下载Apache Pig
首先,从以下网站下载最新版本的Apache Pig,下载Pig步骤取自W3C:Pig安装教程
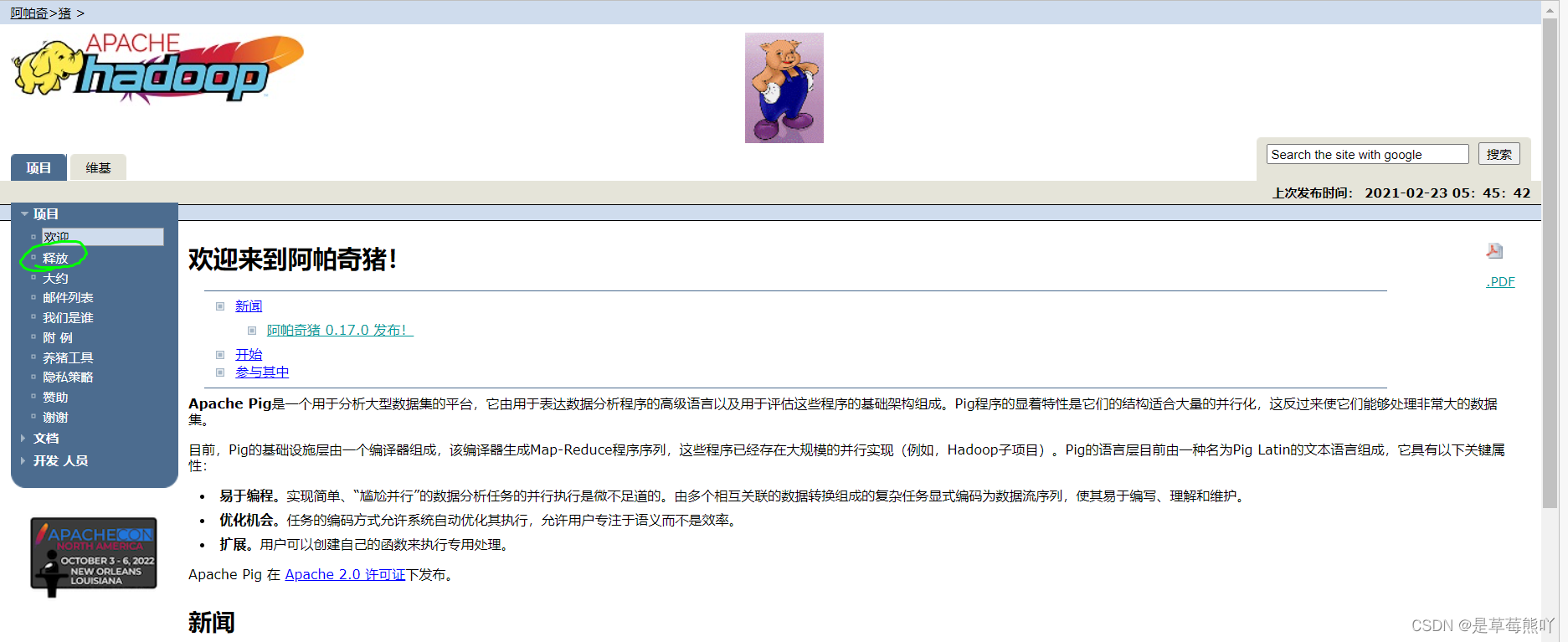
步骤1
打开Apache Pig网站的主页。在News部分下,点击链接release page(释放),如下面的快照所示。
步骤2
点击指定的链接后,你将被重定向到 Apache Pig Releases 页面。在此页面的Download(下载)部分下,单击链接,然后你将被重定向到具有一组镜像的页面。
步骤3
选择并单击这些镜像中的任一个,如下所示。

步骤4
这些镜像将带您进入 Pig Releases 页面。 此页面包含Apache Pig的各种版本。 单击其中的最新版本。
步骤5
在这些文件夹中,有发行版中的Apache Pig的源文件和二进制文件。下载Apache Pig 0.16, pig0.16.0-src.tar.gz 和 pig-0.16.0.tar.gz 的源和二进制文件的tar文件。
安装Apache Pig
下载Apache Pig软件后,按照以下步骤将其安装在Linux环境中。
步骤一
登录hadoop用户,将pig-0.17.0.tar.gz移动至用户目录下解压
tar -xvf pig-0.17.0.tar.gz
步骤二
进入.profile文件配置环境变量:vim ~/.profile,添加:
export PIG_HOME=/home/hadoop/pig-0.17.0
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
在已存在的PATH变量后面$PATH前面添加
$PIG_HOME/bin: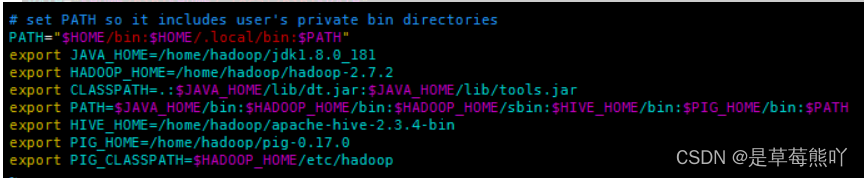
步骤三
保存退出输入指令:source ~/.profile,使环境变量生效
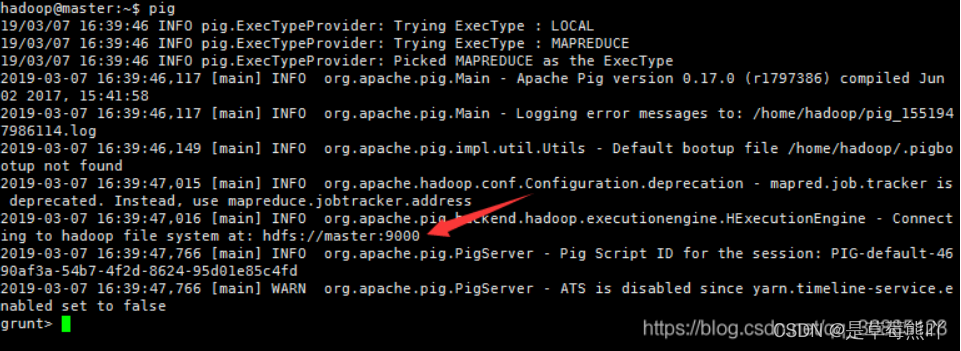
pig 本地启动:pig -x local
pig MapReduce启动:
1、start-all.sh启动hadoop集群
2、mr-jobhistory-daemon.sh start historyserver开启作业历史服务
3、输入jps指令查看:

4、输入pig或者pig -x mapreduce启动pig