一、Redis数据类型及命令
(一)String
| 类别 | 命令描述 | 命令 | 示例 | 备注 |
| 取/赋值操作 | 赋值 | set key value | set lclkey lclvalue | |
| 取值 | get key | get lclkey | ||
| 取值并赋值 | getset key value | getset lclkey1 lclvalue1 | 获取原值,并设置新的值 | |
| 仅当不存在时赋值 | setnx key value | setnx lcl4 value4 | 设置成功返回1,设置失败返回0;可以用来实现分布式锁 | |
| 同时设置多个值 | mset key value [key value ......] | mset s1 v1 s2 v2 s3 v3 | ||
| 同时获取多个值 | mget key value [key value ......] | mget s1 s2 s3 | ||
| 数值增减 | 数值递增 | incr key | incr lcl3 | 1、当value为整数时,才能做数值增减操作 2、数值增减都是原子操作 3、redis中每一个命令都是原子操作,但是当多个命令一起执行时,就不能保证原子性,不过可以使用redis的事务和Lua脚本来实现 |
| 增加指定整数 | incrby key increment | incrby lcl3 5 | ||
| 数值递减 | decr key | decr lcl3 | ||
| 减指定证数 | decrby key incrment | decrby lcl3 5 | ||
| 其他命令 | 向尾部追加值 | append key value | append lclkey 123 | 该命令返回的是value的长度 |
| 获取字符串长度 | strlen key | strlen lclkey |
(二)hash
hash类型也叫散列类型,它提供了字段和字段值的映射关系,字段值只能是字符串类型,不支持散列类型、集合类型等类型。
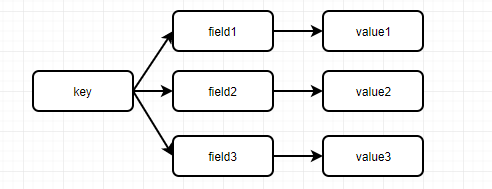
hash一般用于存储需要变更的对象。
| 类型 | 命令描述 | 命令 | 示例 | 备注 |
| 设置/获取值 | 设置一个字段 | hset key field value | hset lclhash h1 v1 | 插入时返回1,更新时返回0 |
| 设置多个字段 | hmset key field value[field value......] | hmset lclhash h2 v2 h3 v3 h4 v4 | ||
| 当字段不存在时赋值 | hsetnx key field value | hsetnx lclhash h5 v5 | ||
| 取一个字段值 | hget key field | hget lclhash h1 | ||
| 获取多个字段的值 | hmget key field[field......] | hmget lclhash h1 h2 h3 | ||
| 获所有字段的值 | hgetall key | hgetall lclhash | 返回的是错有的field和对应的值 | |
| 获取字段名 | hkeys key | hkeys lclhash | ||
| 获取字段值 | hvals key | hvals lclhash | ||
| 获取字段数量 | hlen key | hlen lclhash | ||
| 其他操作 | 删除一个或多个字段 | hdel key field[field......] | hdel lclhash h1 h2 | |
| 增加数字 | hincrby key field increment | hincrby lclhash age 5 | ||
| 判断字段是否存在 | hexists key field | hexists lclhash h1 | 存在返回1,不存在返回0 |
String类型和hash类型的区别:hash适合存储对象数据,特别是对象属性经常发生 增删改 操作的数据;string类型也可以存储对象数据,将java对象转换成json存储,这种主要适合 查询 操作。
(三)list
Redis的列表类型(list类型)可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。
列表类型内部使用双向链表实现的,所以向列表两端添加元素的时间复杂度为O(1),获取越接近两端的元素速度就越快,这意味着使用一个有几千万个元素的列表,获取头部或尾部的若干条记录也是非常快的。
list一般用于商品的评论列表等场景
| 类型 | 命令描述 | 命令 | 示例 | 备注 |
| lpush | 从左侧插入数据 | lpush key value[value......] | lpush mylist 1 2 3 4 | |
| rpush | 从右侧插入数据 | rpush key value[value......] | rpush mylist a b c d | |
| lrange | 从左侧获取列表中的某个片段 | lrange key start stop | lrange mylist 0 -1 | |
| lpop | 从左侧弹出一个元素 | lpop key | lpop mylist | |
| rpop | 从右侧弹出一个元素 | rpop key | rpop mylist | |
| llen | 获取列表中元素个数 | llen key | llen mylist | |
| lrem | 删除列表中前count个值为value的元素 | lrem key count value | lrem mylist 2 a | 当count>0时,从左边开始删除;当count<0时,从右边开始删除;当count=0时,删除所有值为value的数据 |
| lindex | 获取指定索引下元素的值 | lindex key index | lindex mylist 5 | 索引从0开始 |
| ltrim | 只保留列表中指定片段,指定范围与lrange一致 | ltrim key start stop | ltrim mylist 5 -1 | |
| linsert | 向列表中插入元素 | linsert key before|after pivot value | linsert mylist after b s | 从左侧找到pivot对应的元素,然后将value插入前/后 |
| rpoplpush | 将元素从一个列表移动到另外一个列表 | rpoplpush list newlist | rpoplprpoplpush mylist mynewlist | 一次只能处理一个 |
(四)set
set类型为集合类型,其中的数据是不重复且没有顺序的。
集合的常用操作是向集合中插入或删除元素,判断某个元素是否存在等,由于集合类型的redis内部是使用值为空的散列表实现的,因此所有这些操作的时间复杂度都为O(1)。
同时redis还提供了多个集合之间的交集、并集、差集的运算。
| 类型 | 命令 | 命令描述 | 命令样例 | 示例 | 备注 |
| 单集合操作 | sadd/srem | 向集合中添加/删除元素 | sadd key member[member......] | sadd myset a b c d a a e | |
| smembers | 获取集合中所有元素 | smembers key | smembers myset | ||
| sismember | 判断元素是否在集合中存在 | sismember key member | sismember myset b | 存在返回1,不存在返回0 | |
| scard | 获取集合中元素数量 | scard key | scard myset | ||
| spop | 从集合中弹出一个元素 | spop key | spop myset | 由于set是无序的,因此spop命令会从集合中随机选择一个元素弹出 | |
| 集合运算操作 | sdiff | 计算差集 | sdiff key [key......] | sdiff myset myset1 myset2 | 获取存在前一个集合但是不存在第二个集合的数据 |
| sinter | 交集 | sinter key [key......] | sinter myset myset1 | ||
| sunion | 并集 | sunion key [key......] | sunion myset myset1 |
(五)zset
zset即sortedset,也就是有序集合,是在set集合类型的基础上,有序集合类型为集合中的每个元素都关联一个分数,这样不仅可以操作插入、删除等操作,而且还能获取分数最高或最低的前N个元素、获取指定分数范围内的元素等与分数有关的操作。
zset和list的相同点:
1、两者都是有序的
2、二者都可以获取一定范围内的元素
zset和list的不同点:
1、列表内部是通过双向链表实现的,获取靠近两端的元素速度非常快,但是当元素增多后,获取中间的数据的速度则会变慢
2、有序集合类型使用散列表实现,即使数据位于集合的中间部分,读取速度依然很快
3、列表中不能简单的调整某个元素的位置,但是有序集合可以(通过更改分数实现)
4、有序集合要比列表类型更耗内存
zset的使用场景可以是根据商品销量对商品进行排序显示等操作。
| 命令 | 命令描述 | 命令样例 | 示例 | 备注 |
| zadd | 增加元素:向有序集合中加入一个元素和该元素的分数, 如果该元素已经存在,则会用新的分数替换原有的分数 | zadd key score member[score member......] | zadd mysortedset1 10 10a 20 20a 30 30a 6 6a | |
| zrange/zrevrange | 获得排名在某个范围的元素列表(zrange是升序,zrevrange是降序) | zrange key start stop | zrange sortedset1 0 2 | |
| zscore | 获取元素的分数 | zscore key member | zscore mysortedset1 6a | |
| zrem | 删除元素 | zrem key member[member......] | zrem mysortedset1 6a | |
| zrangebyscore | 获取指定分数区间的元素 | zrangebyscore key min max [withscores] | zrangebyscore mysortedset1 20 60 withscores | 命令不带withscores时,只返回元素,如果带withscores,则返回元素及元素的分数 |
| zincrby | 增加某个元素的值 | zincrby key increment member | zincrby mysortedset1 3 20a | 返回值为该元素增加后的分数 |
| zcard | 获得集合中元素的数量 | zcard key | zcard mysortedset1 | |
| zcount | 获取指定分数范围内的元素个数 | zcount key min max | zcount mysortedset1 30 610 | |
| zremrangebyrank | 按照排名范围删除 | zremrangebyrank key start stop | zremrangebyrank mysortedset1 3 4 | 左闭右开 |
| zremrangebyscore | 按照分数区间删除 | zremrangebyscore key min max | zremrangebyscore mysortedset1 10 30 | |
| zrangk/zrevrank | 获取元素的排名(下标索引) | zrank key member | zrank mysortedset1 20a |
(六)通用命令
| 命令 | 命令描述 | 命令样例 | 示例 | 备注 |
| keys | 返回满足给定条件的所有key | keys pattern | keys my* | |
| del | 删除 | del key | del lcl4 | |
| exists | 判断key是否存在 | exists key | exists lcl4 | 存在返回1,不存在返回0 |
| expire | 设置超时时间(秒) | expire key seconds | expire lclkey 100 | |
| ttl | 查看key剩余过期时间 | ttl key | ttl lclkey | 如果返回-2则说明已经过期;返回-1说明没有设置过期时间 |
| persist | 清除超时时间 | persist key | persist lclkey | |
| pexpire | 设置超时时间(毫秒) | pexpire key millseconds | pexpire lclkey 10000 | |
| rename | 重命名key | rename oldkey newkey | rename lclkey qmmkey | |
| type | 获取key的数据类型 | type key | type myset2 |
二、Redis特殊数据类型
(一)BitMap
BitMap就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是元素本身,实际上底层也是通过字符串的操作来实现,redis2.2版本之后新增了setbit、getbit、bitcount等几个bitmap命令,虽然是新的命令,但是本身都是对字符串的操作,语法如下:
使用 setbit key offset value 命令设置值,其中offset必须是数字,value只能是0或者1,同时可以使用 getbit key offset 来查询指定偏移量的值,可以使用 bitcount key 来做快速的统计(统计出来有多少设置为1的值)
127.0.0.1:6380> setbit k1 5 1
(integer) 0
127.0.0.1:6380> getbit k1 3
(integer) 0
127.0.0.1:6380> getbit k1 5
(integer) 1
127.0.0.1:6380> setbit k1 4 0
(integer) 0
127.0.0.1:6380> bitcount k1
(integer) 1
127.0.0.1:6380> setbit k1 4 1
(integer) 0
127.0.0.1:6380> bitcount k1
(integer) 2使用场景:
(1)统计年活跃用户数量
可以使用用户id作为offset,当用户在一年内访问过网站,就将对应的offset置为1,然后通过bitcount来统计i一年内访问过网站的用户数量
(2)统计三天内活跃用户数量
时间字符串作为key,例如"20200228:active",用户id可以作为offset,当用户访问过网站时,就将对应的偏移量的值置为1;
统计三天的活跃用户,通过 bittop or 获取三天内访问过的用户数
模拟场景,2021年1月21日,登陆用户3,5,7;2021年1月22日,登陆用户7,9,11;2021年1月21日,登陆用户5,6,7,8。
127.0.0.1:6380> setbit 20210121:active 3 1
(integer) 0
127.0.0.1:6380> setbit 20210121:active 5 1
(integer) 0
127.0.0.1:6380> setbit 20210121:active 7 1
(integer) 0
127.0.0.1:6380> setbit 20210122:active 7 1
(integer) 0
127.0.0.1:6380> setbit 20210122:active 9 1
(integer) 0
127.0.0.1:6380> setbit 20210122:active 11 1
(integer) 0
127.0.0.1:6380> setbit 20210123:active 5 1
(integer) 0
127.0.0.1:6380> setbit 20210123:active 6 1
(integer) 0
127.0.0.1:6380> setbit 20210123:active 7 1
(integer) 0
127.0.0.1:6380> setbit 20210123:active 8 1
(integer) 0统计:使用bitop命令,由于是需要统计三天内活跃的总用户,那么可以使用bitop and deskkey key[key ......],and就是取并集然后将新的值赋给deskkey,可以看到下面的命令示例,获取的统计结果为7。
127.0.0.1:6380> bitop or temp1 20210123:active 20210122:active 20210121:active
(integer) 2
127.0.0.1:6380> bitcount temp1
(integer) 7(3)连续三天访问的用户数量
连续三天访问,就需要用and处理。
127.0.0.1:6380> bitop and temp2 20210121:active 20210122:active 20210123:active
(integer) 2
127.0.0.1:6380> bitcount temp2
(integer) 1(4)取反处理,例如当天有多少人没有访问
使用 bitop not 命令,这里是将原有的为0的offset置为1,将1置为0,并将新的值放到新的bitmap中,这里需要特殊说明一下,bitmap的长度默认是8的倍数,因此当取反时后获取数量的话,获得的是大于原bitmap最大偏移量的最小的8的倍数减去原bitmap的数量。
例如:为一个bitmap的23位设置位1,那么此时的bitmap长度默认为24(大于23的最小8的倍数),那么取反时,除了23位取反变成0之外,其余的23位全部由0变为1,那么新的bitmap取长度就是23
127.0.0.1:6380> setbit bitmap1 22 1
(integer) 0
127.0.0.1:6380> bitop not newbitmap bitmap1
(integer) 3
127.0.0.1:6380> bitcount bitmap1
(integer) 1
127.0.0.1:6380> bitcount newbitmap
(integer) 23(5)统计在线人数
当用户登陆时,使用 setbit 设置值为1,退出时,使用 setbit 设置为0.
(二)HyperLogLog(2.8之后)
HyperLogLog是基于bitmap计数,并且基于概率基数,这个数据结构的命令有:pfadd、pfcount、pfmerge
可以使用pfadd向一个key中添加元素,使用pfcount获取元素个数(去重后),使用pfmerge合并两个key到一个
127.0.0.1:6380> pfadd key1 1 2 3 4 2 3 4 5 6 8 5 4 2
(integer) 1
127.0.0.1:6380> pfcount key1
(integer) 7
127.0.0.1:6380> pfadd key2 5 6 4 8 9 10 11 6
(integer) 1
127.0.0.1:6380> pfmerge key3 key1 key2
OK
127.0.0.1:6380> pfcount key3
(integer) 10主要用途:记录网站IP注册数,每日访问的IP数,页面实时UV,在线用户人数
如果基数不大,就不用使用HyperLogLog。和bitmap对比,bitmap可以标识哪些用户在活跃,而HyperLogLog可以统计活跃人数等同机型内容,两者可以结合使用。
(三)Geospatial(3.0之后)
geospatial可以用来保存地理位置,同时可以做距离计算等,geo本身不是一个数据结构,底层还是用zset来实现的。
127.0.0.1:6380> geoadd cities 116.404269 39.91582 beijing
(integer) 0
127.0.0.1:6380> geoadd cities 121.478799 31.235456 shanghai
(integer) 0
127.0.0.1:6380> geoadd cities 120.165036 30.278973 hangzhou
(integer) 1
127.0.0.1:6380> geodist cities beijing shanghai m
"1068567.6977"
127.0.0.1:6380> geodist cities beijing shanghai km
"1068.5677"
127.0.0.1:6380> zrange cities 0 -1
1) "hangzhou"
2) "shanghai"
3) "beijing"
127.0.0.1:6380> zrange cities 0 -1 withscores
1) "hangzhou"
2) "4054134264615180"
3) "shanghai"
4) "4054803475356102"
5) "beijing"
6) "4069885555377153"二、Redis消息模式
(一)队列模式
队列模式使用list类型的lpush和rpop实现消息队列;
发送者使用lpush命令向list中存数据,获取数据可以使用rpop命令获取数据
阿里云:0>lpush queue 1 2 3
3
阿里云:0>rpop queue
1
阿里云:0>rpop queue
2但是这样存在一个问题:如果list中没有数据的话,消息接收方会一直发送rpop命令,如果这样的话,每一次都会建立一个连接,这样显然不太好。
可以使用brpop,这样取不到数据的话,就会一直阻塞,在一定范围内没有取出则返回null
brpop list1 10其中key后面跟的是阻塞时间。可以忽略。
(二)发布订阅模式
首先,消费者需要订阅:subscribe channel
subscribe lcl-channel
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "lcl-channel"
3) (integer) 1然后消息生产者生产消息:publish channel message
publish lcl-channel "124"此时,消费者就会输出对应的消息
subscribe lcl-channel
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "lcl-channel"
3) (integer) 1
1) "message"
2) "lcl-channel"
3) "124"可以看到,无论订阅还是消费消息,都输出了三个结果,类型(订阅或消息)、通道、信息(订阅渠道的顺序或消费的消息)
三、Redis Stream
redis Stream官方定义:以更抽象的方式建模日志的数据结构。通俗地讲,Redis Stream就类似于Kafka和MQ。
Stream有消息、生产者、消费者和消费组四个部分组成。
(一)添加(XADD)、删除(XDEL)、获取长度(XLEN)
首先添加、删除和查看消息长度;添加时,stream名称后面可以跟*或者ID,如果使用*,则redis会根据内置的规则生成ID,同时一次可以设置多个field
127.0.0.1:6380> xadd orders * orderid 123 ordertype 3
"1611839914184-0"127.0.0.1:6380> xdel orders 1611839914184-0
(integer) 1
127.0.0.1:6380> xadd orders * orderid 123 ordertype 4
"1611840003654-0"
127.0.0.1:6380> xadd orders * orderid 123 ordertype 5
"1611840014821-0"
127.0.0.1:6380> xlen orders
(integer) 2(二)正序获取已有数据(XRANGE)、反序获取已有数据(XREVRANGE)
可以使用XRANGE获取已有的数据,XRANGE后面需要ID的范围,获取的数据则是两个ID之间的数据,同时也可以使用 - 和 + 来表示最小ID和最大ID;也可以带count参数,表示需要获取多少条数据
127.0.0.1:6380> xrange orders - +
1) 1) "1611840003654-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "4"
2) 1) "1611840014821-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "5"
3) 1) "1611840405335-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "6"
4) 1) "1611840408395-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "7"
5) 1) "1611840410425-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "8"
127.0.0.1:6380> xrange orders - + count 3
1) 1) "1611840003654-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "4"
2) 1) "1611840014821-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "5"
3) 1) "1611840405335-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "6"也可以逆向读取
127.0.0.1:6380> xrevrange orders + -
1) 1) "1611840410425-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "8"
2) 1) "1611840408395-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "7"
3) 1) "1611840405335-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "6"
4) 1) "1611840014821-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "5"
5) 1) "1611840003654-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "4"
127.0.0.1:6380> xrevrange orders + - count 3
1) 1) "1611840410425-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "8"
2) 1) "1611840408395-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "7"
3) 1) "1611840405335-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "6"(三)阻塞读取(XREAD)
命令:xread count num block time streams streaname id
阻塞获取指定stream名称中指定id的消息,如果超过设置时间,则停止阻塞。
以 xread count 2 block 50000 streams orders $ 为例,获取stream名称为orders的2条消息,阻塞时间为50秒,如果阻塞时间为0,则表示只要没有读取到数据,则永远阻塞。后面的$表示只获取最新的数据。
127.0.0.1:6380> xread count 2 block 50000 streams orders $
1) 1) "orders"
2) 1) 1) "1611840884859-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "9"
(5.17s)同时可以同时订阅多个stream流
xread count 2 block 50000 streams orders orders1 orders2 $(四)消费组:创建消费组(XGROUP)、消费组读取(XREADGROUP)
创建消费组:XGROUP [CREATE key groupname id-or-$][SETID key id-or-$] [DESTROY key groupname][DELCONSUMER key groupname consumername]
需要注意的是,目前XGROUP CREATE的streams必须是一个存在的streams,否则会报错:
127.0.0.1:6380> xgroup create orders111 g1 $
(error) ERR The XGROUP subcommand requires the key to exist. Note that for CREATE you may want to use the MKSTREAM option to create an empty stream automatically.
127.0.0.1:6380> xgroup create orders g1 $
OK根据消费组获取消息:
127.0.0.1:6380> xreadgroup group g2 qmm count 5 block 0 streams orders >
1) 1) "orders"
2) 1) 1) "1611842177694-0"
2) 1) "orderid"
2) "123"
3) "ordertype"
4) "15"
(4.77s)四、Redis Pipeline
Pipeline是客户端提供的一种批处理技术,可以批量执行一组命令,一次性返回结果,可以减少频繁的请求应答。
五、Redis事务
redis的事务是通过multi、exec、discard、watch、unwatch这五个命令来完成的。
redis的单个命令都是原子性的,所以这里需要确保事务性的对象是命令集合
redis将命令集合序列化并确保处于同一事务的命令集合连续且不被打断的执行。
redis不支持回滚操作。
| 命令 | 描述 | 语法 |
| multi | 用于标记事务的开始,redis会将后续的命令逐个放入队列中,然后使用exec命令原子化的执行这个命令序列 | |
| exec | 在一个事务中执行所有先前放入队列的命令,然后恢复正常的连接状态 | |
| discard | 清除所有先前在一个事务中放入队列的命令,然后恢复正常的连接状态 | |
| watch | 当某个事务需要按照条件执行时,就要使用这个命令将给定的键设置为受监控的状态 当监控一个key时,如果 | watch key |
| unwatch | 清除所有先前为一个事务监控的键 |