基于Transformer视觉分割综述
SAM (Segment Anything )作为一个视觉的分割基础模型,在短短的 3 个月时间吸引了很多研究者的关注和跟进。如果你想系统地了解 SAM 背后的技术,并跟上内卷的步伐,并能做出属于自己的 SAM 模型,那么接下这篇 Transformer-Based 的 Segmentation Survey 是不容错过!
南洋理工大学和上海人工智能实验室几位研究人员写了一篇关于 Transformer-Based 的 Segmentation 的综述,系统地回顾了近些年来基于 Transformer 的分割与检测模型,调研的最新模型截止至今年 6 月!综述还包括了相关领域的最新论文以及大量的实验分析与对比,并披露了多个具有广阔前景的未来研究方向!
视觉分割旨在将图像、视频帧或点云分割为多个片段或组。这种技术具有许多现实世界的应用,如自动驾驶、图像编辑、机器人感知和医学分析。在过去的十年里,基于深度学习的方法在这个领域取得了显著的进展。最近,Transformer 成为一种基于自注意力机制的神经网络,最初设计用于自然语言处理,在各种视觉处理任务中明显超越了以往的卷积或循环方法。
具体而言,视觉 Transformer 为各种分割任务提供了强大、统一甚至更简单的解决方案。本综述全面概述了基于 Transformer 的视觉分割,总结了最近的进展。首先,回顾了背景,包括问题定义、数据集和以往的卷积方法。接下来,总结了一个元架构,将所有最近的基于 Transformer 的方法统一起来。基于这个元架构,研究了各种方法设计,包括对这个元架构的修改和相关应用。此外,还介绍了几个相关的设置,包括 3D 点云分割、基础模型调优、域适应分割、高效分割和医学分割。此外,在几个广泛认可的数据集上编译和重新评估了这些方法。最后,确定了这个领域的开放挑战,并提出了未来研究的方向。会持续和跟踪最新的基于 Transformer 的分割与检测方法。
研究动机
ViT 和 DETR 的出现使得分割与检测领域有了十足的进展,目前几乎各个数据集基准上,排名靠前的方法都是基于 Transformer 的。为此有必要系统地总结与对比下这个方向的方法与技术特点。
近期的大模型架构均基于 Transformer 结构,包括多模态模型以及分割的基础模型(SAM),视觉各个任务向着统一的模型建模靠拢。
分割与检测衍生出来了很多相关下游任务,这些任务很多方法也是采用 Transformer 结构来解决。
综述特色
系统性和可读性。系统地回顾了分割的各个任务定义,以及相关任务定义,评估指标。并且本文从卷积的方法出发,基于 ViT 和 DETR,总结出了一种元架构。基于该元架构,本综述把相关的方法进行归纳与总结,系统地回顾了近期的方法。
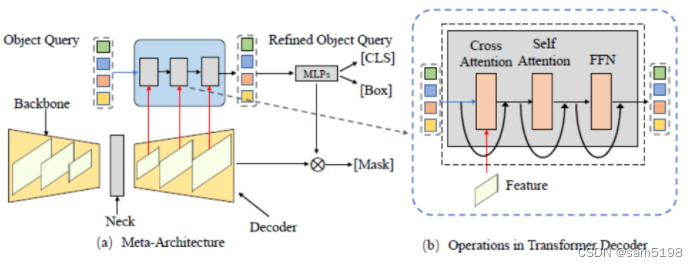
技术的角度进行细致分类。相比于前人的 Transformer 综述,对方法的分类会更加的细致。把类似思路的论文汇聚到一起,对比了他们的相同点以及不同点。例如,会对同时修改元架构的解码器端的方法进行分类,分为基于图像的 Cross Attention,以及基于视频的时空 Cross Attention 的建模。
研究问题的全面性。会系统地回顾分割各个方向,包括图像,视频,点云分割任务。同时,也会同时回顾相关的方向比如开集分割于检测模型,无监督分割和弱监督分割。