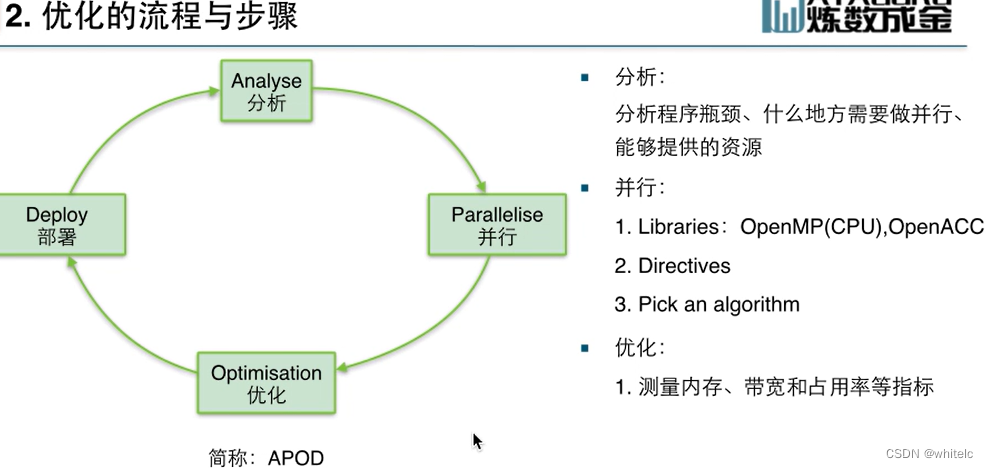
希望用GPU解决更大的问题,更多的程序在同等的设备商运行


最大化单个kernel的运算强度,
最小化内存的操作时间

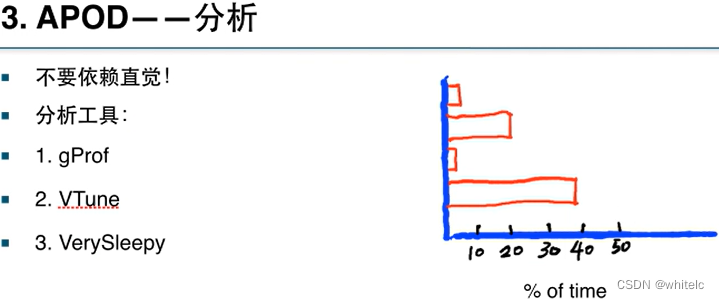
在第一步分析的时候,不要依赖直觉
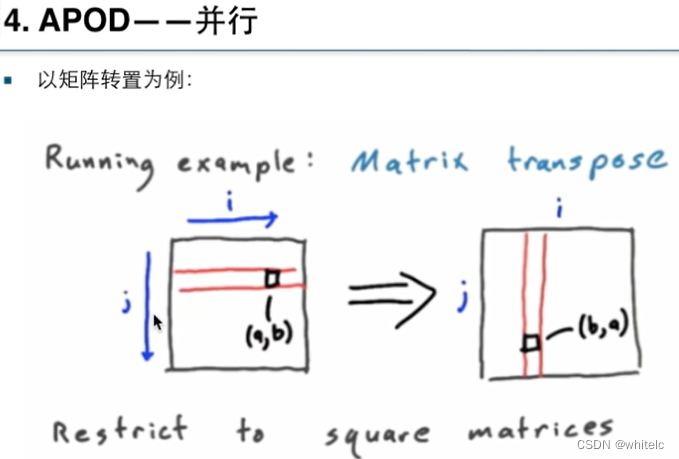

类似CPU,单个线程处理这个事情,串行

把读取全局内存的地方合并以后再去处理输出
输入里面每一个值element,把这个值放到共享内存里面,一小块一小块放到共享内存里面去做转置,做完以后,共享内存中的结果再复制到输出矩阵
使用全局变量-----合并到一个共享内存里面------放到这个内存的同时把转置的工作做了
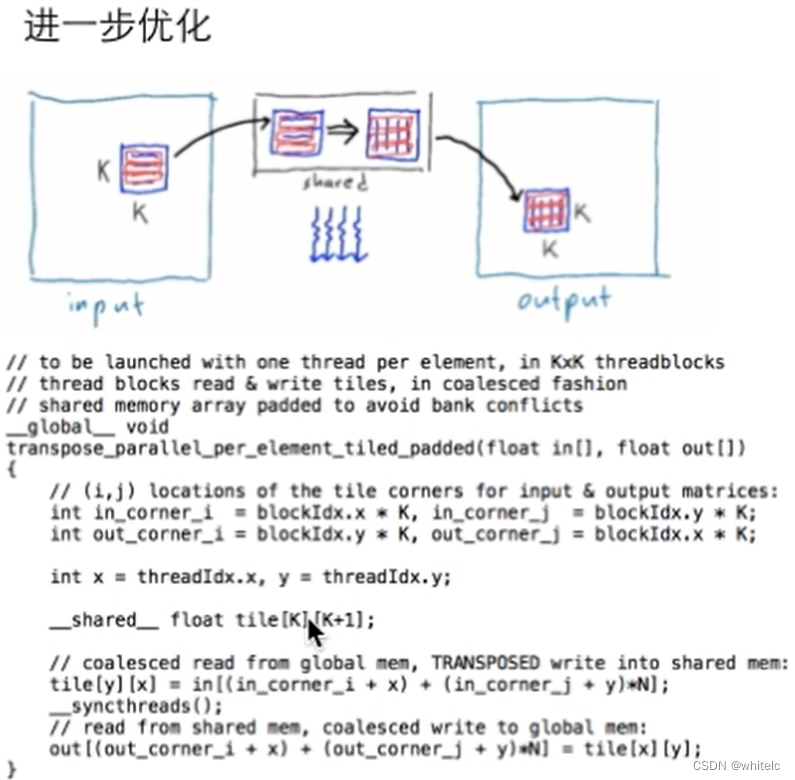
把共享内存的大小缩小以后,K=16,处理的速度也得到了提升

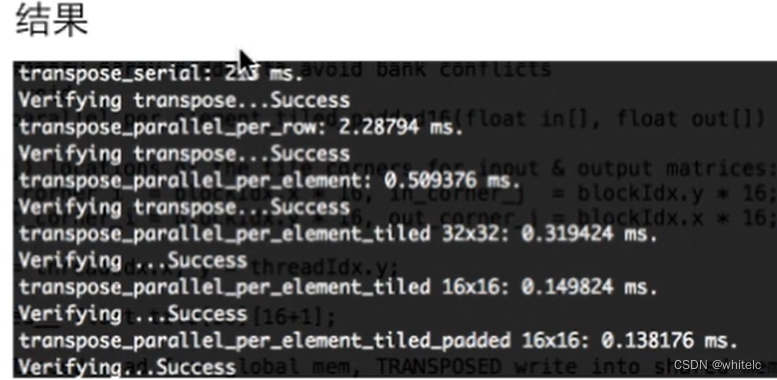
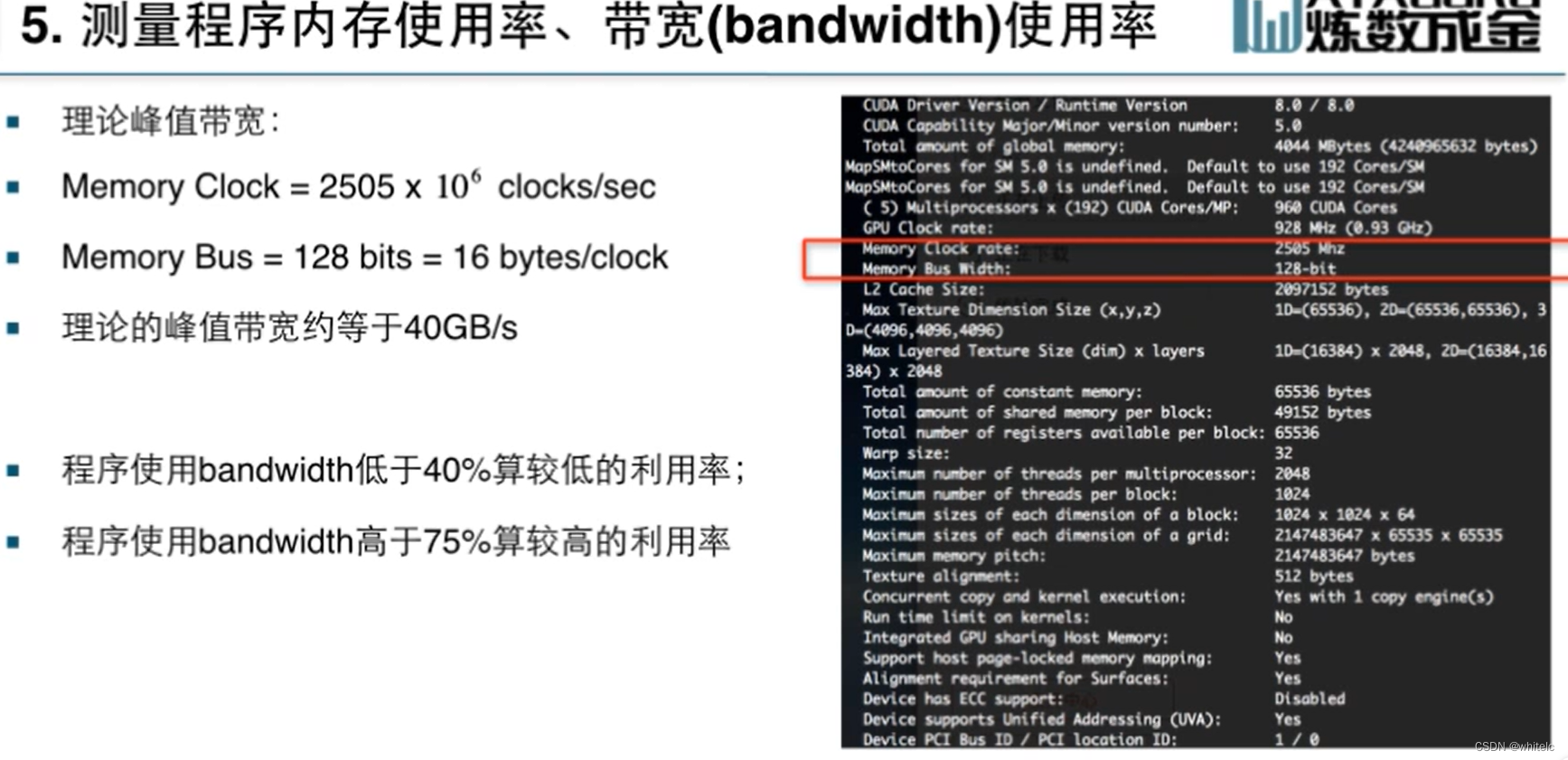
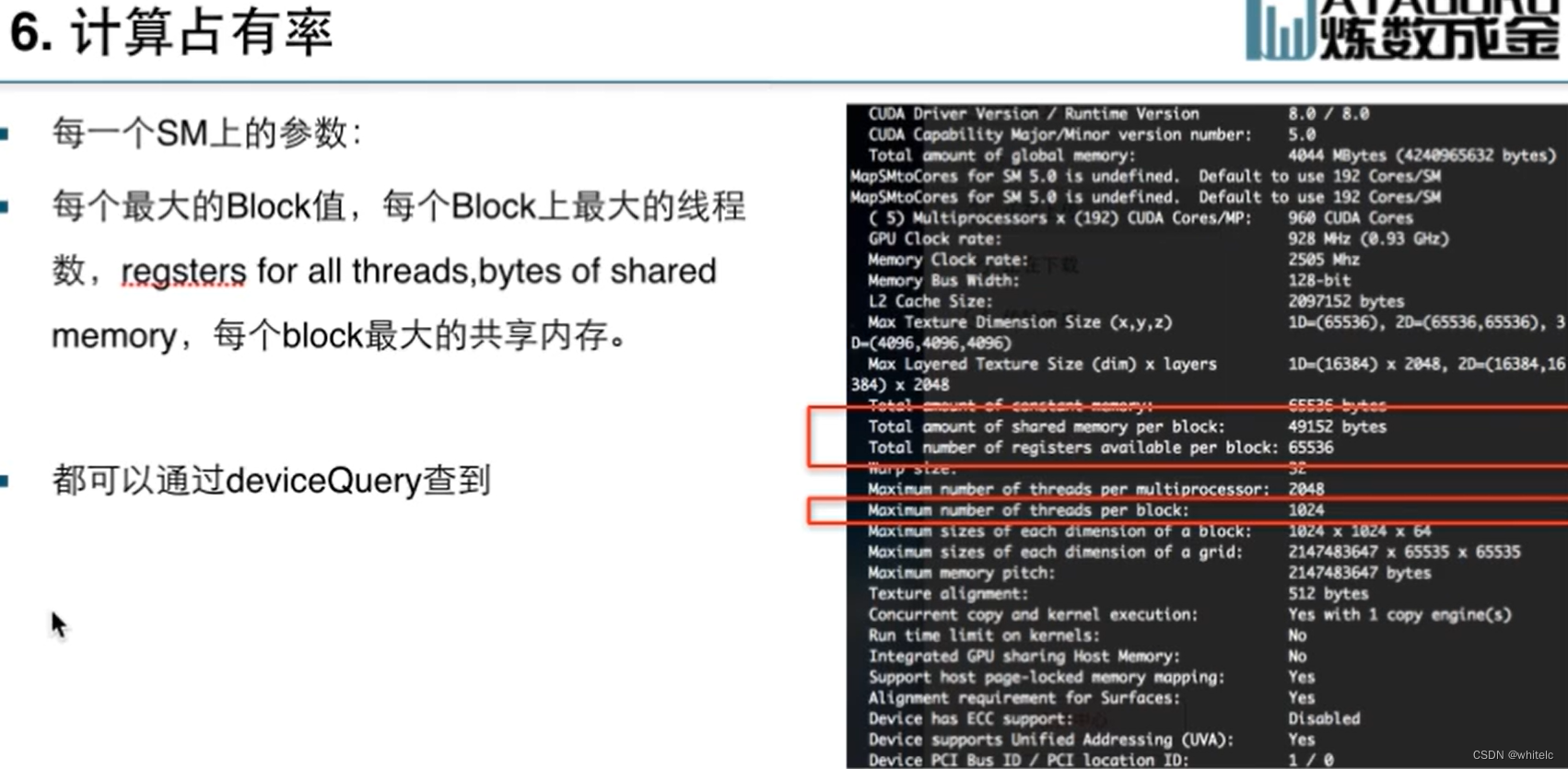
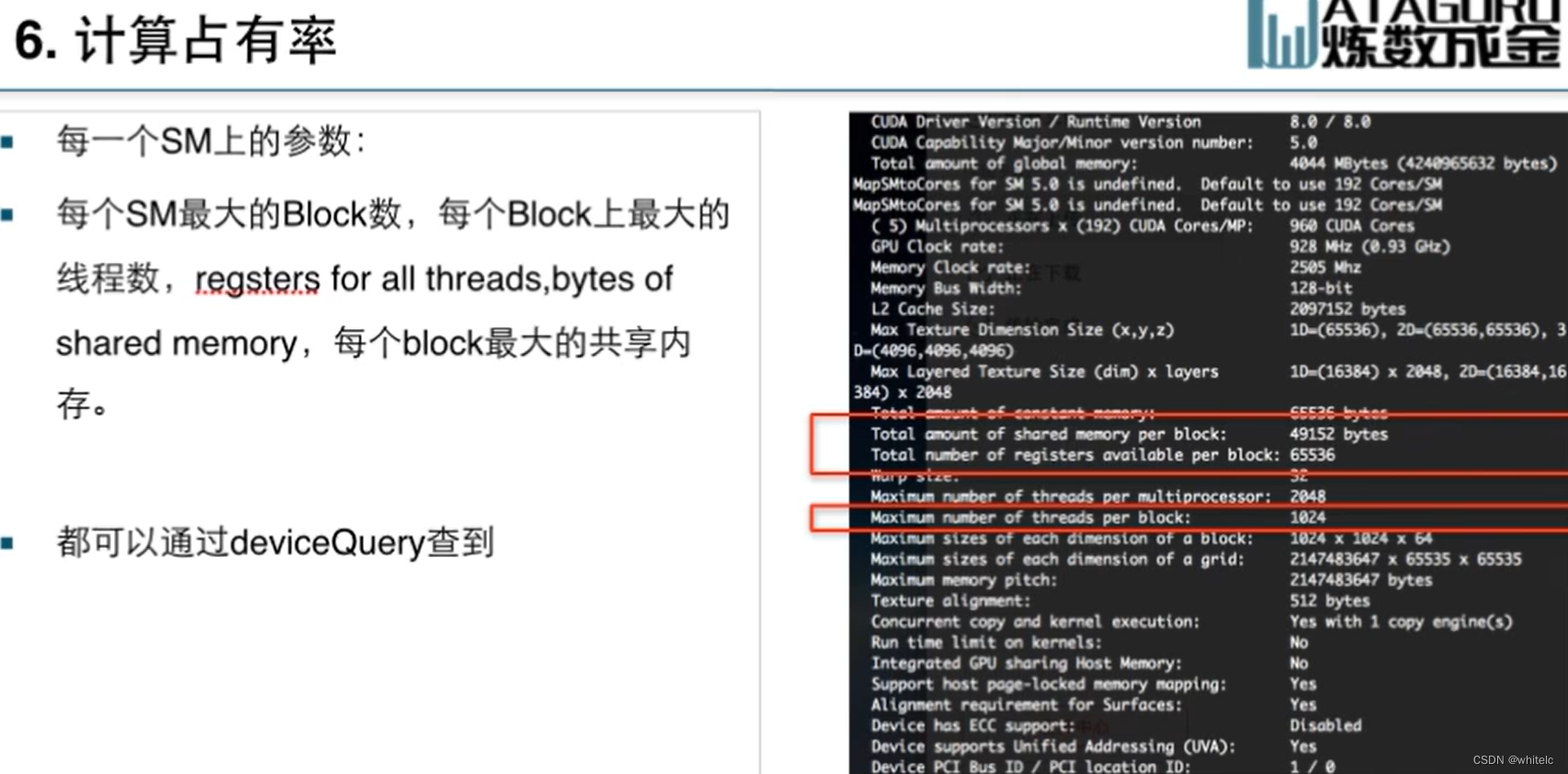
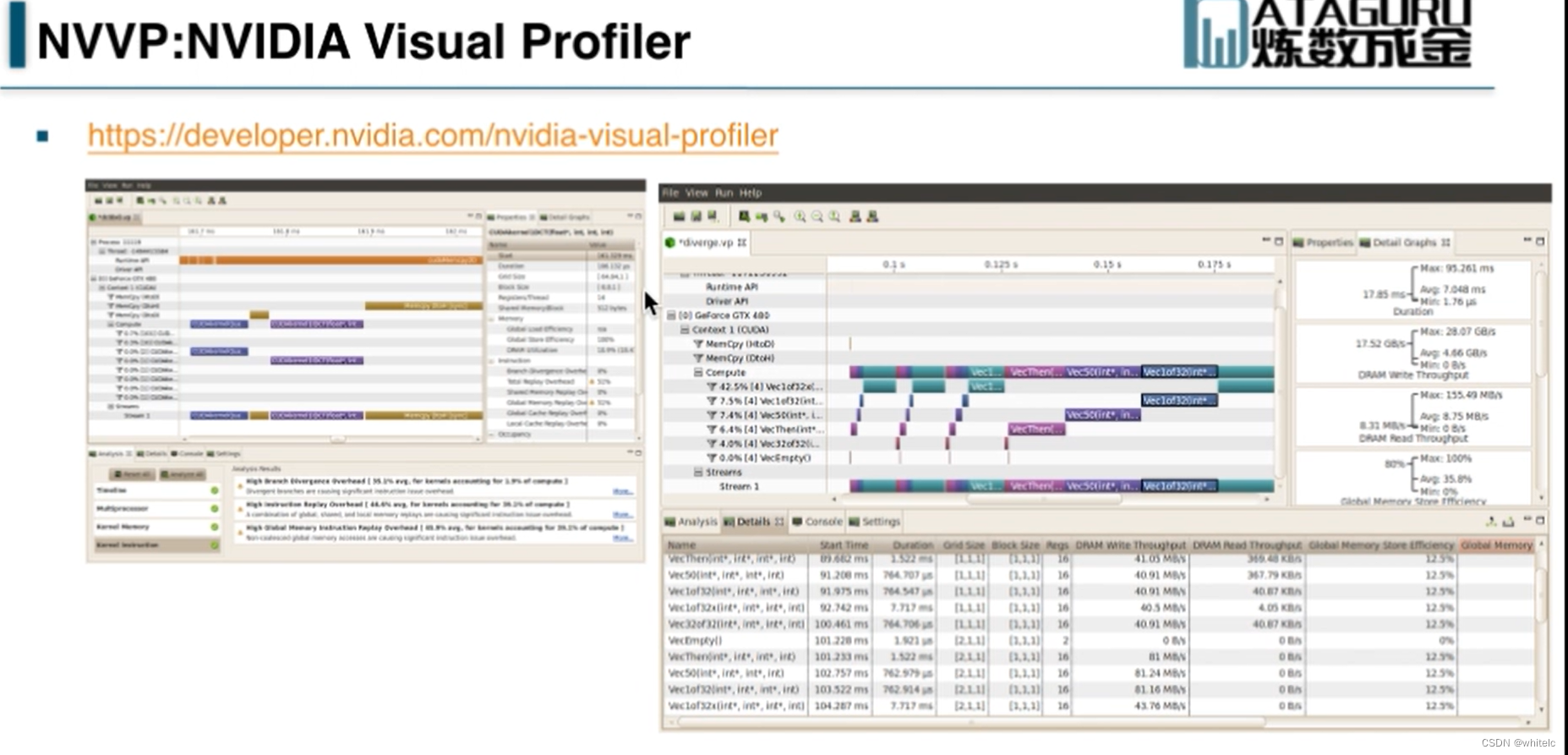
NVVP:可以看性能

边缘和中间部分处理不一样,可以看看写成两个kernel函数处理—把它变成两次的并行化处理,或者同样指令,
B站课程链接
https://www.bilibili.com/video/BV1zK411A7Wq/?spm_id_from=333.337.top_right_bar_window_history.content.click