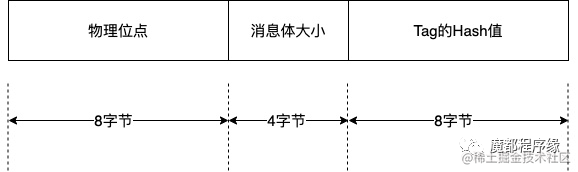
文章目录
- Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
- 摘要
- 本文方法
- 实验结果
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
摘要
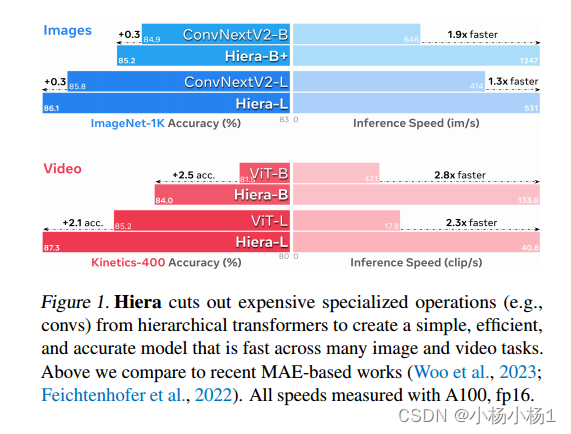
现代层次视觉转换器在追求监督分类性能的过程中增加了一些特定于视觉的组件。虽然这些组件带来了有效的精度和有吸引力的FLOP计数,但增加的复杂性实际上使这些变压器比它们的ViT对应产品慢。在本文中,我们认为这种额外的体积是不必要的。
本文方法
通过使用强视觉代理任务(MAE)进行预训练,我们可以在不损失精度的情况下从最先进的多级视觉变压器中去除所有的铃声和口哨。在这个过程中,我们创建了一个非常简单的分层视觉变压器Hiera,它比以前的模型更准确,同时在推理和训练过程中都要快得多。我们在图像和视频识别的各种任务上对Hiera进行了评估
代码地址
本文方法
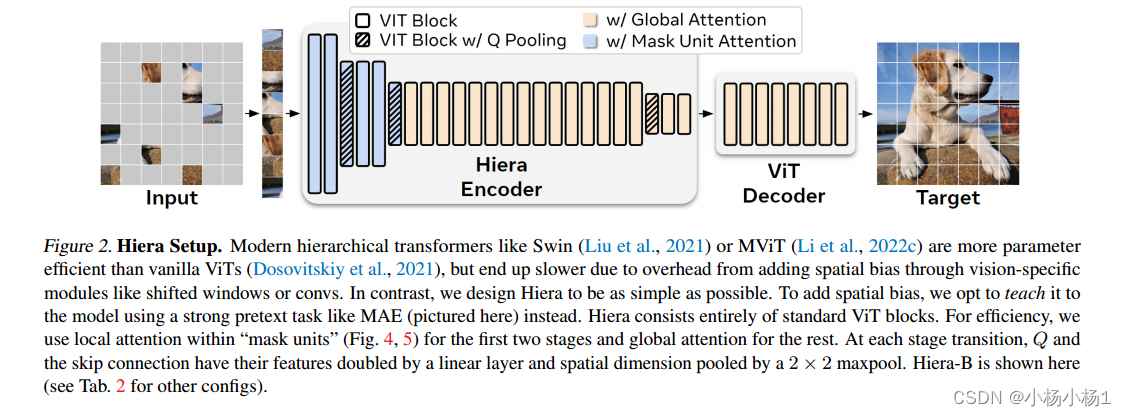
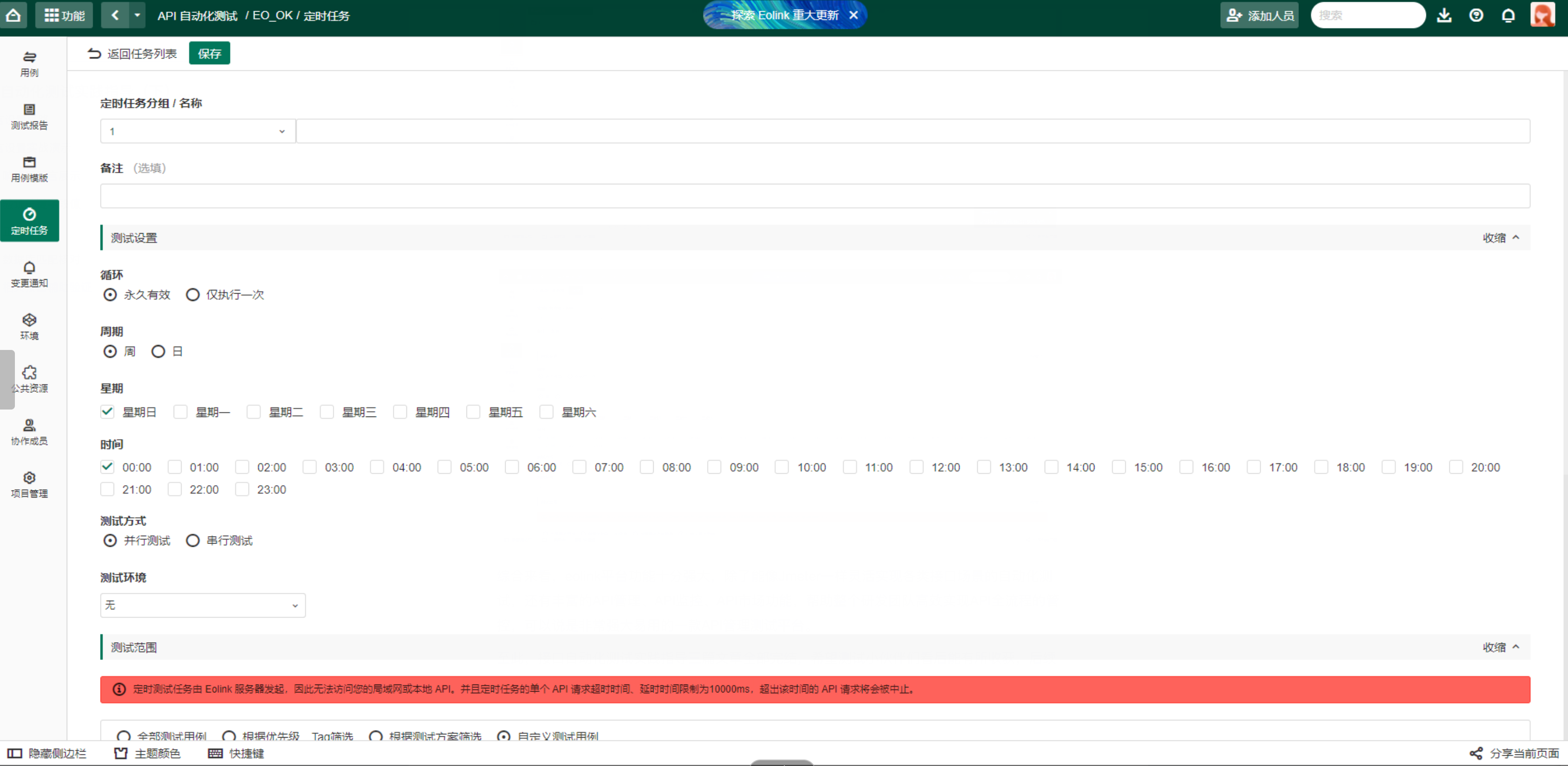
Swin或MViT这样的现代层级式transformer比普通vit参数效率更高,但由于通过视觉特定模块(如移位窗口或convs)添加空间偏差的开销,最终速度变慢。相反,我们将Hiera设计得尽可能简单。为了增加空间偏差,我们选择使用强大的代理任务(如MAE)来教模型。Hiera完全由标准ViT块组成。为了提高效率,我们在前两个阶段使用“掩模单元”中的局部注意力(图4,5),其余阶段使用全局注意力。在每个阶段的过渡中,Q和跳跃连接的特征被线性层加倍,空间维度被2 × 2 maxpool池化。层次结构b显示在这里(其他配置见表2)

图4。层次模型的MAE。MAE与多阶段模型不兼容,但我们可以应用一些简单的技巧来解决这个问题。虽然MAE mask了单个令牌,但多级变压器中的令牌开始时非常小(例如,4 × 4像素),每级大小增加一倍。
(a)因此,我们掩码更粗的“掩码单位”(32×32像素)而不是直接token。
(b)为了提高效率,MAE是稀疏的,这意味着它删除了它所掩盖的东西(这是像卷积这样的空间模块的问题)。
©保留掩码令牌修复了这个问题,但放弃了MAE潜在的4 - 10倍的训练加速。
(d)作为基线,我们引入了一个技巧,将掩码单元作为卷积的单独实体,解决了问题,但需要不必要的填充。
(e)在Hiera中,我们通过改变架构来完全回避这个问题,这样内核就不会在掩码单元之间重叠。

MViTv2使用池化注意力(a),通过K和V的池化版本执行全局关注。对于大输入(例如视频)来说,这可能会很昂贵,所以我们选择用“掩码单元注意”(b)来代替它,它在掩码单元内执行局部注意(图4a)。这没有开销,因为我们已经将令牌分组为屏蔽单元。
我们不必像在Swin中那样担心转移(Liu et al, 2021),因为我们在阶段3和4中使用了全局注意力(图2)。

窗口注意(a)在固定大小的窗口内执行局部注意。这样做可能会在稀疏MAE预训练期间与删除的标记重叠。相比之下,掩模单元注意(b)在单个掩模单元内执行局部注意,无论其大小如何。
实验结果