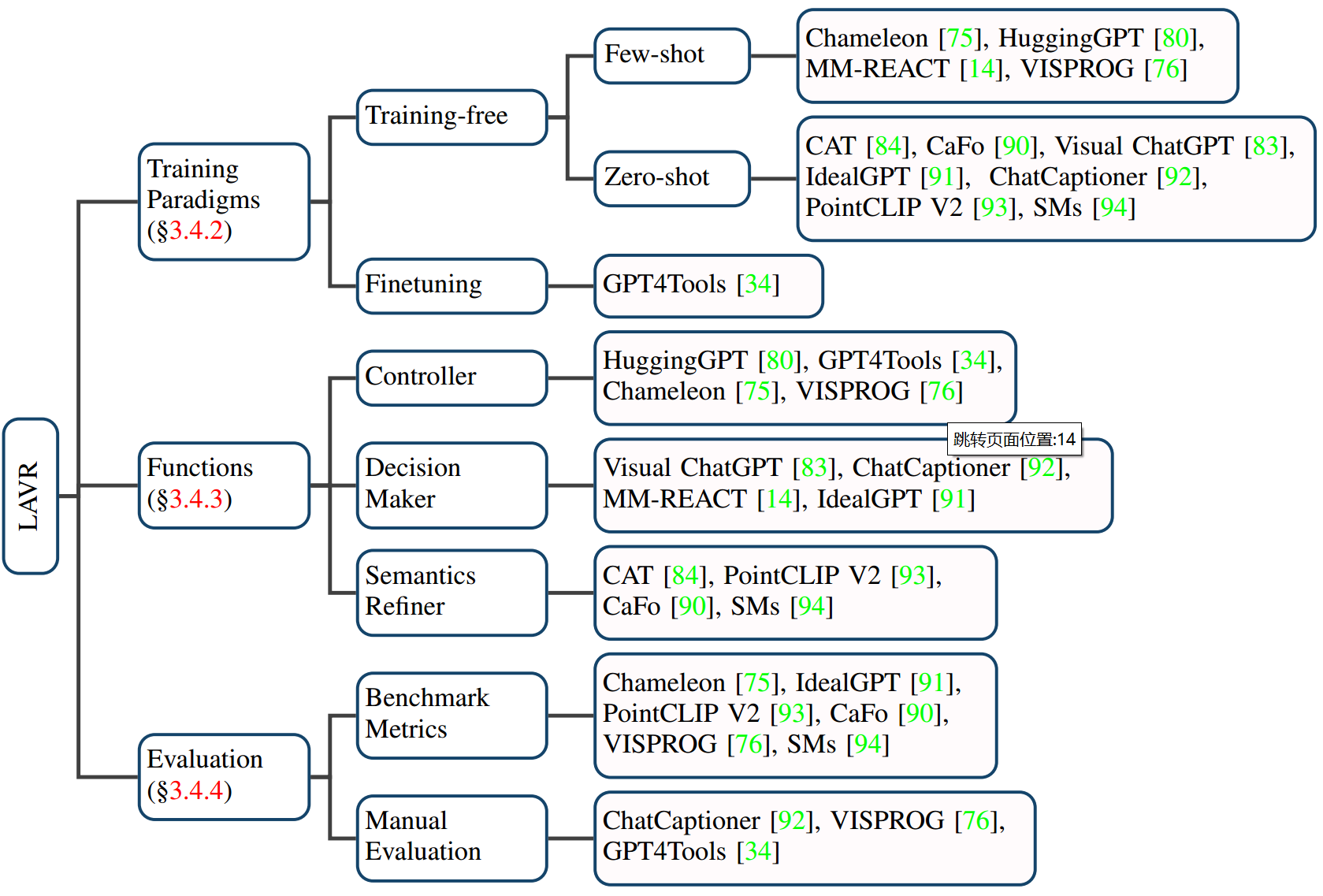
目录
业务无关量
随机数字
线程安全随机
随机字符串
业务相关量
随机相关量
上游接口获取
上游接口造数据
提前造数据
总结:
下面分享几种我工作中常用到的增加参数多样性的方法。
业务无关量
这个是最常用到的,当部分的接口参数对接下来的用例没有实际影响的时候我通常会用一个随机的数字和字符串来设置参数。
随机数字
这个相对简单,我是Java,分享一下简单的代码:
/**
* 获取随机数,获取1~num 的数字,包含 num
*
* @param num 随机数上限
* @return 随机数
*/
public static int getRandomInt(int num) {
return random.get().nextInt(num) + 1;
}
/**
* 随机范围int,取头不取尾
*
* @param start
* @param end
* @return
*/
public static int getRandomIntRange(int start, int end) {
if (end <= start) return TEST_ERROR_CODE;
return random.get().nextInt(end - start) + start;
}
线程安全随机
在做性能测试的时候,我经常会有在不同线程随机出某个唯一的量的需求,这里我一般采用两段组成:多线程唯一量和线程内唯一量。
举个例子来讲:
/**
* 用于非单纯的http请求以及非HTTP请求,没有httprequestbase对象的标记方法,自己实现的虚拟类,可用户标记header固定字段或者随机参数,使用T作为参数载体,目前只能使用在T为string类才行
*/
public class ParamMark extends SourceCode implements MarkThread, Cloneable, Serializable {
private static final long serialVersionUID = -5532592151245141262L;
public static AtomicInteger threadName = new AtomicInteger(getRandomIntRange(1000, 9000));
/**
* 用于标记执行线程
*/
String name;
int num = getRandomIntRange(100, 999) * 1000;
@Override
public String mark(ThreadBase threadBase) {
return name + num++;
}
@Override
public ParamMark clone() {
ParamMark paramMark = new ParamMark();
return paramMark;
}
public ParamMark() {
this.name = threadName.getAndIncrement() + EMPTY;
}
public ParamMark(String name) {
this();
this.name = name;
}
}
这里我用了一个全局的静态变量threadName作为一个基础值,之所以这里也随机是想让每次运行的时候尽量都不一样,没有使用时间戳是因为时间戳太长了,现在这个比较满足需求。

下面每个对象创建的时候调用的构造方法:
public ParamMark() {
this.name = threadName.getAndIncrement() + EMPTY;
}
这里就可以保证每一个线程拿到的值都是不一样的,当然这个功能还可以通过中提到的方法解决,这里就不多说了。
@Override
public String mark(ThreadBase threadBase) {
return name + num++;
}
这里我就可以通过num++获取一个线程内的唯一数字,然后和name组合成为一个全局唯一的量。
随机字符串
这个好像没有特别大的需求量,之前写过一个StringUtil的工具类来完成,一般为了生成一个固定长度的随机字符串,我都是调用一个方法:
/**
* 获取随机字符串
* @param i
* @return
*/
static String getString(int i) {
def re = new StringBuffer()
if (i < 1) return re
for (int j in 1..i) {
re.append(getChar())
}
re.toString()
}
或者:
/**
* 获取随机字符串,没有数字
* @param i
* @return
*/
static String getStringWithoutNum(int i) {
def re = new StringBuffer()
if (i < 1) return re
for (int j in 1..i) {
re << getWord()
}
re.toString()
}
同样这里也有线程安全的问题,可以采用上面的多线程唯一量和线程内唯一量的方式解决。如果是的唯一性要求严格的话,我一般采用时间戳的形式。这样做比较方便,如果毫秒的时间错不足以满足需求,可以采用纳秒的时间戳,自测完全没问题。
/**
* 获取纳秒的时间标记
*
* @return
*/
public static long getNanoMark() {
return System.nanoTime();
}
业务相关量
这里分享一下,业务相关的参数相关的多样性问题我的解决方案。
随机相关量
这个主要场景指的是有指定的随机范围,比如说某个接口数值型参数的范围是0-7,那么我们就可以通过随机这个参数来丰富该接口的请求参数。
有的接口几个参数是关联性的,我们就需要从一个List中随机或者是数组中随机出一个对象,FunTester通常会把多个关联参数封装成一个对象,例如:
private static class K extends AbstractBean {
int id
int type
int level
K(int id, int type, int level) {
this.id = id
this.type = type
this.level = level
}
}
这样我们就可以通过将可用的参数放到一个列表中获取,此方法跟下面的造数据有些区别,一个取是访问一下,一个取是取走了,各位可以待会对比一下。
分享一些代码片段:
params.put("pullnew", random(1, 2, 3));
params.put("class_id", random(Common.CLASSES));
其中public static final Integer[] CLASSES = property.getIntArray("classes");

实现方法:
/**
* 随机选择某一个值
*
* @param fs
* @param <F>
* @return
*/
public static <F extends Number> F random(F... fs) {
return fs[getRandomInt(fs.length) - 1];
}
/**
* 随机选择某一个字符串
*
* @param fs
* @return
*/
public static String random(String... fs) {
if (ArrayUtils.isEmpty(fs)) ParamException.fail("数组不能为空!");
return fs[getRandomInt(fs.length) - 1];
}
/**
* 随机选择某一个对象
*
* @param list
* @param <F>
* @return
*/
public static <F extends Object> F random(List<F> list) {
if (list == null || list.isEmpty()) ParamException.fail("数组不能为空!");
return list.get(getRandomInt(list.size()) - 1);
}
-
如果是
Groovy来写,可以用0..10来选择随机数字范围。
上游接口获取
例如JSONObject response = clazz.recommend(ks.id, ks.type, ks.level)这个接口请求中,用到的K对象是从上游接口def klist = mirro.getKList()中获取的,所有可用的K对象都在接口中返回。
如果想丰富clazz.recommend()方法的请求参数的话,一定要将mirro.getKList()中的响应结果解析成List<K>的形式。
因为多层结构,我只解析了第一层的。
def karray = klist.getJSONArray("data")
def kss = []
karray.each {
JSONObject parse = JSON.parse(JSON.toJSONString(it))
def level = parse.getIntValue("node_level")
def type = parse.getIntValue("ktype")
def id = parse.getIntValue("id")
kss << new K(id, type, level)
}
这里我没有提前将所以可用的参数都存起来,原因有二:用户不会这么做;数据可能会变动。我提到无数据驱动,这就是个例子,不给用例输入除账号密码外的数据。
K ks = kss.get(0)
K ks2 = kss.get(1)
K ks3 = kss.get(3)
clazz.recommend(ks3.id, ks3.type, ks3.level)
clazz.recommend(ks2.id, ks2.type, ks2.level)
JSONObject response = clazz.recommend(ks.id, ks.type, ks.level)
上游接口造数据
这个比如收藏和取消收藏接口,正常来讲,首页可以收藏和取消收藏。在获取个人列表页可以取消收藏。这里我设置了先收藏,再去个人列表页,然后取消收藏。
这样既保证正常业务流程下,最后取消接口的是有足够的可用接口的。
JSONObject response = clazz.recommend(ks.id, ks.type, ks.level)
def minis = []
int i = 0
response.getJSONArray("data").each {
if (i++ < 2) {
JSONObject parse = JSON.parse(JSON.toJSONString(it))
int value = parse.getIntValue("minicourse_id")
clazz.collect(value, ks.type, ks.id)
}
}
mirro.getMiniCourseListV3(ks.id, ks.type, 0, ks.level)
def res = mirro.getMiniCourseListV3(ks.id, ks.type, 0, ks.level)
res.getJSONObject("data").getJSONArray("minicourse_list").each {
def ss = JSON.parseObject(JSON.toJSONString(it))
def mid = ss.getIntValue("minicourse_id")
clazz.unCollect(mid, ks.type, ks.id)
}
提前造数据
这个就更常用了,有些时候我们在性能测试的时候,必须要进行前期大量测试数据的构造工作。关于这个话题,很多文章都写过了。我这里分享一下在多线程条件下,如何保证每个线程拿到参数唯一性的方法。
我先讲构造的数据通过配置文件(这里可以临时从数据库中查)读取到一个线程安全的LinkedBlockingQueue中,然后每个线程每次获取都取走一个对象,这样就可以满足需求了。
static LinkedBlockingQueue<String> sqls = new LinkedBlockingQueue<>();
存储和获取的方法:
/**
* 添加存储任务,数据库存储服务用
*
* @param sql
* @return
*/
public static boolean addWork(String sql) {
try {
sqls.put(sql);
} catch (InterruptedException e) {
logger.warn("添加数据库存储任务失败!", e);
return false;
}
return true;
}
/**
* 从任务池里面获取任务
*
* @return
*/
static String getWork() {
String sql = null;
try {
sql = sqls.poll(SqlConstant.MYSQLWORK_TIMEOUT, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
logger.warn("获取存储任务失败!", e);
} finally {
return sql;
}
}
这里需要提前预估消耗量,不然容易因为数据量准备不足导致测试失败。当然,也可以单独写一个线程,不断往队列中添加数据以保障测试用例顺利执行。
总结:
感谢每一个认真阅读我文章的人!!!
我个人整理了我这几年软件测试生涯整理的一些技术资料,包含:电子书,简历模块,各种工作模板,面试宝典,自学项目等。欢迎大家点击下方名片免费领取,千万不要错过哦。
Python自动化测试学习交流群:全套自动化测试面试简历学习资料获取点击链接加入群聊【python自动化测试交流】:![]() http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=DhOSZDNS-qzT5QKbFQMsfJ7DsrFfKpOF&authKey=eBt%2BF%2FBK81lVLcsLKaFqnvDAVA8IdNsGC7J0YV73w8V%2FJpdbby66r7vJ1rsPIifg&noverify=0&group_code=198408628
http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=DhOSZDNS-qzT5QKbFQMsfJ7DsrFfKpOF&authKey=eBt%2BF%2FBK81lVLcsLKaFqnvDAVA8IdNsGC7J0YV73w8V%2FJpdbby66r7vJ1rsPIifg&noverify=0&group_code=198408628