文章目录
- 一、Redis简介
- 1、特点:
- 2、优势
- 二、启动Redis
- 三、数据类型
- 0、通用命令
- 1、String(字符串)
- 2、Hash类型
- 3、List类型
- 4、Set(集合)
- 5、zset(sorted set:有序集合)
- 6、各个数据类型使用场景
- 四、SpringDataRedis
- 1、`RedisTemplate`简单介绍
- 2、代码配置
- 3、序列化方式
- 3.1 序列化代码
- 3.2 序列化问题
- 4、StringRedisTemplate
- 五、Redis分布式锁
- 1、set nx ex 方 式
- 2、Redisson方式
- 六、Redis服务搭建
- 1、Redis单机版
- 2、Redis主从模式
- 4.2.1 特点
- 4.2.3 配置文件解析
- 4.2.3 启动服务
- 3、Redis哨兵模式
- 4、Redis集群模式
- 六、Redis常见问题
- 1、缓存穿透
- 2、缓存雪崩
- 3、缓存击穿
一、Redis简介
1、特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
2、优势
- **性能极高:**Redis能读的速度是110000次/s,写的速度是81000次/s 。
- **丰富的数据类型:**Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- **原子:**Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- **丰富的特性:**Redis还支持 publish/subscribe(发布订阅), 通知, key 过期等等特性。
二、启动Redis
启动Redis:
redis-cli
实用配置文件启动
./redis-cli redis.conf
远程连接Redis
redis-cli -h host -p port -a password
校验Redis服务器是否可用ping
ping
三、数据类型
0、通用命令
- KEYS:查看符合模板的所有key
- DEL:删除一个指定的key
- EXISTS:判断key是否存在
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个KEY的剩余有效期
1、String(字符串)
Redis的key的格式:
[项目名]:[业务名]:[类型]:[id]
String类型,也就是字符串类型,是Redis中最简单的存储类型。其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512m。
常用命令:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
127.0.0.1:6379> SET runoob "菜鸟教程"
OK
127.0.0.1:6379> GET runoob
"\xe8\x8f\x9c\xe9\xb8\x9f\xe6\x95\x99\xe7\xa8\x8b"
2、Hash类型
Redis hash 是一个键值(key=>value)对集合。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:

Hash的常见命令有:
- HSET key field value:添加或者修改hash类型key的field的值
- HGET key field:获取一个hash类型key的field的值
- HMSET:批量添加多个hash类型key的field的值
- HMGET:批量获取多个hash类型key的field的值
- HGETALL:获取一个hash类型的key中的所有的field和value
- HKEYS:获取一个hash类型的key中的所有的field
- HVALS:获取一个hash类型的key中的所有的value
- HINCRBY:让一个hash类型key的字段值自增并指定步长
- HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
127.0.0.1:6379> hmset test test01 "hello" test02 "world"
OK
127.0.0.1:6379> hget test test01
"hello"
127.0.0.1:6379> hget test test02
"world"
3、List类型
- Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
- 列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
List的常见命令有:
- LPUSH key element … :向列表左侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
- RPUSH key element … :向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素
- LRANGE key star end:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil

127.0.0.1:6379> lpush my_list redis
(integer) 1
127.0.0.1:6379> lpush my_list hello
(integer) 2
127.0.0.1:6379> lpush my_list word
(integer) 3
127.0.0.1:6379> lrange my_list 0 10
1) "word"
2) "hello"
3) "redis"
127.0.0.1:6379>
4、Set(集合)
- Redis 的 Set 是 string 类型的无序集合。
- 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
- 以上实例中 rabbitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。
- 集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。
String的常见命令有:
- SADD key member … :向set中添加一个或多个元素
- SREM key member … : 移除set中的指定元素
- SCARD key: 返回set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中的所有元素
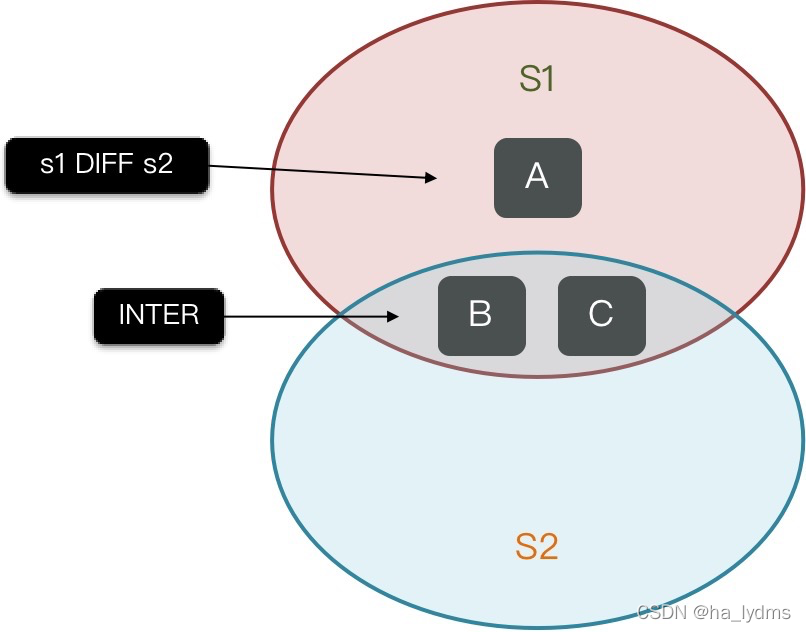
- SINTER key1 key2 … :求key1与key2的交集
- SDIFF key1 key2 … :求key1与key2的差集
- SUNION key1 key2 …:求key1和key2的并集
127.0.0.1:6379> sadd my_set redis
(integer) 1
127.0.0.1:6379> sadd my_set hello
(integer) 1
127.0.0.1:6379> sadd my_set world
(integer) 1
127.0.0.1:6379> sadd my_set world
(integer) 0
127.0.0.1:6379> smembers my_set
1) "hello"
2) "redis"
3) "world"
127.0.0.1:6379>
5、zset(sorted set:有序集合)
- Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
- 不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
- zset的成员是唯一的,但分数(score)却可以重复。
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF、ZINTER、ZUNION:求差集、交集、并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可
127.0.0.1:6379> zadd my_zset 0 set01
(integer) 1
127.0.0.1:6379> zadd my_zset 10 set02
(integer) 1
127.0.0.1:6379> zadd my_zset 20 set03
(integer) 1
127.0.0.1:6379> zadd my_zset 30 set04
(integer) 1
127.0.0.1:6379> zrangebyscore my_zset 0 1000
1) "set01"
2) "set02"
3) "set03"
4) "set04"
127.0.0.1:6379>
6、各个数据类型使用场景
| tring(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | — |
|---|---|---|---|
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1)。 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友。 2、利用唯一性,统计访问网站的所有独立ip。 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |
四、SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
提供了对不同Redis客户端的整合(Lettuce和Jedis)
提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
1、RedisTemplate简单介绍
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。
并且将不同数据类型的操作API封装到了不同的类型中:
| API | 返回值类型 | 说明 |
|---|---|---|
| redisTemplate.opsForValue() | ValueOperations | 操作String类型数据 |
| redisTemplate.opsForHash() | HashOperations | 操作Hash类型数据 |
| redisTemplate.opsForList() | ListOperations | 操作List类型数据 |
| redisTemplate.opsForSet() | SetOperations | 操作Set类型数据 |
| redisTemplate.opsForZSet() | ZSetOperations | 操作SortedSet类型数据 |
| redisTemplate | 通用的命令 |
2、代码配置
1.pom.xml配置
<!--Redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--连接池依赖-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
2.配置文件(application.Properties)
spring.redis.host=192.168.150.101
spring.redis.port=6379
spring.redis.password=123321
spring.redis.lettuce.pool.max-active=8 # 最大连接数
spring.redis.lettuce.pool.max-idle=8 # 最大空闲连接
spring.redis.lettuce.pool.min-idle=0 # 最小空闲连接
spring.redis.lettuce.pool.max-wait=100 # 连接等待时间
3.具体代码
@Autowired
private RedisTemplate redisTemplate;
@SpringBootTest
public class RedisTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
// 插入一条string类型数据
redisTemplate.opsForValue().set("name", "李四");
// 读取一条string类型数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}
3、序列化方式
3.1 序列化代码
1.StringRedisSerializer
@Bean(name = "redisTemplate")
@SuppressWarnings("unchecked")
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
//使用fastjson序列化
// value值的序列化采用fastJsonRedisSerializer
template.setValueSerializer(new StringRedisSerializer());
template.setHashValueSerializer(new StringRedisSerializer());
// key的序列化采用StringRedisSerializer
template.setKeySerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
template.setConnectionFactory(redisConnectionFactory);
return template;
}
2.GenericJackson2JsonRedisSerializer
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(); // 设置连接工厂
redisTemplate.setConnectionFactory(redisConnectionFactory); // 设置序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// key和 hashKey采用 string序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// value和 hashValue采用 JSON序列化
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);
return redisTemplate;
}
3.2 序列化问题
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题,如图:
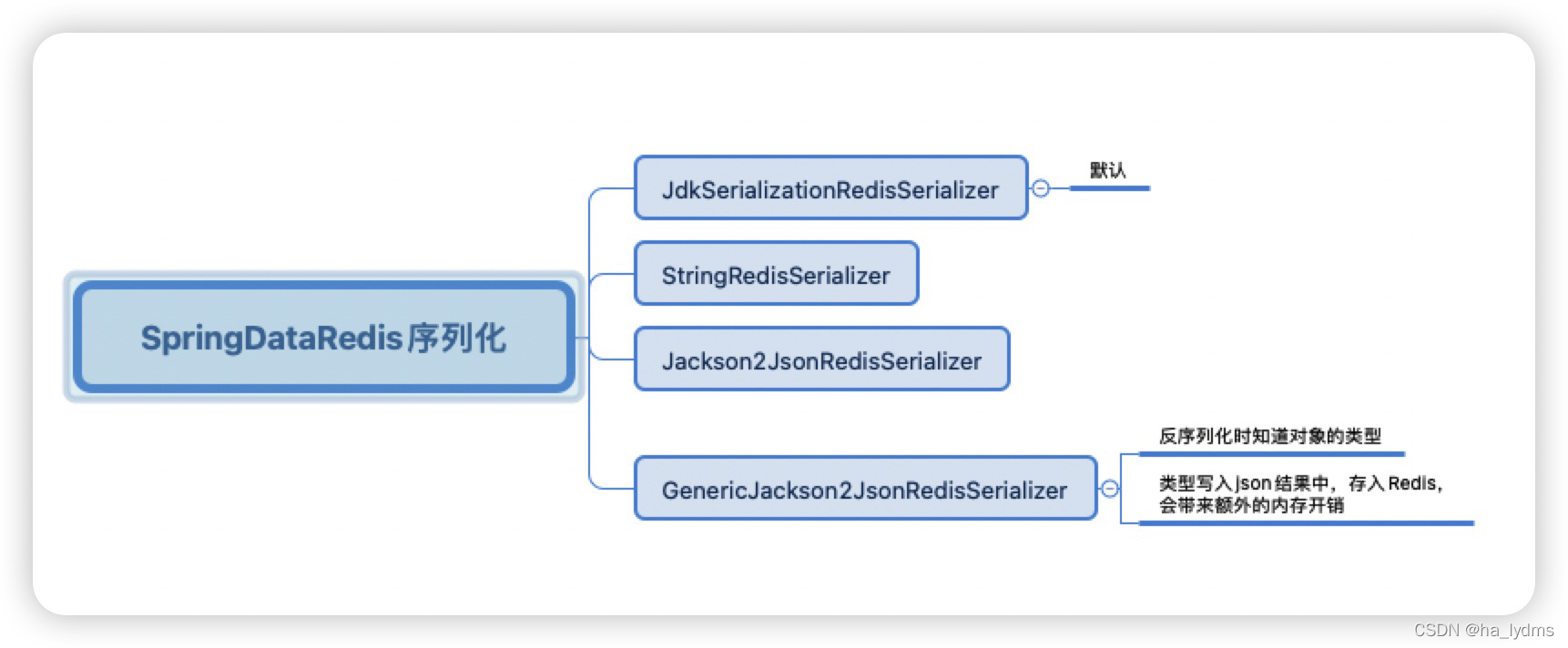
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
4、StringRedisTemplate
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
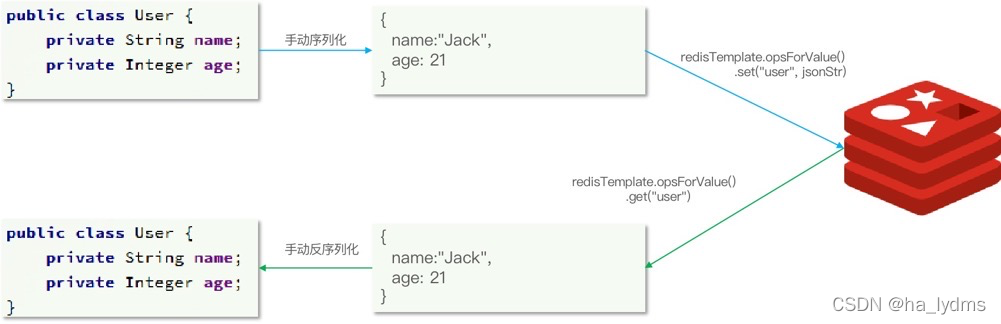
Spring默认提供了一个StringRedisTemplate类,它的key和value的序列化方式默认就是String方式。省去了我们自定义RedisTemplate的过程:
@Autowired
private StringRedisTemplate stringRedisTemplate;
// JSON工具
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testStringTemplate() throws JsonProcessingException {
// 准备对象
User user = new User("虎哥", 18);
// 手动序列化
String json = mapper.writeValueAsString(user);
// 写入一条数据到redis
stringRedisTemplate.opsForValue().set("user:200", json);
// 读取数据
String val = stringRedisTemplate.opsForValue().get("user:200");
// 反序列化
User user1 = mapper.readValue(val, User.class);
System.out.println("user1 = " + user1);
}
五、Redis分布式锁
1、set nx ex 方 式
基于Redis的分布式锁实现思路:
- 利用set nx ex获取锁,并设置过期时间,保存线程标示
- 释放锁时先判断线程标示是否与自己一致,一致则删除锁
特性:
- 利用set nx满足互斥性
- 利用set ex保证故障时锁依然能释放,避免死锁,提高安全性
- 利用Redis集群保证高可用和高并发特性
基于setnx实现的分布式锁存在下面的问题:

2、Redisson方式
六、Redis服务搭建
1、Redis单机版
2、Redis主从模式
4.2.1 特点
- 主节点(master)进行数据插入,从节点(slave)进行数据查询。
- 主节点宕机后,将不能再进行数据插入,只能进行查询。
- 使用主从模式时应注意matser节点的持久化操作,matser节点在未使用持久化的情况详情下如果宕机,并自动重新拉起服务,从服务器会出现丢失数据的情况。
4.2.3 配置文件解析
核心配置:
slaveof 121.5.193.35 6379
配置解析:
| 13 | slaveof <masterip> <masterport> | 设置当本机为 slave 服务时,设置 master 服务的 IP 地址及端口,在 Redis 启动时,它会自动从 master 进行数据同步 |
|---|
实际配置文件(master):
bind 0.0.0.0
# 端口号
port 6379
# 日志输出文件
logfile "6379.log"
# 指定存储数据文件名
dbfilename "dump-6379.rdb"
# 是否开启守护线程形式
daemonize yes
# 存储至本地数据库时是否压缩数据
rdbcompression yes
实际配置文件(cluster):
bind 0.0.0.0
port 6380
logfile "6380.log"
dbfilename "dump-6380.rdb"
daemonize yes
rdbcompression yes
slaveof 121.5.193.35 6379
4.2.3 启动服务
启动Redis服务
./redis-server redis.conf
3、Redis哨兵模式
4、Redis集群模式
六、Redis常见问题
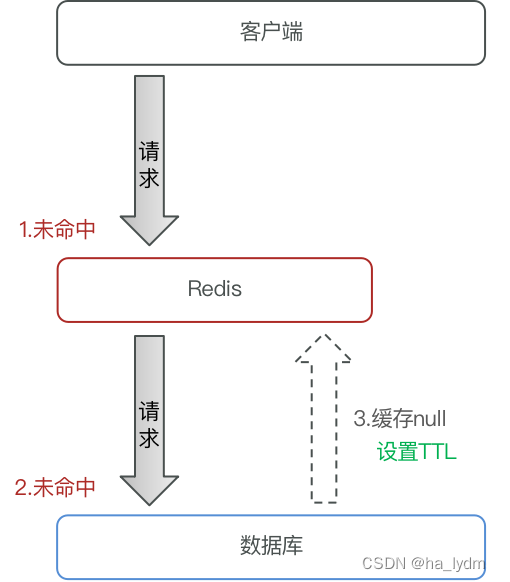
1、缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
缓存空对象
优点:
- 实现简单,维护方便
缺点:
-
额外的内存消耗
-
可能造成短期的不一致
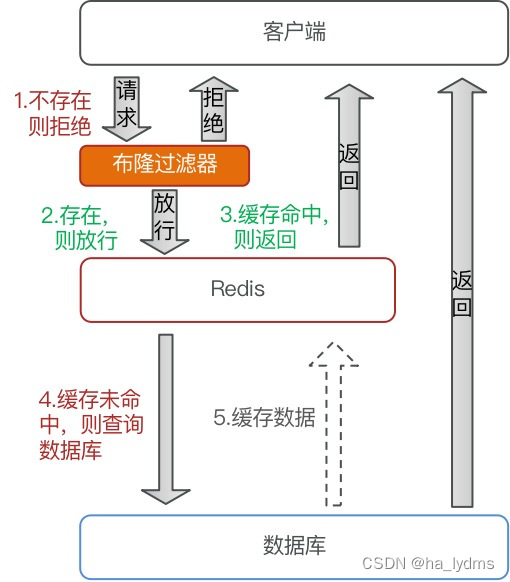
布隆过滤
优点:
- 内存占用较少,没有多余key
缺点:
- 实现复杂
- 存在误判可能
总结:
缓存穿透产生的原因是什么?
- 用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力
缓存穿透的解决方案有哪些?
- 缓存null值
- 布隆过滤
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
2、缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
-
给不同的Key的TTL添加随机值
-
利用Redis集群提高服务的可用性
-
给缓存业务添加降级限流策略
-
给业务添加多级缓存

3、缓存击穿
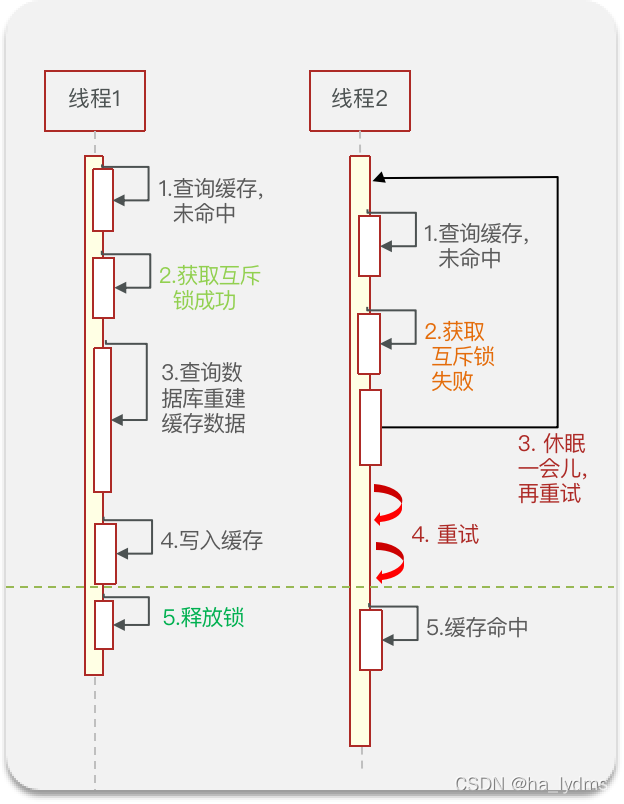
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
- 互斥锁
- 逻辑过期
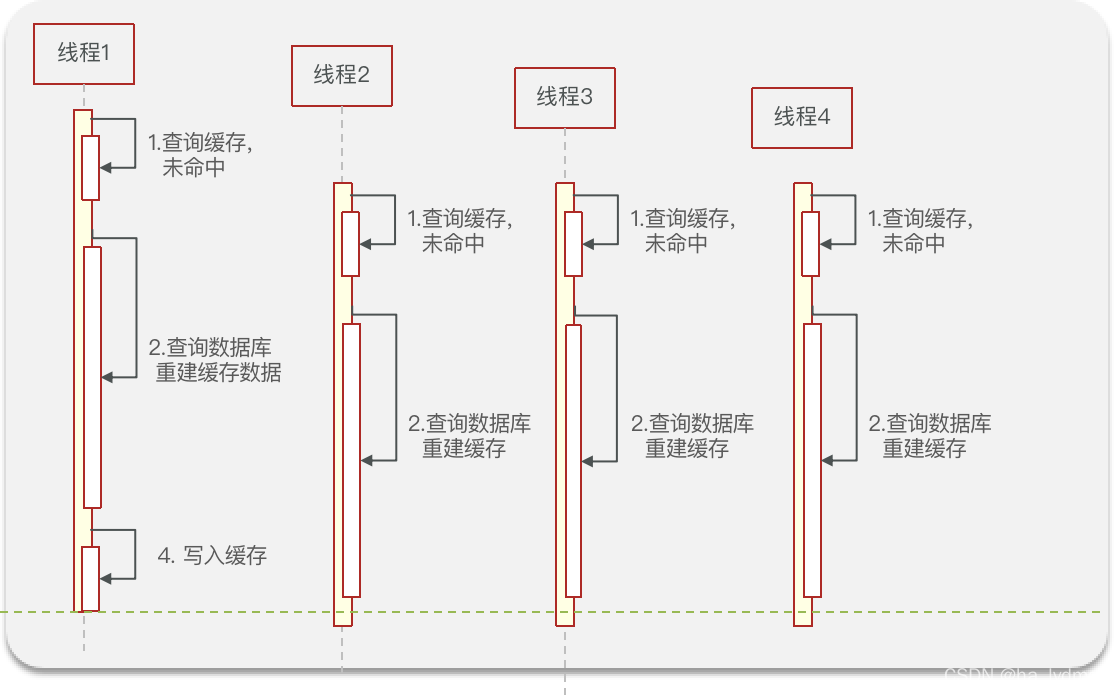
解决方式一:互斥锁
解决方式二:逻辑过期
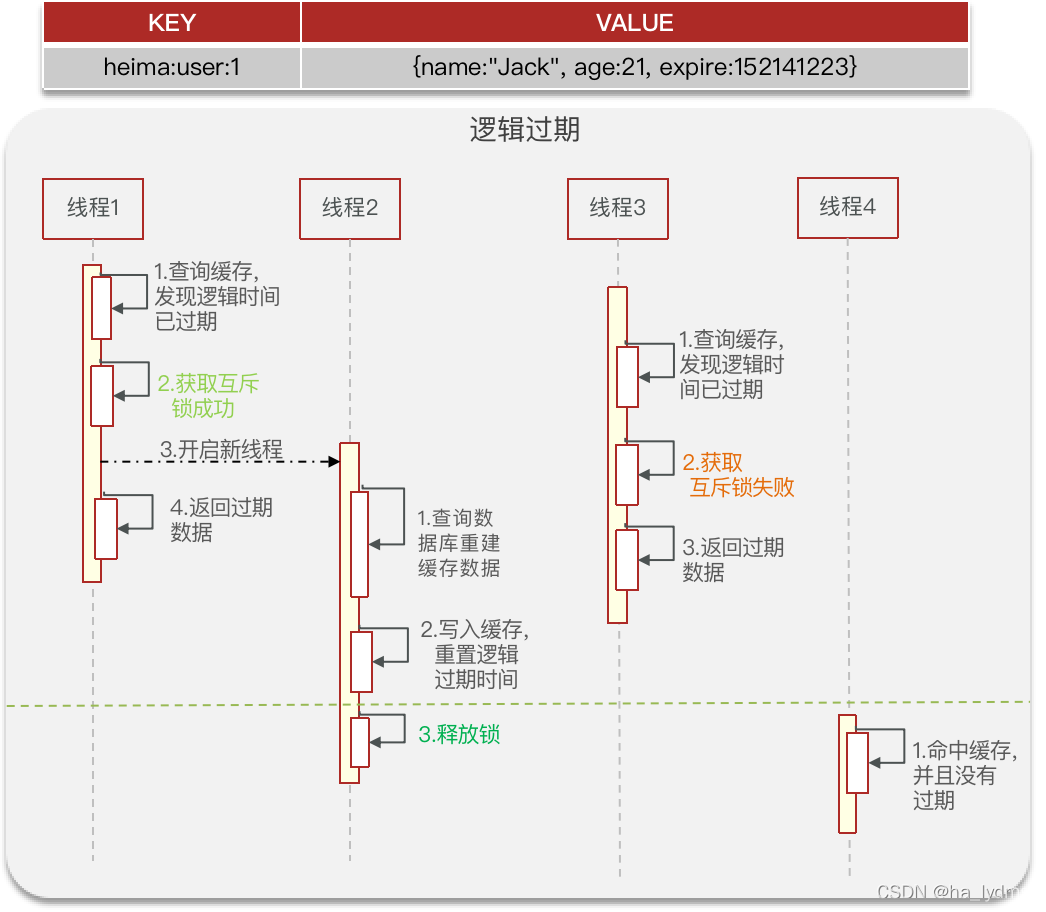
优缺点: