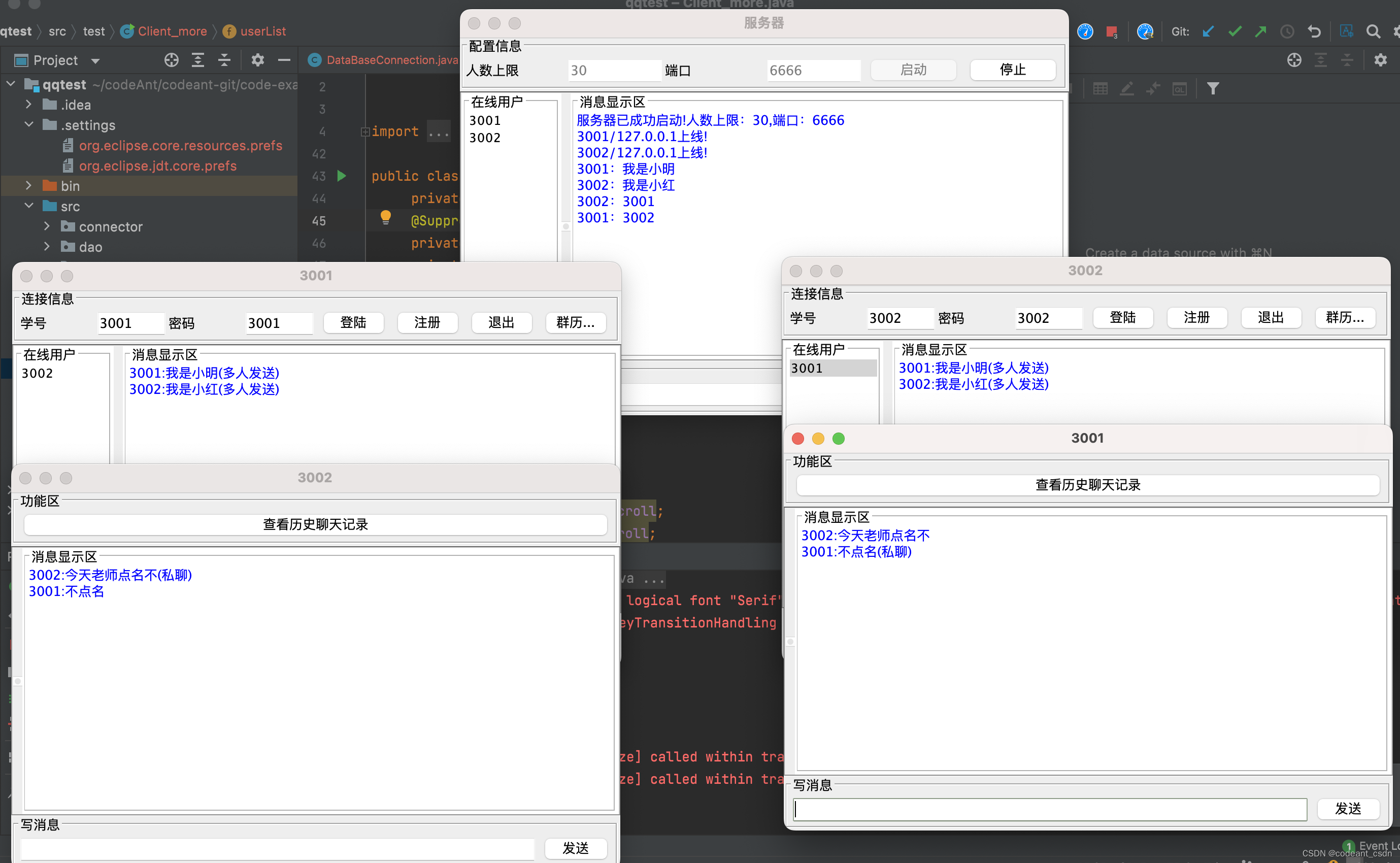
A Survey on Multimodal Large Language Models;
论文链接:https://arxiv.org/pdf/2306.13549.pdf
项目链接(实时更新最新论文,已获1.8K Stars):https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
研究背景
我们将MLLM定义为“由LLM扩展而来的具有接收与推理多模态信息能力的模型”,该类模型相较于热门的单模态LLM具有以下的优势:
-
更符合人类认知世界的习惯。人类具有多种感官来接受多种模态信息,这些信息通常是互为补充、协同作用的。因此,使用多模态信息一般可以更好地认知与完成任务。
-
更加强大与用户友好的接口。通过支持多模态输入,用户可以通过更加灵活的方式输入与传达信息。
-
更广泛的任务支持。LLM通常只能完成纯文本相关的任务,而MLLM通过多模态可以额外完成更多任务,如图片描述和视觉知识问答等。
作者写这篇综述是为了让研究人员掌握MLLMs的基本思想、主要方法和当前进展。
请注意,作者主要关注视觉和语言模态,但也包括涉及其他模态的作品。
具体来说,作者将现有的MLLM分为4种类型,并进行相应的总结,同时打开一个实时更新的GitHub页面。
该综述主要围绕MLLM的三个关键技术以及一个应用展开,包括:
-
多模态指令微调(Multimodal Instruction Tuning,M-IT)
-
多模态上下文学习(Multimodal In-Context Learning,M-ICL)
-
多模态思维链(Multimodal Chain of Thought,M-CoT)
-
LLM辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)
前三个构成了MLLM的基本原理,而最后一个是以LLM为核心的多模态系统。请注意,这三种技术是相对独立的,并且可以组合使用。因此,作者对一个概念的说明也可能涉及其他。
作者根据4个主要类别组织调查,并依次介绍。作者首先详细介绍了M-IT(§3.1),以揭示LLM如何在架构和数据两个方面适应多模态。然后,作者介绍了M-ICL(§3.2),这是一种常用于推理阶段的有效技术,用于提高Few-Shot性能。另一个重要的技术是M-CoT(§3.3),它通常用于复杂的推理任务。之后,作者进一步总结了LLM在LAVR中主要扮演的几个角色(§3.4),其中经常涉及这三种技术。最后,作者以总结和潜在的研究方向结束了作者的调查。
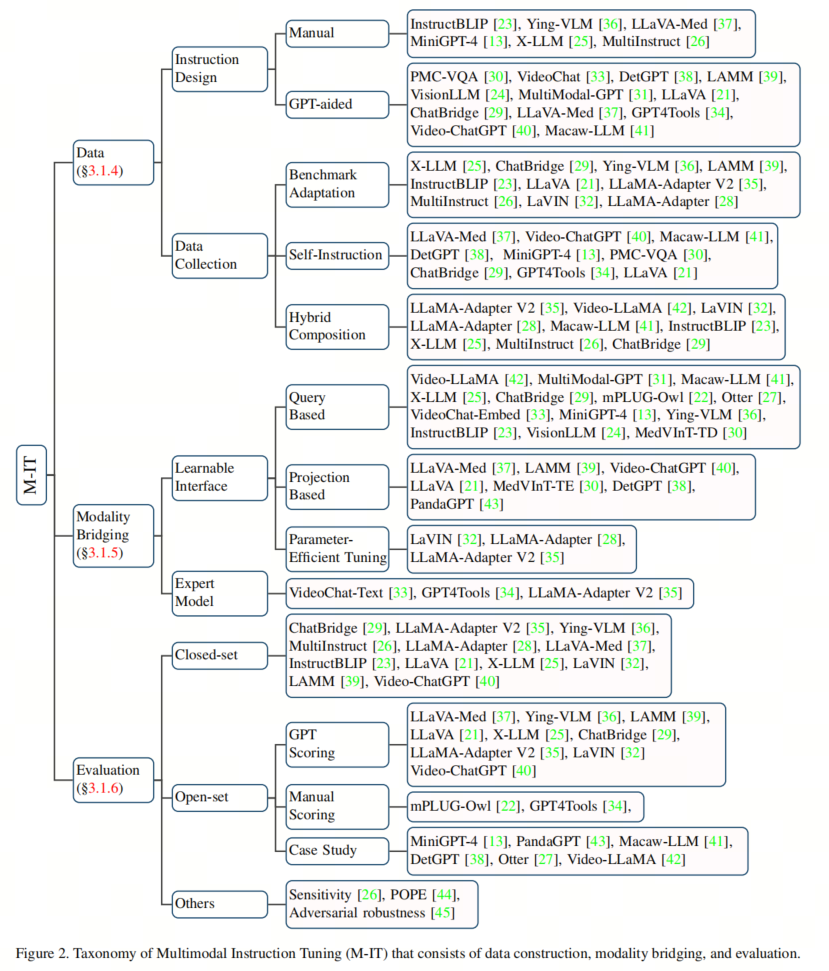
1多模态指令微调(Multimodal Instruction Tuning,M-IT)
指令(Instruction)指的是对任务的描述,多模态指令微调是一种通过指令格式的数据(Instruction-formatted data)来微调预训练的MLLM的技术。通过该技术,MLLM可以跟随新的指令泛化到未见过的任务上,提升zero-shot性能。
这个简单而有效的想法引发了NLP领域后续工作的成功,如ChatGPT、InstructGPT、FLAN和OPT-IML。
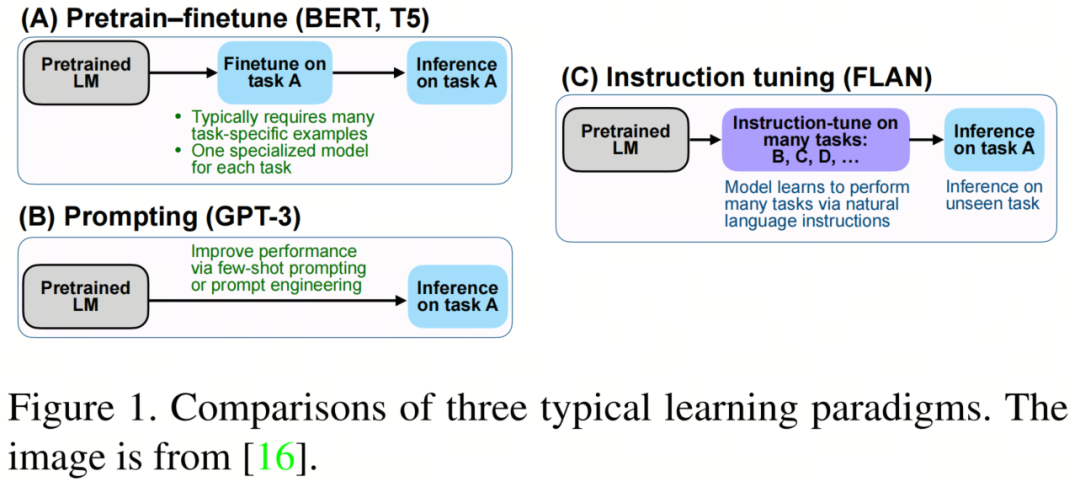
指令调优与相关的典型学习范式之间的比较如图1所示。监督微调方法通常需要许多特定任务的数据来训练特定任务的模型。
-
prompt方法减少了对大规模数据的依赖,并且可以通过prompt工程来完成专门的任务。在这种情况下,虽然 few-shot性能得到了改进,但Zero-Shot性能仍然相当平均。
-
指令调优学习如何泛化到看不见的任务,而不是像两个对应的任务那样适应特定的任务。此外,指令调整与多任务prompt高度相关。
相反,传统的多模态模型仍然局限于前两种调谐范式,缺乏Zero-Shot能力。因此,最近的许多工作探索了将LLM中的指令调整的成功扩展到多模态。为了从单模态扩展到多模态,数据和模型都需要进行相应的调整。
对于数据,研究人员通常通过调整现有的基准数据集或self-instruction来获取M-IT数据集。关于该模型,一种常见的方法是将外来模态的信息注入LLM,并将其视为强有力的推理机。
相关工作要么直接将外来嵌入与LLM对齐,要么求助于专家模型将外来模态翻译成LLM可以吸收的自然语言。通过这种方式,这些工作通过多模态指令调整将LLM转换为多模态聊天机器人和多模态通用任务求解器。
1.1 指令与训练目标
本节简要说明了多模态教学样本的一般结构和M-IT的常见过程。
多模态指令样本通常包括指令和输入输出对。
指令通常是描述任务的自然语言句子,例如“详细描述图像”。
- 输入可以是像视觉问答(VQA)任务那样的图像-文本对,也可以是像图像字幕任务那样的仅图像。输出是以输入为条件的指令的答案。
多模态的指令格式如下所示:

如表1所示,指导模板是灵活的,并遵循手动设计。注意,指令样本也可以推广到多轮指令,其中多模态输入是共享的。
形式上,多模态指令样本可以表示为三元组形式,即(I,M,R),其中I,M,R 分别表示指令、多模态输入和 GT响应。
MLLM在给定指令和多模态输入的情况下预测答案:
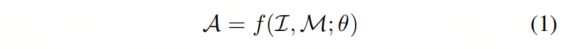
这里,A 表示预测答案,θ是模型的参数。
训练目标通常是用于训练LLM的原始自回归目标,在此基础上,MLLM被迫预测响应的下一个 Token。
目标可以表示为:
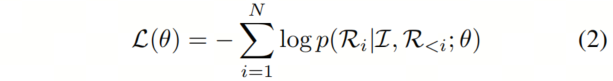
其中,是GT响应的长度。
1.2 模态对齐
通常对成对数据进行大规模(与指令调优相比)的预训练,以鼓励不同模态之间的对齐,这是在M-IT之前。
对齐数据集通常是图像-文本对或自动语音识别(ASR)数据集,它们都包含文本。
更具体地说,图像-文本对以自然语言句子的形式描述图像,而ASR数据集包含语音的转录。对齐预训练的一种常见方法是保持预训练模块(例如视觉编码器和LLM)冻结,并训练一个可学习的接口,如下一节所示。
1.3 数据收集方法
1.3.1 Benchmark Adaptation
基准数据集是高质量数据的丰富来源。因此,大量的工作利用现有的基准数据集来构建指令格式的数据集。以VQA数据集的转换为例,原始样本是输入-输出对,其中输入包括图像和自然语言问题,输出是以图像为条件的问题的文本答案。
这些数据集的输入输出对可以自然地包括指令样本的多模态输入和响应(见§3.1.2)。指令,即任务描述,可以来自手动设计,也可以来自GPT辅助的半自动生成。
具体而言,一些作品手工制作了一个候选指令库,并在训练期间对其中一个进行采样。作者提供了VQA数据集的指令模板示例,如表2所示。其他工作手动设计一些种子指令,并使用这些指令prompt-GPT生成更多。

请注意,由于现有VQA和标题数据集的答案通常很简洁,因此直接使用这些数据集进行指令调整可能会限制MLLM的输出长度。解决这个问题有两种常见的策略。
第一个是修改指令。例如,ChatBridge明确声明了简短数据的简短和简短,以及标题数据的句子和单句。类似地,InstructionBLIP将简短的插入到公共数据集的指令模板中,这些数据集本质上更喜欢简短的响应。
第二个是延长现有答案的长度。例如,M3 IT建议通过用原始问题、答案和上下文prompt-ChatGPT来重新表述原始答案。
1.3.2 Self-Instruction
尽管现有的基准数据集可以提供丰富的数据源,但它们通常不能很好地满足现实世界场景中的人类需求,例如多轮对话。为了解决这个问题,一些作品通过Self-Instruction收集样本,Self-Instruction引导LLM使用一些手工注释的样本生成文本指令。
具体来说,一些指令跟随样本是手工制作的种子示例,之后会prompt ChatGPT/GPT-4以种子样本为指导生成更多指令样本。LLaVA通过将图像转换为字幕和边界框的文本,并prompt GPT-4在种子示例的上下文中生成新数据,将该方法扩展到多模态领域。
通过这种方式,构建了一个M-IT数据集,称为LLaVA-Instruct-150k。根据这一想法,Mini GPT-4、Chat-Bridge、GPT4-Tools和DetGPT等后续工作开发了不同的M-IT数据集,以满足不同的需求。
1.3.3 Hybrid Composition
除了M-IT数据外,纯语言用户助理会话数据还可用于提高会话熟练度和指令跟随能力。LaVIN通过从纯语言数据和M-IT数据中随机采样,直接构建了一个小批量。
Multi-Instruction探讨了融合单模态和多模态数据的不同训练策略,包括 Hybrid 指令调整(结合两种类型的数据和随机混洗)、顺序指令调整(文本数据后接多模态数据)和基于适配器的顺序指令调整。实证结果表明, Hybrid 指令调整至少不比单独调整多模态数据差。
1.4 模态桥接
由于LLM只能感知文本,因此有必要弥合自然语言和其他模态之间的差距。然而,以端到端的方式训练大型多模态模型将是昂贵的。
此外,这样做会带来灾难性遗忘的风险。因此,一种更实用的方法是在预训练的视觉编码器和LLM之间引入可学习的接口。另一种方法是在专家模型的帮助下将图像翻译成语言,然后将语言发送给LLM。
1.4.1 Learnable Interface
当冻结预训练的模型的参数时,可学习接口负责连接不同的模态。挑战在于如何有效地将视觉内容翻译成LLM能够理解的文本。一个常见且可行的解决方案是利用一组可学习的查询 Token以基于查询的方式提取信息,这首先在Flamingo和BLIP-2中实现,随后被各种工作继承。
此外,一些方法使用基于投影的界面来缩小模态间隙。例如,LLavA采用简单的线性层来嵌入图像特征,MedVInTTE使用两层多层感知器作为桥接器。
还有一些工作探索了一种参数有效的调整方式。LLaMA适配器在训练期间在Transformer中引入了一个轻量级适配器模块。LaVIN设计了一种 Hybrid 模态适配器来动态决定多模态嵌入的权重。
1.4.2 Expert Model
除了可学习的界面外,使用专家模型,如图像字幕模型,也是弥合模态差距的可行方法。不同的是,专家模型背后的想法是在没有训练的情况下将多模态输入转换为语言。这样,LLM就可以通过转换后的语言间接地理解多模态。
例如,VideoChat Text使用预训练的视觉模型来提取动作等视觉信息,并使用语音识别模型丰富描述。尽管使用专家模型很简单,但它可能不如采用可学习的界面那么灵活。将外来模态转换为文本通常会造成信息丢失。正如VideoChat文本所指出的,将视频转换为文本描述会扭曲时空关系。
1. 5 验证
1.5.1 close set
Closed-set问题是指一类问题,其中可能的答案选项是预先定义的,并限于有限集。评估通常在适应基准的数据集上进行。在这种情况下,可以通过基准度量自然地判断响应。例如,Instruction BLIP报告了ScienceQA的准确性,以及NoCaps和Flickr30K的CIDEr评分。
评估设置通常为Zero-Shot或微调。第一种设置通常选择涵盖不同一般任务的广泛数据集,并将其拆分为保留和保留数据集。在对前者进行调优后,使用未查看的数据集甚至未查看的任务对后者进行Zero-Shot性能评估。相反,在评估特定领域的下游任务时,经常会观察到第二种设置。例如,LLaVA和LLaMA适配器报告了ScienceQA上的微调性能。LLaVA Med报道了生物医学VQA的结果。
上述评估方法通常局限于小范围的选定任务或数据集,缺乏全面的定量比较。为此,一些人努力开发专门为MLLM设计的新基准。例如,傅等人构建了一个综合评估基准MME,该基准包括总共14项感知和认知任务。MME中的所有指令-答案对都是手动设计的,以避免数据泄露。
通过详细的排行榜和分析,对10个先进的MLLM进行了评估。LAMM Benchmark被提出用于在各种2D/3D视觉任务上定量评估MLLMs。Video-ChatGPT提出了一个基于视频的会话模型定量评估框架,其中包括两种评估,即基于视频的生成性能评估和Zero-Shot问题回答。
1.5.2 open set
与Closed-set问题相比,对Open-set问题的回答可以更灵活,MLLM通常扮演聊天机器人的角色。因为聊天的内容可以是任意的,所以判断起来比封闭式输出更难。该标准可分为人工评分、GPT评分和案例研究。
人工评分要求人类评估产生的反应。这种方法通常涉及手工制作的问题,旨在评估特定的维度。例如,mPLUGOwl收集了一个视觉相关的评估集,以判断自然图像理解、图表和流程图理解等能力。类似地,GPT4Tools分别为微调和Zero-Shot性能构建了两组,并从思想、行动、论点和整体方面评估了响应。
由于人工评估是劳动密集型的,一些研究人员探索了GPT评分,即GPT评分。这种方法通常用于评估多模态对话的表现。LLaVA建议通过GPT-4从不同方面对反应进行评分,如帮助性和准确性。具体而言,从COCO验证集中采样30幅图像,每幅图像通过GPT-4上的Self-Instruction与一个简短问题、一个详细问题和一个复杂推理问题相关联。MLLM和GPT-4生成的答案被发送到GPT-4进行比较。随后的工作遵循了这一想法,并促使ChatGPT或GPT-4对结果进行评分或判断哪一个更好。
基于GPT-4的评分的一个主要问题是,目前,其多模态接口尚未公开。因此,GPT-4只能基于图像相关的文本内容(如标题或边界框坐标)生成响应,而无需访问图像。因此,在这种情况下,将GPT-4设置为性能上限可能是有问题的。
另一种方法是通过案例研究比较MLLM的不同能力。例如,mPLUG Owl使用一个与视觉相关的笑话理解案例来与GPT-4和MM-REAT进行比较。类似地,视频LLaMA提供了一些案例来展示几种能力,如视听协同感知和公共知识概念识别。
1.5.3 others
其他一些方法侧重于MLLM的一个特定方面。
例如,Multi-Instruction提出了一种称为灵敏度的指标,用于评估模型对不同指令的鲁棒性。
李等人深入研究了对象幻觉问题,并提出了一种查询方法POPE来评估这方面的性能。赵等人考虑了安全问题,并建议评估MLLM对对手攻击的鲁棒性。
2. 多模态上下文学习 (Multimodal In-Context Learning
ICL是LLM的重要涌现能力之一。ICL有两个很好的特点:
2.1 ICL 的优势
-
与传统的从丰富的数据中学习内隐模态的监督学习范式不同,ICL的关键是从类比中学习。具体而言,在ICL设置中,LLM从几个例子和可选指令中学习,并推断出新的问题,从而以少量的方式解决复杂和看不见的任务。
-
ICL通常以无训练的方式实现,因此可以在推理阶段灵活地集成到不同的框架中。与ICL密切相关的一项技术是指令调整(见§3.1),经验表明它可以增强ICL的能力。
在MLLM的背景下,ICL已扩展到更多模态,从而产生了多模态ICL(M-ICL)。基于(§3.1.2)中的设置,在推理时,可以通过向原始样本添加一个演示集,即一组上下文中的样本来实现M-ICL。
2.2 指令模板进行扩展
在这种情况下,可以对模板进行扩展,如表3所示。请注意,作者列出了两个上下文中的示例进行说明,但示例的数量和顺序可以灵活调整。事实上,模型通常对演示的安排很敏感。

2.3M-ICL主要用于两种场景
就多模态的应用而言,M-ICL主要用于两种场景:
解决各种视觉推理任务
教LLM使用外部工具
前者通常包括从几个特定任务的例子中学习,并概括为一个新的但相似的问题。根据说明和演示中提供的信息,LLM可以了解任务在做什么以及输出模板是什么,并最终生成预期的答案。相比之下,工具使用的示例通常是纯文本的,而且更细粒度。它们通常包括一系列步骤,这些步骤可以按顺序执行以完成任务。因此,第二种情况与CoT密切相关(见§3.3)。
3.多模态思维链(Multimodal Chain of Thought,M-CoT)
正如先驱工作所指出的,CoT是“一系列中间推理步骤”,已被证明在复杂推理任务中是有效的。CoT的主要思想是促使LLM不仅输出最终答案,而且输出导致答案的推理过程,类似于人类的认知过程。
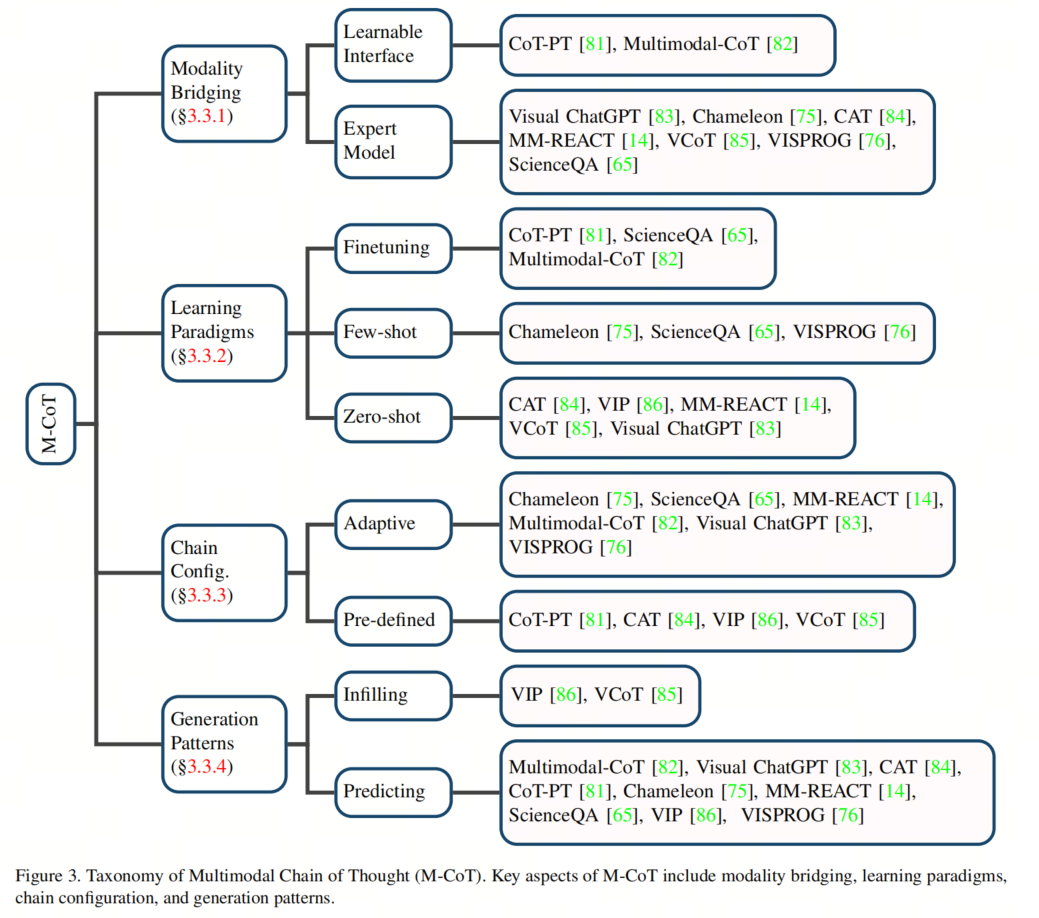
3.1 模态桥接
为了将成功从NLP转移到多模态,模态桥接是第一个需要解决的问题。大致有两种方法可以实现这一点:通过融合特征或通过将视觉输入转换为文本描述。与3.1.5中的情况类似,作者将它们分别分类为可学习的界面和专家模型,并按顺序进行讨论。
「Learnable Interface」
这种方法包括采用可学习的界面将视觉嵌入映射到单词嵌入空间。然后可以将映射的嵌入作为prompt,将其发送给具有其他语言的LLM,以引发M-CoT推理。例如,CoT PT链接多个Meta-Net用于prompt调整,以模拟推理链,其中每个Meta-Net将视觉特征嵌入到prompt的特定步骤偏差中。多模态CoT采用了一个具有共享基于Transformer的结构的两阶段框架,其中视觉和文本特征通过交叉注意力进行交互。
- 专家模型
引入专家模型将视觉输入转换为文本描述是一种替代的模态桥接方式。例如,ScienceQA采用图像字幕模型,并将图像字幕和原始语言输入的级联提供给LLM。尽管这种方法简单明了,但在字幕处理过程中可能会出现信息丢失。
3.2 学习范式
学习范式也是一个值得研究的方面。获得M-CoT能力的方法大致有三种,即通过微调和无训练的Few/Zero-Shot学习。三种方式的样本量要求按降序排列。
直观地说,微调方法通常涉及为M-CoT学习管理特定的数据集。例如,ScienceQA构建了一个包含讲座和解释的科学问答数据集,该数据集可以作为学习CoT推理的来源,并对该提出的数据集进行微调。多模态CoT也使用ScienceQA基准,但以两步方式生成输出,即基本原理(推理步骤链)和基于基本原理的最终答案。CoT PT通过快速调整和特定步骤视觉偏见的组合来学习隐含的推理链。
与微调相比,Few/Zero-Shot学习的计算效率更高。它们之间的主要区别在于,Few-Shot学习通常需要手工制作一些上下文中的例子,这样模型就可以更容易地一步一步地学习推理。
相比之下,Zero-Shot学习不需要任何具体的CoT学习示例。在这种情况下,通过prompt“让作者逐帧思考”或“这两个关键帧之间发生了什么”等设计指令,模型学会在没有明确指导的情况下利用嵌入的知识和推理能力。类似地,一些工作prompt模型,描述任务和工具使用情况,将复杂任务分解为子任务。
3.3 链结构
链结构是推理的一个重要方面,可以分为适应性的结构和预定义的结构。前一种配置要求LLM自己决定何时停止推理链,而后一种设置则停止具有预定义长度的链。
3.4 生成模态
如何构建链条是一个值得研究的问题。作者将当前的工作总结为:
-
基于填充的模态
-
基于预测的模态
具体而言,基于填充的模态需要在周围上下文(前一步和后一步)之间推导步骤,以填补逻辑空白。相反,基于预测的模态需要在给定条件(如指令和先前的推理历史)的情况下扩展推理链。这两种类型的模态有一个共同的要求,即生成的步骤应该是一致和正确的。
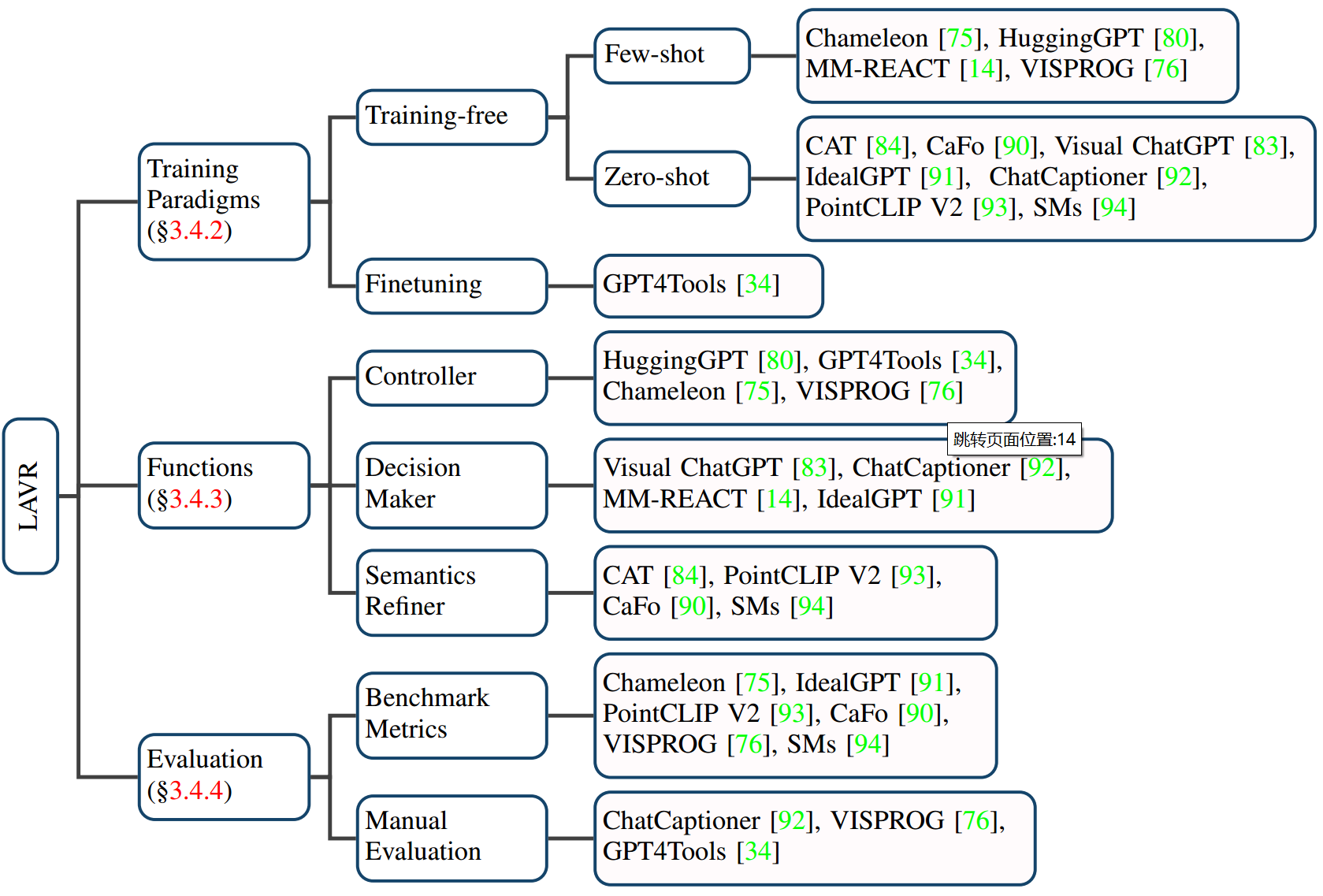
4. LLM辅助的视觉推理 LAVR
这类工作利用LLM强大的内嵌知识与能力以及其他工具,设计各种视觉推理系统。相比于传统视觉推理模型,这些工作具有以下的好的特性:
- 强大的零/少样本泛化能力。
- 具备新的能力。这些系统能够执行更加复杂的任务,如解读梗图的深层含义。
- 更好的互动性与可控性。
我们从
- 训练范式、
- LLM 充当的功能作用
- 评测三个部分总结了当前的进展:
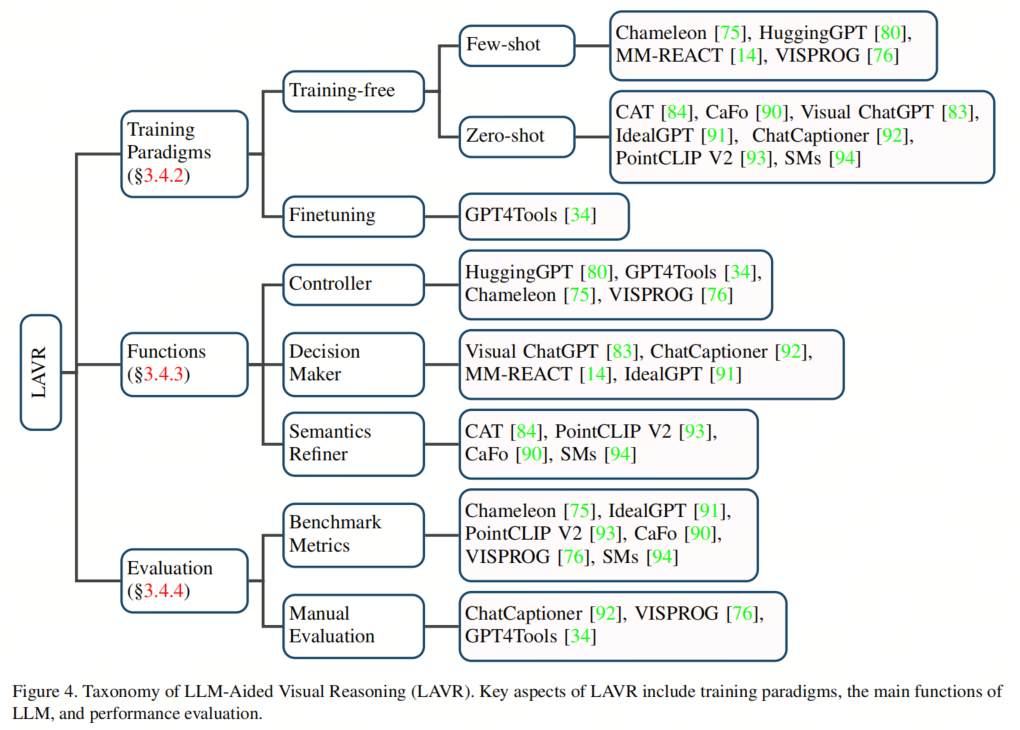
4.1 训练范式、
4.2 LLM 充当的功能作用
4.3 评测
5. 未来研究内容
-
目前的MLLM在感知能力方面仍然有限,导致视觉信息获取不完整或错误。
这可能是由于信息容量和计算负担之间的折衷。更具体地说,Q-Former只使用32个可学习的 Token来表示图像,这可能会导致信息丢失。尽管如此,扩大 Token大小将不可避免地给LLM带来更大的计算负担,LLM的输入长度通常是有限的。一种潜在的方法是引入像SAM这样的大型视觉基础模型,以更有效地压缩视觉信息。 -
MLLM的推理链可能很脆弱。
例如,傅等人发现,在数学计算的情况下,尽管MLLM计算出了正确的结果,但由于推理的失败,它仍然给出了错误的答案。这表明单模态LLM的推理能力可能不等于LLM在接收到视觉信息后的推理能力。改进多模态推理的主题值得研究。 -
MLLM的指令跟随能力需要升级。
在M-IT之后,尽管有明确的指示,“请回答是或否”,但一些MLLM无法生成预期答案(“是”或“否”)。这表明指令调整可能需要涵盖更多的任务来提高泛化能力。 -
object hallucination 物体幻视问题普遍存在,这在很大程度上影响了MLLMs的可靠性。
这可能归因于对准预训练不足。因此,一个可能的解决方案是在视觉模态和文本模态之间进行更细粒度的对齐。细粒度是指图像的局部特征,可以通过SAM获得,以及相应的局部文本描述。 -
需要高效参数训练。
现有的两种模态桥接方式,即可学习接口和专家模型,都是对减少计算负担的初步探索。更有效的训练方法可以在计算资源有限的MLLM中释放更多的功率。