文章目录
- 前言
- 一、数据的基本描述性分析
- 1.1 导包与读取数据
- 1.2 数据的基本情况
- 1.3 变量的分布情况
- 1.4 相关性分析
- 二、数据的预处理
- 2.1 Lasso变量选择模型
- 三、建立财政收入预测模型
- 3.1 灰色模型
- 3.2 神经网络预测模型
- 环境搭建
- Spark pandsAPI接口(了解)
- 分布式 + Spark进行数据处理
- 文件上传hdfs(分布存储)
- Spark数据处理
前言
1、对搜集的某市地方财政收入以及各类别收入数据,分析识别影响地方财政收入的关键属性
2、预测筛选出的关键影响因素的2014年、2015年的预测值。
3、评估模型的准确率。
参考资料:【数据挖掘案例】财政收入影响因素分析及预测模型
单机、小数据、pandas
一、数据的基本描述性分析
1.1 导包与读取数据
- 数据(data.xlsx)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import mpl
import openpyxl
# 正常显示中文标签
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示负号
mpl.rcParams['axes.unicode_minus'] = False
# 禁用科学计数法
pd.set_option('display.float_format', lambda x: '%.2f' % x)
# 读入数据
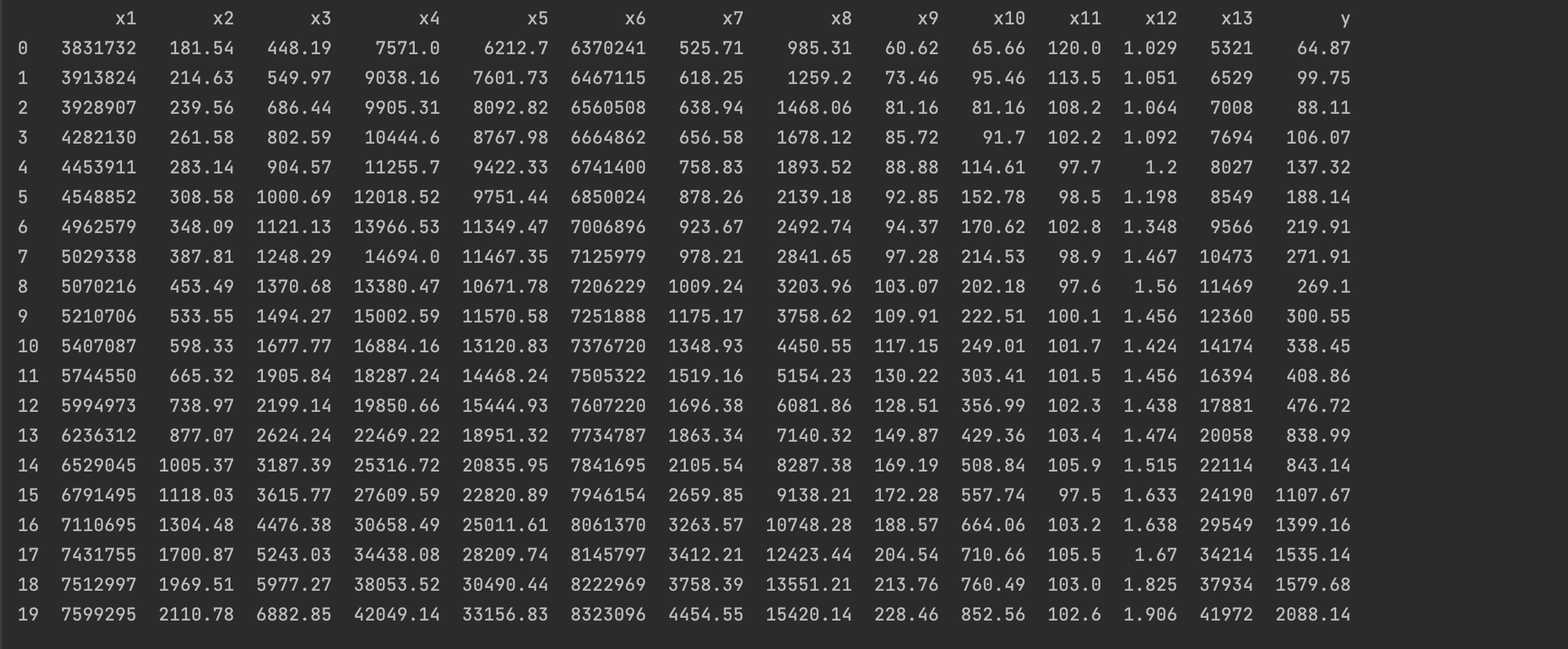
data = pd.read_excel('./input/data.xlsx')
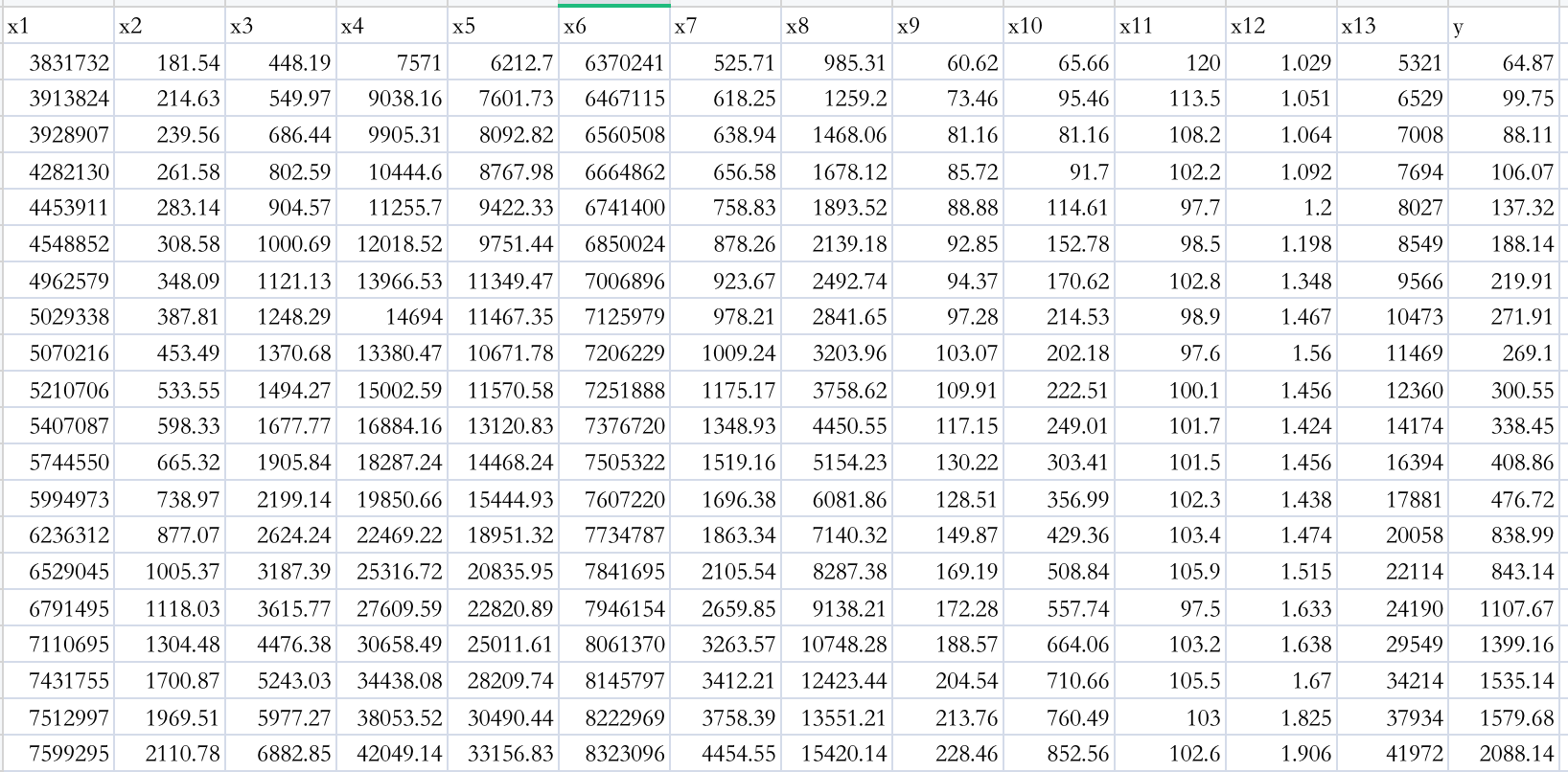
- 字段含义
- 社会从业人数(x1 )
- 在岗职工工资总额(x2)
- 社会消费品零售总额(x3)
- 城镇居民人均可支配收人(x4)
- 城镇居民人均消费性支出(x5)
- 年末总人口(x6)
- 全社会固定资产投资额(x7)
- 地区生产总值(x8)
- 第一产业产值(x9)
- 税收(x10)
- 居民消费价格指数(x11)
- 第三产业与第二产业产值比(x12)
- 地区生产总值(x8)和居民消费水平(x13)
1.2 数据的基本情况
data.shape # (20, 14)
data.info()
# 描述性分析
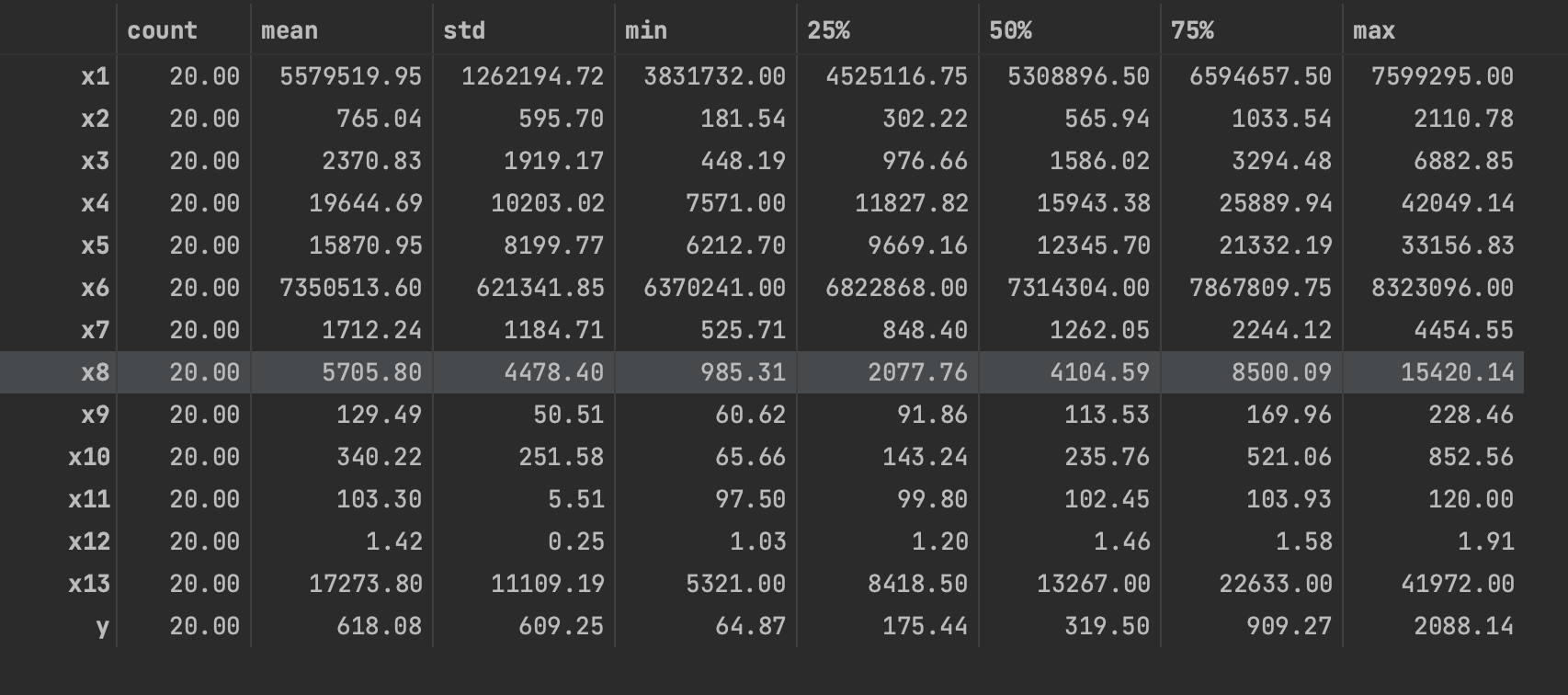
data.describe().T
# 描述性分析
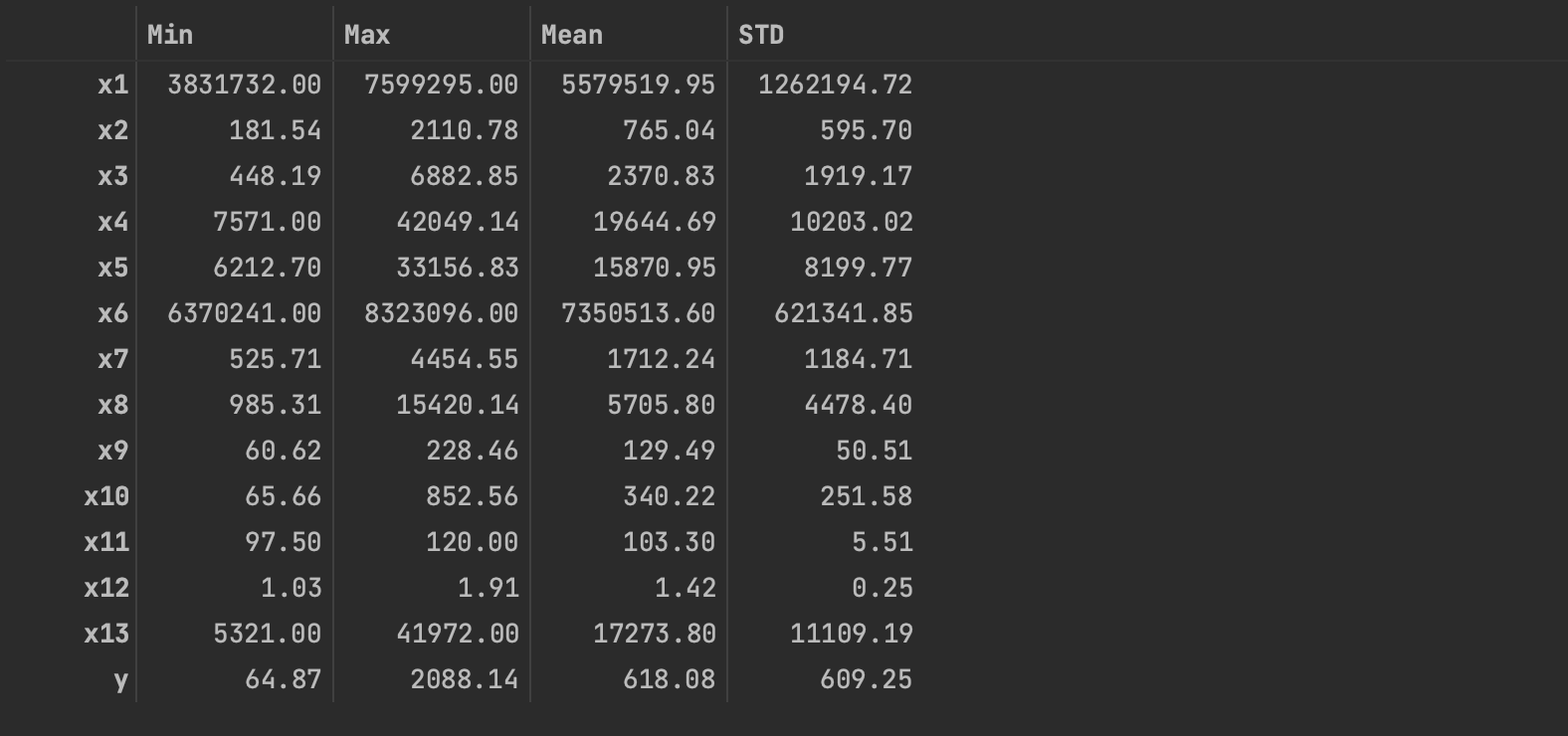
r = [data.min(), data.max(), data.mean(), data.std()]
r = pd.DataFrame(r, index=['Min', 'Max', 'Mean', 'STD']).T
r = np.round(r, 2)
r
1.3 变量的分布情况
from sklearn.preprocessing import MinMaxScaler
#实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
data_scale = pd.DataFrame(scaler.transform(data)) #通过接口导出结果
data_scale.columns = data.columns
import joypy
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import cm
import seaborn as sns
fig, axes = joypy.joyplot(data_scale, alpha=.5, color='#FFCC99')#连续值的列为一个"脊"
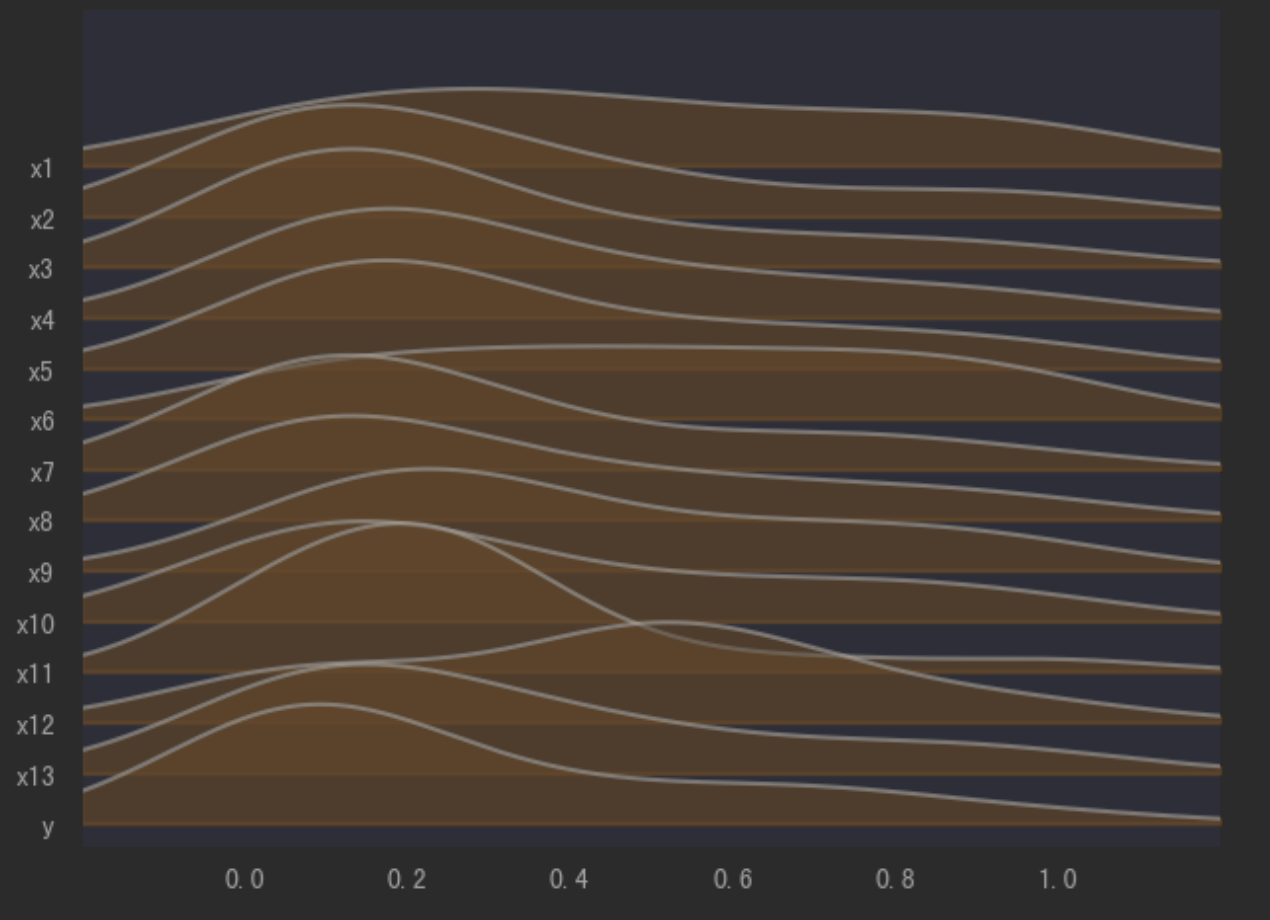
data_scale.plot()
1.4 相关性分析
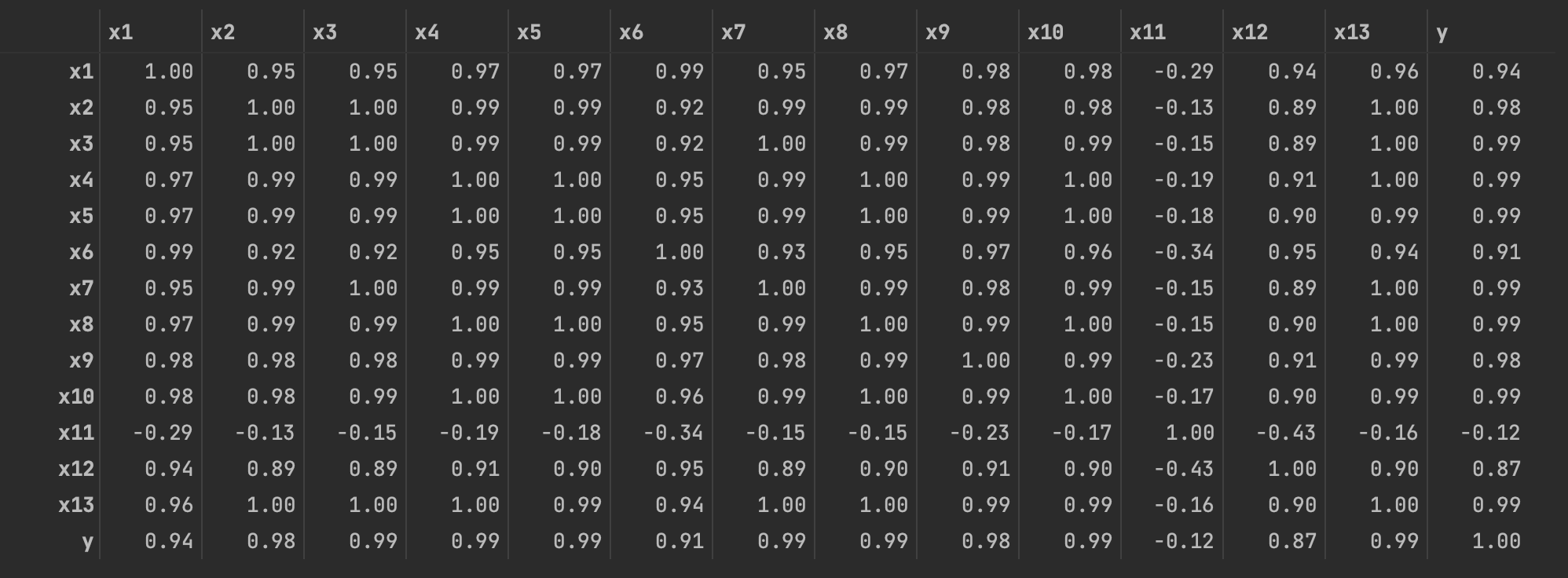
pear = np.round(data.corr(method = 'pearson'), 2)
pear
plt.figure(figsize=(12,12))
sns.heatmap(data.corr(), center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5},annot=True, fmt='.1f')
#设置x轴
plt.xticks(fontsize=15)
#设置y轴
plt.yticks(fontsize=15)
plt.tight_layout()
plt.savefig('a.png')
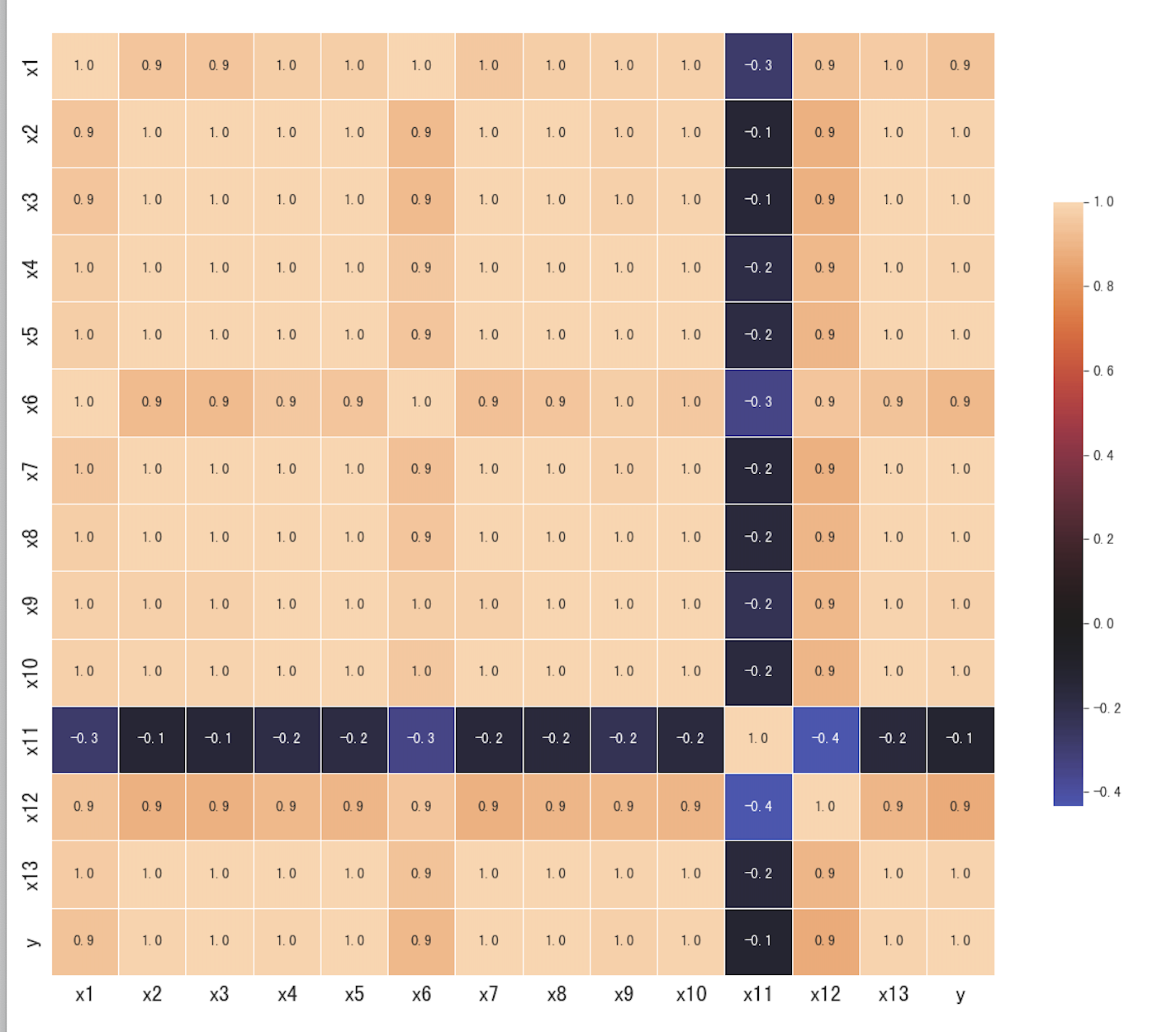
- 由图可知,居民消费价格指数(x11)与财政收入的线性关系不显著,而且呈现负相关。其余变量均与财政收入呈现高度的正相关关系。
二、数据的预处理
- 变量的筛选(分析方法的选择):
- 以往对财政收入的分析会使用 多元线性回归模型和最小二乘估计方法来估计回归模型的系数通过系数能否通过检验来检验它们之间的关系,但这样的结果对数据依赖程度很大,并且求得的往往只是局部最优解,后续的检验可能会失去应有的意义。
- 因此本案例运用Adaptive-Lasso变量选择方法来研究,对于Lasso,这里参考书中的理论知识
2.1 Lasso变量选择模型
- 这里没有找到AdaptiveLasso这个函数,用Lasso代替
from sklearn.linear_model import Lasso
model = Lasso(alpha=0.1, max_iter=100000)
model.fit(data.iloc[:, 0:13], data['y'])
q=model.coef_#各特征的系数
q=pd.DataFrame(q,index=data.columns[:-1])
q
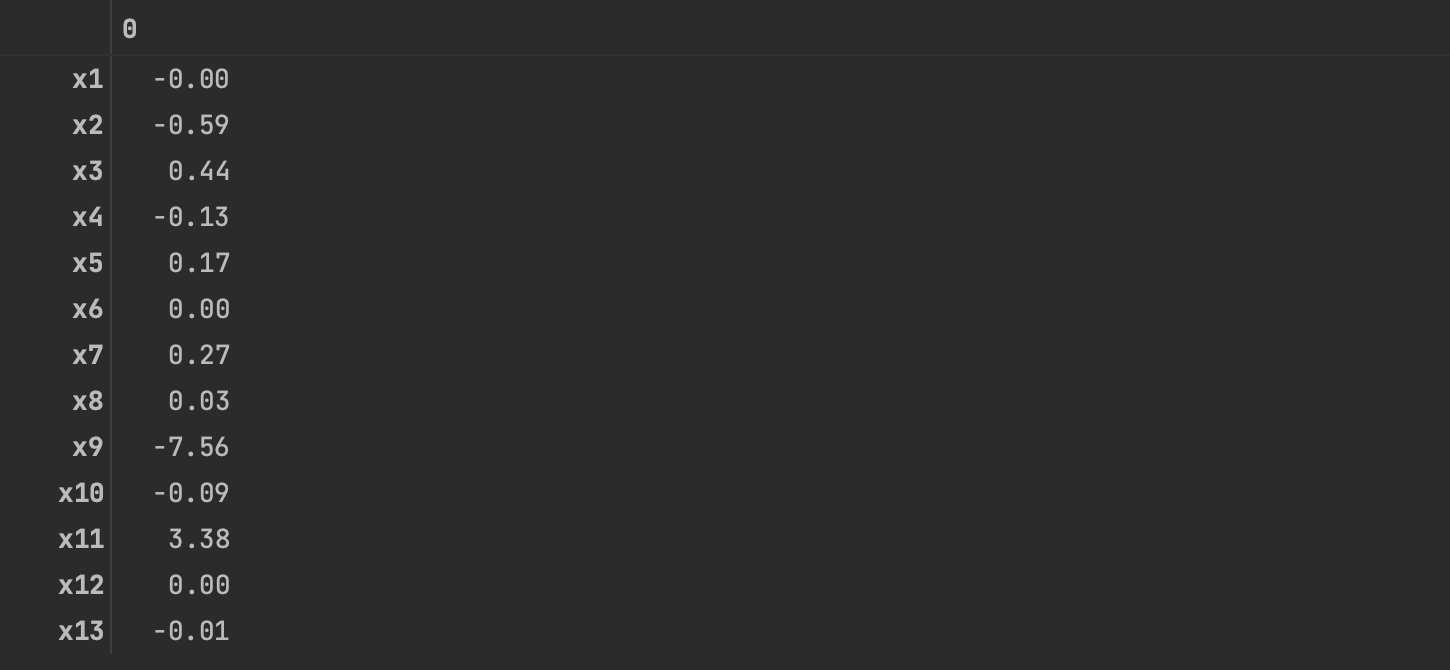
- 计算出某变量的特征值非零,则表示该变量对预测变量存在较大影响,而如果某变量的特征值为零,则表示该变量对预测变量影响很小。
- 调整参数值(参照:https://blog.csdn.net/weixin_43746433/article/details/100047231)
from sklearn.linear_model import Lasso
lasso = Lasso(1000) #调用Lasso()函数,设置λ的值为1000
lasso.fit(data.iloc[:,0:13],data['y'])
print('相关系数为:',np.round(lasso.coef_,5)) #输出结果,保留五位小数
## 计算相关系数非零的个数
print('相关系数非零个数为:',np.sum(lasso.coef_ != 0))
mask = lasso.coef_ != 0 #返回一个相关系数是否为零的布尔数组
print('相关系数是否为零:',mask)
new_reg_data = data.iloc[:,:13].iloc[:,mask] #返回相关系数非零的数据
new_reg_data = pd.concat([new_reg_data,data.y],axis=1)
new_reg_data.to_excel('new_reg_data.xlsx')

- 根据非零的系数,最终通过Lasso筛选出的变量如下
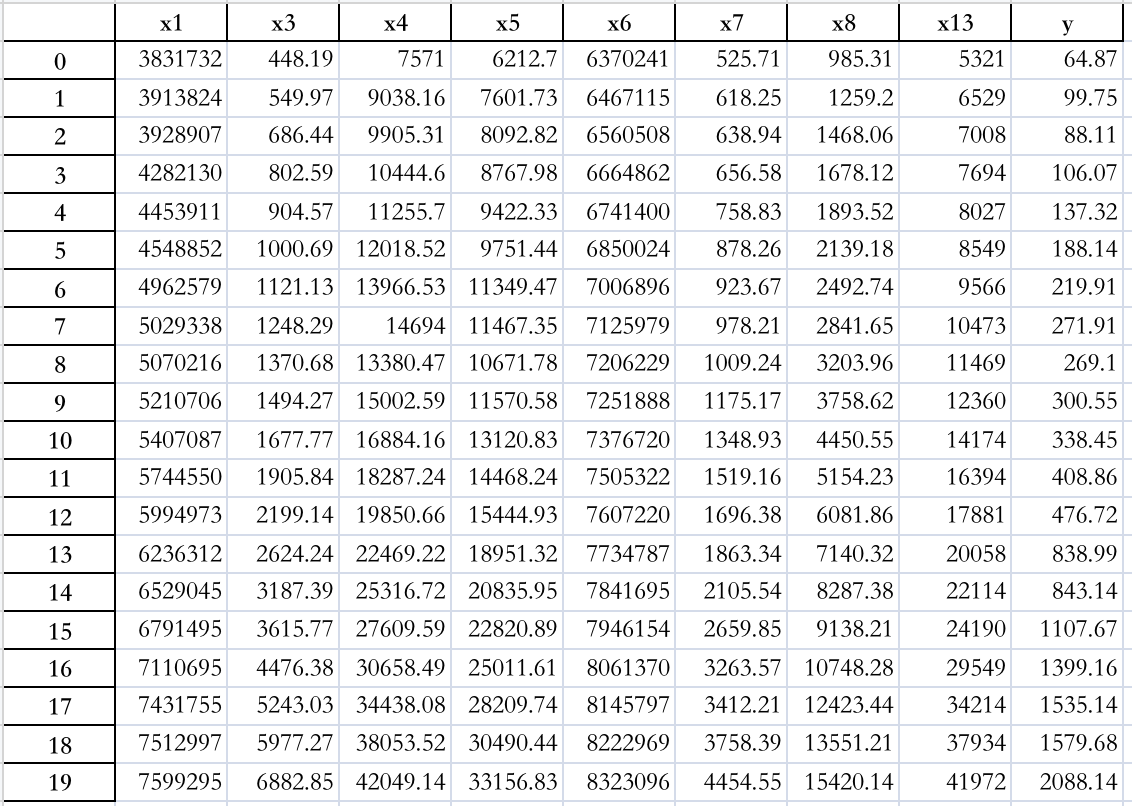
- 变量筛选好之后,接下来的开始建模
三、建立财政收入预测模型

3.1 灰色模型
- 灰色模型学习:https://blog.csdn.net/qq_42374697/article/details/106611556
def GM11(x0): #自定义灰色预测函数
import numpy as np
x1 = x0.cumsum() # 生成累加序列
z1 = (x1[:len(x1)-1] + x1[1:])/2.0 # 生成紧邻均值(MEAN)序列,比直接使用累加序列好,共 n-1 个值
z1 = z1.reshape((len(z1),1))
B = np.append(-z1, np.ones_like(z1), axis = 1) # 生成 B 矩阵
Y = x0[1:].reshape((len(x0)-1, 1)) # Y 矩阵
[[a],[u]] = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Y) #计算参数
f = lambda k: (x0[0]-u/a)*np.exp(-a*(k-1))-(x0[0]-u/a)*np.exp(-a*(k-2)) #还原值
delta = np.abs(x0 - np.array([f(i) for i in range(1,len(x0)+1)])) # 计算残差
C = delta.std()/x0.std()
P = 1.0*(np.abs(delta - delta.mean()) < 0.6745*x0.std()).sum()/len(x0)
return f, a, u, x0[0], C, P #返回灰色预测函数、a、b、首项、方差比、小残差概率
data.index = range(1994, 2014)
data.loc[2014] = None
data.loc[2015] = None
# 模型精度评价
# 被lasso筛选出来的6个变量
l = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13']
for i in l:
GM = GM11(data[i][list(range(1994, 2014))].values)
f = GM[0]
c = GM[-2]
p = GM[-1]
data[i][2014] = f(len(data)-1)
data[i][2015] = f(len(data))
data[i] = data[i].round(2)
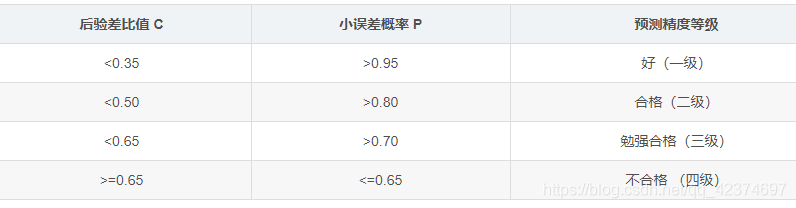
if (c < 0.35) & (p > 0.95):
print('对于模型{},该模型精度为---好'.format(i))
elif (c < 0.5) & (p > 0.8):
print('对于模型{},该模型精度为---合格'.format(i))
elif (c < 0.65) & (p > 0.7):
print('对于模型{},该模型精度为---勉强合格'.format(i))
else:
print('对于模型{},该模型精度为---不合格'.format(i))
data[l+['y']].to_excel('data2.xlsx')
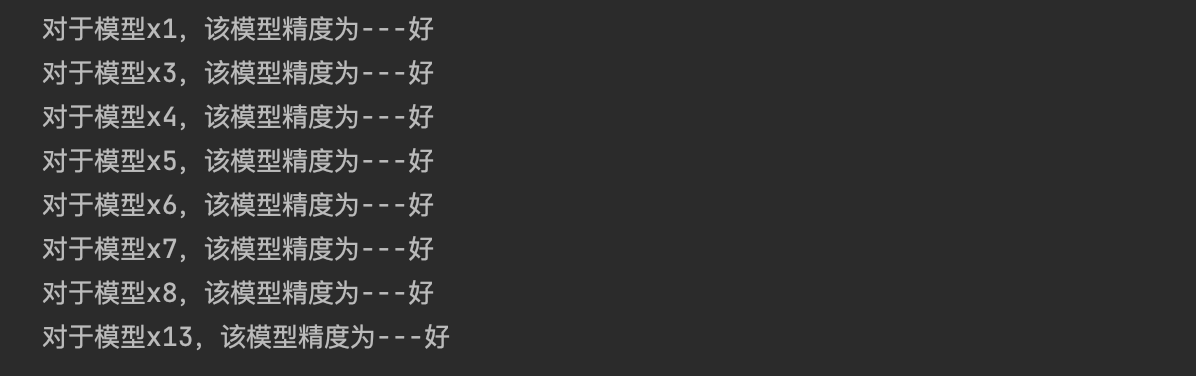
- 预测值如下:
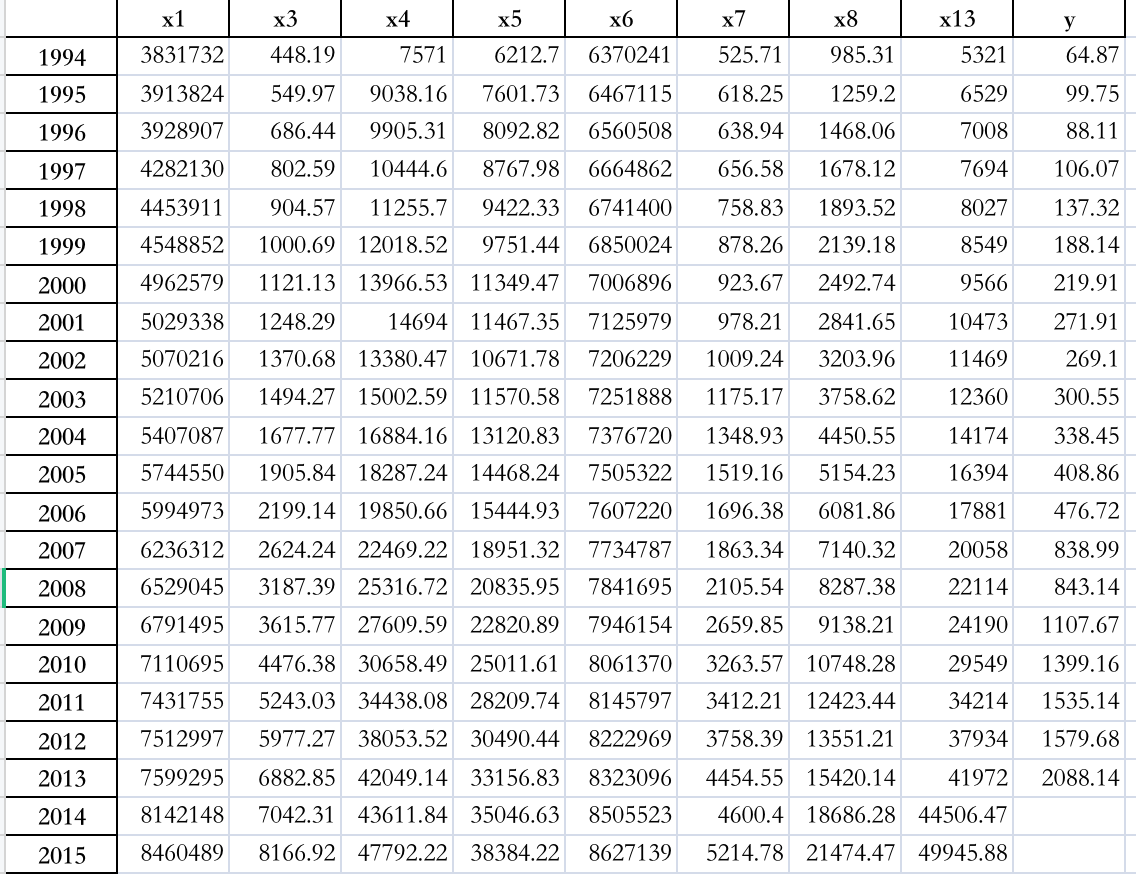
3.2 神经网络预测模型
- 下面用历史数据建立神经网络模型
- 其参数设置为误差精度107,学习次数10000次,神经元个数为Lasso变量选择方法选择的变量个数8。
'''神经网络'''
data2 = pd.read_excel('data2.xlsx', index_col=0)
# 提取数据
feature = list(data2.columns[:len(data2.columns)-1]) # ['x1', 'x2', 'x3', 'x4', 'x5', 'x7']
train = data2.loc[list(range(1994, 2014))].copy()
mean = train.mean()
std = train.std()
train = (train - mean) / std # 数据标准化,这里使用标准差标准化
x_train = train[feature].values
y_train = train['y'].values
# 建立神经网络模型
from keras.models import Sequential
from keras.layers import Dense, Activation
import tensorflow
model = Sequential()
model.add(Dense(input_dim=8, units=12))
model.add(Activation('relu'))
model.add(Dense(input_dim=12, units=1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(x_train, y_train, epochs=10000, batch_size=16)
model.save_weights('net.model')
- 训练好模型后,将1994 − 2005带入模型中做预测
# 将整个变量矩阵标准化
x = ((data2[feature] - mean[feature]) / std[feature]).values
# 预测,并还原结果
data2['y_pred'] = model.predict(x) * std['y'] + mean['y']
data2.to_excel('data3.xlsx')
- 预测结果
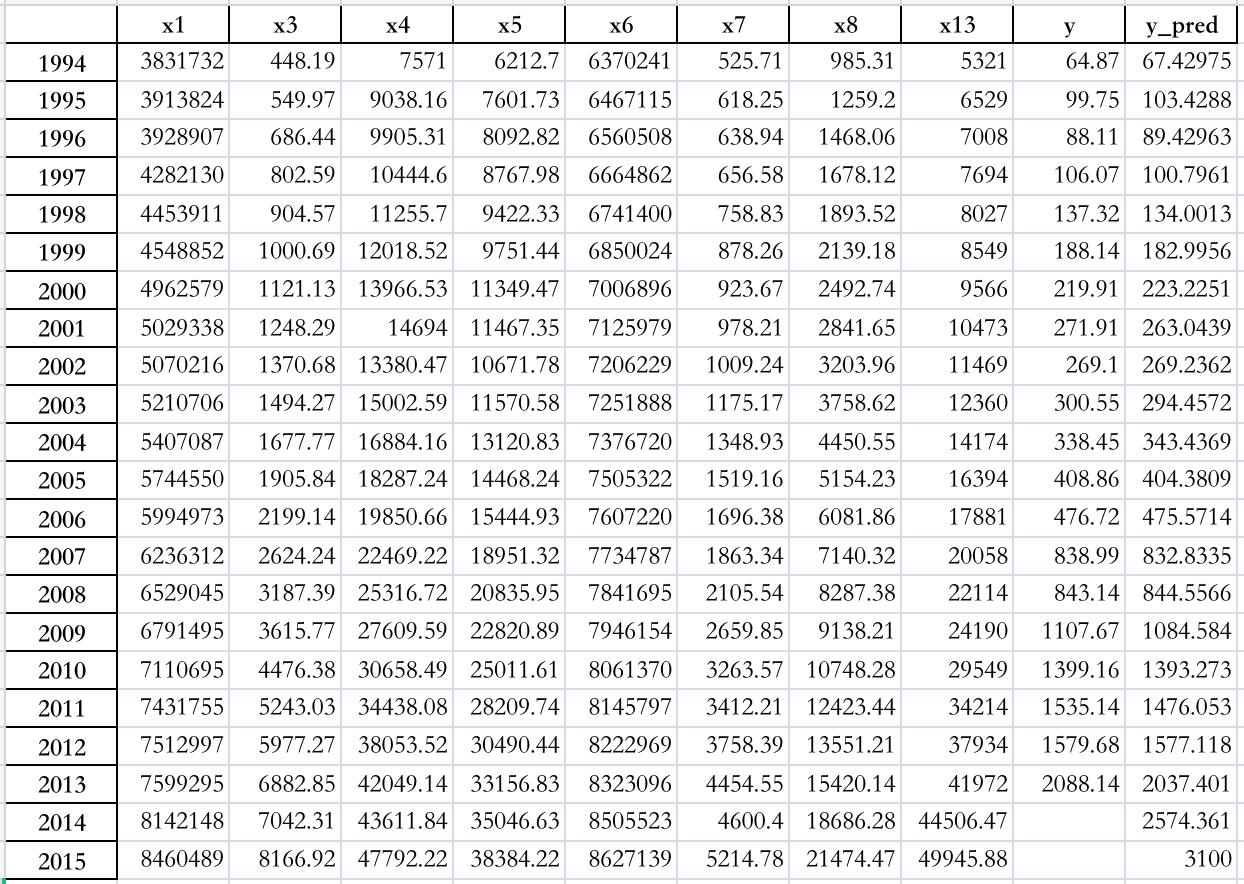
- 绘制真实值与预测值之间的折线图
import matplotlib.pyplot as plt
p = data2[['y', 'y_pred']].plot(style=['b-o', 'r-*'])
p.set_ylim(0, 2500)
p.set_xlim(1993, 2016)
plt.show()
plt.savefig('plot.png') # 保存图像为 plot.png
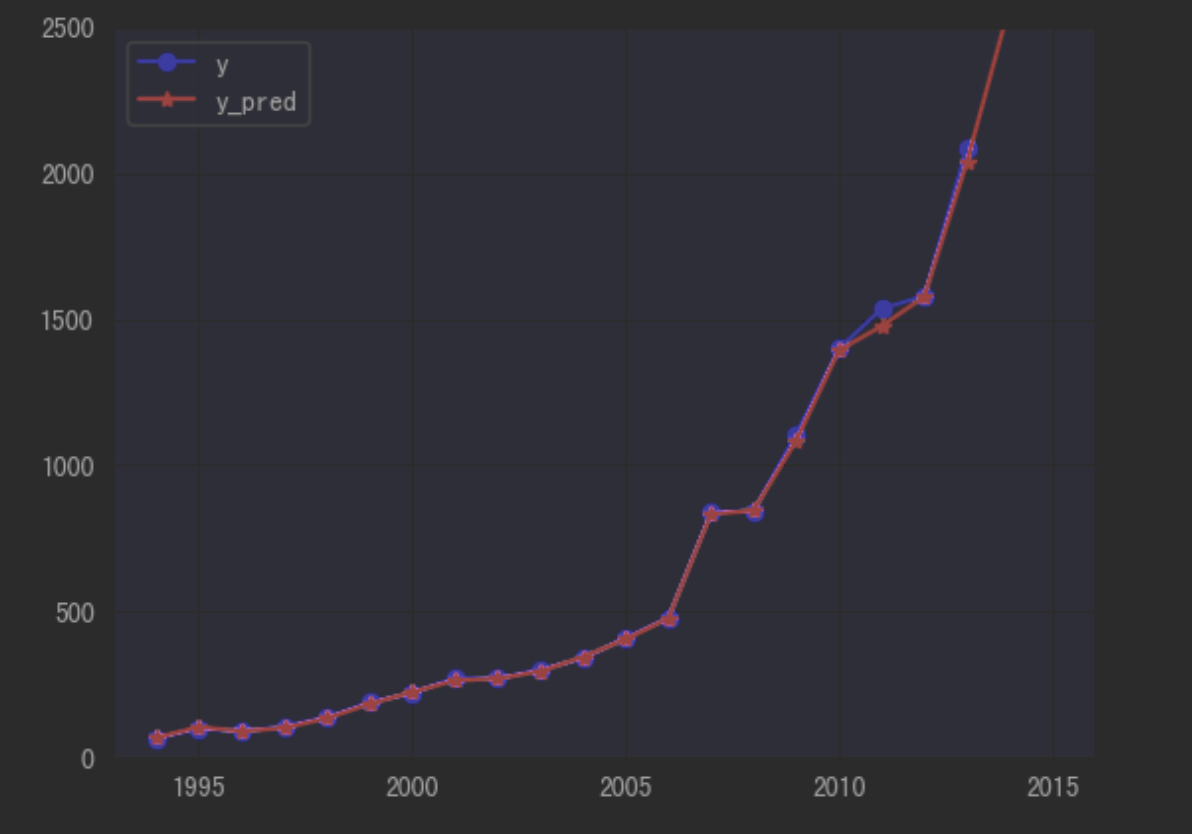
- 从结果中,比较预测值与真实值基本高度吻合
- 为了与神经网络预测结果有一个对比,下面使用其他预测模型查看其结果如何
from sklearn.linear_model import LinearRegression # 线性回归
from sklearn.neighbors import KNeighborsRegressor # K近邻回归
from sklearn.neural_network import MLPRegressor # 神经网络回归
from sklearn.tree import DecisionTreeRegressor # 决策树回归
from sklearn.tree import ExtraTreeRegressor # 极端随机森林回归
from xgboost import XGBRegressor # XGBoot
from sklearn.ensemble import RandomForestRegressor # 随机森林回归
from sklearn.ensemble import AdaBoostRegressor # Adaboost 集成学习
from sklearn.ensemble import GradientBoostingRegressor # 集成学习梯度提升决策树
from sklearn.ensemble import BaggingRegressor # bagging回归
from sklearn.linear_model import ElasticNet
from sklearn.metrics import explained_variance_score,\
mean_absolute_error,mean_squared_error,\
median_absolute_error,r2_score
models=[LinearRegression(),KNeighborsRegressor(),MLPRegressor(alpha=20),DecisionTreeRegressor(),ExtraTreeRegressor(),XGBRegressor(),RandomForestRegressor(),AdaBoostRegressor(),GradientBoostingRegressor(),BaggingRegressor(),ElasticNet()]
models_str=['LinearRegression','KNNRegressor','MLPRegressor','DecisionTree','ExtraTree','XGBoost','RandomForest','AdaBoost','GradientBoost','Bagging','ElasticNet']
data2 = pd.read_excel('data2.xlsx', index_col=0)
# 提取数据
feature = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13']
train = data2.loc[list(range(1994, 2014))].copy()
mean = train.mean()
std = train.std()
train = (train - mean) / std # 数据标准化,这里使用标准差标准化
x_train = train[feature].values
y_train = train['y'].values
# 将整个变量矩阵标准化
x = ((data2[feature] - mean[feature]) / std[feature]).values
for name,model in zip(models_str,models):
print('开始训练模型:'+name)
model=model #建立模型
a = 'y_pred_'+ name
data2[a] = model.fit(x_train,y_train).predict(x) * std['y'] + mean['y']
df=data2[:-2]
print('平均绝对误差为:',mean_absolute_error(df['y'].values,df[a].values))
print('均方误差为:',mean_squared_error(df['y'],df[a]))
print('中值绝对误差为:',median_absolute_error(df['y'],df[a]))
print('可解释方差值为:',explained_variance_score(df['y'],df[a]))
print('R方值为:',r2_score(df['y'],df[a]))
print('*-*'*15)

环境搭建
- 安装成功后弹出镜像(否则无法正常安装)
# 设置中文字体
plt.rcParams['font.sans-serif'] = 'SimHei'
Spark pandsAPI接口(了解)
- 使用Spark提供的pandsAPI接口进行数据处理
- 处理操作同pands,略有不同
- 适合处理大型数据(≥1M)
十分钟了解 Spark 上的 Pandas API(一)
注意,读取含有字符串的Excel文件时,需要指定Spark DataFrame的模式(schema),以确保每列的类型正确
无法关闭科学计数法
from pyspark.sql import SparkSession
import pyspark.pandas as ps
# 创建SparkSession
spark = SparkSession.builder.getOrCreate()
# 使用pandas读取Excel文件
pandas_df = ps.read_excel('./input/data.xlsx')
pandas_df = pandas_df.astype(str)
print(pandas_df)
官方资料:Spark上的Pandas APD
分布式 + Spark进行数据处理
文件上传hdfs(分布存储)
Spark数据处理