参考资料:
- 《统计学习方法》李航
- 通俗理解信息熵 - 知乎 (zhihu.com)
- 拉格朗日函数为什么要先最大化? - 知乎 (zhihu.com)
1 逻辑斯蒂回归
1.1 逻辑斯蒂回归
输入
x
=
(
x
(
1
)
,
x
(
2
)
,
⋯
,
x
(
n
)
,
1
)
T
x=(x^{(1)},x^{(2)},\cdots,x^{(n)},1)^T
x=(x(1),x(2),⋯,x(n),1)T ,参数
w
=
(
w
(
1
)
,
w
(
2
)
,
⋯
,
w
(
n
)
,
b
)
T
w=(w^{(1)},w^{(2)},\cdots,w^{(n)},b)^T
w=(w(1),w(2),⋯,w(n),b)T ,输出
Y
∈
{
0
,
1
}
Y\in\lbrace0,1\rbrace
Y∈{0,1} ,逻辑斯蒂模型为:
P
(
Y
=
1
∣
x
)
=
exp
(
w
⋅
x
)
1
+
exp
(
w
⋅
x
)
P
(
Y
=
0
∣
x
)
=
1
1
+
exp
(
w
⋅
x
)
P(Y=1|x)=\frac{\exp(w\cdot x)}{1+\exp(w\cdot x)}\\ P(Y=0|x)=\frac{1}{1+\exp(w\cdot x)}\\
P(Y=1∣x)=1+exp(w⋅x)exp(w⋅x)P(Y=0∣x)=1+exp(w⋅x)1
逻辑斯蒂模型会比较两个条件概率的大小,将
x
x
x 分到概率值较大的那一类。
1.2 参数估计
记
π
(
x
)
=
P
(
Y
=
1
∣
x
)
\pi(x)=P(Y=1|x)
π(x)=P(Y=1∣x) ,则似然函数:
L
(
w
)
=
∏
i
=
1
N
P
(
y
i
∣
x
i
,
w
)
=
∏
i
=
1
N
π
y
i
(
x
i
)
(
1
−
π
(
x
)
)
1
−
y
i
\begin{align} L(w)&=\prod\limits_{i=1}^{N}P(y_i|x_i,w)\notag\\ &=\prod\limits_{i=1}^{N}\pi^{y_i}(x_i)\big(1-\pi(x)\big)^{1-y_i}\notag \end{align}
L(w)=i=1∏NP(yi∣xi,w)=i=1∏Nπyi(xi)(1−π(x))1−yi
取对数,得:
l
(
w
)
=
∑
i
=
1
N
(
y
i
log
π
(
x
i
)
+
(
1
−
y
i
)
log
(
1
−
π
(
x
i
)
)
=
∑
i
=
1
N
(
y
i
log
π
(
x
i
)
+
(
1
−
y
i
)
log
(
1
−
π
(
x
i
)
)
)
=
∑
i
=
1
N
(
y
i
(
w
⋅
x
i
)
−
log
(
1
+
exp
(
w
⋅
x
i
)
)
)
\begin{align} l(w)&=\sum\limits_{i=1}^{N}\Big(y_i\log\pi(x_i)+(1-y_i)\log\big(1-\pi(x_i)\Big)\notag\\ &=\sum\limits_{i=1}^{N}\Big(y_i\log\pi(x_i)+(1-y_i)\log\big(1-\pi(x_i)\big)\Big)\notag\\ &=\sum\limits_{i=1}^{N}\big(y_i(w\cdot x_i)-\log(1+\exp(w\cdot x_i))\big) \end{align}
l(w)=i=1∑N(yilogπ(xi)+(1−yi)log(1−π(xi))=i=1∑N(yilogπ(xi)+(1−yi)log(1−π(xi)))=i=1∑N(yi(w⋅xi)−log(1+exp(w⋅xi)))
采用随机梯度下降法,求出梯度:
KaTeX parse error: Expected 'EOF', got '&' at position 36: …}{\partial w_j}&̲=\sum\limits_{i…
1.3 逻辑蒂斯的推广
逻辑蒂斯也适用于多分类模型:
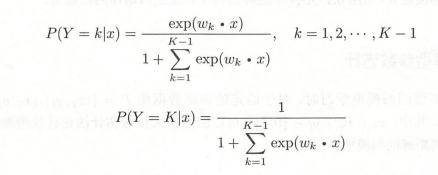
2 最大熵模型
2.1 最大熵原理
设随机变量
X
∼
P
(
X
)
X\sim P(X)
X∼P(X) ,则随机变量
X
X
X 的熵
H
(
X
)
H(X)
H(X) 为:
H
(
X
)
=
−
∑
x
P
(
x
)
log
P
(
x
)
H(X)=-\sum\limits_{x}P(x)\log P(x)
H(X)=−x∑P(x)logP(x)
进一步地,定义条件熵
H
(
Y
∣
X
)
H(Y|X)
H(Y∣X) 为:
H
(
Y
∣
X
)
=
∑
x
P
(
x
)
H
(
Y
∣
X
=
x
)
=
−
∑
x
,
y
P
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
H(Y|X)=\sum_{x}P(x)H(Y|X=x)=-\sum\limits_{x,y}P(x)P(y|x)\log P(y|x)
H(Y∣X)=x∑P(x)H(Y∣X=x)=−x,y∑P(x)P(y∣x)logP(y∣x)
所谓最大熵原理,就是在所有符合约束条件的模型中,选取熵最大的模型。
2.2 最大熵模型的定义
一般而言,我们的分类模型是一个条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 。给定训练集 T = { ( x 1 , y 1 ) , ⋯ , ( x N , y N ) } T=\lbrace(x_1,y_1),\cdots,(x_N,y_N)\rbrace T={(x1,y1),⋯,(xN,yN)} ,我们可以得到联合经验分布和边缘经验分布:
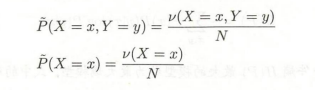
定义一组特征函数:
f
i
(
x
,
y
)
=
{
1
,
x
和
y
满足某一事实
0
,
其他
f_i(x,y)= \begin{cases} 1,&x和y满足某一事实\\ 0,&其他 \end{cases}
fi(x,y)={1,0,x和y满足某一事实其他
特征函数关于经验分布
P
~
(
X
,
Y
)
\tilde{P}(X,Y)
P~(X,Y) 的期望为:
E
P
~
(
f
i
)
=
∑
x
,
y
P
~
(
x
,
y
)
f
i
(
x
,
y
)
E_{\tilde{P}}(f_i)=\sum\limits_{x,y}\tilde{P}(x,y)f_i(x,y)
EP~(fi)=x,y∑P~(x,y)fi(x,y)
特征函数关于模型
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X) 和经验分布
P
~
(
X
)
\tilde{P}(X)
P~(X) 的期望为:
E
P
(
f
i
)
=
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
f
i
(
x
,
y
)
E_{P}(f_i)=\sum\limits_{x,y}\tilde{P}(x)P(y|x)f_i(x,y)
EP(fi)=x,y∑P~(x)P(y∣x)fi(x,y)
模型的约束条件定义为:对所有的特征函数,有
E
P
~
(
f
i
)
=
E
P
(
f
i
)
E_{\tilde{P}}(f_i)=E_{P}(f_i)
EP~(fi)=EP(fi)
2.3 最大熵模型的学习
最大熵的学习等价于约束最优化问题:
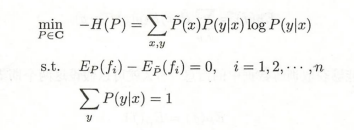
C C C 为所有满足约束条件的模型的集合
引入拉格朗日乘数法:
L
(
P
,
w
)
=
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
+
w
0
(
∑
y
p
(
y
∣
x
)
−
1
)
+
∑
i
=
1
n
w
i
(
E
P
~
(
f
i
)
−
E
P
(
f
i
)
)
L(P,w)=\sum\limits_{x,y}\tilde{P}(x)P(y|x)\log P(y|x)+w_0\big(\sum\limits_{y}p(y|x)-1\big)+\sum\limits_{i=1}^{n}w_i\big(E_{\tilde{P}}(f_i)-E_{P}(f_i)\big)
L(P,w)=x,y∑P~(x)P(y∣x)logP(y∣x)+w0(y∑p(y∣x)−1)+i=1∑nwi(EP~(fi)−EP(fi))
在一般的机器学习模型中,我们往往要先给出模型的表达式(
P
(
Y
∣
X
;
w
)
P(Y|X;w)
P(Y∣X;w) ),然后通过训练集来选取合适的参数。所以,我们要试着改写优化问题,使之能向一般的机器学习模型靠拢。
首先,上述最优化问题等价于:
min
P
∈
C
max
w
L
(
P
,
w
)
\min\limits_{P\in C}\max\limits_{w}L(P,w)
P∈CminwmaxL(P,w)
这是因为如果所有约束条件均被满足,则必有
−
H
(
P
)
=
max
w
L
(
P
,
w
)
-H(P)=\max\limits_{w}L(P,w)
−H(P)=wmaxL(P,w) ;如果存在某个约束条件不被满足,则一定可以通过调整对应参数,使得
max
w
L
(
P
,
w
)
=
+
∞
\max\limits_{w}L(P,w)=+\infty
wmaxL(P,w)=+∞ ,这保证了通过
min
max
\min\max
minmax 方式得到的解,一定是符合约束条件的解。
然后,我们根据拉格朗日对偶性得到对偶问题:
max
w
min
P
∈
C
L
(
P
,
w
)
\max\limits_{w}\min\limits_{P\in C}L(P,w)
wmaxP∈CminL(P,w)
首先求解
min
P
∈
C
L
(
P
,
w
)
\min\limits_{P\in C}L(P,w)
P∈CminL(P,w) :
∂
L
(
P
,
w
)
∂
P
=
∑
x
,
y
P
~
(
x
)
(
1
+
log
P
(
y
∣
x
)
)
+
∑
y
w
0
−
∑
i
=
1
n
(
w
i
∑
x
,
y
P
~
(
x
)
f
i
(
x
,
y
)
)
=
∑
x
,
y
P
~
(
x
)
(
1
+
log
P
(
y
∣
x
)
−
w
0
−
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
\begin{align} \frac{\partial L(P,w)}{\partial P}&=\sum\limits_{x,y}\tilde{P}(x)\big(1+\log P(y|x)\big)+\sum\limits_{y}w_0-\sum\limits_{i=1}^{n}\big(w_i\sum\limits_{x,y}\tilde{P}(x)f_i(x,y)\big)\notag\\ &=\sum\limits_{x,y}\tilde{P}(x)\Big(1+\log P(y|x)-w_0-\sum\limits_{i=1}^{n}w_if_i(x,y)\Big)\notag\\ \end{align}
∂P∂L(P,w)=x,y∑P~(x)(1+logP(y∣x))+y∑w0−i=1∑n(wix,y∑P~(x)fi(x,y))=x,y∑P~(x)(1+logP(y∣x)−w0−i=1∑nwifi(x,y))
令偏导数为
0
0
0 ,在
P
~
(
x
)
>
0
\tilde{P}(x)>0
P~(x)>0 的情况下,有:
P
(
y
∣
x
)
=
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
exp
(
1
−
w
0
)
P(y|x)=\frac{\exp\Big(\sum\limits_{i=1}^{n}w_if_i(x,y)\Big)}{\exp(1-w_0)}
P(y∣x)=exp(1−w0)exp(i=1∑nwifi(x,y))
通过
∑
y
P
(
y
∣
x
)
=
1
\sum\limits_{y}P(y|x)=1
y∑P(y∣x)=1 消去
w
0
w_0
w0 得:
P
(
y
∣
x
)
=
1
Z
w
(
x
)
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
P(y|x)=\frac{1}{Z_w(x)}{\exp\Big(\sum\limits_{i=1}^{n}w_if_i(x,y)\Big)}
P(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))
其中:
Z
w
(
x
)
=
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
Z_w(x)=\sum\limits_{y}\exp\Big(\sum\limits_{i=1}^{n}w_if_i(x,y)\Big)
Zw(x)=y∑exp(i=1∑nwifi(x,y))
此时,将
P
(
y
∣
x
)
P(y|x)
P(y∣x) 代回
L
(
P
,
w
)
L(P,w)
L(P,w) ,再求出
max
w
L
(
P
,
w
)
\max\limits_{w}L(P,w)
wmaxL(P,w) 即可。
3 模型学习的最优化算法
3.1 改进的迭代尺度法(IIS)
IIS是最大熵模型的最优化算法,其想法是根据当前的参数向量 w = ( w 1 , w 2 , ⋯ , w n ) T w=(w_1,w_2,\cdots,w_n)^T w=(w1,w2,⋯,wn)T 找到一个 δ \delta δ ,使得似然函数 L ( w + δ ) ≥ L ( w ) L(w+\delta)\ge L(w) L(w+δ)≥L(w) 。实际操作时,通常是构造一个似然函数改变量的下界 B ( δ ∣ w ) B(\delta|w) B(δ∣w),然后取 δ \delta δ 为下界函数的最大值点。
已知最大熵模型为:
P
(
y
∣
x
)
=
1
Z
w
(
x
)
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
P(y|x)=\frac{1}{Z_w(x)}{\exp\Big(\sum\limits_{i=1}^{n}w_if_i(x,y)\Big)}
P(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))
其中:
Z
w
(
x
)
=
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
Z_w(x)=\sum\limits_{y}\exp\Big(\sum\limits_{i=1}^{n}w_if_i(x,y)\Big)
Zw(x)=y∑exp(i=1∑nwifi(x,y))
对数似然函数为:
L
(
w
)
=
∑
i
=
1
N
log
P
(
y
i
∣
x
i
,
w
)
=
∑
x
,
y
P
~
(
x
,
y
)
log
P
(
y
∣
x
,
w
)
\begin{align} L(w)&=\sum\limits_{i=1}^{N}\log P(y_i|x_i,w)\notag\\ &=\sum\limits_{x,y}{\tilde{P}(x,y)}\log P(y|x,w)\notag \end{align}
L(w)=i=1∑NlogP(yi∣xi,w)=x,y∑P~(x,y)logP(y∣x,w)
其实第一行的式子并不等于第二行的式子,但二者的变化趋势是相同的。