这里写目录标题
- 什么是Selenium?
- Selenium基础用法详解
- 环境搭建
- 编写第一个Selenium脚本
- 解析脚本
- 脚本执行结果
- 常用的元素定位方法
- 常用的WebDriver方法
- 等待机制
- Selenium高级技巧详解
- 页面元素操作
- 处理弹窗和警告框
- 截图和日志记录
- 多窗口和多标签页操作
- 一个实战的小demo
- 步骤一:py文件代码
- 步骤二:excel文件
- 总结
- 相关文章
什么是Selenium?
Selenium是一套用于Web应用程序自动化测试的开源工具。它支持多种浏览器(如Chrome、Firefox、Safari等)和多种编程语言(如Java、Python、C#等),使测试人员可以编写脚本来自动化执行测试用例,提升测试效率。

Selenium基础用法详解
环境搭建
在开始编写Selenium脚本之前,我们需要搭建开发环境。
-
安装Python:从Python官网下载并安装最新版本的Python。
-
安装Selenium库:
pip install selenium -
确认你的Chrome浏览器版本。你可以在Chrome浏览器中打开 chrome://settings/help 查看版本号。

-
下载浏览器驱动:
ChromeDriver官网下载地址
ChromeDriver官网最新版下载地址
ChromeDriver国内镜像下载地址
ChromeDriver国内镜像最新版下载地址
windows/mac用户需要将下载的驱动程序路径,添加到系统的环境变量中,方便Selenium识别和调用。
确认环境变量命令:chromedriver

编写第一个Selenium脚本
让我们通过一个简单的示例,了解如何使用Selenium进行网页自动化操作(代码示例,可以直接运行)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
try:
# 打开百度首页
driver.get("https://www.baidu.com")
# 确保页面加载完成
time.sleep(2)
# 找到搜索框
search_box = driver.find_element(By.NAME, "wd")
# 输入搜索关键词
search_box.send_keys("Selenium Python")
# 提交搜索
search_box.send_keys(Keys.RETURN)
# 等待页面加载
time.sleep(2)
# 获取搜索结果的标题
results = driver.find_elements(By.CSS_SELECTOR, 'h3')
print("搜索结果标题:")
for index, result in enumerate(results):
print(f"结果 {index + 1}: {result.text}")
# 点击第一个搜索结果(如果存在)
if results:
results[0].click()
time.sleep(10) # 等待页面加载
# 打印当前页面的标题
print("当前页面标题:", driver.title)
time.sleep(10)
finally:
# 关闭浏览器
driver.quit()
解析脚本
-
初始化WebDriver:创建一个Chrome浏览器实例,通过
webdriver.Chrome()来指定使用的浏览器驱动。 -
打开网站:使用
get方法访问xx的首页(https://www.baidu.com) -
定位搜索框:通过
find_element(By.NAME, "wd")方法找到搜索框元素 -
输入搜索关键词:使用
send_keys方法将"Selenium Python"输入到搜索框中,在使用send_keys(Keys.RETURN)模拟按下回车键提交搜索。 -
获取搜索结果标题:通过
find_elements(By.CSS_SELECTOR, 'h3')方法获取所有搜索结果的标题,使用CSS选择器定位到h3标签。 -
打印搜索结果标题:遍历搜索结果,使用
enumerate函数为每个结果编号,并打印出每个结果的标题。 -
点击第一个搜索结果:检查是否有搜索结果,如果存在,就使用
results[0].click()点击第一个结果 -
打印当前页面标题:在新页面加载完成后,使用
driver.title获取并打印当前页面的标题。 -
关闭浏览器:使用
driver.quit()确保无论程序是否发生异常,都会关闭浏览器实例,释放资源。
这就是我们简单的自动化demo,通常可以用在输入框较多需要构造大批量数据,或者自动化回归测试的时候使用
脚本执行结果
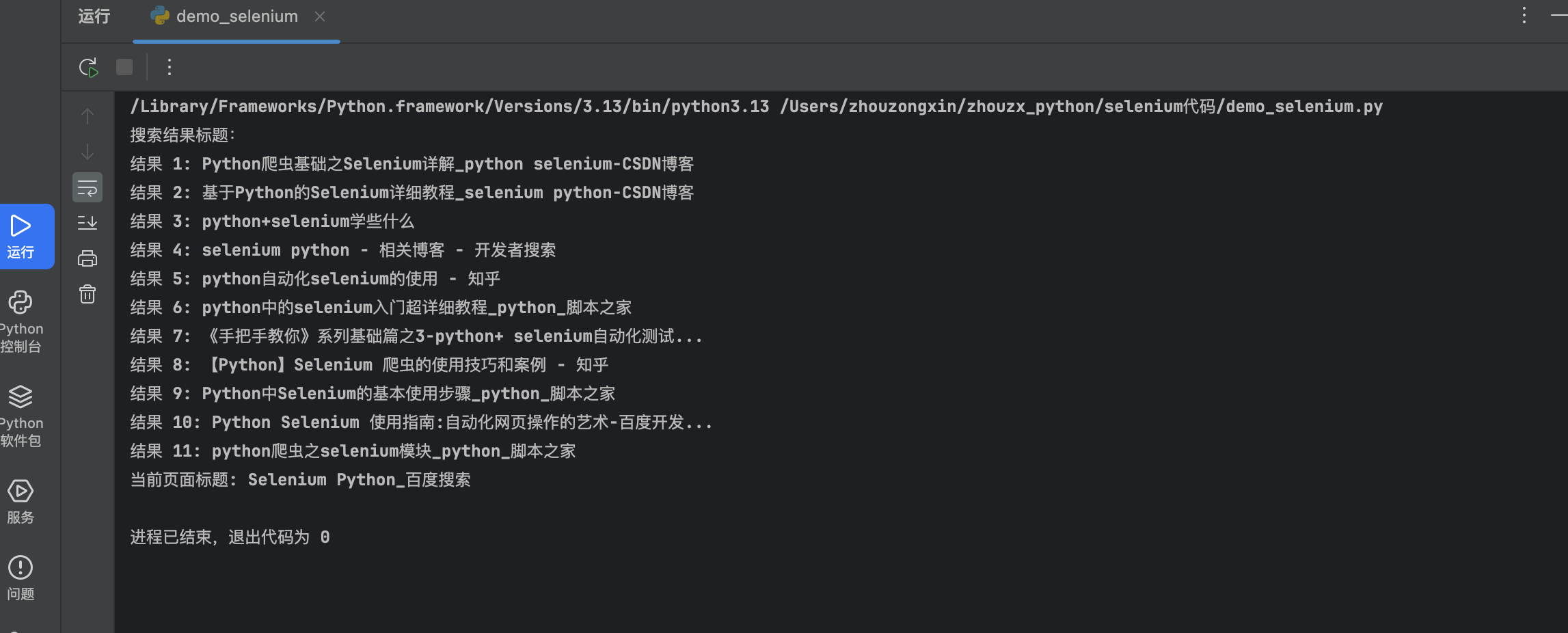
常用的元素定位方法
Selenium提供了多种方法来定位网页元素,选择合适的方法可以提高脚本的稳定性和可维护性。以下是几种常用的定位方式:
- By.ID:通过元素的ID属性定位。
driver.find_element(By.ID, "element_id") - By.NAME:通过元素的名称属性定位。
driver.find_element(By.NAME, "element_name") - By.XPATH:通过XPath表达式定位,适用于复杂的层级结构。
driver.find_element(By.XPATH, "//div[@class='example']") - By.CSS_SELECTOR:通过CSS选择器定位,语法简洁。
driver.find_element(By.CSS_SELECTOR, ".class > #id") - By.CLASS_NAME:通过元素的类名定位。
driver.find_element(By.CLASS_NAME, "class_name") - By.TAG_NAME:通过元素的标签名定位。
driver.find_element(By.TAG_NAME, "button") - By.LINK_TEXT 和 By.PARTIAL_LINK_TEXT:通过链接文本定位。
driver.find_element(By.LINK_TEXT, "点击这里") driver.find_element(By.PARTIAL_LINK_TEXT, "点击")
注意:在正常的情况下,我们通常只会用到id、name和Xpath,但一定要注意获取的元素要是唯一的。
常用的WebDriver方法
掌握一些常用的WebDriver方法,可以大大提升编写脚本的效率和灵活性。
注意:driver是我们之前定义浏览器实例的实例,如下:
driver = webdriver.Chrome()
因为这个driver实例,所以才能调用下面的方法
- driver.get(url):打开指定URL。
- driver.find_element(by, value):定位单个元素。
- driver.find_elements(by, value):定位多个元素。
- driver.send_keys(keys):向元素输入文本。
- driver.click():点击元素。
- driver.get_title():获取当前页面的标题。
- driver.get_current_url():获取当前页面的URL。
- driver.back():浏览器后退。
- driver.forward():浏览器前进。
- driver.refresh():刷新页面。
- driver.quit():关闭浏览器。
等待机制
在自动化测试中,页面加载速度不一,合理的等待机制可以提高脚本的稳定性。
-
隐式等待:
driver.implicitly_wait(10) # 最多等待10秒在查找元素时,如果元素未立即出现,WebDriver会等待指定的时间。
-
显式等待:
from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC wait = WebDriverWait(driver, 10) element = wait.until(EC.presence_of_element_located((By.ID, "element_id")))根据特定条件等待元素出现,更加灵活和精准。
-
线程等待:
import time time.sleep(5) # 强制等待5秒不推荐使用,容易导致测试效率低下。
Selenium高级技巧详解
页面元素操作
除了基本的点击和输入,Selenium还支持更多复杂的操作,如下拉菜单选择、拖拽、鼠标悬停等。
-
选择下拉菜单中的选项:
from selenium.webdriver.support.ui import Select select_element = Select(driver.find_element(By.ID, "dropdown")) select_element.select_by_visible_text("选项1") # 也可以通过值或索引选择 # select_element.select_by_value("value1") # select_element.select_by_index(1) -
鼠标悬停:
from selenium.webdriver.common.action_chains import ActionChains element = driver.find_element(By.ID, "hover_element") ActionChains(driver).move_to_element(element).perform() -
拖拽操作:
source = driver.find_element(By.ID, "source") target = driver.find_element(By.ID, "target") ActionChains(driver).drag_and_drop(source, target).perform()
处理弹窗和警告框
Web应用中常常会出现各种弹窗和警告框,Selenium提供了简单的方法来处理它们。
# 切换到警告框
alert = driver.switch_to.alert
# 获取警告框文本
alert_text = alert.text
print(alert_text)
# 接受警告框
alert.accept()
# 取消警告框
alert.dismiss()
# 输入文本到警告框(如果有输入框)
alert.send_keys("测试")
截图和日志记录
为了更好地调试和记录测试过程,Selenium支持截图和日志记录功能。
-
截图:
driver.save_screenshot("screenshot.png") -
获取页面源代码:
page_source = driver.page_source -
日志记录:
import logging logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("这是一个日志信息")
多窗口和多标签页操作
在现代Web应用中,可能会涉及到多个窗口或标签页的切换,Selenium同样能够轻松应对。
# 获取当前窗口句柄
main_window = driver.current_window_handle
# 打开新窗口或标签页
driver.execute_script("window.open('https://www.example.com')")
# 获取所有窗口句柄
windows = driver.window_handles
# 切换到新窗口
for window in windows:
if window != main_window:
driver.switch_to.window(window)
break
# 在新窗口中执行操作
driver.find_element(By.ID, "new_window_element").click()
# 切换回主窗口
driver.switch_to.window(main_window)
一个实战的小demo
这是一个通过读取excel文件获取数据,然后封装方法去执行的简单demo。
步骤一:py文件代码
import time, os # 导入时间和操作系统模块
import pandas as pd # 导入pandas库用于数据处理
from selenium import webdriver # 导入selenium的webdriver模块
from selenium.webdriver.common.by import By # 导入定位元素的By类
from selenium.webdriver.common.keys import Keys # 导入键盘操作的Keys类
class CodeMoss(object):
# 初始化方法
def __init__(self):
self.url = "https://pc.aihao123.cn/index.html?#/chat" # 设置要访问的URL
self.driver = webdriver.Chrome() # 创建Chrome浏览器实例
# 读取Excel文件中的数据
def read_excel(self):
path = os.path.dirname(os.path.dirname(__file__)) # 获取当前文件的上级目录
data = os.path.join(path, 'selenium代码/codemoss_data.xlsx') # 拼接Excel文件路径
df = pd.read_excel(data, index_col=None, header=None) # 读取Excel文件
test_data = [] # 初始化测试数据列表
for row in df.itertuples(index=False): # 遍历每一行数据
test_data.append({"name": row[0], "type": row[1], "element": row[2], "text": row[3], "times": row[4],
"procedure": row[5]}) # 将每行数据转换为字典并添加到列表中
del test_data[0] # 删除第一行(通常是表头)
return test_data # 返回测试数据列表
# 退出浏览器的方法
def out_moss(self):
time.sleep(10) # 等待10秒
self.driver.quit() # 关闭浏览器
# 根据XPath点击元素
def element_click_xpath(self, Xpath):
self.driver.find_element(By.XPATH, str(Xpath)).click() # 查找并点击指定XPath的元素
# 根据ID点击元素
def element_click_id(self, id):
self.driver.find_element(By.ID, str(id)).click() # 查找并点击指定ID的元素
# 根据XPath输入文本
def element_text_xpath(self, Xpath, text):
self.driver.find_element(By.XPATH, str(Xpath)).send_keys(text) # 查找指定XPath的元素并输入文本
# 根据ID输入文本
def element_text_id(self, id, text):
self.driver.find_element(By.ID, str(id)).send_keys(text) # 查找指定ID的元素并输入文本
# 等待指定的时间
def element_times(self, times):
time.sleep(times) # 暂停执行指定的时间
# 登录操作的方法
def login_moss(self):
print(self.read_excel()) # 打印读取的Excel数据
self.driver.get(self.url) # 打开指定的URL
for data in self.read_excel(): # 遍历读取的测试数据
print(data['procedure']) # 打印当前操作步骤
if data['name'] == "click": # 如果操作是点击
if data['type'] == "xpath": # 根据类型判断
self.element_click_xpath(data['element']) # 点击XPath元素
if data['type'] == "id":
self.element_click_id(data['element']) # 点击ID元素
if data['name'] == "text": # 如果操作是输入文本
if data['type'] == "xpath":
self.element_text_xpath(data['element'], data['text']) # 输入XPath元素文本
if data['type'] == "id":
self.element_text_id(data['element'], data['text']) # 输入ID元素文本
if data['name'] == "times": # 如果操作是等待
self.element_times(data['times']) # 等待指定时间
self.out_moss() # 执行退出操作
if __name__ == '__main__':
CodeMoss().login_moss() # 创建CodeMoss实例并执行登录操作
步骤二:excel文件
这个excel文件跟上面的py文件是在同一个级别。注意文件地址。

文件内容如下:

总结
Selenium作为一款强大的自动化测试工具,凭借其灵活性和广泛的支持,已成为众多测试人员的首选。
如果你对Selenium还有更多疑问或想了解更深入的高级技巧,欢迎在评论区留言,我们一起探讨!
相关文章
【OpenAI】(一)获取OpenAI API Key的多种方式全攻略:从入门到精通,再到详解教程!!
【VScode】(二)VSCode中的智能AI-GPT编程利器,全面揭秘CodeMoss & ChatGPT中文版
【CodeMoss】(三)集成13种AI大模型(GPT4、o1等)、支持Open API调用、自定义助手、文件上传等强大功能,助您提升工作效率! >>> - CodeMoss & ChatGPT-AI中文版


















![[fastadmin] 第三十四篇 FastAdmin 商城模块标签使用详解](https://i-blog.csdnimg.cn/img_convert/d59fe4ec699bbe13c98f651b8339e969.png)