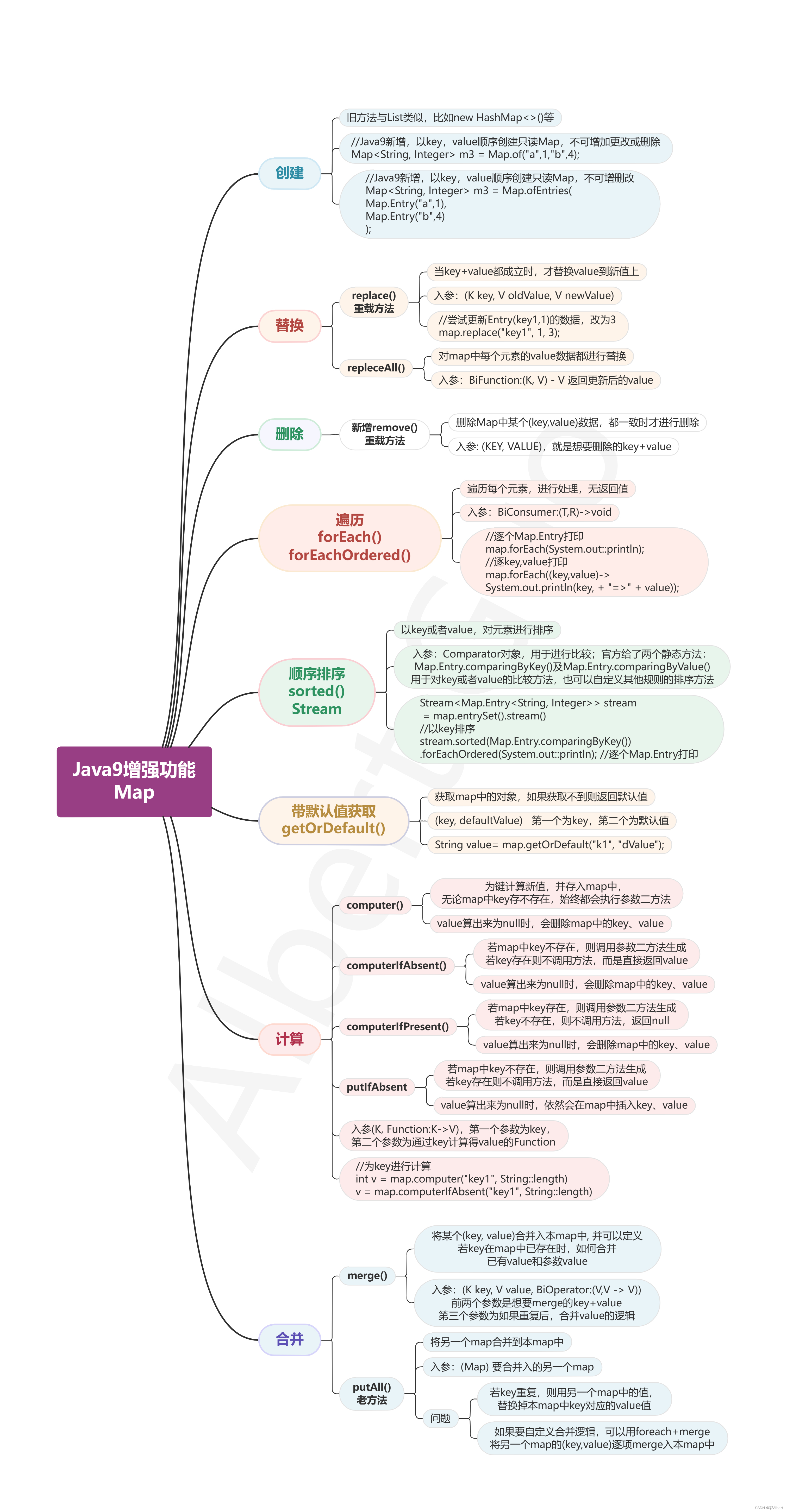
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,以便在不同的应用程序中使用。
今天我们来学习DeepLearning.AI的在线课程:LangChain for LLM Application Development的第二门课:Memory,该门课程主要讲解几种和LLM交互时的内存记忆方法。一般情况下我们通过api的方式来访问openai的语言模型时,LLM是没有记忆能力的,也就是说LLM不能记住之前与用户对话的内容,要解决这个问题,我们必须每次与LLM对话时都必须将之前的所有对话内容全部输入给LLM,但这样也会增加程序的复杂性,同时也会增加经济成本,因为像ChatGPT这样的LLM是根据用户提交的数据内容的token数量来收费的,如果我们每次和LLM交互时提交的内容越多也就意味着token越多,那么就会产生越多的费用。这里Langchain提供了几种内存记忆组件可以帮助我们使用更高效和经济的方法来与LLM交互。
大纲
- ConversationBufferMemory
- ConversationBufferWindowMemory
- ConversationTokenBufferMemory
- ConversationSummaryMemory
ConversationBufferMemory
ConversationBufferMemory是一种最简单的记忆力组件,它会记住每次与LLM对话内容,并在下一轮对话时将历史对话记录全部传给LLM,这样LLM就会记住之前的对话内容,下面我们看一个例子:
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
import warnings
warnings.filterwarnings('ignore')from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI(temperature=0.0)
#定义ConversationBufferMemory记忆力组件
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory = memory,#加入ConversationBufferMemory组件
verbose=True
)这里我们定义了一个llm, 该llm默认使用的是openai的"gpt-3.5-turbo"模型,同时我们温度参数temperature设置为0.0,这个很重要,因为温度参数temperature代表了LLM回答问题时候的随机性,取值范围是0-1之间,如果temperature越大,则LLM回答问题的随机性就会越大,这里我们将temperature设置为0,其目的是让LLM每次只选择概率最高的答案,从而避免产生随机答案。
conversation.predict(input="你好,我的名字叫王老六")
这里我们看到,在与LLM交互时Langchain会产生一个prompt其中除了用户的输入的内容外,还有一段英语的前缀信息,这里前缀信息+用户信息构成了一个完整的prompt,下面我们进行第二轮对话:
conversation.predict(input="1+1等于几?")
在langchain产生的第二轮对话的prompt中,我们看到除了前缀信息以为,还增加了历史对话记录。下面我们看第三轮对话:
conversation.predict(input="你还记得我叫什么名字吗?") 
第三轮对话时用户询问了LLM是否还记得用户的名字,LLM给出了正确的答案,这是因为第三轮对话的prompt中包含了历史所有的对话记录,所以LLM能够记住用户的名字。这里记住所有历史对话记录的能力就是由ConversationBufferMemory组件来实现的。
下面我们可以查看ConversationBufferMemory的一些内置方法:
print(memory.buffer)
memory.load_memory_variables({}) 
memory = ConversationBufferMemory()
memory.save_context({"input": "你好"},
{"output": "有啥事吗?"})
print(memory.buffer) 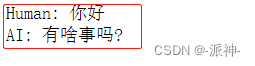
memory.load_memory_variables({})![]()
memory.save_context({"input": "想找你聊天,可以吗?"},
{"output": "好的,没问题!"})
memory.load_memory_variables({}) 
ConversationBufferWindowMemory
ConversationBufferWindowMemory组件与ConversationBufferMemory组件功能类似,只是ConversationBufferWindowMemory组件增加了一个窗口参数k, 因为之前的ConversationBufferMemory组件会在prompt中记录历史所有的聊天对话内容,而ConversationBufferWindowMemory组件只会记住最近的k轮对话内容,更早之前的对话讲话被抛弃而不保存在prompt中,下面我们看一个例子:
from langchain.memory import ConversationBufferWindowMemory
llm = ChatOpenAI(temperature=0.0)
#定义内存组件
memory = ConversationBufferWindowMemory(k=1)#k=1,意味着只能记住最后1轮对话内容
conversation = ConversationChain(
llm=llm,
memory = memory, #添加记忆力组件
verbose=True #展示中间结果
)这里我们将ConversationBufferWindowMemory对象的参数K设置为1,这意味着在prompt中只保留最近一轮的历史对话记录。
conversation.predict(input="你好,我是王老六。")
conversation.predict(input="1+1等于几?")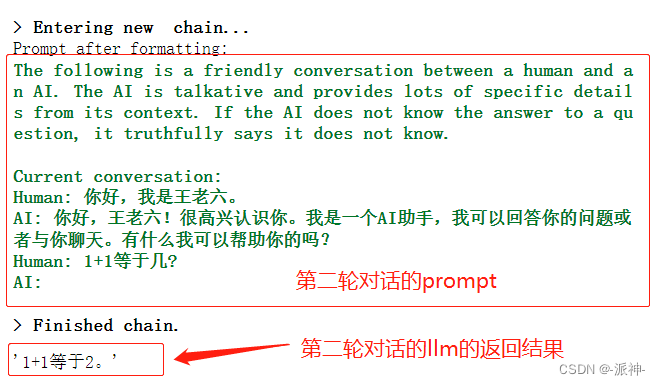
conversation.predict(input="你还记得我叫什么名字吗?") 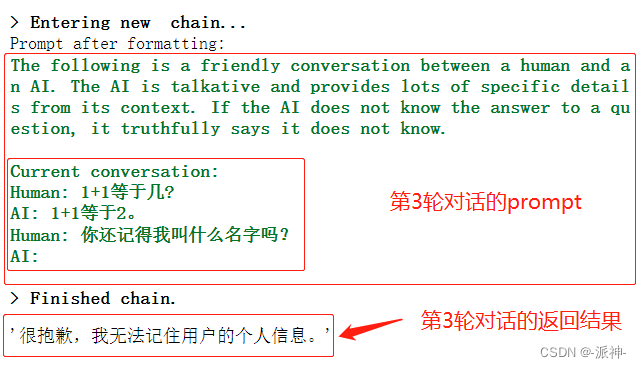
由于在第三轮对话的时候,prompt中只保留了上一轮对话的历史记录,且没有包含首轮对话记录,因此LLM并不记得在首轮对话时用户告诉LLM关于用户名字的信息,因此此时LLM无法给出用户的名字。下面我们再做一些简单的测试:
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "Hi"},
{"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"},
{"output": "Cool"})
memory.load_memory_variables({})
这里我们也可以看到,虽然我们给memory组件手动增加了两组对话记录,但是最终它只保存了一组对话记录,这是因为我们定义memory时设置了窗口参数k=1所导致的。
ConversationTokenBufferMemory
ConversationTokenBufferMemory组件的功能也是限制prompt中存储对话记录的数量,与ConversationBufferWindowMemory不同的是ConversationBufferWindowMemory组件是根据窗口参数K来限制对话条数,而ConversationTokenBufferMemory组件是根据token数量来限制prompt中的对话条数:
#!pip install tiktoken
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI
llm = ChatOpenAI(temperature=0.0)
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30)
memory.save_context({"input": "AI is what?!"},
{"output": "Amazing!"})
memory.save_context({"input": "Backpropagation is what?"},
{"output": "Beautiful!"})
memory.save_context({"input": "Chatbots are what?"},
{"output": "Charming!"})上面我们在定义ConversationTokenBufferMemory时设置了参数max_token_limit的值为30,这意味着prompt中的历史对话数据的token数量不能超过30个token,接着我们给ConversationTokenBufferMemory组件手动增加了3轮对话记录,下面我们看看ConversationTokenBufferMemory组件最终能保存多少轮对话记录:
memory.load_memory_variables({})
这里我们看到ConversationTokenBufferMemory组件保存了最近的30个token左右的对话记录,更早之前的对话记录已被丢弃,关于计算token的方法,不在本篇博客中说明。用户可以执行查阅相关资料。
ConversationSummaryMemory
ConversationSummaryMemory顾名思义会在prompt中保存历史对话记录的摘要,而不是完整的对话记录,下面我们来看一个例子:
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAI
#定义llm
llm = ChatOpenAI(temperature=0.0)
schedule ="""
上午 8 点与您的产品团队召开会议。\
您需要准备好幻灯片演示文稿。\
上午 9 点到中午 12 点有时间处理你的 LangChain 项目,\
这会进展得很快,因为 Langchain 是一个非常强大的工具。\
中午,在意大利餐厅与开车的顾客共进午餐\
距您一个多小时的路程,与您见面,了解人工智能的最新动态。\
请务必携带您的笔记本电脑来展示最新的LLM演示。\
"""
#定义ConversationSummaryBufferMemory组件
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
memory.save_context({"input": "你好"}, {"output": "什么事?"})
memory.save_context({"input": "没啥事情, 有个小问题请教"},
{"output": "好的,请说"})
memory.save_context({"input": "今天的日程安排是什么?"},
{"output": f"{schedule}"})
memory.load_memory_variables({})
在上面我们定义了一个ConversationSummaryMemory组件,并且设置了max_token_limit为100,这意味着prompt中的历史对话摘要的长度不能超过100个token。然后我们模拟了一组聊天记录,从返回的结果上看,memory组件中保存的不再是完整的对话记录,而是一段原始对话的摘要。保留摘要的好处是即保存了原始对话的内容的主要含义,又节省了token。
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True
)
conversation.predict(input="一个好的演示应该展示什么?")
参考资料
https://learn.deeplearning.ai/langchain/lesson/3/memory