前言
由 Pytorch分布式训练(一)_chenxy02的博客-CSDN博客 可知Pytorch分布式训练实现进程间寻址,主要依靠以下 四个参数:
- MASTER_ADDR
- MASTER_PORT
- WORLD_SIZE
- RANK
MASTER_PORT和MASTER_ADDR的目的是告诉进程组中负责进程通信协调的核心进程的IP地址和端口。 RANK参数是该进程的id,WORLD_SIZE是说明进程组中进程的个数。
从上一篇博客我们可以想到 手工启动分布式训练 有以下缺点:
1、得手工在多个节点上启动多个 python脚本,配置不同的 rank等参数
2、如果是在K8S上起多个 pod 进行分布式训练 ,还得解决IP不确定的问题
3、难以满足用户想在特定情景下动态伸缩节点数的要求
带着这三个问题,我们来解析一下 PyTorchJob (training-operator实现的CRD之一) 的实现机制。
Training-operator 介绍
代码仓库:GitHub - kubeflow/training-operator: Training operators on Kubernetes.
如下,Training-operator 提供各位了 各种 K8S 的 custom resources。 使得在 K8S 上进行 TensorFlow/PyTorch/Apache MXNet/XGBoost/MPI/Paddle 框架的分布式训练变得容易。
Training-operator 安装
由 training-operator 在 v1.6 之后才支持 PaddlePaddle,这里我们安装 v1.6.0 版本。
# 在线安装
kubectl apply -k "github.com/kubeflow/training-operator/manifests/overlays/standalone?ref=v1.6.0"
# 离线安装则提前下好training-operator的项目代码,以及镜像 kubeflow/training-operator:v1-5a5f92d检查安装结果

PytorchJob 入门使用
apply 一个 kind 为 PyTorchJob 的 yaml ,如下:
kubectl apply -n kubeflow -f <<EOF
apiVersion: "kubeflow.org/v1"
kind: PyTorchJob
metadata:
name: pytorch-simple-001
namespace: kubeflow
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: pytorch
image: kubeflowkatib/pytorch-mnist:v1beta1-45c5727
imagePullPolicy: Always
command:
- "python3"
- "/opt/pytorch-mnist/mnist.py"
- "--epochs=1"
Worker:
replicas: 2
restartPolicy: OnFailure
template:
spec:
containers:
- name: pytorch
image: kubeflowkatib/pytorch-mnist:v1beta1-45c5727
imagePullPolicy: Always
command:
- "python3"
- "/opt/pytorch-mnist/mnist.py"
- "--epochs=1"
EOF正常情况下,我们会看到三个running的pod,如下:

训练完成后,Pod 的状态变成 Completed,如下:

PytorchJob 源码分析
关于 traning-operator 所使用的脚手架工具 kubebuilder 的代码结构可参见 Kubeflow--TFJob实现机制分析_chenxy02的博客-CSDN博客 , 这里我们直接看PyTorchJob的调谐方法 Reconcile()
代码地址:pkg/controller.v1/pytorch/pytorchjob_controller.go

其中,r.ReconcileHPA(pytorchjob) 会根据 pytorchjob.spec.elasticPolicy 字段,对训练任务进行动态扩缩容。利用此,也便可以解决 上述第三个问题——“在特定情景下动态伸缩节点数”。
接下来 我们进到 r.ReconcileJobs(pytorchJob, ……)方法,看一下 PyTorchJob 怎么解决上述前两个问题。在 ReconcileJobs() 方法中调用了 ReconcilePods()方法负责调谐出Pod,pod的数量由 pytorchjob.spec.pytorchReplicaSpecs 决定。
代码地址:github.com/kubeflow/common/pkg/controller.v1/common/pod.go

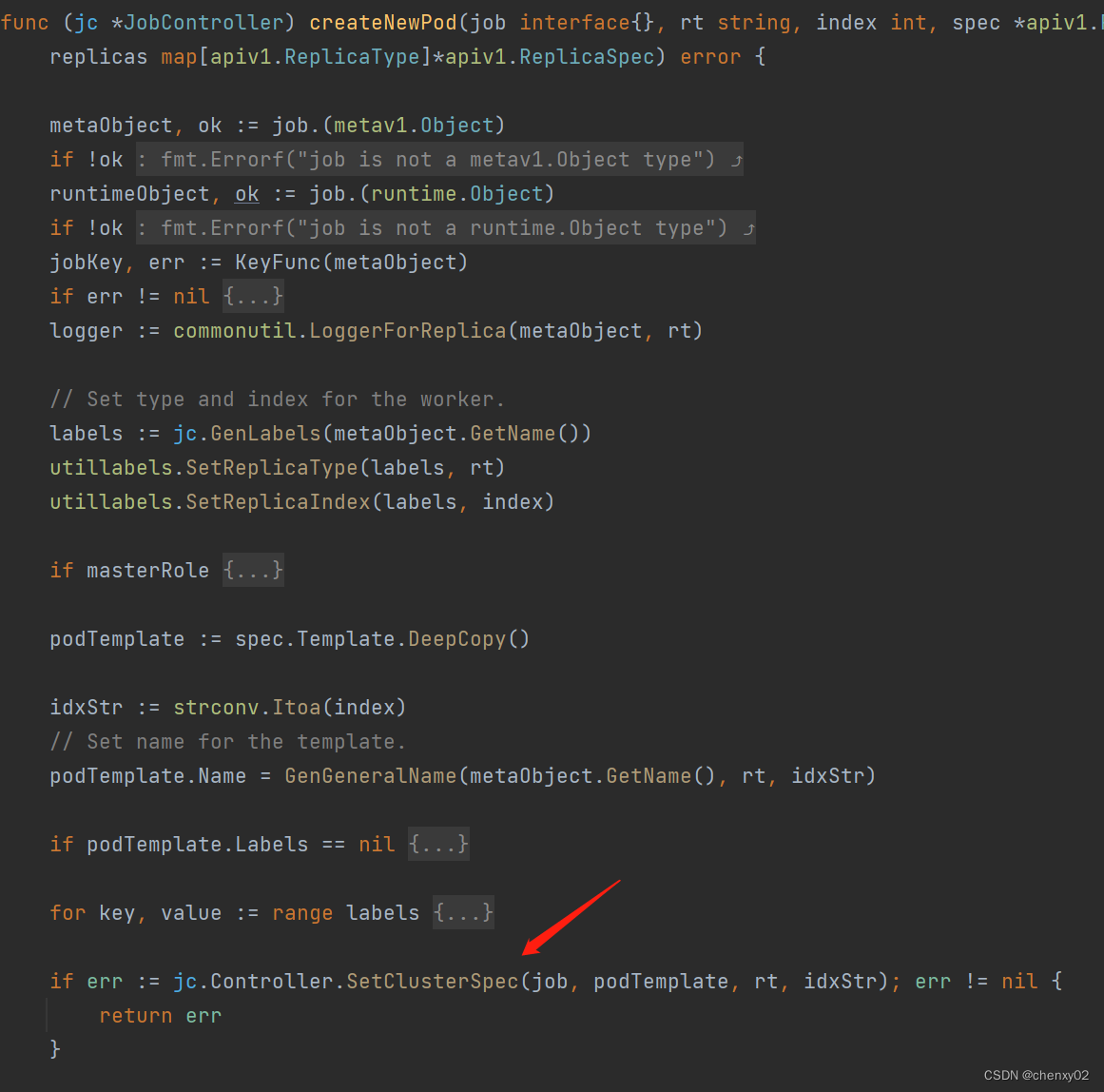
进入到 jc.createNewPod() 可以发现,training-operator是通过 jc.Controller.SetClusterSpec()方法,根据不同分布式训练框架的需要,为训练容器注入相应的配置。
代码地址:github.com/kubeflow/common/pkg/controller.v1/common/pod.go
代码地址:pkg/controller.v1/pytorch/pytorchjob_controller.go

进入在setPodEnv() 便可以看到 training-operator是怎么为pytorch分布式训练的容器注入所需的 MASTER_PORT、MASTER_ADDR、WORLD_SIZE、RANK 等环境变量。
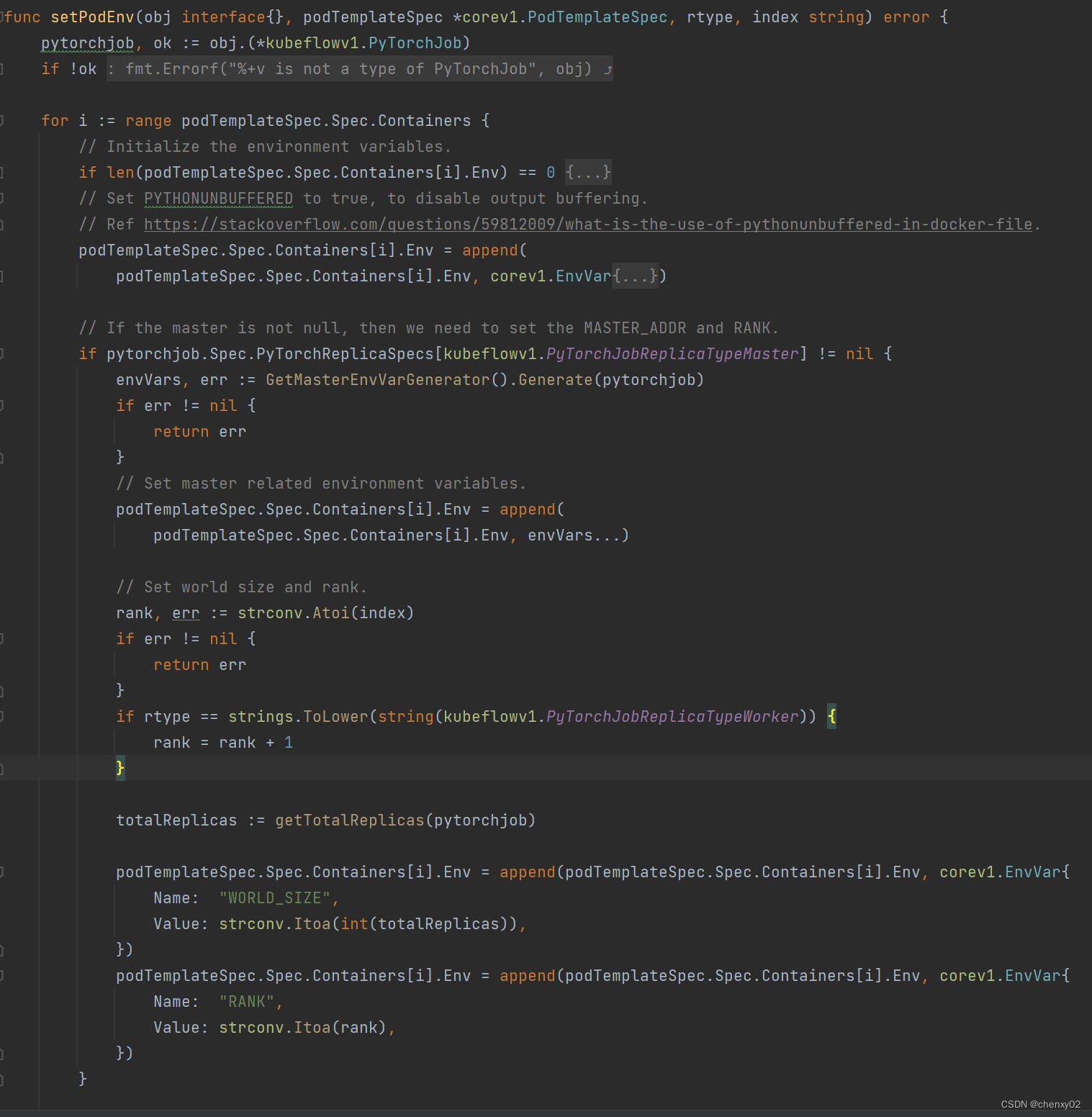
至此,便解决了上述第一个问题—— “启动多个 python脚本,配置不同的 rank值”
至于上述第二个问题——"多个 pod 进行分布式训练 ,IP不确定的问题"。则是通过为每一个训练节点创建一个Services,通过记录集群内域名来解决。详见:jc.Controller.ReconcileServices方法(代码地址:github.com/kubeflow/common/pkg/controller.v1/common/job.go)