---------------------- Redis 性能管理 ----------------------------------------
----- 查看Redis内存使用 -----
info memory redis-cli -a 'abc123' info memory
----- 内存碎片率 -----
- used_memory_rss:是Redis向操作系统申请的内存。
- used_memory:是Redis中的数据占用的内存。
- mem_fragmentation_ratio:内存碎片率。
mem_fragmentation_ratio = used_memory_rss / used_memory- used_memory_peak:redis内存使用的峰值。
内存碎片如何产生的?
Redis内部有自己的内存管理器,为了提高内存使用的效率,来对内存的申请和释放进行管理。
Redis中的值删除的时候,并没有把内存直接释放,交还给操作系统,而是交给了Redis内部有内存管理器。
Redis中申请内存的时候,也是先看自己的内存管理器中是否有足够的内存可用。
Redis的这种机制,提高了内存的使用率,但是会使Redis中有部分自己没在用,却不释放的内存,导致了内存碎片的发生。Redis请求了一堆内存空着不用,也不还给操作系统,俗称占着茅坑不拉屎。
跟踪内存碎片率对理解Redis实例的资源性能是非常重要的
●内存碎片率在1到1.5之间是正常的,这个值表示内存碎片率比较低,也说明 Redis 没有发生内存交换。
●内存碎片率超过1.5,说明Redis消耗了实际需要物理内存的150%,其中50%是内存碎片率。
●内存碎片率低于1的,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换。需要增加可用物理内存或减少 Redis内存占用。解决碎片率大的问题
如果你的Redis版本是4.0以下的,需要在 redis-cli 工具上输入 shutdown save 命令,让 Redis 数据库执行保存操作并关闭 Redis 服务,再重启服务器。Redis服务器重启后,Redis会将没用的内存归还给操作系统,碎片率会降下来。Redis4.0版本开始,可以在不重启的情况下,线上整理内存碎片。
config set activedefrag yes #自动碎片清理,内存就会自动清理了。 memory purge #手动碎片清理
----- 内存使用率 -----
redis实例的内存使用率超过可用最大内存,操作系统将开始进行内存与swap空间交换。
避免内存交换发生的方法
●针对缓存数据大小选择安装 Redis 实例(内存大多装几个Redis实例,内存小就少装)
●尽可能的使用Hash数据结构存储(hash 散列 占用空间小)
●设置key的过期时间(设置过期时间 用不到的key不让他浪费空间)
----- 内回收key -----
内存数据淘汰策略,保证合理分配redis有限的内存资源
当达到设置的最大阀值时,需选择一种key的回收策略,默认情况下回收策略是禁止删除。
配置文件中修改 maxmemory-policy 属性值vim /usr/local/redis/conf/redis.conf --1149-- maxmemory-policy noenviction #最大内存时key的淘汰策略 ●volatile-lru:从已设置过期时间的数据集合中 使用LRU算法淘汰数据(移除最近最少使用的key,针对设置了TTL的key) ●volatile-ttl:从已设置过期时间的数据集合中 挑选即将过期的数据淘汰(移除最近过期的key) ●volatile-random:从已设置过期时间的数据集合中 随机挑选数据淘汰(在设置了TTL的key里随机移除) ●allkeys-lru:使用LRU算法从所有数据集合中淘汰数据(移除最少使用的key,针对所有的key) ●allkeys-random:从数据集合中任意选择数据淘汰(随机移除key) ●noenviction:禁止淘汰数据(不删除直到写满时报错)其它限制相关
●maxclients #最大客户端连接数 设置redis同时可以与多少个客户端进行连接。 默认情况下为10000个客户端。 如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应。 ●maxmemory #最大内存使用量 Redis使用最大内存量。建议必须设置,否则,将内存占满,造成服务器宕机。 设置redis可以使用的内存量。一旦到达内存使用上限,redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。 如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。 但是对于无内存申请的指令,仍然会正常响应,比如GET等。如果你的redis是主redis(说明redis集群有主从),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。 ●maxmemory-samples #LRU/最小TTL算法的采样数量 设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key并选择其中LRU的那个。 一般设置3到7的数字,数值越小样本越不准确,但性能消耗越小。
redis优化(总结)
性能优化
1)设置 config set activedefrag yes 开启内存碎片自动清理, 或者定时执行 memory purge 清理内存碎片
2)设置 maxmemory 指定redis占用最大内存大小, 设置 maxmemory-samples 指定内存数据淘汰策略的样本数量
3)设置 内存数据淘汰策略 maxmemory-policy 实现保证内存使用率不超过设置的最大内存大小
4)设置 key 的过期时间,精简 键名和键值,及控制键值的大小
5)尽可能使用 Hash 数据类型存储数据,因为 Hash 类型的一个键包含多个字段,该类型的数据占用空间较小
6)合理设置 maxclients 最大客户端连接数(10000),tcp-backlog tcp监控端口的最大连接排队数(1024), timeout 连接超时时间(30000)安全优化
7)设置 AOF 持久化8)部署 主从复制 备份数据,采用 哨兵 或者 集群 模式实现高可用
9)设置 config set requirepass 开启密码验证
缓存和数据库双写一致性问题(面试有几率问)
Redis缓存服务器要与MySQL服务器中数据保持一致。
为了实现数据的一致,可以
先更新数据库,然后再删除缓存 + 缓存做过期时间,数据过期后再有读请求可从数据库直接更新缓存,以保证数据的一致性。
1.读取数据时,先从Redis中读取,如果Redis中没有,再从MvSQL中读取,并将读取到的数据写入到Redis缓存中。
2.更新数据时,先更新MySQL数据库,再更新Redis缓存。
3.删除数据时,同样需要先删除Redis缓存,再删除MvSQL数据库。
4.对于一些关键数据,可以使用MySQL的触发器(Trigger) 来实现同步更新Redis缓存。当MySQL中的数据发生变化时,触发器可以自动将变化同步到Redis中,避免了手动操作的疏漏。
5.定期同步MySQL和Redis中的数据,以确保数据的一致性。可以使用定时任务或者其他方式定期同步两个数据源中的数据,从而保持一致。
缓存的三大问题(需要知道现象原因,解决方案可以不用管,是软件开发的业务逻辑问题)
正常情况下,大量的资源请求都会被redis响应,在redis得不到响应的小部分请求才会去请求DB,这样DB的压力是非常小的,是可以正常工作的。
缓存雪崩/击穿/穿透三大问题的根本原因在于Redis命中率下降,大量请求直接落在数据库上,导致数据库直接崩溃。
- 缓存雪崩:redis中大量key集体过期
- 缓存击穿:redis中一个热点key过期(大量用户访问该热点key,但是热点key过期)
- 缓存穿透:大量请求根本不存在的key
缓存雪崩
缓存同一时间大面积的过期失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。(软件开发负责)
给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
缓存击穿
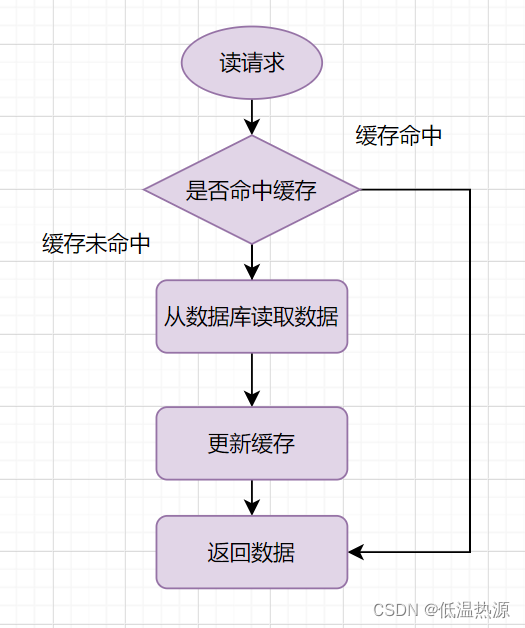
缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。解决方案
实时调整,监控哪些数据是热门数据,实时的调整key的过期时长
使用锁机制,加互斥锁
缓存穿透
缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
采用布隆过滤器(牠说有的数据不一定有,但是确认过没有的数据肯定没有),将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力穿透解决方案:
对空值进行缓存
设置白名单
使用布隆过滤器
网警