前言
这是python网络爬虫的最后一篇给大家做个总结,且看且珍惜把!
截止到目前, 前几章本书介绍的爬虫技术都应用于一个定制网站,这样可以帮助我们更加专注于学习特定技巧。而在本章中,我们将分析几个真实网站,来看看这些技巧是如何应用的。首先我们使用 Google 演示一个真实的搜索表单,然后是依赖 JavaScript 的网站 Facebook, 接下来是典型的在线商店 Gap,最后是拥有地图接口的宝马官网由于这些都是活跃的网站,因此读者在阅读本书时这些网站存在已经发生变更的风险。不过这样也好,因为这些例子的目的是为了向你展示如何应用前面所学的技术,而不是展示如何抓取指定网站。当你选择运行某个示例时,首先需要检 查网站结构在示例编写后是否发生过改变,以及当前该网站的条款与条件是否禁止了爬虫。
9.1 Google 搜索引擎
根据第4篇文章中 Alexa 的数据, google.com 是全世界最流行的网站之一,而且非常方便的是, 该网站结构简单,易于抓取。
下图所示为 Google 搜索主页使用 Firebug 加载查看表单元素时的界面。
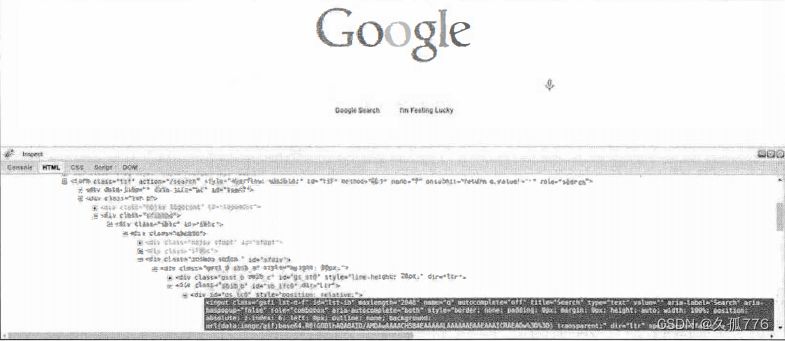
可以看到搜索查询存储在输入参数q当中,然后表单提交到 action 属性设定的search路径。我们可以通过将 test 作为搜索条件提交给表单对其进行测试,此时会跳转到类似https://www.google. com/search?q=test&oq=test&es_sm=93&ie=UTF- 8 的URL中。确切的 URL 取决于你的浏览器和地理位置。此外,还需要注意的是,如果开启了 Google 实时,那么搜索结果会使用 AJAX 执行动态加载,而不再需要提交表单。虽然 URL 中包含了很多参数,但是只有用于查询的参数q是必需的。当URL为https://www.google.com/search?q=test时也能产生相同的结果,如下图 所示 。

搜索结果的结构可以使用Firebug来检查,如下图所示。

从下图中可以看出,搜索结果是以链接的形式出现的,并且其父元素是 class 为”主”的<h3>标签。想要抓取搜索结果,我们可以使用第2篇文章中介绍的css选择器。


到目前为止,我们已经下载得到了 Google的搜索结果,并且使用lxrnl抽取出其中的链接。在上图中,我们发现链接中的真实网站URL之后还包含了一串附加参数,这些参数将用于跟踪点击下面是第一个链接。

这里我们需要的内容是http://www.speedtest.net/ ,可以使用urlparse 模块从查询字符串中其解析出来。

该查询字符串解析方法可以用于抽取所有链接。

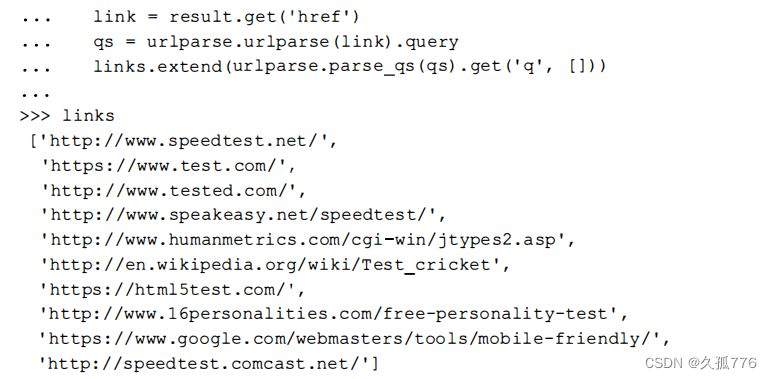
成功了!从Google搜索中得到的链接已经被成功抓取出来了。该示例的完整源码可以从https:// bitbucket.org/wswp/code/src/tip/chapter09/google.py获取。
抓取 Google 搜索结果时会碰到的一个难点是,如果你的IP出现可疑行为,比如下载速度过快, 则会出现验证码图像如下图所示

我们可以使用第7章中介绍的技术来解决验证码图像这一 问题,不过更好的方法是降低下载速度,或者在必须高速下载时使用代理,以避免被Google怀疑。
9.2 Facebook
目前,从月活用户数维度来看,Facebook 是世界上最大的社交网络之一 ,因此其用户数据非常有价值。
9.2.1 网 站
下图所示为 Packt 出版社的 Facebook 页面,其网址为https://www.
facebook.com/PacktPub。
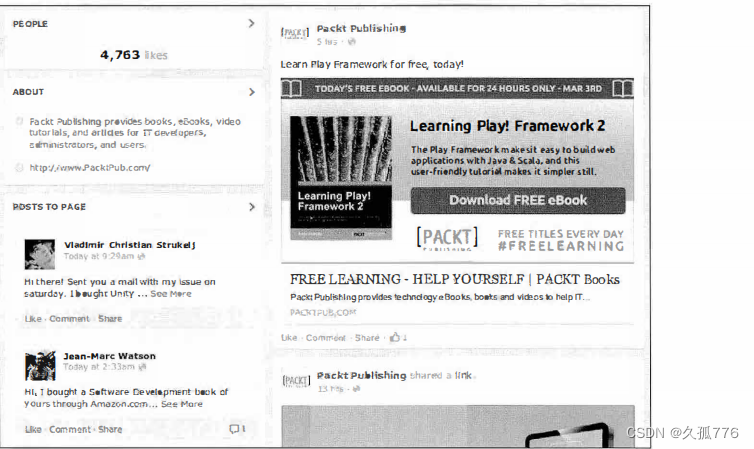
当你查看该页的源代码时,可以找到最开始的几篇日志,但是后面的日志只有在浏览器滚动时才会通过 AJAX 加载。另外, Facebook 还提供 了 一个移
动端界面, 正如第 l 章所述, 这种形式的界面通常更容易抓取。该页面在移
动端的网址为https://m.facebook.com/PacktPub,如下图所示。
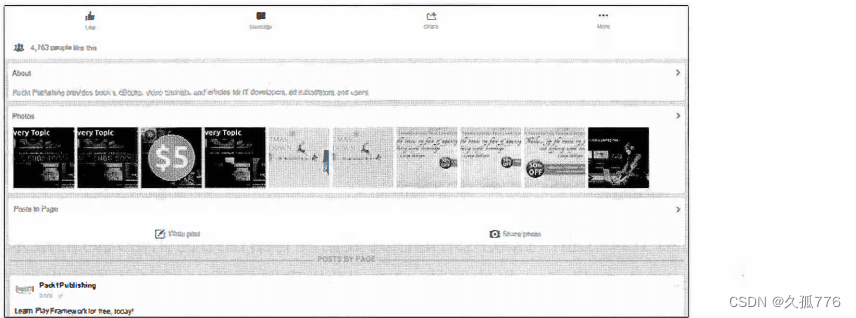
当我们与移动端网站进行交互,并使用 Firebug 查看时,会发现该界面使用了和之前相似的结构用于处理 AJAX 事件,因此该方法实际上无法简化抓取。虽然这些 AJAX 事件可以被逆向工程,但是不同类型的 Facebook 页面使用了不同的 AJAX 调用,而且依据我的过往经验,Facebook 经常会变更这些调用的结构,所以抓取这些页面需要持续维护。因此,如第5章所述,除非性能十分重要,否则最好使用浏览器渲染引擎执行JavaScript事件,然后访问生成的 HTML 页面。
下面的代码片段使用 Selenium 自动化登录 Facebook,并跳转到给定页面的 URL。
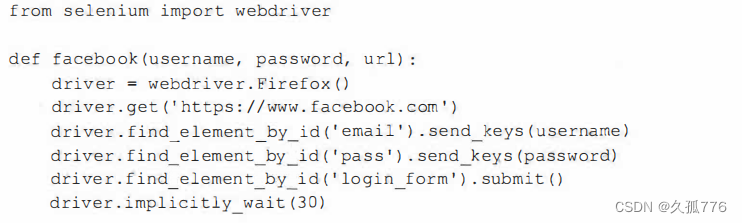

然后,可以调用该函数加载你感兴趣的 Facebook 页面,并抓取生成的HTML页面。
9.2.2 API
如第1章所述,抓取网站是在其数据没有给出结构化格式时的最末之选。而 Facebook 提供了 一些数据的API,因此我们需要在抓取之前首先检查一下 Facebook 提供的这些访问是否己经满足需求。下面是使用 Facebook 的 图形 API从Packt 出版社页面中抽取
数据的代码示例。
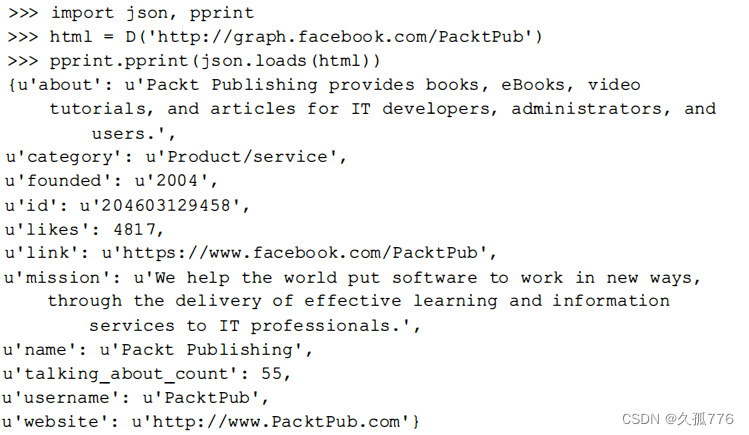
该 API 调用以 JSON 格式返回数据,我们可以使用 json 模块将其解析为 Python 的 diet 类型。 然后 ,我们可以从中抽取一些有用的特征,比如公司名、详细信息以及网站等。
图形 API 还提供了很多访问用户数据的其他调用,其文档可以从Facebook 的开发者页面中获取 网址为 https://developers.facebook.com/docs/graph-api。不过,这些 API 调用多数是设计给与己授
权的 Facebook 用户交互的 Facebook 应用的,因此在抽取他人数据时没有太大用途。要想得 到更加详细的信息,比如用户日志,仍然需要爬虫。
9.3 Gap
Gap 拥有一个结构化良好的网站,通过 Sitemap 可以帮助网络爬虫定位其最新的内容。如果我们使用第 1 章中学到的技术调研该网站,则会发现在 http://www.gap.com/robots.txt这一网址下的 robots.txt文件中包含了网站地图的链接。

下面是链接的 Sitemap 文件中的内容。

如 上 所 示 , Sitemap 链 接 中 的 内 容仅仅是索 引 , 其中又包 含 了 其他 Sitemap 文件的 链接 。 其他的 这些 S i temap 文件中 则包含 了 数千种产 品类目 的链接, 比如 http : / /www . gap.com/products /blue-long- s leeve
shirts- for -me n .jsp ,如下图所示
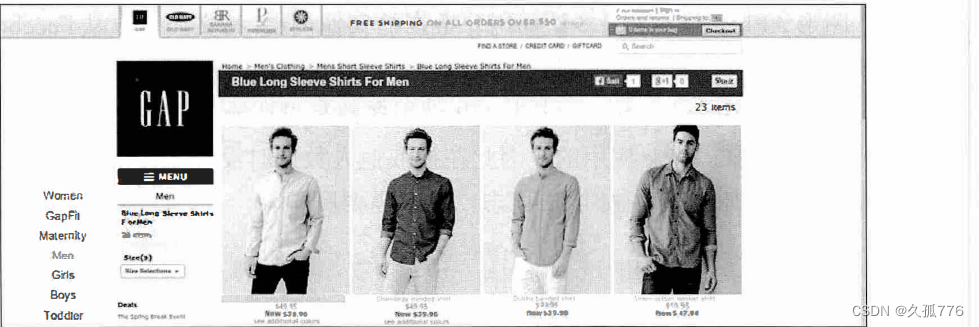
这里有大量要爬取的内容因此我们将使用第 4 章 中开发的多线程爬虫。
你可能还记得该爬虫支持一个可选的回调参数,用于定义如何解析下载到的网页。下面是爬取 Gap 网站中Sitemap 链接 的回调函数。

该回调函数首先检查下载到的URL的扩展名。如果扩展名为.xml,则认为下载到的URL是 Sitemap 文件,然后使用 lxml 的 etree 模块解析B任文件并从中抽取链接。否则,认为这是一个类 目 URL,不过本例中还没有实现抓取类目的功能。现在,我们可以在多线程爬虫中使用该回调函数来爬取 gap.com 了。


和预期一样,首先下载的是Sitemap文件,然后是服装类目。
9.4 宝马
宝马官方网站中有一个查询本地经销商的搜索工具,其网址为https://www.bmw.de/de/home. html?entryType=dlo,界面如下图所示

该工具将地理位置作为输入参数,然后在地图上显示附近的经销商地点比如在下图中以Berlin作 为搜索参数
使用Firebug,我们会发现搜索触发了如下AJAX请求。

这里, maxResults 参数被设为 99。不过,我们可以使用第1章中介绍的技术增大该参数的值, 以便在一次请求中下载所有经销商的地点。下面是将 maxResults 的值增加到 1000 时 的输出结果

AJAX请求提供了JSONP格式的数据其中JSONP是指填充模式的JSON (JSON withpadding)。 这里的填充通常是指要调用的函数,而函数的参数则为纯JSON数据,在本例中调用的是callback 函数。要想使用 Python 的json模块解析该数据,首先需要将填充部分截取掉。

现在,我们已经将德国所有的宝马经销商加载到 JSON 对象中,可以看出目前总共有731个经销 商。下面是第一个经销商的数据。

现在可以保存我们感兴趣的数据了。下面的代码片段将经销商的名称和经纬度写入一个电子表格 当中。

运行该示例后 , 得到的bmw.csv表格中的内容类似如下所示。

从宝马官网抓
取
数据的完整源代码可以从
https:/
/b
i
t
b
uc
ket
.
org/wswp/code/src/tip/chapter09/bmw.py获取。
9.5 本章小结
本章分析了几个著名网站,并演示了如何在其中应用本书中介绍过的技术。我们在抓取 Google 结果页时使用了css 选择器,在抓取Facebook页面时测试了浏览器渲染引擎和 API,在爬取Gap时使用了Sitemap,在从地图中抓取所有宝马经销商时利用了 AJAX 调用。