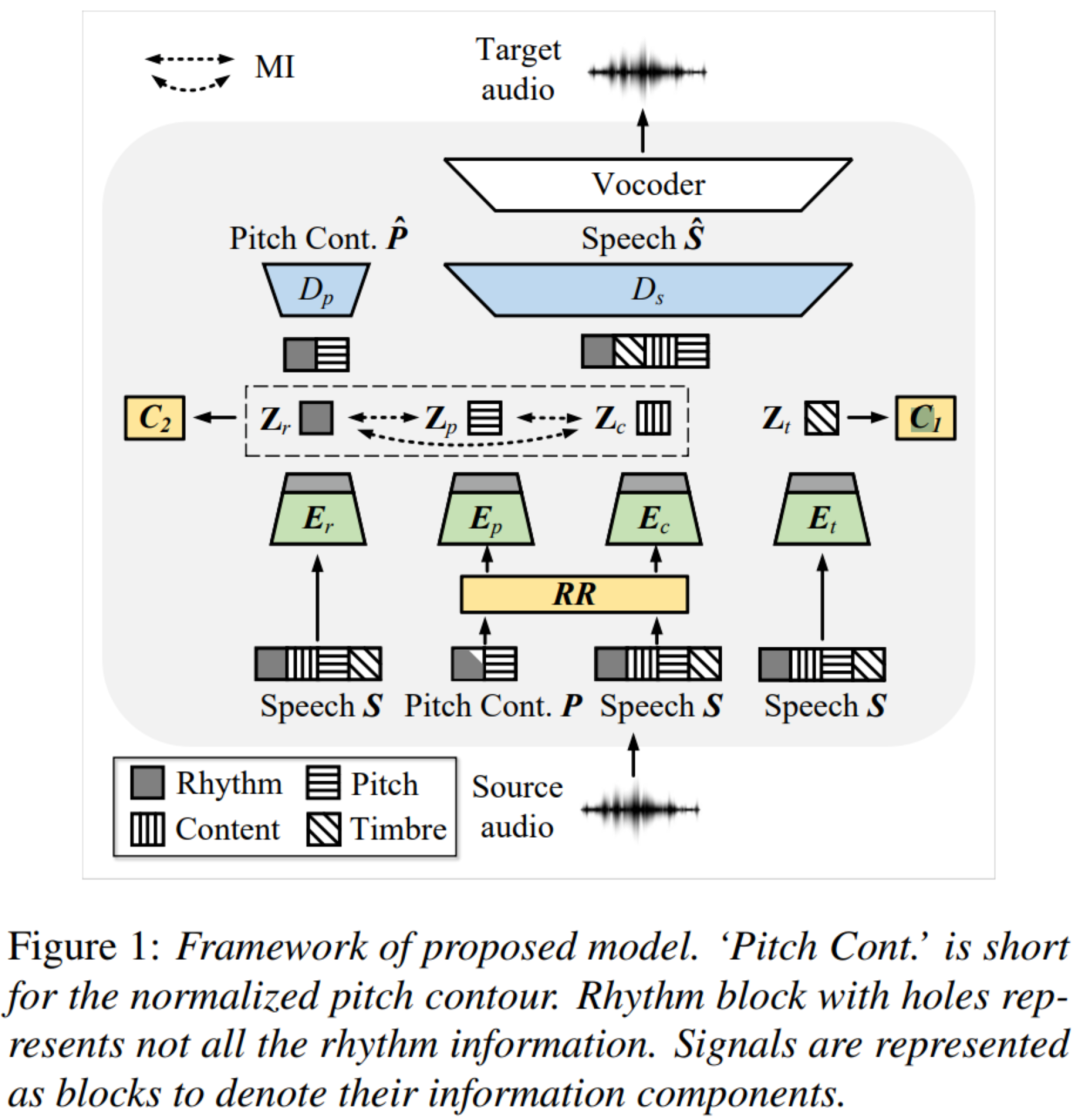
如图所示,所提模型的架构由六个模块组成: 韵律编码器、音高编码器、内容编码器、音色编码器、音高解码器和语音解码器。
语音表征编码器。 受SpeechSplit启发,韵律编码器、音高编码器、内容编码器使用相同的结构,由5×1卷积层和双向长短期记忆(BiLSTM)层堆叠而成。 除了Mel谱图,音高轮廓也带有韵律的信息。 在输入的Mel谱图和归一化的音高轮廓被送入内容编码器和音高编码器之前,沿时间维度进行随机重采样操作以去除韵律信息。 该模型依靠韵律编码器来恢复韵律信息。 说话人编码器用来提供全局语音特征,以控制说话人身份。
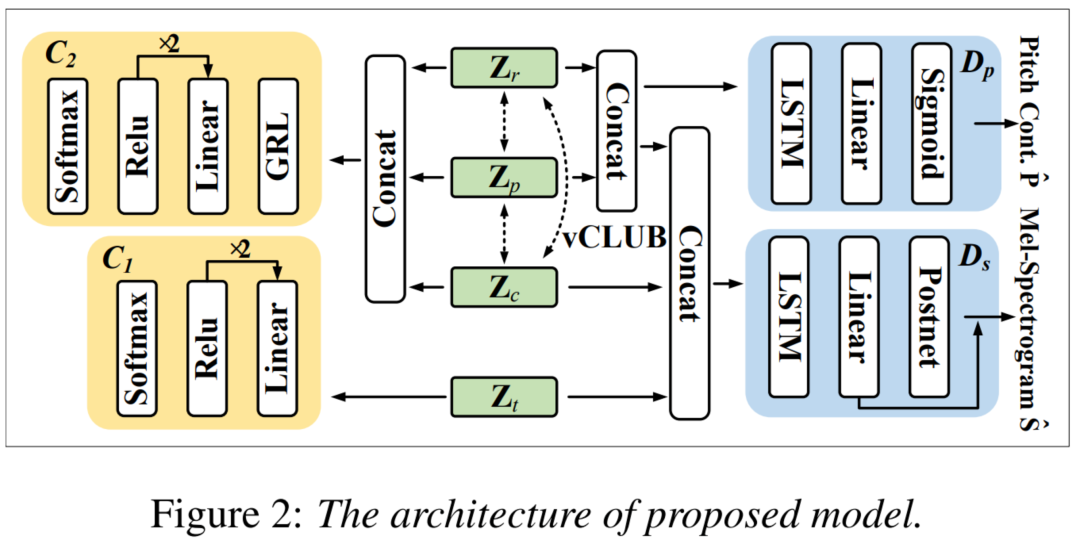
解码器。 语音解码器将所有编码器的输出作为其输入,并输出Mel谱图。 音高解码器的输出是归一化音高轮廓。 上图展示了实验中使用的网络结构。
对抗互信息学习
如上图所示,我们使用普通分类器C1和对抗性说话人分类器C2来识别说话人的身份。 vCLUB被用来计算说话人无关信息的MI的上限。
梯度反转。 如上图所示,C2使用GRL对抗性分类器。
互信息。 互信息的VCLUB被定义为:
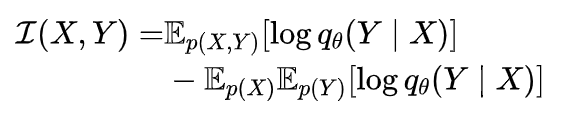
样本的VCLUB的无偏估计为:
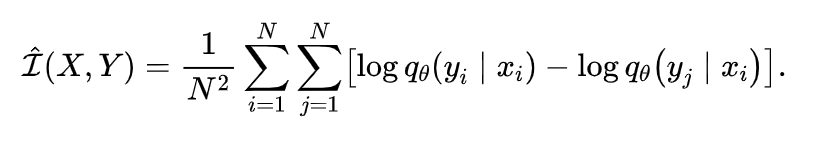
通过最小化以上方程,我们可以减少不同说话人无关的语音表征之间的相关性。
在不同的语音表征上的零样本VC
以一般语音转换(音色转换)为例。 韵律、音高和内容的表示是从源说话人的语音中提取的。 而音色是从目标说话人的语音中提取的。 为了转换韵律,我们将目标语音送入韵律编码器。 如果要转换音高,我们把目标说话人的归一化音高轮廓送入音高编码器。 此外,三种双方面的转换(韵律+音高,韵律+音色,音高+音色)和全方面的转换是相似的。
04 实验验证
不同表征转化可视化
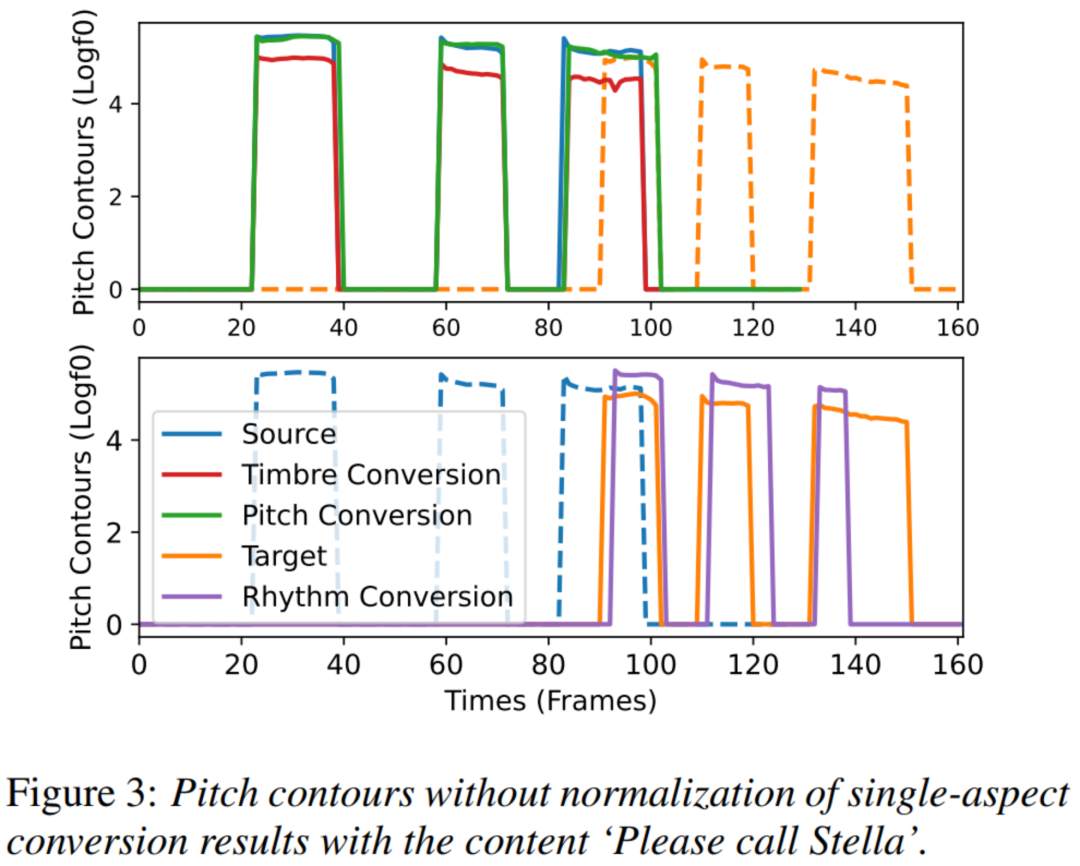
上图显示了内容为 "Please call Stella "的源语音(女性说话人)、目标语音(男性说话人)和转换后语音的音高轮廓。 请注意,我们仅使用平行的语音数据来直观地显示结果。 对于音色转换,转换后的语音的音高轮廓与目标语音的平均音高一致,但保留了源音高轮廓的详细特征。 另一方面,对于音高转换,转换后的音高轮廓试图重建目标语音的细节特征,其平均音高值接近源音高。 对于韵律转换,转换后的音高轮廓如预期般位于目标位置。 此外,上图中的音色转换结果也证实了一个常识,即 从女性到男性 转换后的语音的平均音高有所下降。
主观评价
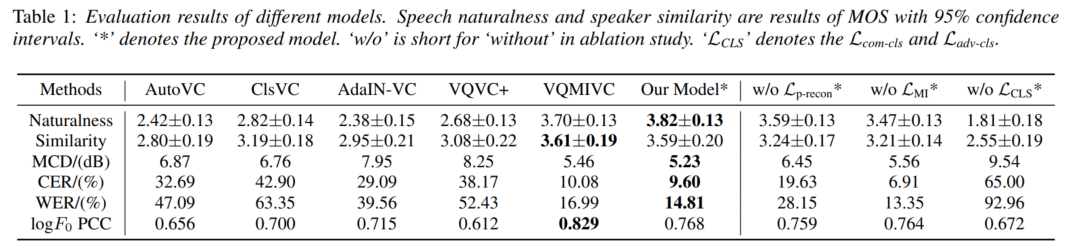
主观测试由32名英语水平良好的听众进行,以评估由不同模型生成的转换后的语音自然度和说话人相似度。 语音音频以随机顺序呈现给受试者。 受试者被要求在1-5分的范围内对演讲进行评分,评分间隔为1分。 上表的前两行报告了对自然度和说话人相似度的平均意见分数(MOS)。 所提出的模型在语音自然度方面优于所有基线模型,在说话人相似度方面与VQMIVC的性能相当。
客观评价
对于客观评价,我们使用了logF0的梅尔倒谱失真(MCD)、字符错误率(CER)、单词错误率(WER)和皮尔逊相关系数(PCC)。 MCD测量两个音频片段之间的频谱距离。 MCD越低,失真越小,意味着两个音频段之间的相似度越高。 为了获得预测结果和参考结果时间维度上的一致性,我们使用动态时间扭曲(DTW)。 CER和WER评估转换后的语音是否保持源语音的语言内容。 CER和WER是由ESPnet2提供的在Librispeech上训练的基于Transformer的语音识别(ASR)模型计算的。 为了评估转换后语音的音高变化,计算了源语音和转换后语音的F0之间的PCC。 为了客观地评估所提出的方法,我们随机选择了50个转换对。 不同方法的结果显示在上表中。 可以看出,我们提出的模型在MCD上优于基线系统。 我们的模型在所有方法中取得了最低的CER和WER,这表明我们提出的方法在保留源语言内容的前提下具有更好的可理解性。 此外,我们的模型实现了更高的对数F0 PCC,这表明我们的模型有能力将源语音的详细语调变化转化并保存到转换后的语音中。 VQMIVC的LogF0 PCC较高,因为音高信息直接输入到解码器,而不经过随机重采样操作和音高编码器。
说话人嵌入可视化
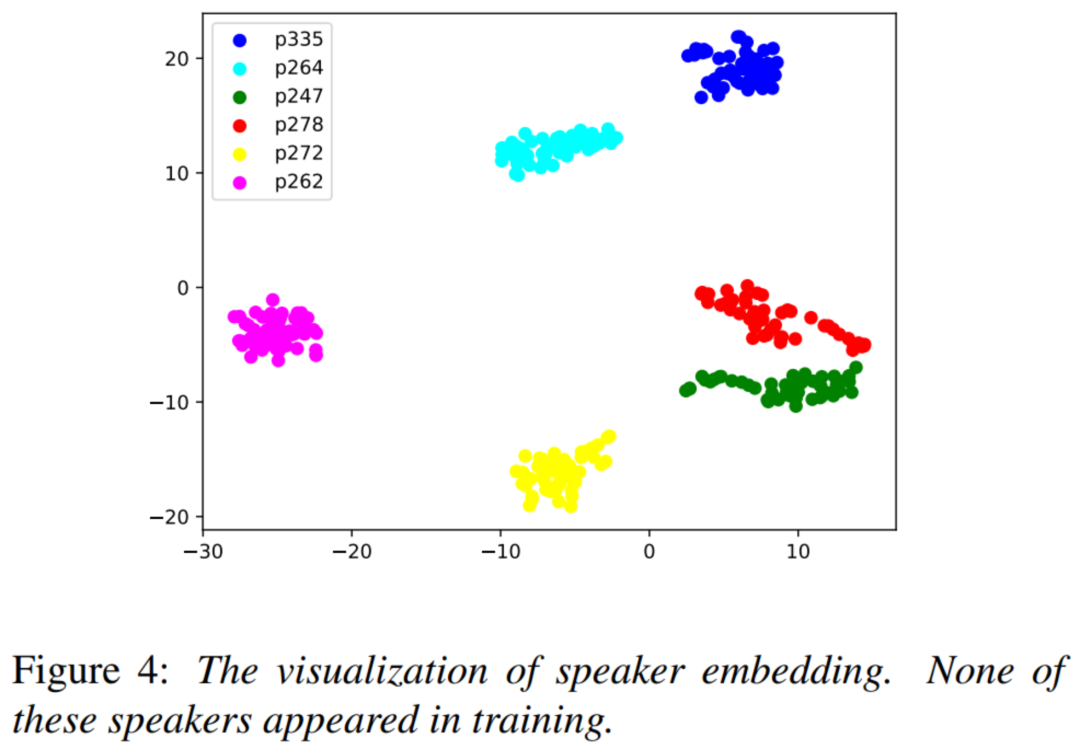
此外,上图显示了用tSNE方法可视化的不同说话人的音色嵌入。 每个说话人都有50个语音样本来计算音色表示。 可以看出,不同说话者的音色嵌入是可分离的。 相比之下,同一说话人语音的音色嵌入是相互接近的。 这一结果表明,我们的音色编码器能够提取包含说话人信息的音色。
05 结语
在本文中,基于语音特征解耦,我们提出了一种使用对抗互信息学习的方法进行零样本VC。 为了使音色尽可能地与说话人相似,我们对于音色使用普通分类器。 同时,我们使用GRL来使与说话人无关的信息尽可能地与说话人分开。 然后,音高和内容信息可以通过随机重采样从韵律信息中去除。 音高解码器确保音高编码器得到正确的音高信息。 vCLUB使与说话人无关的信息尽可能地分离。 我们实现了韵律、内容、说话人和音高表征的适当分离,并且能够在零样本VC中分别转换不同的语音表征。 语音特征解耦提高了零样本VC的自然性和可懂度,而SRD的性能和鲁棒性则通过互信息学习得到改善。