文章目录
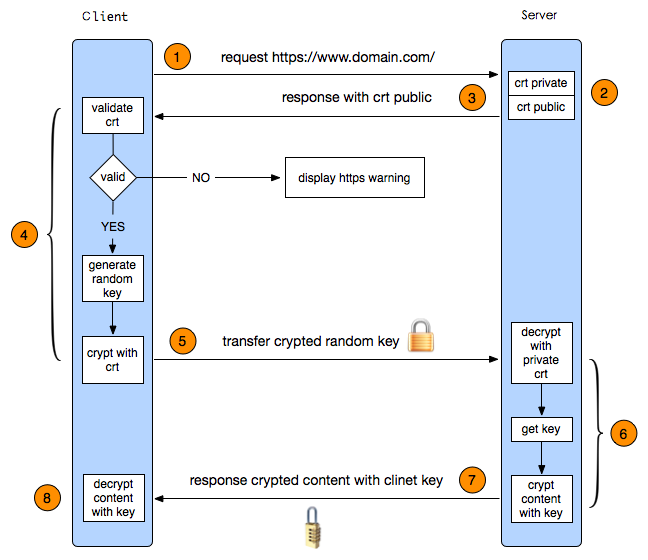
- Hudi File Layouts
- 1 核心概念
- 1.1 Base File
- 1.2 Base File
- 1.3 File Slice
- 1.4 File Group
- 2. File Layouts写过程
- 2.1 COW表
- 2.2 MOR表
Hudi File Layouts
1 核心概念
- File Layouts(文件布局)是指Hudi的数据文件在存储介质上的分布,Hudi会严格管理数据文件的命名、大小和存放位置,并会在适当时机新建、合并或分裂数据文件,这些逻辑都会体现在文件布局上。
- Hudi在文件操作上有一个重要,文件一旦创建,永远不会再更新,任何添加、修改或删除操作只会在现有文件数据的基础上合并输入数据一起写入到下一个新文件中,清楚这一点对我们解读文件布局很有帮助。
- 整体上,Hudi文件布局的顶层结构是数据表对应的base目录,下一层是各分区目录,分区目录可根据分区列数量嵌套多层,这和Hive/Spark的表结构是一致的。在最底层分区文件夹上,Hudi不再创建子文件夹,全部都是平铺的数据文件,但是这些文件在逻辑上依然有着清晰的层级关系。顶层的文件集合是File Group,File Group下面是File Slice,File Slice下面就是具体的数据文件了。我们反过来,按从下到上的顺序梳理一下这些文件和文件集合
1.1 Base File
Base File是存储Hudi数据集的主体文件,以Parquet等列式格式存储,所以我们在Hudi中看到的Parquet文件基本都是Base File。实际上,Base File的命名是为了呼应Log File,在没有Log File的COW表里,Base File就是基层的数据存储文件,没必要强调它的“Base”身份,直接叫Parquet文件就可以。Base File遵循一致的命名规范,格式为:
<fileId>_<writeToken>_<instantTime>.parquet
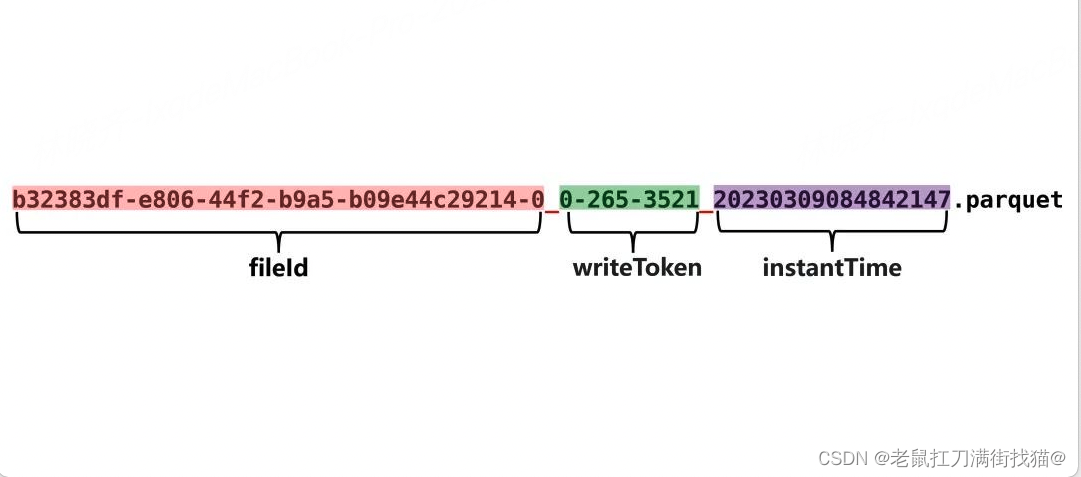
fileId部分是一个uuid,我们会在多个文件中看到相同的fileId,这些fileId相同的文件就组成了一个File Group。instantTime是写入这个文件对应的instant的时间,也是该文件的一个“版本”标注,因为一个Base File历经多轮增删改操作后就会产生多个版本,Hudi就使用instantTime对它们进行标识。不管是MOR表还是COW表,都有Base File,只是在COW表里只有Base File,在MOR表里除了Base File还有Log File。
1.2 Base File
Log File是在MOR表中用于存储变化数据的文件,也常被称作Delta Log,Log File不会独立存在,一定会从属于某个Parquet格式的Base File,一个Base File和它从属的若干Log File所构成的就是一个File Slice。Log File也遵循一致的命名规范,格式为:
.<fileId>_<baseCommitTime>.log.<fileVersion>_<writeToken>
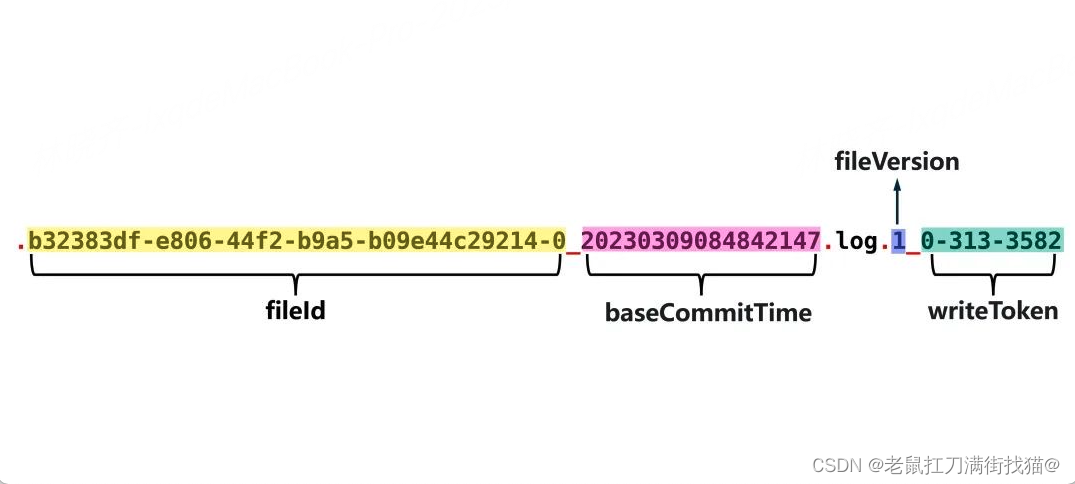
不同于Base File,Log File文件名中时间戳部分并不是Log File自己对应的instanceTime,而是它所从属的Base File的instanceTime,即baseCommitTime。如此一来,就没有办法通过时间戳来区分Log File提交的先后顺序了,所以Hudi在Log File文件名中加入了fileVersion,它是一个从1开始单调递增的序列号,用于标识Log File产生的顺序。
1.3 File Slice
在MOR表里,由一个Base File和若干从属于它的Log File组成的文件集合被称为一个File Slice。应该说File Slice是针对MOR表的特定概念,对于COW表来说,由于它不生成Log File,所以File Silce只包含Base File,或者说每一个Base File就是一个独立的File Silce。总之,对于COW表来说没有必要区分File Silce,也不没必要强调Base File的“Base”身份,只是为了概念对齐,大家会统一约定Hudi文件的三层逻辑布局为:File Group -> File Slice -> Base / Log Files。
1.4 File Group
在前面介绍Base File时,我们已经提到了File Group,简单说,就是fileId相同的文件属于同一个File Group。同一File Group下往往有多个不同版本(instantTime)的Base File(针对COW表)或Base File + Log File的组合(针对MOR表),当File Group内最新的Base File迭代到足够大( >100MB)时,Hudi就不会在当前File Group上继续追加数据了,而是去创建新的File Group。
2. File Layouts写过程
2.1 COW表
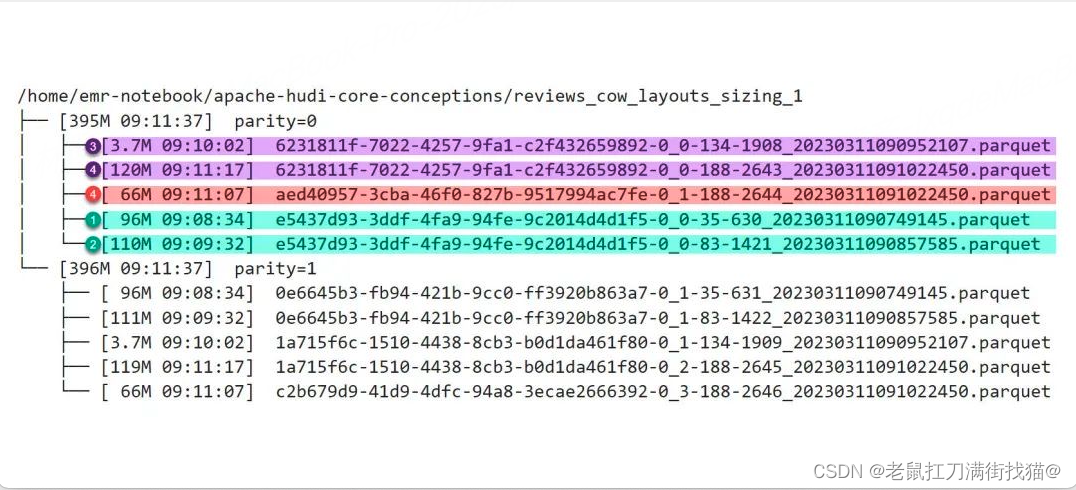
图中:青色、紫色和红色标注的文件分属于三个File Group,因为它们开头的uuid是三个不同的值,从文件名尾部的instantTime可以推断它们被创建的先后时间。当前的文件布局是历经4次操作演进而来,以分区parity=0为例,时间线(Timeline)如下:
- 第1次插入96M数据,生成了第一个Parquet文件;
- 第2次插入14M数据,在Copy On Write机制运作下,插入的14M数据与原96M数据合并写入新的Parquet文件,大小110M,fileID不变;
- 第3次插入3.7M数据,由于现有Parquet文件已经超过了100M的阈值,被Hudi判定为大文件,故不再选择它进行Copy On Write操作,转而生成新的fileId,创建新的File Group,并将数据写入新File Group的Parquet文件中,大小3.7M;
- 第4次插入182M数据,现有3.7M的文件是一个小文件,Hudi会选择以该文件为基础,将其3.7M的数据和新插入数据一起合并写入新的Parquet文件,由于这次插入的数据量较大,写入文件的体积将会超过Hudi规定的单一Parquet文件的上限(120M),所以Hudi将182M中的116M与现有3.7M数据合并,写满一个Parquet文件(120M),同时创建第3个File Group,将另外66M数据写入第3个File Group下的Parquet文件中。注意:66M的文件使用红色标记,属于一个独立的File Group,但它却是第④次提交的产物,不存在第5次提交。
2.2 MOR表
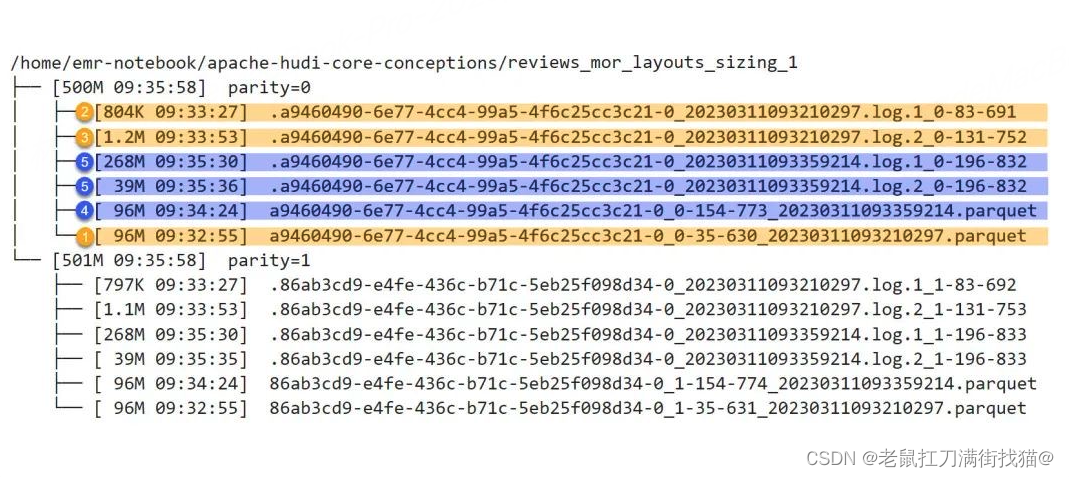
图中:单一分区下的所有文件属于一个File Group(uuid全部相同),黄色和蓝色标注的文件分属于两个不同的File Slice,其中两个Parquet文件是两个File Slice各自的Base File,它们各带两个Log File。当前的文件布局是历经4次操作(5次提交)演进而来,以分区parity=0为例,
- 第1次插入96M数据,生成了第一个Base File;
- 第2次更新了其中的一小部分数据,生成了从属于第一个Base File文件的第一个Log File,大小804K,fileVersion是1;
- 第3次又更新了其中的一小部分数据,生成了从属于第一个Base File文件的第二个Log File,大小1.2M,fileVersion是2;
- 由于该表启用了同步压缩(Inline Compaction),并将触发Compaction的deltacommits阈值设为了3,所以第3次提交后触发了同步的Compaction操作,Hudi将此前的Base File和两个Log File压缩成一个新的Base File,大小96M,fileId不变,这样就出现了第二个File Slice。每次Compaction都会进行一次独立的提交(即commit,非deltacommit),所以新Base File尾部的时间戳更新为Compaction这次提交对应的instantTime;
- 第4次更新(但却已是第5次提交)的数据量达到了307M,由于该测试表的Log File上限被设定为了250M,此次提交触发了Log File的分裂,Hudi将更新数据写入了两个Log File,一个268M,fileVersion是1;另一个39M,fileVersion是2

![[ISO26262]汽车功能安全第二部分:功能安全管理](https://img-blog.csdnimg.cn/fc434d897c4b41968d6476780e08a6e1.png)