目录
前言
基于业务模型实现
基于流量录制回放
灰度分流
总结:
前言
现在全链路越来越火,各大厂商也纷纷推出了自己的全链路压测测试方案。特别是针对全链路压测流量模型,各家方案都有所不同。最近我看了一些这方面的资料,有一些感悟。分享给大家。
全链路压测流量模型的梳理呢,这里就先不讲了,各家公司自有司情在。因为主要是全链路压测模型的实现,其实实现也对应了流量模型的梳理结果。
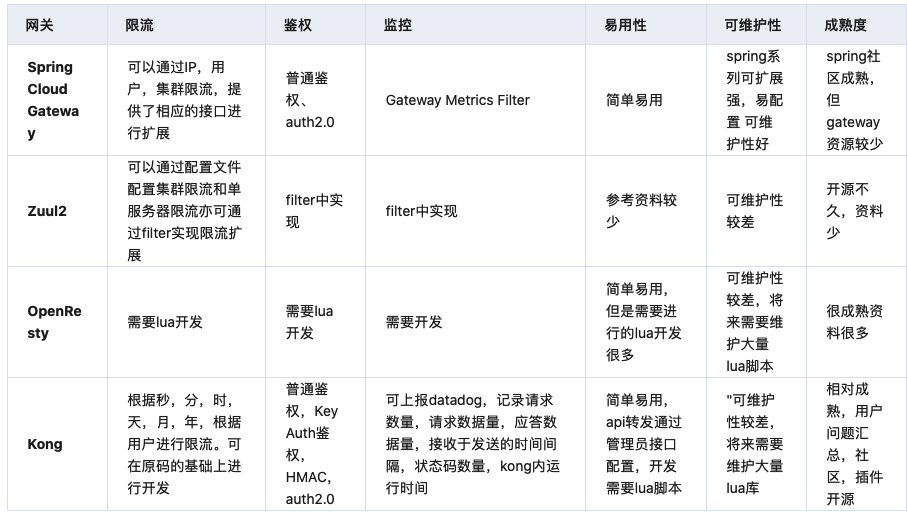
业界常用的三种方一种:是基于业务模型的实现,一种是基于真实流量的录制回放,最后一种是灰度分流。

基于业务模型实现
这个是一种比较常用的方式。首先要对公司业务模型进行梳理,也就是说对公司的业务链路进行梳理。这里的业务链路可能会比较复杂,不是像很多案例中到的了就非常流行畅的一条链路,中间很有可能会出现各种各样的支路。如果图图形化展示的话,某一条链路应该就是一个树形结构。树形结构的开始是用户的入口页一般就是入口页面的登陆,或者说是首页接口。四元结构的右侧是用户的出口,这里根据业务模型不同,用户的出口会非常的多,所以大多数来时候来讲,这就是一个分叉的树形结构。
要对这样的流量模型进行实现。是比较困难的。首先要梳理出这样的业务模型,就不太容易,再加上接口的相互调用啊,数据之间的相互依赖又可能是复杂程度增加一个量级。所以一般的实现方式就是做归拢。将比较复杂的树形结构简单化,或者干脆将以个业务联络分解成n个列有链路。然后分别实现。最终将流量汇聚,就变成了整个业务链路的流量模型实现。
在业务模型实现这个方向,各家都有不同的实现方式啊,基本上就分为工具以及脚本实现。我自己不怎么用工具做过接口的性能测试,全都是使用java和groovy脚本去实现的。首先,我会实现一个基于接口的业务测试框架,将每一个接口封装成一个方法。接口的参数即是这个方法的参数。然后将每一个用户封装成一个对象。将用户的各种信息变成这个对象的属性。然后用户在请求不同的接口的时候对用户的属性进行赋值这样就达到了一个参数传递的目的。然后通过调用不同的方法,我们就可以实现对不同接口的请求。通过控制参数或者说接口请求的频率,我们就可以达到控制当前用户。在整个业务链的走向。
基于流量录制回放
基于流量录制和回放,这个是最容易实现的方式。也是最容易贴近真实情况的方式。哦,我接触到的主要有一个回放模型,就是用golang语言写的goreply。go语言的性能是非常好的,用于性能测试足够满足用户的需求。大多数公司都会选择在原生引擎的基础上做一些封装。然后对对业务进行一些兼容,最主要的还是适配流量来源。通常流量的来源是通过日志文件来获取的,但是我看行业内也有通过一些固定的流量存储分析引擎去完成。这里的技术我不是太熟,也就不多分享啦。
我觉得基于流量录制回放这种模式有一个比较难以解决的问题:流量的不可见性。一般来说,录制流量会非常大。介于几十万上百万之间。这么规模大的流量,是很难对他进行可视化的。常遇到的一个问题,就是对于一些请求量非常小的接口。录制的时候可能会录丢。还有一种就是录制流量的时间范围不会太广。那么录制出来的流量文件只能反映录制时的流量模型,并不能反映其他录制时间段的流量模型。如果某个服务的流量是根据时间变化的。那么就需要对多个时间段都录制流量,然后进行合并。由于流量的不可见性,所以对流量的模型进行分析,就会显得比较麻烦。

灰度分流
这是我在某个会议上看到大佬分享的一个方案。灰度大家听的可能比较多的是灰度发布。就是将服务或者app更新范围限制在某些一批人,或者说某个地理范围。这里讲的灰度分流,其实核心上差不多,就是将线上的一部分流量转到某些机器上。以实现对这些机器所在服务的一些压测。这种方案。基于线上流量完成,所以几乎不需要测试。投入过多的资源进行开发实现。这种方案有点儿基于业务模型和基于流量录制取了一个中间态。既能保证流量的真实有效性。又可以避免开发测试脚本带来的负担。
这种方式对于公司的架构,主或者说是分流的实现来说,技术难度是比较高的。因为他用的全都是用户的真实数据,所以一旦出现问题的话,这个问题影响范围不太可控,而且比较严重。对于接收灰度分流流量的机器来说,压测流量完全真实。但是他也无法避免基于流量录制,回放同样的问题。就是流量的不可见性以及流量与时间可能存在于一个关联关系并不是线性的。甚至这一点流量的灰度分流还不如流量的录制与回放。我想这也是。我身边接触到的公司,都没有采用这种方案的原因吧。
总结:
感谢每一个认真阅读我文章的人!!!
我个人整理了我这几年软件测试生涯整理的一些技术资料,包含:电子书,简历模块,各种工作模板,面试宝典,自学项目等。欢迎大家评论区留言333或私我领取。