文章目录
- 一、线性模型
- 二、实例
- 1.pytorch求导功能
- 2.简单线性模型(人工数据集)
- 来源
一、线性模型
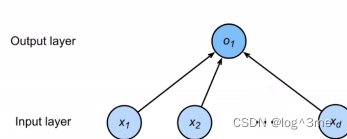
一个简单模型:假设一个房子的价格由卧室、卫生间、居住面积决定,用x1,x2,x3表示。
那么房价y就可以认为y=w1x1+w2x2+w3x3+b,w为权重,b为偏差。
第一步

线性模型可以看做是单层(带权重的层是1层)神经网络。
第二步:
定义loss,衡量预估质量:真实值和预测值的差距

这里带1/2是方便求导的时候把2消去。
训练数据:收集数据来决定权重和偏差
训练损失:loss=1/n∑[(真实值-预测值(xi和权重的内积-偏差))平方]。目标是找到最小的loss
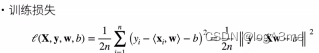
第三步:优化
优化方法:梯度下降。先挑选一个初值w0,之后不断更新w0使他接近最优解。更新方法是wt=wt-1 - 学习速率梯度。
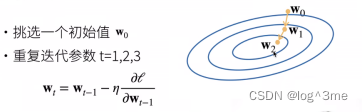
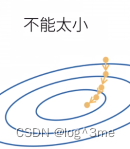
Learning rate不能太小(到达一个点要走很多步),也不能太大(一直震荡没有真的下降)

在整个训练集上梯度下降太贵,跑一次模型可能要数分钟/小时。所以采用小批量随机梯度下降,随机采样b个样本用这b个样本来近似损失。b不能太大也不能太小
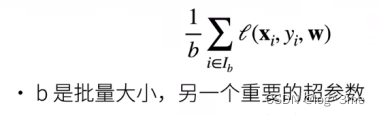
二、实例
1.pytorch求导功能
代码如下:
# 自动求导
import torch
# 假设对函数y=2xT x关于列向量求导
x = torch.arange(4.0)
# 算y关于x的梯度之前,需要一个地方来存储梯度
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
print(x.grad) # 默认值是None y关于x的导数存在这里
y=2*torch.dot(x,x)
y.backward() # 求导
print(x.grad)
print(x.grad==4*x)
# 在默认情况下,PyTorch会累积梯度,需要清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()
print(x.grad)
x.grad.zero_()
y=x*x
u=y.detach()# 把y当成常数而不是x的函数
z=u*x
z.sum().backward()
print(x.grad==u)
2.简单线性模型(人工数据集)
代码如下:
# 构建人工数据集(好处是知道w和b)
# 根据w=[2,-3.4] b=4.2 和噪声生成数据集和标签 y=Xw+b+噪声
import numpy as np
import torch
from torch import nn
from torch.utils import data
# 生成数据
def synthetic_data(w, b, num_examples):
"""生成y=Xw+b+噪声"""
X = np.random.normal(0, 1, (num_examples, len(w))) # 均值为0,方差为1,num_ex个样本,列数=w的个数
y = np.dot(X, w) + b # y=Xw+b
y += np.random.normal(0, 0.01, y.shape) # 加上随机噪音
x1 = torch.tensor(X, dtype=torch.float32) # 把np转化为torch
y1 = torch.tensor(y, dtype=torch.float32)
return x1, y1.reshape((-1, 1)) # 列向量反馈
# 读取数据
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train) # shuffle:是否需要随机打乱
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
# 使用iter构造Python迭代器,并使用next从迭代器中获取第一项。
print(next(iter(data_iter)))
# 定义模型
# nn是神经网络的缩写
net = nn.Sequential(nn.Linear(2, 1)) # 输入维度是2 输出是1 sequential相当于一个list of layer
# 初始化参数 net[0]访问这个layer
net[0].weight.data.normal_(0, 0.01) # normal:使用正态分布替换weight的值,均值为0,方差为0.01
net[0].bias.data.fill_(0) # bias直接设为0
# 定义loss:mseloss类
loss = nn.MSELoss()
# 定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.03) # net.patameters():所有参数 ,lr:learning rate
# 训练
num_epochs = 3
for epoch in range(num_epochs): # 对所有数据扫一遍
for X, y in data_iter: # 拿出一个批量大小的x和y
l = loss(net(X), y) # x和y的小批量损失
trainer.zero_grad() # 梯度清零
l.backward() # 计算梯度
trainer.step() # 模型更新
l = loss(net(features), labels) # 计算损失
print(f'epoch {epoch + 1}, loss {l:f}')
来源
b站 跟李沐学AI 动手学深度学习v2 08