天津大学天津市认知计算与应用重点实验室视听觉认知计算团队12篇论文被语音技术顶会Interspeech 2023接收,涵盖意图识别、口语理解、声学特征、语音识别、语音分离、情感识别等研究方向,论文简介如下。
01. Rethinking the visual cues in audio-visual speaker extraction
论文作者:李俊杰,葛檬,潘泽旭,曹瑞,王龙标,党建武,张仕良
论文单位:天津大学,阿里巴巴达摩院

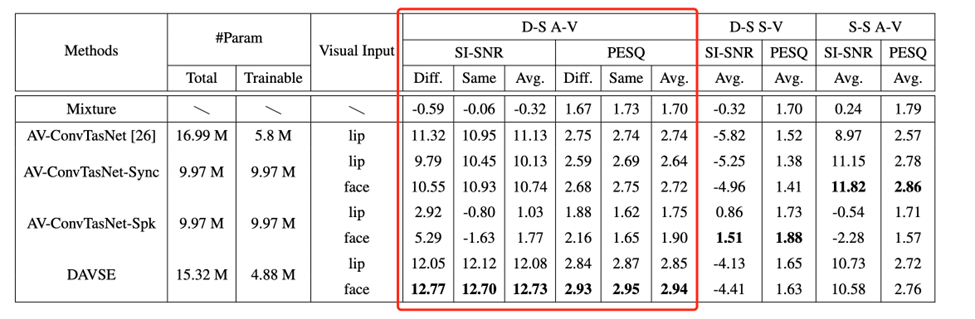
音视频语音分离利用视觉信息从混合语音中提取目标人的语音信号。然而目前的方法仅仅采用单独的视觉编码器来提取视觉信息,本文提出利用两个视觉编码器分别提取视觉信号中的说话人信息和同步信息,模型结构如图d所示。本文的实验结果表明,相比于单解码器隐性利用的方法,显性地利用身份和同步信息的方法能显著提升语音分离模型的性能。
02. Locate and Beamform: Two-dimensional Locating All-neural Beamformer for Multi-channel Speech Separation
论文作者:付燕杰、葛檬,王洪龙,李楠,尹浩然,王龙标,张高燕,党建武,邓承韵,王飞
论文单位:天津大学,新加坡国立大学,北京小桔科技有限公司
论文资源:https://arxiv.org/abs/2305.10821

近年来,神经波束成形技术在多通道语音分离方面取得了惊人的进步。然而,它们大多忽略了混合信号中包含的说话人二维位置线索。在本文中,我们提出了一种端到端的波束成形网络,用于在仅给定混合信号的情况下,通过二维位置信息引导语音分离。该网络首先估计可辨别的方向和二维位置线索,这些线索暗含声源相对多参考麦克风的到达方向及其二维位置坐标。然后将这些线索整合到位置感知神经波束成形模块,从而可以精确地重建两个声源的语音信号。实验表明,与基线系统相比,我们提出的模型不仅在语音分离指标上取得了全面的提升,而且避免了在空间重叠情况下表现不佳。
03. SDNet: Stream-attention and Dual-feature Learning Network for Ad-hoc Array Speech Separation
论文作者:王洪龙,邓承韵,付燕杰,葛檬,王龙标,张高燕,党建武,王飞
论文单位:天津大学,北京小桔科技,新加坡国立大学
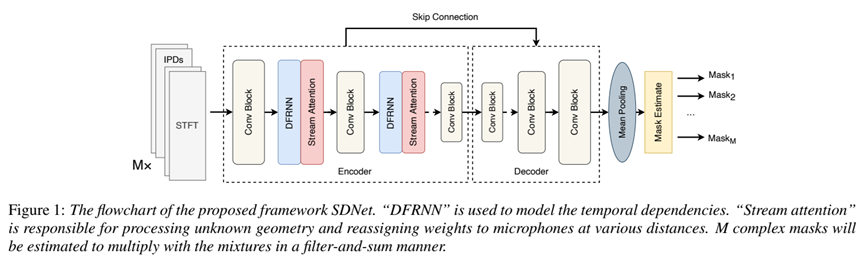
使用固定阵列的多通道语音分离领域已经取得了不错的进展。本文提出一个适用于分布式麦克风阵列的鲁棒系统,以应对麦克风位置和数量的不确定性。以往的研究通常使用平均化方法处理分布式的麦克风信号,忽视了麦克风在不同位置的多样性。一些研究表明,信噪比高的麦克风对提高语音质量更有帮助。受此启发,我们提出了一种名为SDNet的通道流注意力和双特征学习网络。主要贡献如下:1)我们提出了一个参数更少的双特征学习块,更好地学习长期依赖。2)基于这种高质量的语音表示,我们进一步提出了通道流注意力,有效处理位置和数量变化的麦克风,并将更多注意力分配给信噪比较高的麦克风。实验证明,我们提出的模型优于其他的基准模型。
04. Discrimination of the Different Intents Carried by the Same Text Through Integrating Multimodal Information
论文作者:李忠杰,张高燕,王龙标,党建武
论文单位:天津大学
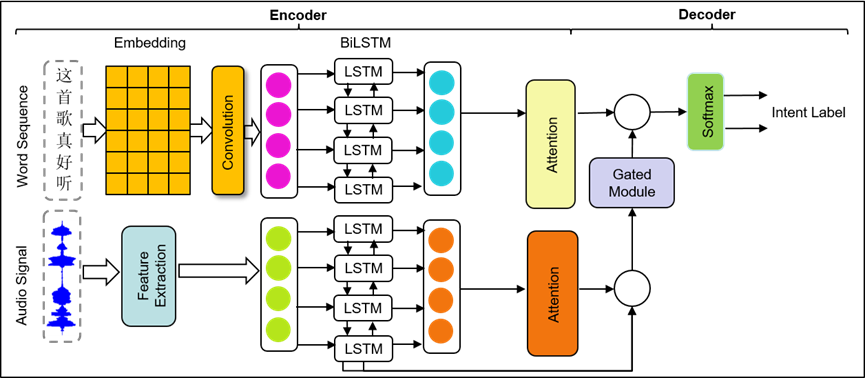
随着人工智能的发展和智能设备的普及,人机智能对话技术得到了广泛的关注。而口语意图理解是整个对话系统的核心模块,因此,如何准确获取由说话人传递的包括由文本信息承载的语言意图和由声学信息承载的副语言意图等全面意图信息是一个关键问题。
目前,许多意图理解研究忽视了副语言信息的影响,这导致在语音交互过程中出现误解,尤其是当相同的文本通过不同的副语言信息传达不同的意图。为了解决这一问题,本研究首先创建了一个包含相同文本但意图不同的中文多模态口语意图理解数据集。然后,我们提出的基于注意力的BiLSTM模型整合了文本和声学特征,并引入了一个声学信息门机制,以补充或修正语言意图。实验结果表明,我们的多模态融合模型相比仅使用语言信息的模型,其意图识别准确性提高了11.0%。该实验结果证明了我们提出的模型在意图识别方面的有效性,特别是在文本相同但意图不同的情况下。
05. Frequency Patterns of Individual Speaker Characteristics at Higher and Lower Spectral Ranges
论文作者:张昭,张句,朱梓毓,迟雨杰,本多清志,魏建国
论文单位:天津大学,慧言科技(天津)有限公司
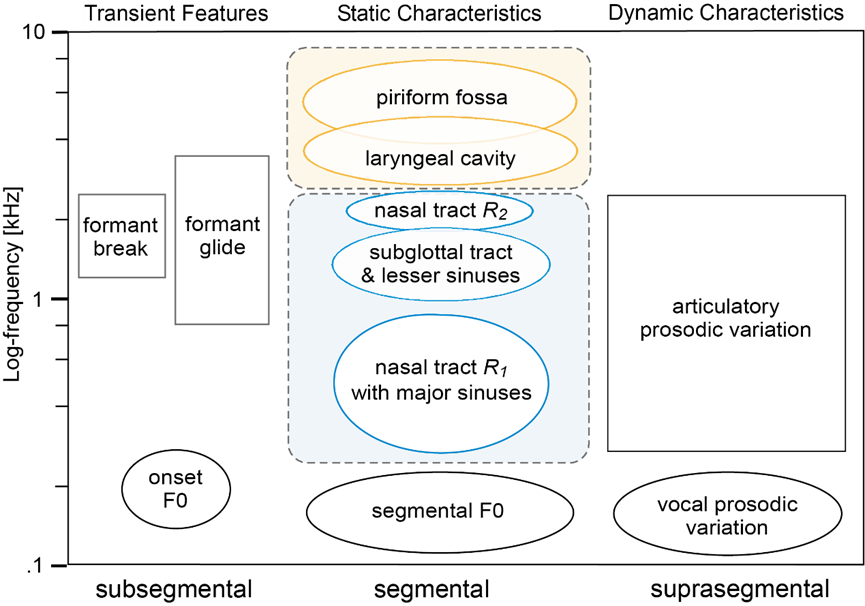
语音的声学特征在个体之间存在差异性,但是仍然保留共享的语音基础信息来被听者通过听觉系统进行感知与分辨。本文讨论了说话者个性化特征的一般时频模式。本文的主要目标是针对高频和低频范围内的说话人个性化频域特征分别进行讨论。为了探讨这种未被充分探索的现象,我们进行了两项实验。首先,我们利用基于传输线模型的声学仿真计算来探索不同下咽腔形状下高频共振的变化。其次,我们分别记录从口腔和鼻孔发出的语音信号,以观察低频谱不规则性的潜在个性化因素。根据我们的研究结果与以往积累的研究相结合,我们提出了一个表达说话人个性化特征的时频模型,该模型提供了说话人的个性化信息在语音频谱图中的大致分布。
06. Improving Zero-shot Cross-domain Slot Filling via Transformer-based Slot Semantics Fusion
论文作者:李宇航,魏笑,司宇珂,王龙标,王晓宝,党建武
论文单位:天津大学
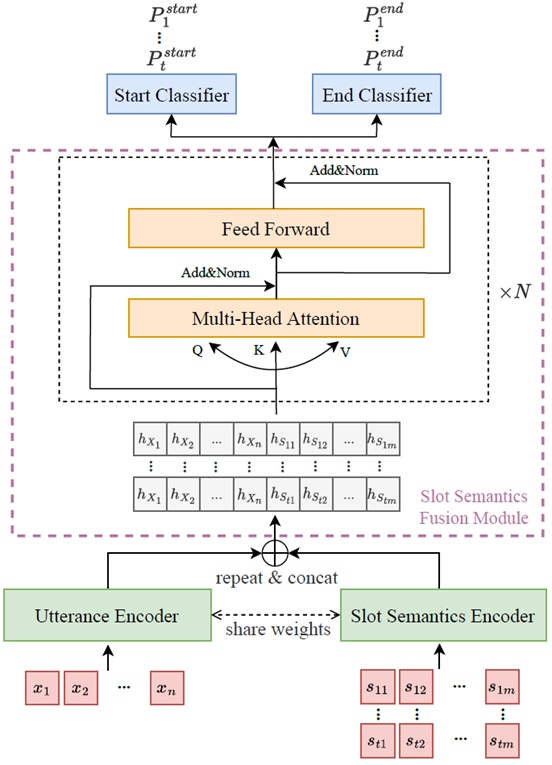
槽填充是任务型对话口语理解中的一个重要组成部分。在现实场景中,由于标注数据的稀缺,零样本槽填充被广泛地研究以将知识从源域迁移到目标域。先前的方法采用槽的文本描述或问题作为槽的语义信息,它们利用槽的文本描述计算相似性得分,或者将任务重新转化为机器阅读理解任务。然而,这些方法并没有充分利用槽语义信息和语句之间的单词级别的依赖关系。在这项研究中,我们提出了一种基于 Transformer 的槽语义融合方法(TSSF)。首先采用共享权重的编码器来得到语句和槽语义的表示。然后,我们设计了基于 Transformer 的槽语义融合模块,用于将槽语义有效地融合进语句表示中。在公共数据集 SNIPS 上的实验结果表明,我们的模型在 slot-F1 指标上显著超过了最先进的模型 6.09%。
07. Auditory Attention Detection in Real-Life Scenarios Using Common Spatial Patterns from EEG
论文作者:杨凯,谢壮,周迪,王龙标,张高燕
论文单位:天津大学,河南大学软件学院,日本北陆先端科学技术大学院大学
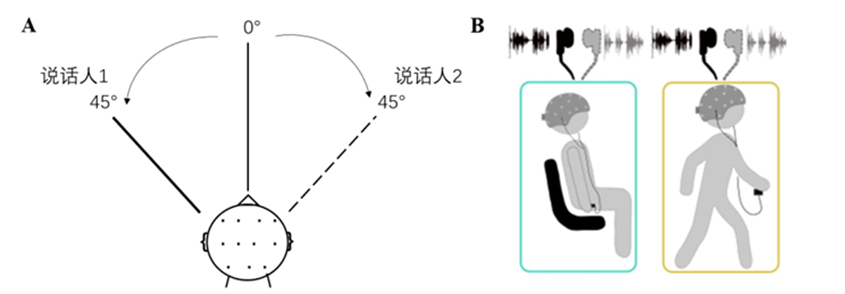
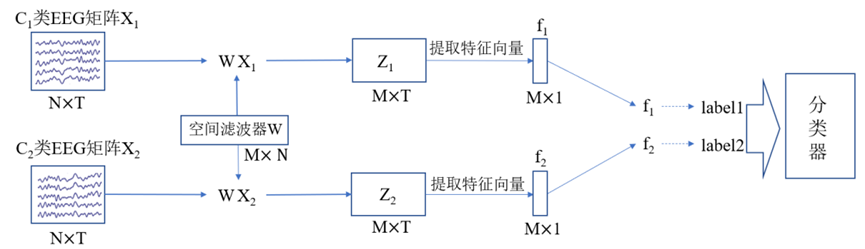
基于脑电图(EEG)的听觉注意力检测方法可用于神经导向的听力设备,以帮助听力损失者提高听力能力。然而,以前的研究大多是在实验室环境下获得EEG数据,这限制了神经导向听力设备的实际应用。在这项研究中,我们采用脑机接口领域常用的共同空间模式(CSP)算法,使用在真实场景中采集的脑电信号执行听觉注意检测,同时区分了受试者不同的行为状态(静坐和行走)。结果显示,当使用不同的决策窗口(1秒-30秒)时,CSP方法可以达到81.3%至87.5%的检测准确率,超越了以往基于线性映射的方法和传统的CNN方法。这证明了CSP算法在实际生活场景中能有效解码人们的注意力。EEG分频段的实验结果表明,δ和β频段在注意力任务中活跃性较高,支持了以往的研究发现。
08. Transvelar Nasal Coupling Contributing to Speaker Characteristics in Non-nasal Vowels
论文作者:朱梓毓,迟雨杰,张昭,本多清志,魏建国
论文单位:天津大学

鼻腔的结构在发音过程中保持稳定且在说话人之间具有个体差异,因此鼻腔共鸣对形成说话人个性化特征具有重要作用。有关鼻腔声学作用的研究主要讨论鼻化元音,鼻腔通过腭咽口(Velopharyngeal port,VPO)连接到主声道上,改变鼻化元音的声学特征。然而,研究者们发现鼻腔共鸣通过经软腭耦合作用(Transvelar nasal coupling)出现在非鼻化元音的发音过程中,并对非鼻化元音的声学特征产生不可忽视的影响。本文设计了一组实验装置进行声学实验,分别记录嘴唇辐射音和鼻孔辐射音。发音语料由非鼻化元音组成。利用频谱分析技术探究非鼻化元音发音时的鼻腔共鸣特征与声学影响。结果表明说话人之间的鼻腔共鸣特征差异分布在2kHz以下:较低频处表现为两个峰值和一个介于二者之间的零点,较高频处表现为分布不均匀的细微零点。此外,鼻孔辐射音的混入会降低嘴唇辐射音输出的元音的第一共振峰值,在不同说话人间降低幅度不同。
09. Effects of Tonal Coarticulation and Prosodic Positions on Tonal Contours of Low Rising Tones: In the Case of Xiamen Dialect
论文作者:胡逸颖,冯卉,赵清华,李爱军
论文单位:天津大学,中国社会科学院
论文资源:http://arxiv.org/abs/2306.02251
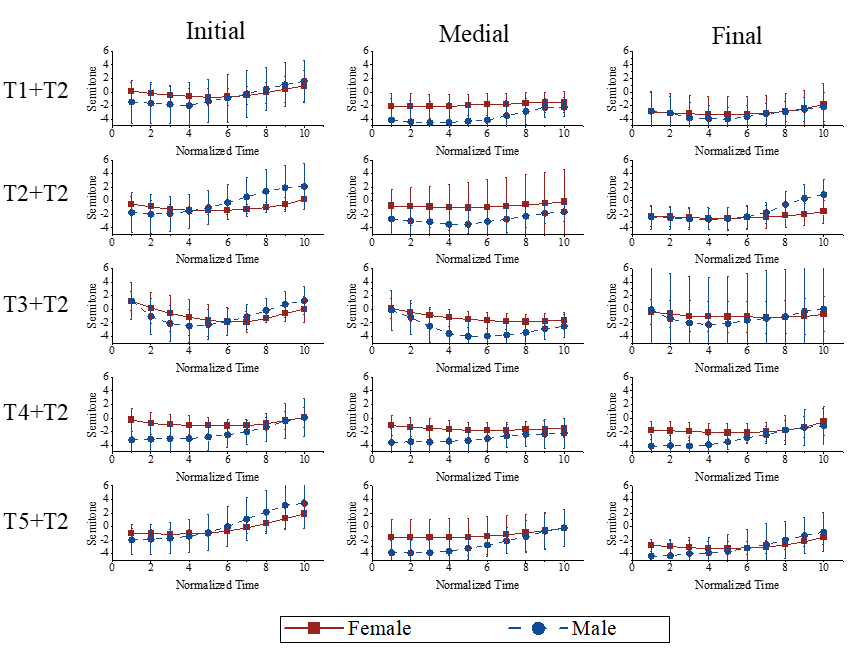
本文研究了声调协同发音和韵律位置对厦门闽南语低升调的影响,并提出了在声调三角形中测量声调曲折程度的量化方法(TCATT: Tonal Contour Analysis in Tonal Triangle)。实验结果表明,厦门闽南语的低升调T2呈现出变为降升调的趋势,且声调协同发音和韵律位置对其的曲折程度均存在显著影响。声调协同发音的影响体现在,当T2前面的音节是一个高平调时,T2会表现为一个降升调,此时其曲折程度最大;当前面的音节是一个低平调或低降调时,T2则表现为低升调。韵律位置的影响体现在,当T2位于句首时,其声调曲线的曲折程度显著大于句中和句末位置的T2曲折程度,且音节时长和声调曲线的曲折程度呈正相关关系。
10. Improving Chinese Mandarin Speech Recognition using Semantic Graph Embedding Regularization
论文作者:林洋仕,路文焕,贾勇哲,马国宁,魏建国
论文单位:天津大学
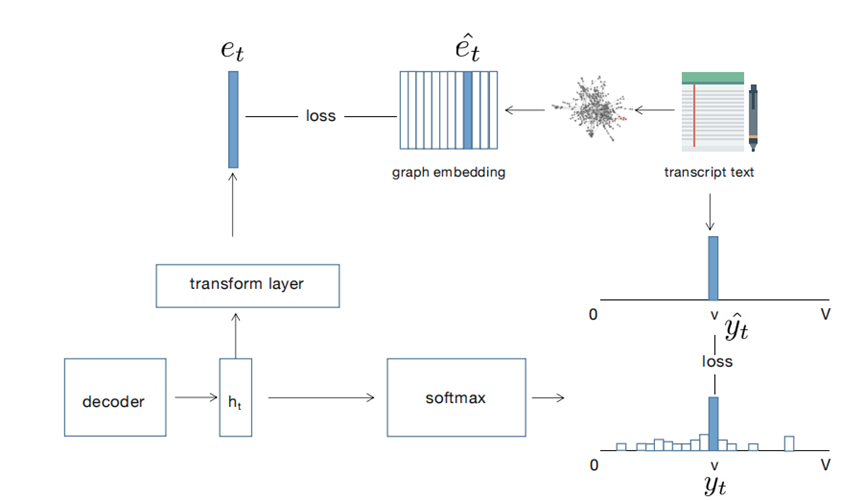
在本文中,我们研究了语义图嵌入在端到端语音识别系统(ASR)中的作用。首先我们介绍了构造汉字语义图的方法,汉字语义图是以汉字字符为节点,由字符组合在句子中出现的频率以及字符组合组成的词汇加权决定边的权重。当汉字语义图构造结束后,我们使用图嵌入方法将图转换为图嵌入向量。该向量用于正则化端到端ASR的decoder权重。我们认为该向量包含的语义信息能够很好的帮助端到端ASR理解语义图中所包含的语义和人为构造词图的规则。我们在Aishell1数据集上进行实验,字符错误率为4.36%,加入语言模型后字符错误率降低为4.25%。实验结果证明该方法能够显著降低端到端ASR的字符错误率。
11. SOT: Self-supervised Learning-Assisted Optimal Transport for Unsupervised Adaptive Speech Emotion Recognition
论文作者:张瑞腾,魏建国,卢绪刚,李永伟,徐君海,金弟,陶健华
论文单位:天津大学,青海民族大学,通信和科学技术研究所,中科院自动化所,清华大学
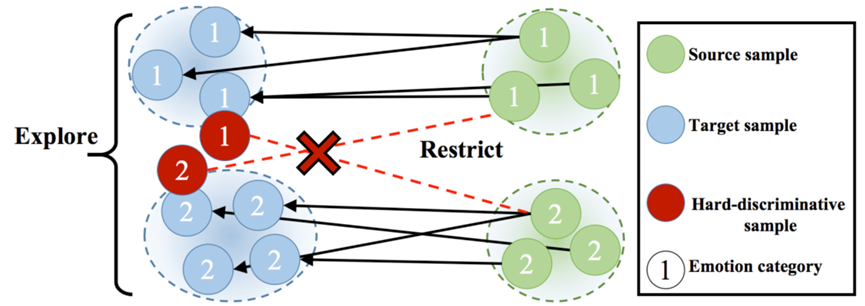
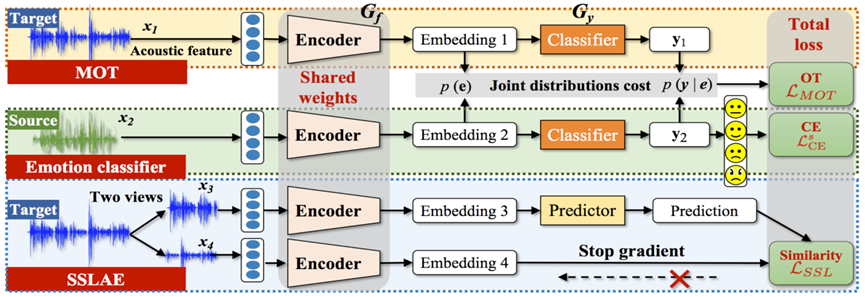
在跨域语音情感识别 (SER) 中,减少不同域之间的全局概率分布距离 (GPDD) 在无监督域适应 (UDA) 中起着至关重要的作用,这可以通过最优传输 (OT) 自然地测量。然而,由于情绪类别的类内差异很大,重叠分布的样本可能会引起负面传输。此外,OT 仅考虑 GPDD,因此在不利用类内分布的局部结构的情况下无法有效地传输难以区分的样本。我们提出了一种用于跨域 SER 的自监督学习 (SSL) 辅助最优传输 (SOT) 算法。首先,我们规范了 OT 的传输耦合以减轻负传输;然后,我们设计了一个 SSL 模块来强调局部类内结构,以帮助 OT 捕获那些不可传输的知识。跨域语音情感识别实验结果表明,SOT 显着优于最先进的无监督域适应算法。
12. Multi-Level Knowledge Distillation for Speech Emotion Recognition in Noisy Conditions
论文作者:刘扬,孙浩钦,陈庚,王庆越,赵振,卢绪刚,王龙标
论文单位:青岛科技大学,日本国立信息通讯研究所,天津大学
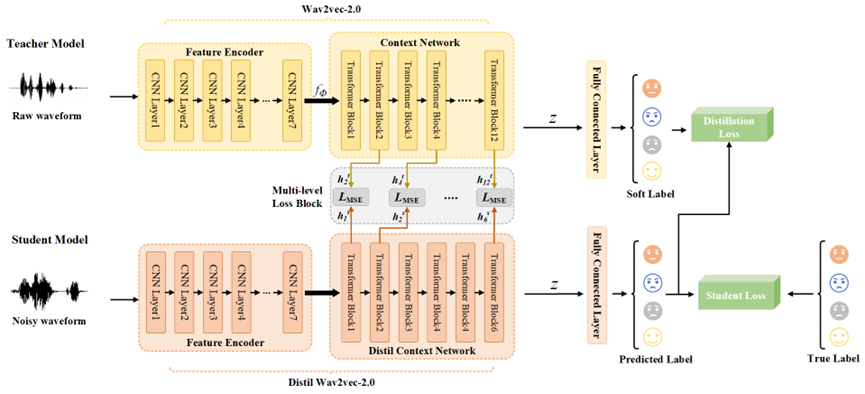
近年来,语音情感识别(SER)的性能已经取得了显著的改善。然而,大多数的算法都是在纯净的语音条件下进行训练和测试的,如何在嘈杂的条件下实现良好的语音情感识别性能,仍然是一项挑战任务。为此,我们提出了一种多层级知识蒸馏的(MLKD)方法,其目的是将知识从在纯净语音上训练的教师模型转移到在嘈杂语音上训练的更简单的学生模型。具体来说,我们使用由wav2vec-2.0提取的干净语音特征作为学习目标,并在噪音条件下训练distil wav2vec-2.0来接近原始wav2vec-2.0的特征提取能力。此外,我们利用原始wav2vec-2.0的多层级知识来监督distil wav2vec-2.0的每个中间层的输出。本文在IEMOCAP语料库和Noisex-92噪声库中进行了实验。实验结果表明,与基线系统相比,在所有类型的噪声下,本文提出的方法在UA上的提高平均达到18.23%,显示了有竞争力的结果。