我相信很多人跟我一样,学习机器学习和数据科学的第一个算法是线性回归,它简单易懂。由于其功能有限,它不太可能成为工作中的最佳选择。大多数情况下,线性回归被用作基线模型来评估和比较研究中的新方法。
在处理实际问题时,你应该了解并尝试许多其他回归算法。一方面可以系统学习回归算法,另外一方面在面试中也常用到这些算法。
在本文中,我们将通过使用 Scikit-learn 和 XGBoost 的动手实践来学习 9 种流行的回归算法。 喜欢本文记得收藏、点赞。
结构如下:
- 线性回归
- 多项式回归
- 支持向量机回归
- 决策树回归
- 随机森林回归
- LASSO 回归
- Ridge 回归
- ElasticNet 回归
- XGBoost 回归
技术提升
本文由技术群粉丝分享,项目源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:mlc2060,备注:来自CSDN +研究方向
方式②、微信搜索公众号:机器学习社区,后台回复:加群
线性回归
线性回归通常是人们学习机器学习和数据科学的第一个算法。线性回归是一种线性模型,它假设输入变量 (X) 和单个输出变量 (y) 之间存在线性关系。 一般来说,有两种情况:
- 单变量线性回归:它对单个输入变量(单个特征变量)和单个输出变量之间的关系进行建模。
- 多变量线性回归(也称为多元线性回归):它对多个输入变量(多个特征变量)和单个输出变量之间的关系进行建模。
这个算法很常见,以至于 Scikit-learn 在 LinearRegression() 中内置了这个功能。 让我们创建一个 LinearRegression 对象并将其拟合到训练数据中:
from sklearn.linear_model import LinearRegression
# Creating and Training the Model
linear_regressor = LinearRegression()
linear_regressor.fit(X, y)
训练完成后,我们可以在 coef_ 属性中检查 LinearRegression 找到的系数参数:
linear_regressor.coef_
array([[-0.15784473]])
现在采用该模型并为训练数据拟合一条线
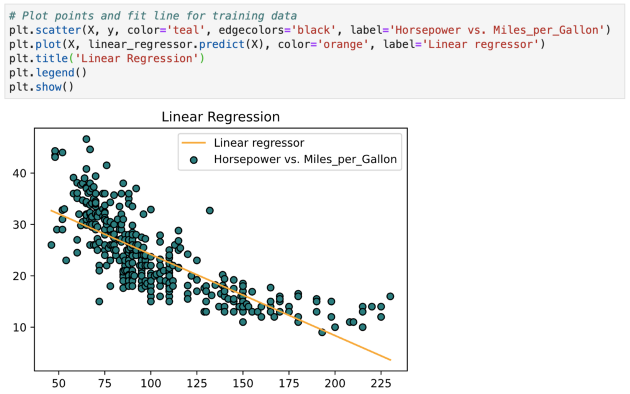
关于线性回归的几个关键点:
- 快速且易于建模
- 当要建模的关系不是非常复杂并且您没有大量数据时,它特别有用。
- 非常直观的理解和解释。
- 它对异常值非常敏感。
多项式回归
当我们想要为非线性可分数据创建模型时,多项式回归是最受欢迎的选择之一。它类似于线性回归,但使用变量 X 和 y 之间的关系来找到绘制适合数据点的曲线的最佳方法。
对于多项式回归,一些自变量的幂大于 1。例如,我们可能会提出如下二次模型:
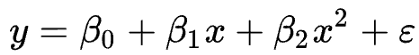
Scikit-learn 的 PolynomialFeatures 内置了这种方法。 首先,我们需要生成一个由所有具有指定度数的多项式特征组成的特征矩阵:
from sklearn.preprocessing import PolynomialFeatures
# We are simply generating the matrix for a quadratic model
poly_reg = PolynomialFeatures(degree = 2)
X_poly = poly_reg.fit_transform(X)
接下来,让我们创建一个LinearRegression 对象并将其拟合到我们刚刚生成的特征矩阵 X_poly 中。
# polynomial regression model
poly_reg_model = LinearRegression()
poly_reg_model.fit(X_poly, y)
现在采用该模型并为训练数据 X_plot 拟合一条线,如下所示:
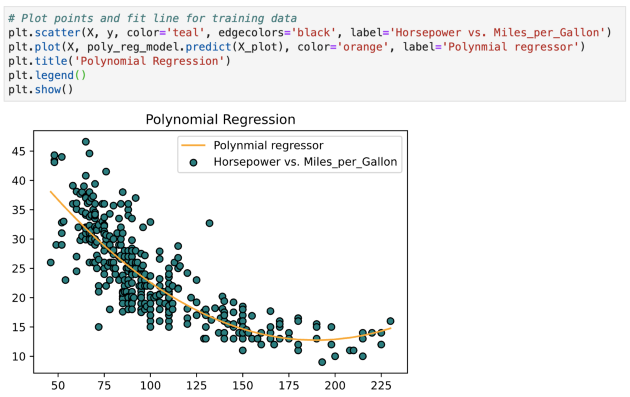
关于多项式回归的几个关键点:
- 能够对非线性可分数据进行建模;线性回归不能做到这一点。一般来说,它更加灵活,可以对一些相当复杂的关系进行建模。
- 完全控制特征变量的建模(要设置的指数)。
- 需要精心设计。 需要一些数据知识才能选择最佳指数。
- 如果指数选择不当,则容易过度拟合。
支持向量机回归
支持向量机在分类问题中是众所周知的。SVM 在回归中的使用称为支持向量回归(SVR)。Scikit-learn在 SVR()中内置了这种方法。
在拟合 SVR 模型之前,通常最好的做法是执行特征缩放,以便每个特征具有相似的重要性。 首先,让我们使用 StandardScaler() 执行特征缩放:
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
# Performing feature scaling
scaled_X = StandardScaler()
scaled_y = StandardScaler()
scaled_X = scaled_X.fit_transform(X)
scaled_y = scaled_y.fit_transform(y)
接下来,我们创建一个 SVR 对象,内核设置为“rbf”,伽马设置为“auto”。 之后,我们调用 fit() 使其适合缩放的训练数据:
svr_regressor = SVR(kernel='rbf', gamma='auto')
svr_regressor.fit(scaled_X, scaled_y.ravel())
现在采用该模型并为训练数据 scaled_X 拟合一条线,如下所示:
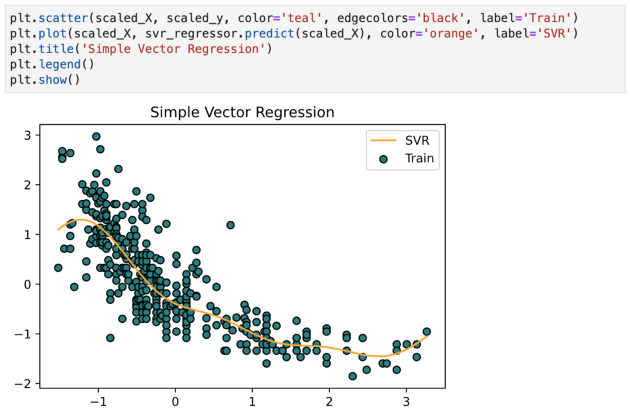
关于支持向量回归的几个关键点
- 它对异常值具有鲁棒性,并且在高维空间中有效
- 它具有出色的泛化能力(能够正确适应新的、以前看不见的数据)
- 如果特征数量远大于样本数量,则容易过拟合
决策树回归
决策树是一种用于分类和回归的非参数监督学习方法。目标是创建一个模型,通过学习从数据特征推断出的简单决策规则来预测目标变量的值。 一棵树可以看作是一个分段常数近似。
决策树回归也很常见,以至于 Scikit-learn 将它内置在 DecisionTreeRegressor 中,可以在没有特征缩放的情况下创建 DecisionTreeRegressor 对象,如下所示:
from sklearn.tree import DecisionTreeRegressor
tree_regressor = DecisionTreeRegressor(random_state = 0)
tree_regressor.fit(X, y)
现在采用该模型并将其拟合到训练数据中:
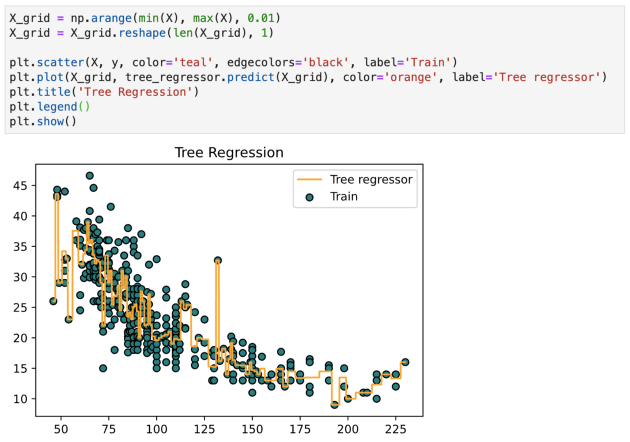
关于决策树的几个关键点:
- 易于理解和解释。树可以可视化。
- 适用于分类值和连续值
- 使用 DT(即预测数据)的成本与用于训练树的数据点数量成对数
- 决策树的预测既不平滑也不连续(如上图所示为分段常数近似)
随机森林回归
随机森林回归基本上与决策树回归非常相似。 它是一个元估计器,可以在数据集的各种子样本上拟合多个决策树,并使用平均来提高预测准确性和控制过拟合。
随机森林回归器在回归中可能会或可能不会比决策树表现更好(虽然它通常在分类中表现更好),因为树构造算法本质上存在微妙的过拟合 - 欠拟合权衡。
随机森林回归很常见,以至于 Scikit-learn 将它内置在 RandomForestRegressor 中。 首先,我们需要创建一个具有指定数量的估计器的 RandomForestRegressor 对象,如下所示:
from sklearn.ensemble import RandomForestRegressor
forest_regressor = RandomForestRegressor(
n_estimators = 300,
random_state = 0
)
forest_regressor.fit(X, y.ravel())
现在采用该模型并将其拟合到训练数据中:
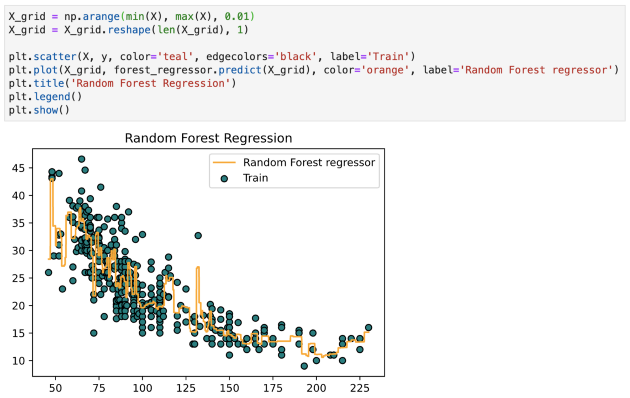
关于随机森林回归的几点:
- 减少决策树中的过度拟合并提高准确性
- 它也适用于分类值和连续值
- 需要大量计算能力和资源,因为它适合许多决策树来组合它们的输出
LASSO 回归
LASSO 回归是使用收缩的线性回归的变体。收缩是将数据值收缩到中心点作为平均值的过程。这种类型的回归非常适合显示重度多重共线性(特征相互之间高度相关)的模型。
Scikit-learn 内置在 LassoCV 中。
from sklearn.linear_model import LassoCV
lasso = LassoCV()
lasso.fit(X, y.ravel())
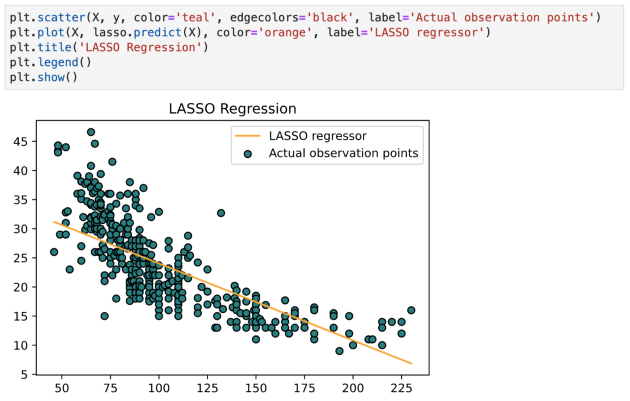
关于 Lasso 回归的几点:
- 它最常用于消除自动变量和选择特征。
- 它非常适合显示重度多重共线性(特征相互之间高度相关)的模型。
- LASSO 回归利用 L1 正则化
- LASSO 回归被认为比 Ridge 更好,因为它只选择了一些特征并将其他特征的系数降低到零。
岭回归
岭回归与 LASSO 回归非常相似,因为这两种技术都使用了收缩。 Ridge 和 LASSO 回归都非常适合显示重度多重共线性(特征相互之间高度相关)的模型。 它们之间的主要区别在于 Ridge 使用 L2 正则化,这意味着没有一个系数会像 LASSO 回归中那样变为零(而是接近零)。
Scikit-learn 内置在 RidgeCV 中。
from sklearn.linear_model import RidgeCV
ridge = RidgeCV()
ridge.fit(X, y)
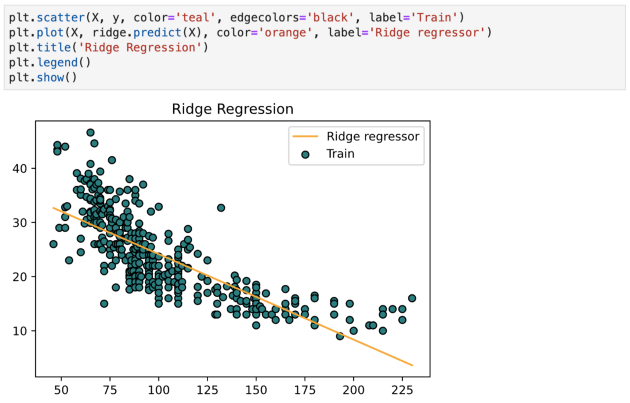
关于岭回归的几点:
- 它非常适合显示重度多重共线性(特征相互之间高度相关)的模型。
- 岭回归使用 L2 正则化。 贡献较小的特征将具有接近于零的系数。
- 由于 L2 正则化的性质,岭回归被认为比 LASSO 更差
ElasticNet 回归
ElasticNet 是另一个使用 L1 和 L2 正则化训练的线性回归模型。它是 Lasso 和 Ridge 回归技术的混合体,因此它也非常适合显示重度多重共线性(特征相互之间高度相关)的模型。
在 Lasso 和 Ridge 之间进行权衡的一个实际优势是它允许 Elastic-Net 在旋转下继承 Ridge 的一些稳定性。Scikit-learn 内置在 ElasticNetCV 中。
from sklearn.linear_model import ElasticNetCV
elasticNet = ElasticNetCV()
elasticNet.fit(X, y.ravel())
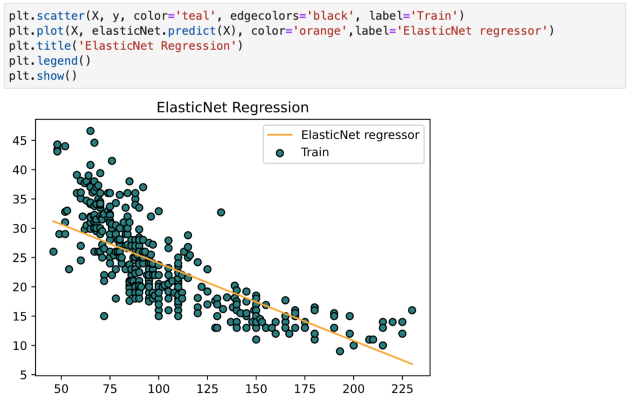
XGBoost 回归
XGBoost 是梯度提升算法的一种高效且有效的实现。梯度提升是指一类可用于分类或回归问题的集成机器学习算法。
XGBoost 是一个开源库,最初由 Chen Tianqi Chen 在其 2016 年题为“XGBoost: A Scalable Tree Boosting System”的论文中开发。 该算法被设计为在计算上既高效又高效。
第一步是安装 XGBoost 库(如果尚未安装)
pip install xgboost
可以通过创建 XGBRegressor 的实例来定义 XGBoost 模型:
from xgboost import XGBRegressor
# create an xgboost regression model
model = XGBRegressor(
n_estimators=1000,
max_depth=7,
eta=0.1,
subsample=0.7,
colsample_bytree=0.8,
)
model.fit(X, y)
- n_estimators:集成中树的数量,通常会增加,直到看不到进一步的改进。
- max_depth:每棵树的最大深度,通常值在 1 到 10 之间。
- eta:用于加权每个模型的学习率,通常设置为较小的值,例如 0.3、0.1、0.01 或更小。
- subsample:每棵树中使用的样本数,设置为 0 和 1 之间的值,通常为 1.0 以使用所有样本。
- colsample_bytree:每棵树中使用的特征(列)数,设置为 0 到 1 之间的值,通常为 1.0 以使用所有特征。
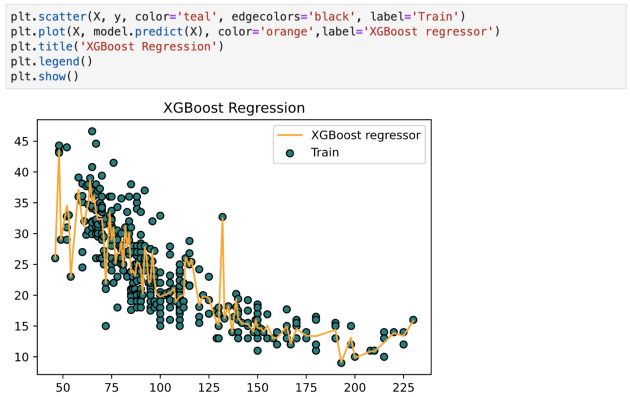
关于 XGBoost 的几点:
- XGBoost 在稀疏和非结构化数据上表现不佳。
- 该算法被设计为计算效率和高效,但是对于大型数据集的训练时间仍然相当长
- 它对异常值很敏感
结论
在本文中,我们介绍了 9 种流行的回归算法,并使用 Scikit-learn 和 XGBoost 进行了动手实践。最好将它们放在您的工具箱中,这样您就可以尝试不同的算法并为实际问题找到最佳回归模型。