在许多介绍图像识别任务的介绍中,通常使用着名的MNIST数据集。
最近我们被客户要求撰写关于图像识别的研究报告,包括一些图形和统计输出。但是,这些数据存在一些问题:
1.太简单了。例如,一个简单的MLP模型可以达到99%的准确度,而一个2层CNN可以达到99%的准确度。
2.它被过度使用。从字面上看,每台机器学习入门文章或图像识别任务都将使用此数据集作为基准。但是,因为获得近乎完美的分类结果非常容易,所以它的实用性会受到打折,并且对于现代机器学习/ AI任务并不真正有用。
因此,出现Fashion-MNIST数据集。该数据集是作为MNIST数据的直接替代而开发的,其意义在于:
1.尺寸和风格相同:28x28灰度图像
2.每个图像与10个类中的1个相关联,即:
0:T恤/上衣,
1:裤子,
2:套头衫,
3:连衣裙,
4 :外套,
5:凉鞋,
6:衬衫,
7:运动鞋,
8:背包,
9:靴
3. 60000训练样本和10000个测试样本,以下是一些样本的截图:

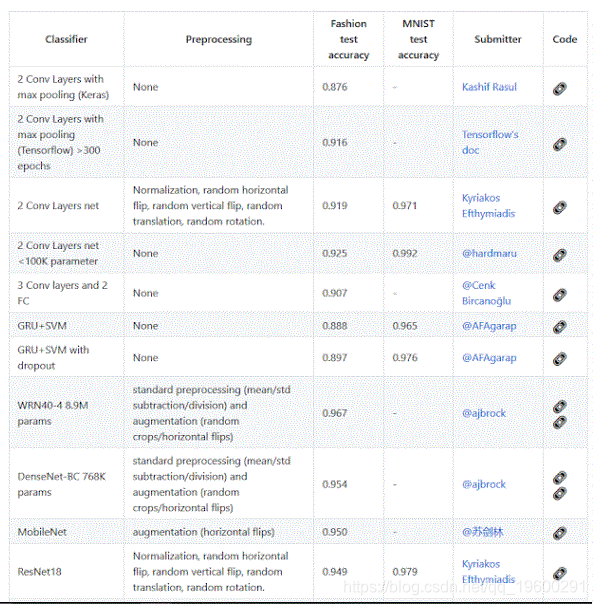
自从它出现以来,已经有多份提交文件来对这些数据进行基准测试,其中一些能够达到95%以上的准确度 。
我也试图用keras来对这个数据进行基准测试。keras是构建深度学习模型的高级框架,在后端选择TensorFlow,Theano和CNTK。它很容易安装和使用。对于我的应用程序,我使用了CNTK后端。
在这里,我将以两个模型为基准。一种是层结构为256-512-100-10的MLP,另一种是类VGG的CNN。
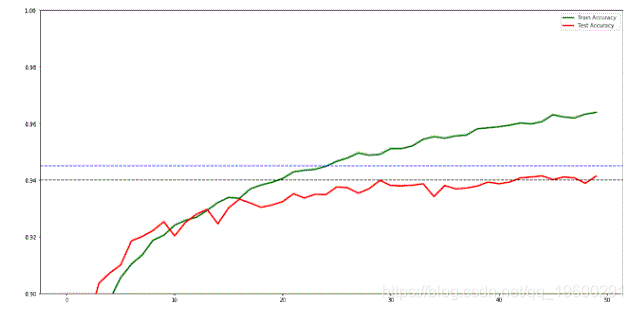
第一个模型在100个历元后的测试数据上达到了[0.89,0.90]的精度,而后者达到了45个时期后的测试数据的精度> 0.94。
我们先用tSNE来看它。据说tSNE是最有效的降纬工具。
我使用了1000个样本来快速运行。如果您的PC速度足够快并且有时间,则可以针对完整数据集运行tSNE。
为了建立自己的网络,我们首先导入一些库

该模型在大约100个时期的测试数据集上达到了近90%的准确度。现在,我们来构建一个类似VGG的CNN模型。我们使用类似于VGG的体系结构,但仍然非常不同。由于图形数据很小,如果我们使用原始VGG体系结构,它很可能会过度拟合,并且在测试数据时表现不佳,这些数据在上面列出的公开提交的基准测试中观察到。在keras中构建这样一个模型是非常容易的:
这个模型有150万个参数。我们可以调用'fit'方法来训练模型:
model3_fit=model3.fit(X_train, Y_train2, validation_data = (X_test, Y_test2), epochs=50, verbose=1, batch_size=500)
经过40次以后,这个模型在测试数据上获得了0.94的精度。显然,这个模型也存在过度拟合问题。我们稍后会解决这个问题。