开窗函数的语法结构:分析函数() over(partition by 分组列名 order by 排序列名 rows between 开始位置 and 结束位置)
over()函数中包括三个函数:分区partition by 列名、排序order by 列名、指定窗口范围rows between 开始位置 and 结束位置
rows between … and … 用得较少
我们知道聚合函数对一组值执行计算并返回单一的值,如sum(),count(),max(),min(), avg()等,这些函数常与group by子句连用。除 COUNT 外,聚合函数忽略空值。
但有时候一组数据只返回一组值是不满足需求的,如经常想知道各地区的前几名、各个班或各个学科的前几名。这时候需要每一组返回多个值。用开窗函数解决这类问题非常方便。它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
建表
DROP TABLE IF EXISTS temp
CREATE TABLE temp(
id INT,
name VARCHAR(10),
class VARCHAR(10),
score INT
);
INSERT INTO temp (id, name, class, score) VALUES (1,'公孙衍', '2', 81);
INSERT INTO temp (id, name, class, score) VALUES (2,'廉颇', '3', 55);
INSERT INTO temp (id, name, class, score) VALUES (3,'李牧', '3', 55);
INSERT INTO temp (id, name, class, score) VALUES (4,'王翦', '1', 96);
INSERT INTO temp (id, name, class, score) VALUES (5,'王贲', '1', 92);
INSERT INTO temp (id, name, class, score) VALUES (6,'白起', '1', 96);
INSERT INTO temp (id, name, class, score) VALUES (7,'蔺相如', '3', 90);
INSERT INTO temp (id, name, class, score) VALUES (8,'赵胜', '3', 81);
INSERT INTO temp (id, name, class, score) VALUES (9,'赵雍', '3', 93);
INSERT INTO temp (id, name, class, score) VALUES (10,'魏无忌', '2', 92);
OVER(PARTITION BY … ORDER BY … DESC)
实例:
| 无分组排序 | 分组排序(对班级) |
| SELECT name,class,score, ROW_NUMBER() OVER(ORDER BY score DESC) mm FROM temp | SELECT name,class,score, ROW_NUMBER() OVER(PARTITION BY class ORDER BY score DESC) mm FROM temp |
 |  |
--也能用无分组无次序的排序实现,只是没有排序后的次序(也就是没有mm列)
SELECT * FROM temp ORDER BY sroce DESC
实例:
| 查询每个班第一名的成绩 | 查询每个班最后一名的成绩 |
| SELECT name,class,score FROM (SELECT name,class,score, RANK() OVER(PARTITION BY class ORDER BY score DESC) mm FROM TEMP ) a WHERE mm = 1; | SELECT name,class,score FROM ( SELECT name,class,score, RANK() OVER(PARTITION BY class ORDER BY score) mm FROM temp ) a WHERE mm = 1; |
 |
|
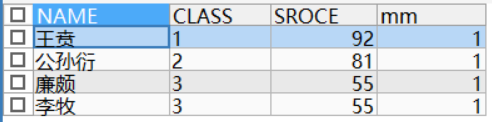
在求第一名成绩时,不能用row_number(),因为如果同班有两个并列第一,mm=1就只返回一个结果。
不加desc,排序就默认升序,取mm=1,就是最后一名
分组排序函数:row_number()、rank() 、dense_rank()、ntile()
- select *,ROW_NUMBER() over(order by name) as 排序 from temp
排序,值一样不会重复排序。如1,2,3,4,5
- select *,RANK() over(order by name) as 排序 from temp
排序,值一样重复排序,有间隙。如1,1,3,4
- select *,DENSE_RANK() over(order by name) as 排序 from temp
排序,值一样重复排序,没有间隙。如1,1,2,2,3,4,5
- select *,NTILE(2) over(order by name) as 排序 from temp
排序,分成2组。此函数一般用于取表中前百分之几的数据。如,取数据的前25%就将数据分4组,然后字段的条件是等于1。
偏移分析窗口函数 lag()、lead()
lag和lead分析函数可以在同一次查询中,取出同一字段的前N行数据(lag)和 后N行数据(lead)作为独立的列。
在实际应用中,若要用到取今天和昨天的某字段差值时,lag和lead函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但lag和lead与left join、right join 等自连接相比,效率更高。
lag(exp_str, offset, defval) over(partition by … order by …)
lead(exp_str, offset, defval) over(partition by … order by …)- exp_str 是字段名
- offset 是偏移量, 即上1个或上N个的值,假设当前行在表中排在第5行,则offset 为3,则表示我们所要找的数据行就是表中的第2行(即5-3=2) 。offset默认值为1。
- defval 是默认值, 当两个函数取上N/下N个值,当在表中从当前行位置向前数N行已经超出了表的范围时,lag()函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NUL。数学运算中,总要给一个默认值才不会出错。
1、lag() 实例
SELECT id,score,
LAG(score,1,0)OVER() AS n1,
LAG(score,1) OVER() AS n2,
LAG(score,2,0)OVER() AS n6,
LAG(score,2) OVER() AS n7
FROM temp
2、lead() 实例
SELECT id,score,
LEAD(score,1,0)OVER() AS n1,
LEAD(score,1) OVER() AS n2,
LEAD(score,2,0)OVER() AS n6,
LEAD(score,2) OVER() AS n7
FROM temp
其他聚合函数
| 名称 | 描述 |
| CUME_DIST() | 累计分配值 |
| DENSE_RANK() | 当前行在其分区内的排名,没有间隙 |
| FIRST_VALUE() | 窗口框架第一行的参数值 |
| LAG() | 来自分区内滞后当前行的行的参数值 |
| LAST_VALUE() | 窗口框架最后一行的参数值 |
| LEAD() | 分区内行前导当前行的参数值 |
| NTH_VALUE() | 来自第 N 行窗口框架的参数值 |
| NTILE() | 其分区内当前行的桶数 |
| PERCENT_RANK() | 百分比排名值 |
| RANK() | 当前行在其分区内的排名,有间隙 |
| ROW_NUMBER() | 其分区内的当前行数 |
group by是对检索结果的保留行进行单纯分组,一般和聚合函数一起使用。如max、min、sum、avg、count等一块用。 partition by虽然也具有分组功能,但同时也具有其他的高级功能。
sum() over()的使用
显示全部字段是为了方便查看,当有明确目标的时候可以适当选择相应字段。
| SELECT t.*, SUM(t.score) s_sum FROM temp t GROUP BY t.class | SELECT t.*, SUM(t.score) OVER(PARTITION BY t.class ORDER BY t.score DESC) s_sum FROM TEMP t | SELECT t.*, SUM(t.score) OVER(ORDER BY t.id) s_sum FROM temp t |
 | 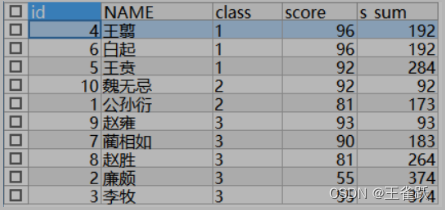 | 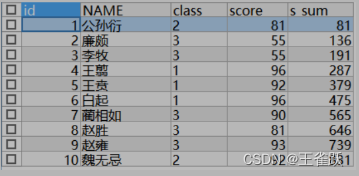 |
avg() over()的使用

SELECT id, score, AVG(score) OVER(ORDER BY id ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) FROM temp

ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
限制计算移动平均值的范围,本语句包含本行和前两行。
语法总结:
avg(…A...) over(partition by …b… order by …C… rows between …D1… and …D2…)
sum(…A…) over(partition by …b… order by …C… rows between …D1… and …D2…)
- A:需要被加工的字段名称
- B:分组的字段名称
- C:排序的字段名称
- D:计算的行数范围
窗口范围说明:
- preceding:往前
- following:往后
- current row:当前行
- unbounded:起点(一般结合preceding,following使用)
- unbounded preceding表示该窗口最前面的行(起点)
- unbounded following:表示该窗口最后面的行(终点)