FFN Fusion: Rethinking Sequential Computation in Large Language Models
代表模型:Llama-3.1-Nemotron-Ultra-253B-v1
1. 摘要
本文介绍了一种名为 FFN Fusion 的架构优化技术,旨在通过识别和利用自然并行化机会来减少大型语言模型(LLMs)中的顺序计算。研究发现,移除特定注意力层后剩余的前馈网络(FFN)层序列通常可以并行化,且对准确性影响最小。通过将这些序列转换为并行操作,显著降低了推理延迟,同时保留了模型行为。作者将这种技术应用于 Llama-3.1-405B-Instruct,创建了一个名为 Llama-Nemotron-Ultra-253B-Base 的高效模型,该模型在推理延迟上实现了 1.71 倍的速度提升,每令牌成本降低了 35 倍,同时在多个基准测试中保持了强大的性能。
2. 引言
大型语言模型(LLMs)已成为变革性技术,但其计算需求已成为部署成本和资源需求的根本瓶颈。现有的优化技术如量化、剪枝和专家混合(MoE)各自面临挑战。本文提出 FFN Fusion,通过识别 FFN 层中的计算独立性模式,实现多 GPU 上的并行执行,提高硬件利用率。
3. 预备知识
Transformer 基础
LLMs 通常基于 Transformer 架构,由一系列顺序块组成,每个块包含注意力层和 FFN 层。FFN 层使用 SwiGLU 模块,定义为: 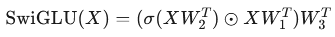
其中,σ 是 SiLU 激活函数,
Puzzle 框架
Puzzle 是一种神经架构搜索(NAS)框架,通过剪枝或重新配置每个 Transformer 块来优化训练后的 LLM 的推理效率。Puzzle 通常会移除许多注意力层,留下连续的 FFN 层序列。
4. FFN Fusion 方法
关键洞察
FFN Fusion 的核心思想是,移除注意力层后,连续的 FFN 层序列可以被并行化。具体来说,多个顺序 FFN 层可以融合成一个更宽的层,从而实现简单的并行执行。
理论基础
定理 3.1 表明,多个 FFN 函数的和等价于一个单一的 FFN 函数,其权重矩阵是原始 FFN 权重矩阵的拼接。这使得多个 FFN 层可以融合为一个更宽的层。
效率动机与分析
LLMs 的设计通常是顺序块,随着模型规模的增大,块的大小和数量增加。通过减少计算图的深度,可以减少同步时间,提高硬件利用率。
块依赖分析
通过计算块之间的依赖关系,识别出适合并行化的 FFN 序列。依赖矩阵 M 的构造基于块 j 在移除块 i 后的贡献变化,量化块之间的依赖关系。
5. 大规模模型的 FFN Fusion 应用
从 Llama-405B 到 Ultra-253B-Base
通过 Puzzle 搜索结果,作者从 Llama-405B 派生出一个 253B 参数的基线模型,该模型移除了许多注意力层,留下 50 个连续的 FFN 层块。应用 FFN Fusion 后,这些层被融合为更少的层,显著减少了模型深度。
额外训练
为了恢复性能,作者使用知识蒸馏(KD)对融合后的模型进行微调。结果显示,融合后的模型在 MMLU 和 MT-Bench 等基准测试中的性能得到了恢复甚至提升。
效率提升
Ultra-253B-Base 在推理延迟上实现了 1.71 倍的速度提升,每令牌成本降低了 35 倍,同时在多个基准测试中匹配或超过了原始 Llama-405B 的性能。
6. 额外的实验研究
FFN Fusion 在 70B 规模模型中的应用
作者在 Llama-3.1-70B-Instruct 的派生模型上应用 FFN Fusion,结果表明,随着融合强度的增加,模型深度减少,准确性略有下降,但通过知识蒸馏可以恢复性能。
移除 FFN 层与 FFN Fusion 的比较
与直接移除 FFN 层相比,FFN Fusion 在保持模型质量方面具有明显优势。移除 FFN 层会导致显著的准确性下降,而融合则通过保留所有参数在一个并行模块中,最小化了性能损失。
FFN 序列中最后一层的敏感性
实验表明,融合 FFN 序列中的最后一层往往会导致更大的准确性下降,因此通常选择跳过这些层以实现高效的融合。
融合可解释性
通过分析层输入和输出之间的关系,作者解释了 FFN Fusion 的可行性,并指出融合区域的层间依赖性较低,使得融合对模型行为的影响较小。
7. 块并行化
方法
作者扩展了块依赖分析,识别出适合并行化的完整 Transformer 块序列。通过贪心算法选择依赖性较低的块序列进行并行化。
结果
实验结果表明,完整块并行化比 FFN Fusion 更具挑战性,因为完整块之间的依赖性更强。尽管如此,某些块序列仍然可以并行化,从而提高推理吞吐量。
8. 结论
FFN Fusion 是一种有效的优化技术,可以显著减少 LLMs 的顺序计算,提高推理效率。通过在不同规模的模型上进行广泛实验,作者证明了 FFN Fusion 的有效性,并指出了未来研究方向,包括模型可解释性、新架构设计和扩展到 MoE 模型等。
整理
技术关系图:

核心技术表
| 技术名称 | 描述 | 优势 | 应用场景 |
|---|---|---|---|
| FFN Fusion | 通过识别 FFN 层中的计算独立性模式,将多个顺序 FFN 层融合为一个更宽的层,实现并行化。 | 显著降低推理延迟,减少模型深度,提高硬件利用率,保持模型性能。 | 优化大型语言模型(LLMs),特别是在移除注意力层后的 FFN 序列。 |
| Puzzle 框架 | 一种神经架构搜索(NAS)方法,用于优化推理效率,通过剪枝或重新配置 Transformer 块。 | 移除冗余的注意力层,生成适合 FFN Fusion 的模型结构。 | 作为 FFN Fusion 的前置步骤,优化模型架构。 |
| 注意力剪枝 | 移除模型中的注意力层,减少模型深度,生成连续的 FFN 层序列。 | 降低计算复杂度,提高硬件利用率,为 FFN Fusion 提供基础。 | 为 FFN Fusion 提供连续的 FFN 层序列。 |
| 块依赖分析 | 通过量化块之间的依赖关系,识别适合并行化的区域。 | 提供模型中适合并行化的区域的可视化和量化依据。 | 模型架构优化,识别适合 FFN Fusion 或完整块并行化的区域。 |
| 知识蒸馏(KD) | 使用知识蒸馏从原始模型中恢复或提升融合后的模型性能。 | 提高模型准确性,尤其是在融合或剪枝后。 | 模型微调,特别是在应用 FFN Fusion 后恢复性能。 |
| 完整块并行化 | 尝试将完整的 Transformer 块(包含注意力和 FFN)并行化。 | 进一步提高推理吞吐量,特别是在大规模模型部署中。 | 大规模模型部署,探索更高的并行化潜力。 |