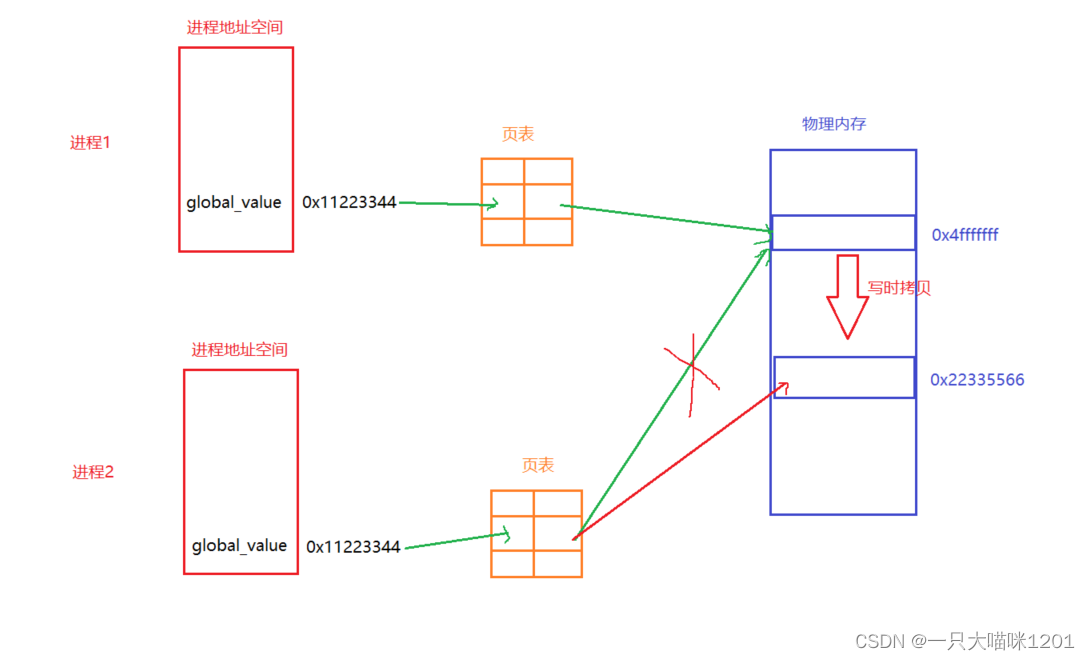
定义
- 设记录表L=(R1 R2…其中Ri(L<=i<=n)为记录, 对给定的某个值k,
在表L中确定key= k的记录的过程,称为查找。 - 若表Lz中存在记录Ri de key = k,记为Ri.key,则查找成功,返回该记录在表L中的序号i(或Ri的地址),否者(查找失败)返回0(或空地址NULL )
查找方法有顺序查找、折半查找、分块查找、Hash表查找等
查找算法的优劣影响到计算的使用效率,应根据应用场合选择响应的查找算法。
对于查找算法,主要分析其T(n)(时间复杂度),一般以“平均查找长度”来衡量T(n)
平均查找长度ASL (Average Search Length) :对给定k,查找表L
中记录比较次数的期望值(或平均值),即:

Pi为查找Ri的概率。等概率情况下Pi=1/n; Ci为查找Ri时key的比较次数(或查找次数)。
哈希表
理想的查找方法是:对给定的k,不经任何比较便能获取所需的记录,其查找的时间复杂度为常数级0©。
这就要求在建立记录表的时候,确定记录的key与其存储地址之间的关系f,即使key与记录的存放地址H相对应:

当要查找key=k的记录时,通过关系就可得到相应记录的地址而获取记录,从而免去了key的比较过程。
这个关系f就是所谓的Hash函数(或称散列函数、杂凑函数) ,记为
H(key)。
它实际上是一个地址映象函数,其自变量为记录的key,函数值为记录的存储地址(或称Hash地址)。
不同的key可能得到同一个Hash地址,即当key;≠key,时, 可能有
H(key)=H(key2),此时称key 和key2为同义词。这种现象称为“冲突"
或“碰撞”,因为一个数据单位只可存放一条记录,
一般, 选取Hash函数只能做到使冲突尽可能少,却不能完全避免。这就要求在出现冲突之后,寻求适当的方法来解决冲突记录的存放问题。
一般, 选取Hash函数只能做到使冲突尽可能少,却不能完全避免。这就要求在出现冲突之后,寻求适当的方法来解决冲突记录的存放问题。

选取(或构造) Hash函数的方法很多,原则是尽可能将记录均匀分布,以减少冲突现象的发生。以下介绍几种常用的构造方法。
直接地址法
平方取中法
叠加法
保留除数法
随机函数法
保留除数法
又称质数除余法,设Hash表空间长度为m,选取-个不大于m的最大质数p,令:H(key)=key%p
表的填充因子a:0.7-0.8左右,(需要存储的的数据占存储空间的比例)
a = n / m (n :需要存储的数据个数)
链式hash的实现
hash.c
#include "hash.h"
hash* hash_creat(){
hash *HT;
if((HT = (hash *)malloc(sizeof(hash)))== NULL){
printf("HT malloc is failed \n");
return NULL;
}
memset(HT,0,sizeof(hash));
return HT;
}
int hash_insert(hash *HT, datatype key){
linklist p,q;
if(HT == NULL){
printf("HT is NULL\n");
return -1;
}
if((p = (linklist)malloc(sizeof(listnode))) == NULL){
printf("HT is NULL\n");
return -1;
}
p->key = key;
p->value = key % N;
p->next = NULL;
q = &(HT->data[key % N]);
while (q->next && q->next->key < p->key)
{
q = q->next;
}
p->next = q->next;
q->next = p;
printf("key = %d\n",key);
return 0;
}
linklist hash_search(hash *HT,datatype key){
linklist p;
if(HT == NULL){
printf("HT is NULL\n");
return NULL;
}
p = &(HT->data[key%N]);
while (p->next && p->next->key < key)
{
p = p->next;
}
if(p->next == NULL){
return NULL;
}else{
printf("found2\n");
return p->next;
}
return NULL;
}
hash.h
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include “hash.h”
hash * hash_create() {
hash * HT;
if ((HT = (hash *)malloc(sizeof(hash))) == NULL) {
printf("malloc failed\n");
return NULL;
}
memset(HT, 0, sizeof(hash));
return HT;
}
int hash_insert(hash *HT, datatype key) {
linklist p, q;
if (HT == NULL) {
printf("HT is NULL\n");
return -1;
}
if ((p = (linklist)malloc(sizeof(listnode))) == NULL) {
printf("malloc failed\n");
return -1;
}
p->key = key;
p->value = key % N;
p->next = NULL;
q = &(HT->data[key % N]);
while (q->next && q->next->key < p->key ) {
q = q->next;
}
p->next = q->next;
q->next = p;
return 0;
}
linklist hash_search(hash *HT, datatype key) {
linklist p;
if (HT == NULL) {
printf("HT is NULL\n");
return NULL;
}
p = &(HT->data[key % N]);
while (p->next && p->next->key != key) {
p = p->next;
}
if (p->next == NULL) {
return NULL;
} else {
printf("found\n");
return p->next;
}
}
main.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "hash.h"
int test();
int main(){
printf("main start\n");
test();
return 0;
}
int test(){
printf("test start\n");
hash *HT;
datatype key;
int data[] = {24,35,74,29,36,96,48,55,6,13,62};
int i;
linklist r;
if((HT = hash_creat()) == NULL){
printf("HT is NULL\n");
return -1;
}
for(i = 0; i<sizeof(data)/sizeof(int); i++){
hash_insert(HT,data[i]);
}
printf("input:");
scanf("%d",&key);
r = hash_search(HT,key);
if(r == NULL){
printf("not found\n");
}else{
printf("found:%d %d\n",key,r->key);
}
return 0;
}