今天被面试 问麻了。第一个问题是:
一个类有私有的变量,如果修改这个类的私有变量。使用setter方法除外。(后来才知道用反射)
算了,我还是太水了。回归主题。
线程池的优点:
(1):降低资源消耗,通过重读利用已经创建的线程降低线程创建和销毁造成的消耗
(2):提高响应速度
(3):提高线程的管理学。使用线程池可以统一分配,调优和监控
线程池的流程:
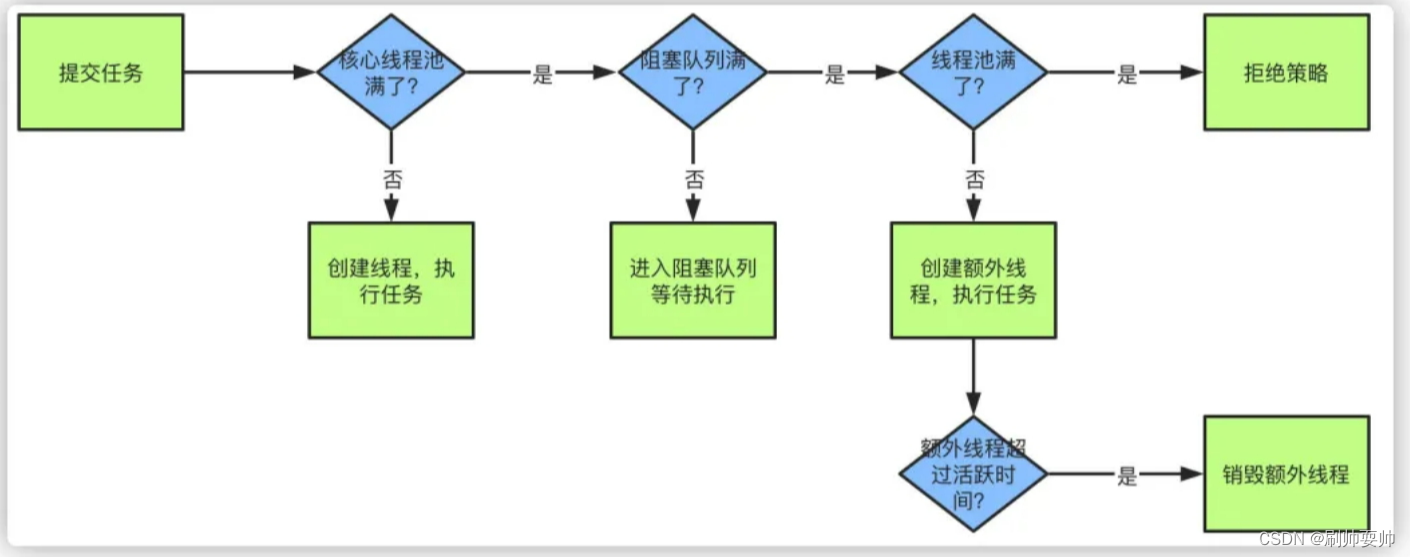
1.当我提交任务时,线程池会根据corePoolSize大小创建若干任务数量线程执行任务
2.当任务数量超过corePoolSize,后续的任务会进入阻塞队列进行排队
3.当阻塞队列也满了以后,就会 (maximumPoolSize - corePoolSize)[最大线程数-核心线程数]个额外线程去执行任务。
4.当额外线超过活跃时间,则销毁额外线程
简单来说就是优先核心线程,其次等待队列,最后非核心线程。
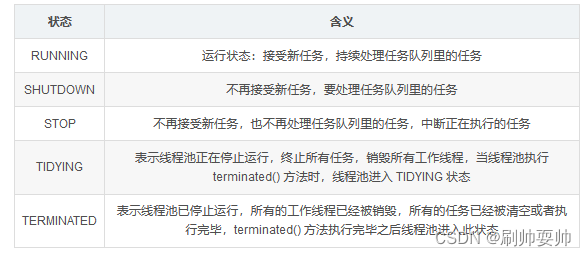
线程池的状态:

接下来就是面试重点:手动创建线程池。必看。不懂就背会,会吹就行。能进去再说。
定制线程池数量从两个方面考虑:
CPU密集型:
需要大量的CPU计算时,如加密,计算hash值时。最佳线程数(核心线程数+1).比如8核CPU时,可以吧线程数设置为9.因为CPU密集的业务场景中,每个线程都会在较大的负荷下工作。很少出现空闲的场景。正好每个线程对应一个CPU核心。这样就实现了最优利用率。多出的已成线程启动备胎作用。在其他线程,意外中断时,顶上去。不过我认为没有必要这么死板,线程数设置CPU核心数的1-2倍都是可以接受的。
I/O密集型
比如读写数据库,读写文件等场景。各种I/0设备的读写速度低于CPU执行速度。所以线程大部门时间都是等待资源而非CPU时间片。这样的话,一个CPU核心就可以应付很多线程了。
为什么手动创建线程池?
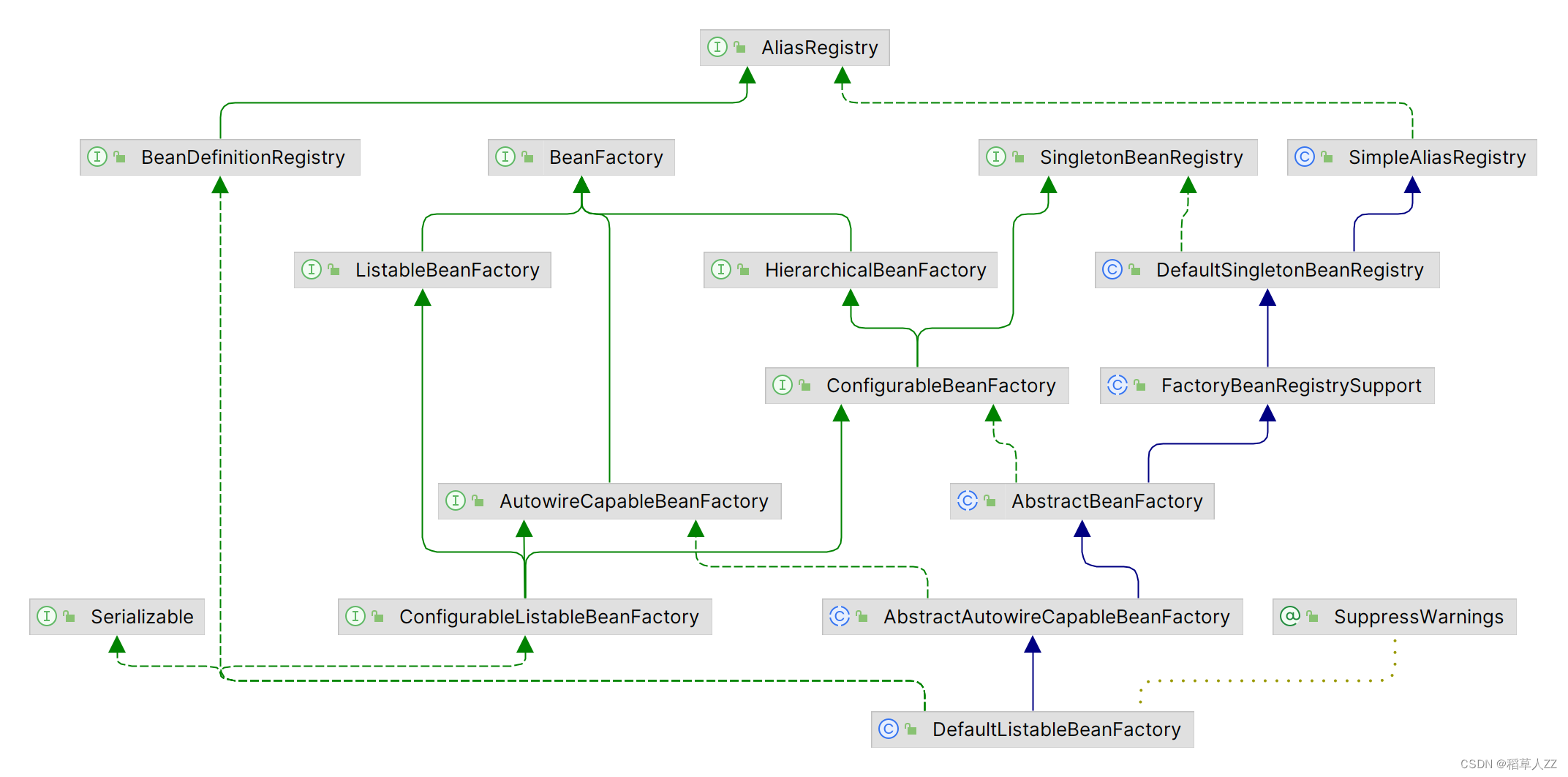
我们之所以要手动创建线程池,是因为 JDK 自带的工具类所创建的线程池存在一定的弊端,那究竟存在怎么样的弊端呢?首先来回顾一下 JDK 中线程池框架的继承关系
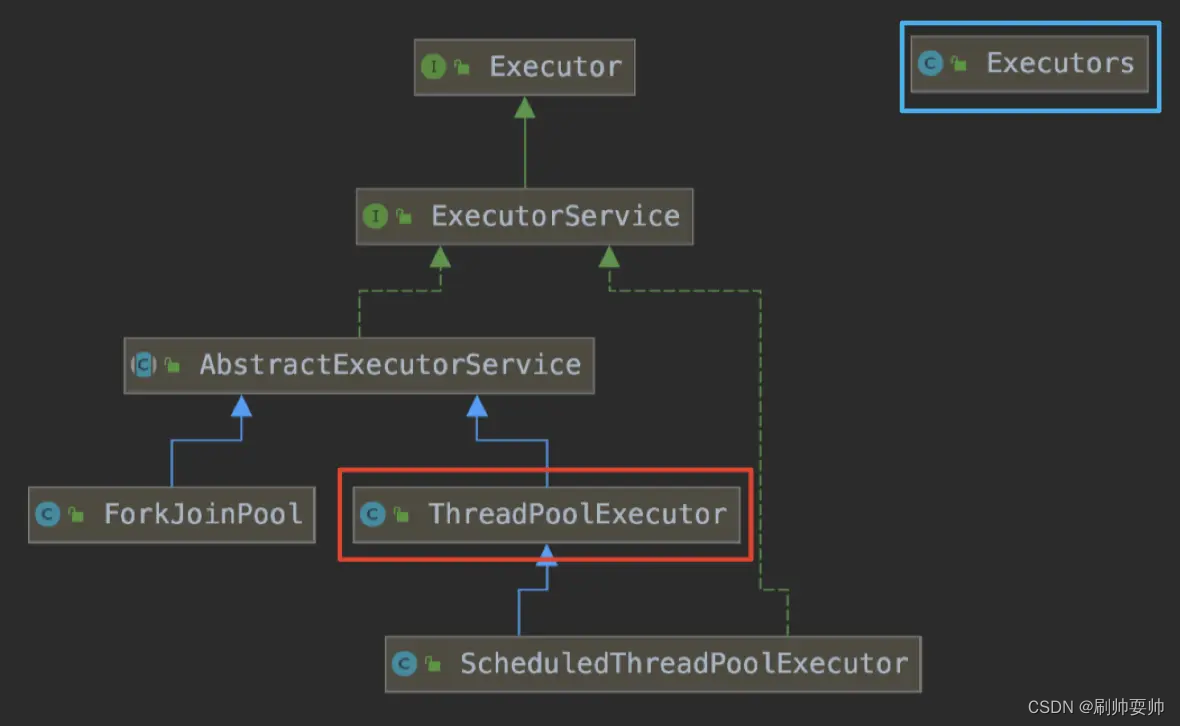
使用 JDK 自带的 Executors工具类 。有的线程池可以无限添加任务或线程,容易导致 OOM;
就拿我们最常用FixedThreadPool和 CachedThreadPool来说,前者的详细创建方法如下:
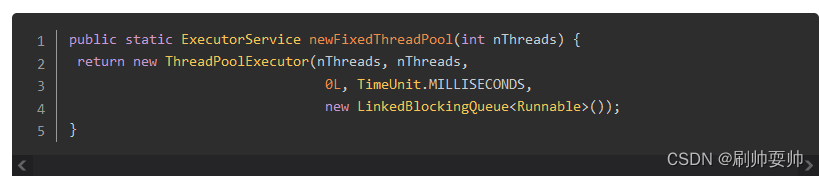 可见其任务队列用的是
可见其任务队列用的是LinkedBlockingQueue,且没有指定容量,相当于无界队列,这种情况下就可以添加大量的任务,甚至达到Integer.MAX_VALUE的数量级,如果任务大量堆积,可能会导致 OO
而 CachedThreadPool
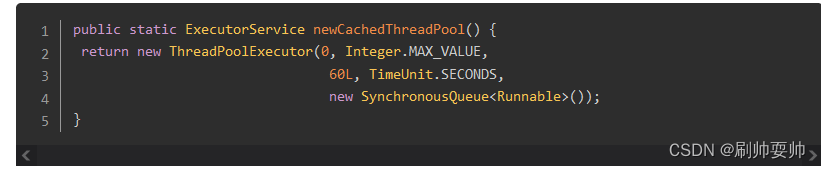
这个虽然使用了有界队列SynchronousQueue,但是最大线程数设置成了Integer.MAX_VALUE,这就意味着可以创建大量的线程,也有可能导致 OOM。
还有一个问题就是这些线程池的线程都是使用 JDK 自带的线程工厂 (ThreadFactory)创建的,线程名称都是类似pool-1-thread-1的形式,第一个数字是线程池编号,第二个数字是线程编号,这样很不利于系统异常时排查问题。
而生产上推荐的写法
// 引入依赖包,创建线程池
private ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("thread-call-runner-%d").build();
private ExecutorService taskExe = new ThreadPoolExecutor(10,20,200L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(),namedThreadFactory)