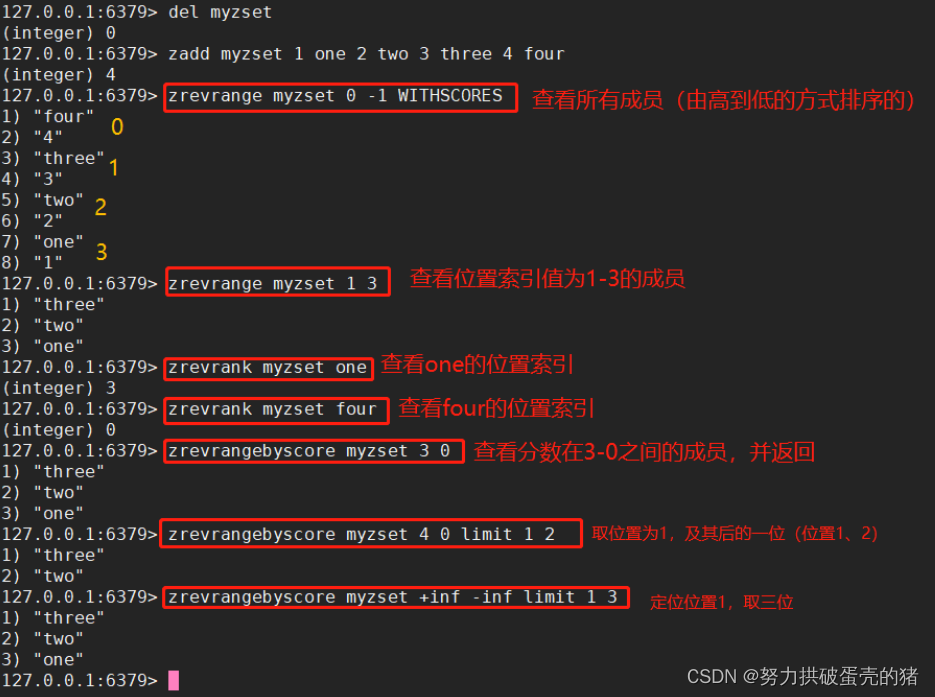
一、知识图谱简单介绍




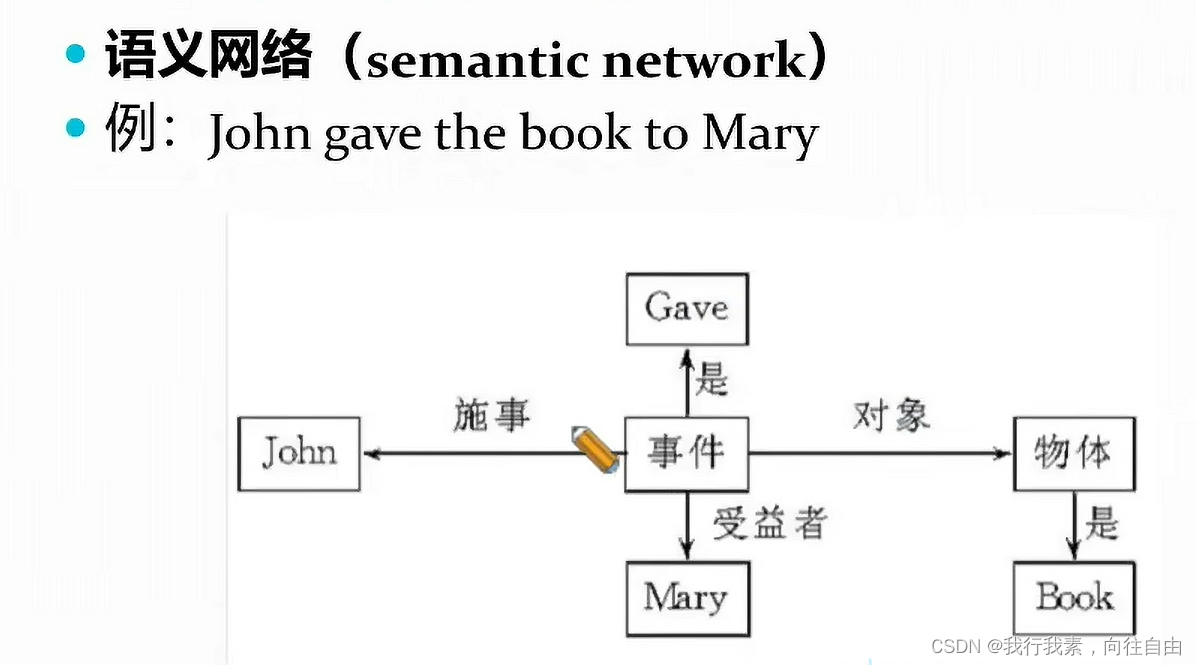
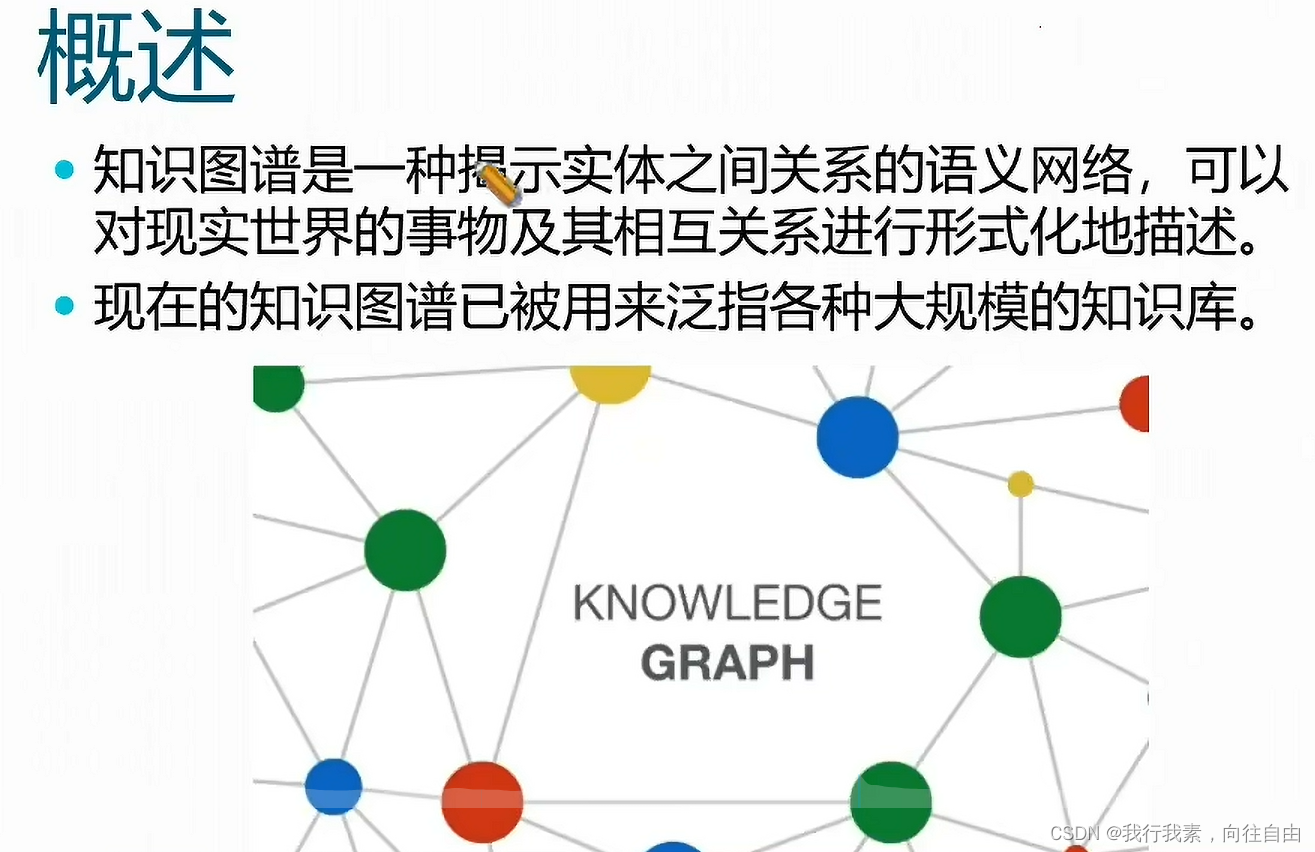
二、知识图谱的构建



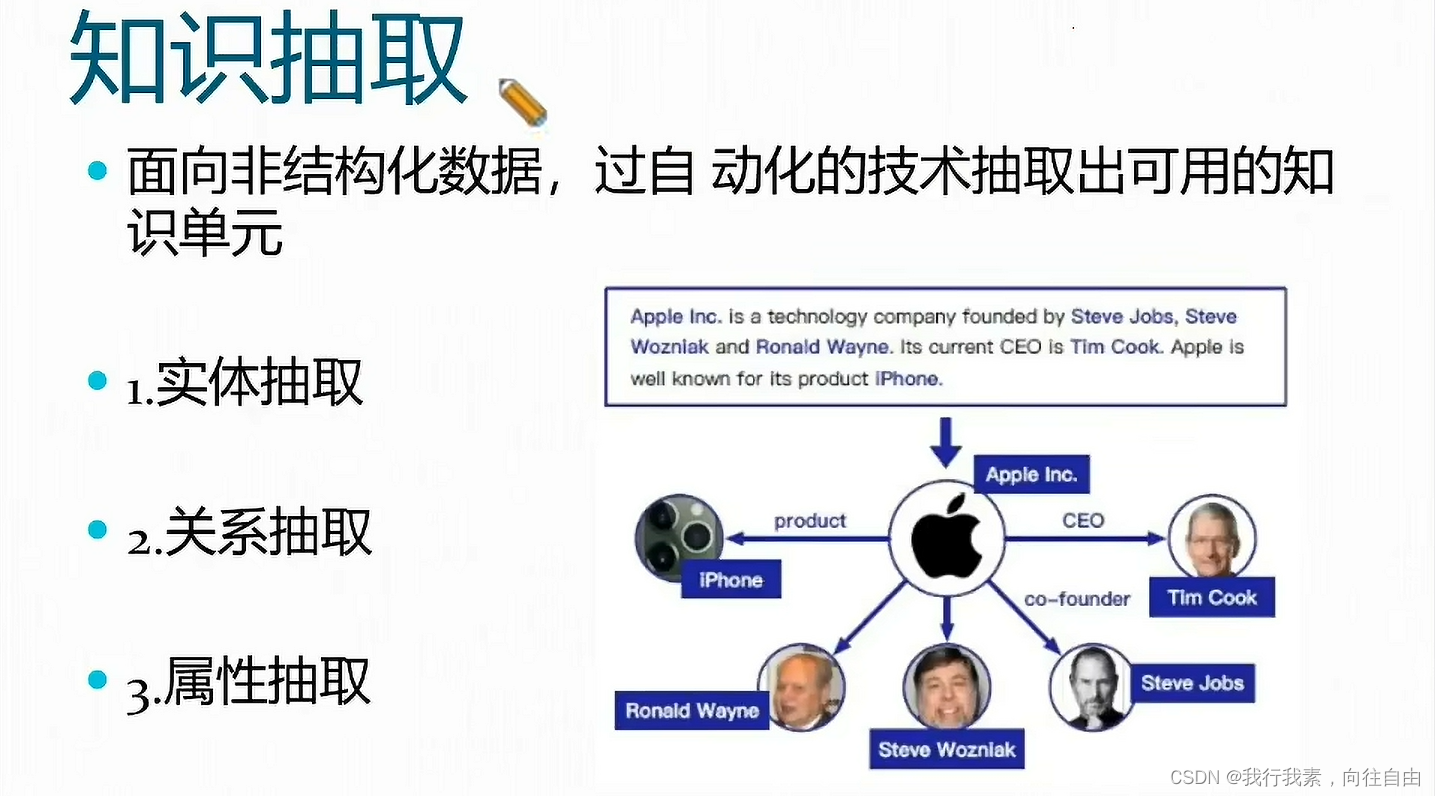






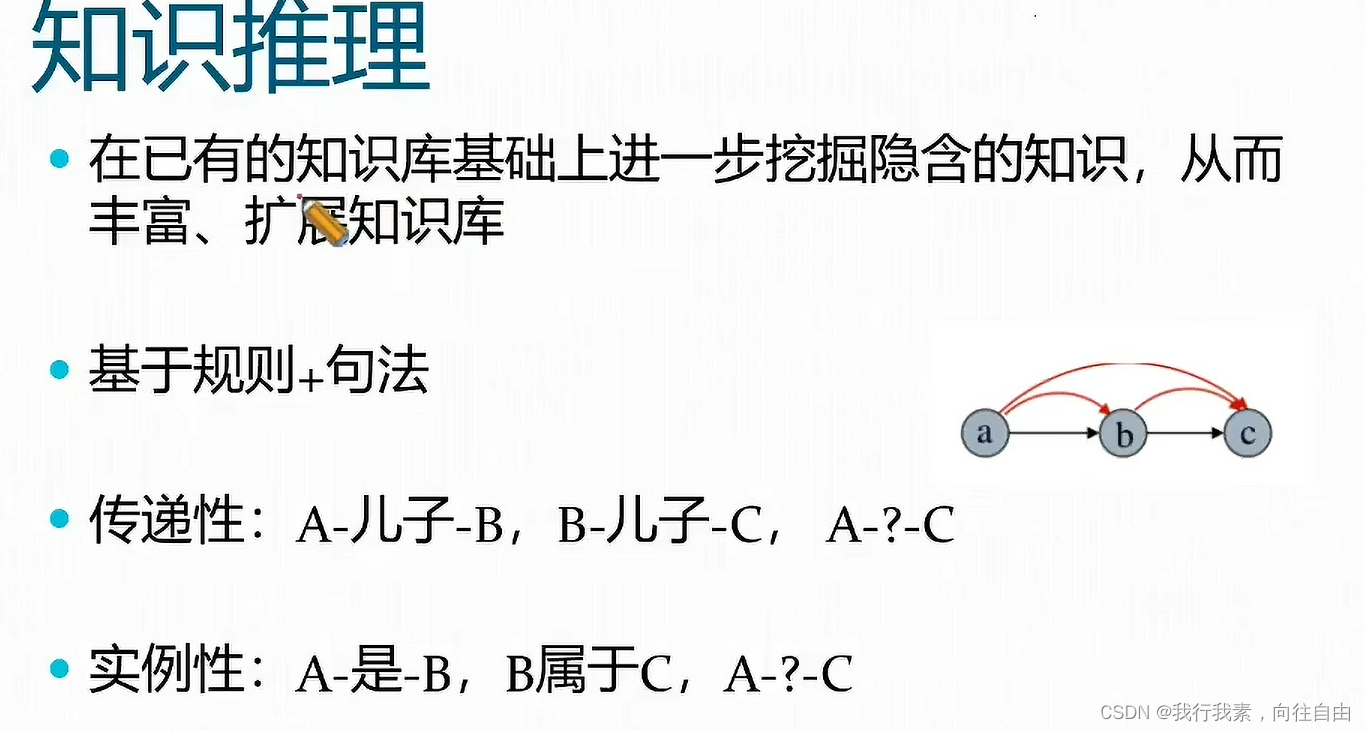






三、知识图谱问答方案
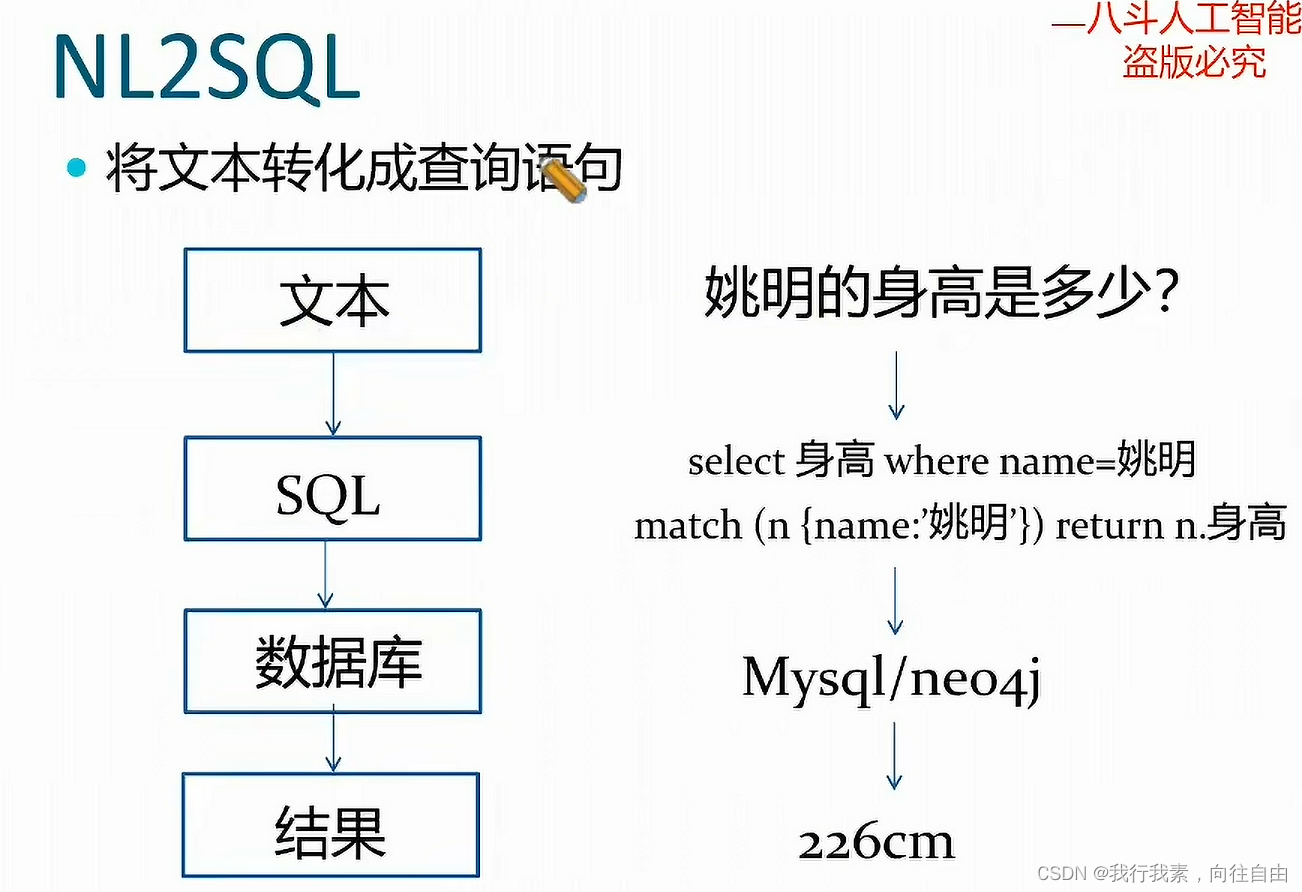
NL2SQL:自然语言转为SQL语句


bulid_graph.py
"""知识图谱"""
#三元组:实体-关系-实体 实体-属性-属性值
import re,json
from py2neo import Graph
from collections import defaultdict
"""读取三元组,并将数据写入neo4j"""
#连接图数据库
graph=Graph("http://localhost:7474",auth=("neo4j","Zmj123456!"))
attribute_data=defaultdict(dict)
relation_data=defaultdict(dict)
label_data={}
#有的实体后面有括号,里面的内容可以作为标签
#提取到标签后,把括号部分删除
def get_label_then_clean(x,label_data):
if re.search("(.+)",x):
label_string=re.search("(.+)",x).group()
for label in ["歌曲","专辑","电影","电视剧"]:
if label in label_string:
x=re.sub("(.+)","",x)#括号内的内容删除掉,因为括号里面是特殊字符会影响cypher的语句运行
label_data[x]=label
else:
x=re.sub("(.+)","",x)
return x
#读取实体-关系-实体三元组文件
with open("data/01test.doc",encoding="utf8") as f:
for line in f:
head,relation,tail=line.strip().split('\t')#取出三元组
head=get_label_then_clean(head,label_data)
relation_data[head][relation]=tail
#读取实体-属性-属性值三元组
with open("data/01triplets_enti_attr_value.doc",encoding='utf8') as f:
for line in f:
entity,attribute,value=line.strip().split('\t')#取出三元组
entity=get_label_then_clean(entity,label_data)
attribute_data[entity][attribute]=value
#构建cypher语句
cypher=""
in_graph_entity=set()
for i,entity in enumerate(attribute_data):
#为所有的实体增加一个名字属性
attribute_data[entity]["NAME"]=entity
#将一个实体的所有的属性拼接成一个类似于字典的表达式
text="{"
for attribute,value in attribute_data[entity].items():
text+="%s:\'%s\',"%(attribute,value)
text=text[:-1]+"}"#最后一个逗号替换成大括号
if entity in label_data:
label=label_data[entity]
#带标签的实体构造语句
cypher+="CREATE (%s:%s %s)"%(entity,label,text)+"\n"
else:
"不带标签的实体构造语句"
cypher+="CREATE (%s %s)"%(entity,text)+"\n"
in_graph_entity.add(entity)
#构造关系语句
for i in enumerate(relation_data):
#有可能实体只有和其他实体的关系,但没有属性,为这样的实体增加一个名称属性,便于在图上认出
if head not in in_graph_entity:
cypher += "CREATE (%s {NAME:'%s'})"%(head,head)+'\n'
in_graph_entity.add(head)
for relation,tail in relation_data[head].items():
#有可能实体只有和其他实体的关系,但没有属性,为这样的实体增加一个名称属性,便于在图上认出
if tail not in in_graph_entity:
cypher +="CREATE (%s {NAME:'%s'})"%(tail,tail)+"\n"
in_graph_entity.add(tail)
#关系语句
cypher +="CREATE (%s)-[:%s]->(%s)"%(head,relation,tail)+"\n"
print(cypher)
#执行建表脚本
graph.run(cypher)
#记录我们图谱里都有哪些实体,哪些属性,哪些关系,哪些标签
data=defaultdict(set)
for head in relation_data:
data["entitys"].add(head)
for relation,tail in relation_data[head].items():
data["relations"].add(relation)
data["entitys"].add(tail)
for enti,label in label_data.items():
data["entitys"].add(enti)
data['labels'].add(label)
for enti in attribute_data:
for attr,value in attribute_data[enti].items():
data['entitys'].add(enti)
data['attributes'].add(attr)
data=dict((x,list(y))for x,y in data.items())
with open('data/kg_schema.json','w',encoding='utf8') as f:
f.write(json.dumps(data,ensure_ascii=False,indent=2))
graph_qa_base_on_sentence_match.py
"""使用文本匹配方式进行知识图谱的应用"""
import itertools,json
import re
import pandas
from py2neo import Graph
from collections import defaultdict
class GraphQA:
def __init__(self):
self.graph=Graph("http://localhost:7474",auth=("neo4j","Zmj123456!"))
schema_path="kg_schema.json"
templet_path="question_templet.xlsx"
self.load(schema_path,templet_path)
print('知识图谱问答系统加载完毕!\n=================')
#加载模板
def load(self,schema_path,templet_path):
self.load_kg_schema(schema_path)
self.load_question_templet(templet_path)
return
#加载图谱信息
def load_kg_schema(self,path):
with open(path,encoding='utf8') as f:
schema=json.load(f)
self.relation_set=set(schema['relations'])
self.entity_set=set(schema['entitys'])
self.label_set=set(schema['labels'])
self.attribute_set=set(schema['attributes'])
return
#加载模板信息
def load_question_templet(self,templet_path):
dataframe=pandas.read_excel(templet_path)
self.question_templet=[]
for index in range(len(dataframe)):
question=dataframe["question"][index]
cypher=dataframe['cypher'][index]
cypher_check=dataframe["check"][index]
answer=dataframe["answer"][index]
self.question_templet.append([question,cypher,json.loads(cypher_check),answer])
return
#获取问题中谈到的实体,可以使用基于词表的方式,也可以使用NER模型
def get_mention_entitys(self,sentence):
return re.findall("|".join(self.entity_set),sentence)
#获取问题中谈到的关系,也可以使用各种文本分类模型
def get_mention_relations(self,sentence):
return re.findall("|".join(self.relation_set),sentence)
#获取问题中谈到的属性
def get_mention_attributes(self,sentence):
return re.findall("|".join(self.attribute_set),sentence)
#获取问题中的谈到的标签
def get_mention_labels(self,sentence):
return re.findall("|".join(self.label_set),sentence)
#对问题进行预处理,提取需要的信息
def parse_sentence(self,sentence):
entitys=self.get_mention_entitys(sentence)
relations=self.get_mention_relations(sentence)
labels=self.get_mention_labels(sentence)
attributes=self.get_mention_attributes(sentence)
return{
"%ENT%":entitys,
"%REL":relations,
"%LAB%":labels,
"%ATT%":attributes
}
#将提取到的值分配到键上
def decode_value_combination(self,value_combination,cypher_check):
res={}
for index,(key,required_count) in enumerate(cypher_check.items()):
if required_count==1:
res[key]=value_combination[index][0]
else:
for i in range(required_count):
key_num=key[:-1]+str(i)+"%"
res[key_num]=value_combination[index][i]
return res
#对于找到了超过模板中需求的实体数量的情况,需要进行排列组合
#info:{"%ENT%":["周杰伦","方文山"],“%REL%”:["作曲"]}
def get_combinations(self,cypher_check,info):
slot_values=[]
for key,required_count in cypher_check.items():
slot_values.append(itertools.combinations(info[key],required_count))
value_combinations=itertools.product(*slot_values)
combinations=[]
for value_combination in value_combinations:
combinations.append(self.decode_value_combination(value_combination,cypher_check))
return combinations
#将带有token的模板替换成真实词
#string:%ENT1%和%ENT2%是%REL%关系吗
#combination:{“%ENT1%”:"word1","%ENT2%":"word2"}
def replace_token_in_string(self,string,combination):
for key,value in combination.items():
string = string.replace(key,value)
return string
#对于单条模板,根据抽取到的实体属性信息扩展,形成一个列表
#info:{"%ENT%":["周杰伦","方文山"],“%REL%”:["作曲"]}
def expend_templet(self,templet,cypher,cypher_check,info,answer):
combinations=self.get_combinations(cypher_check,info)
templet_cypher_pair=[]
for combination in combinations:
replaced_templet=self.replace_token_in_string(templet,combination)
replaced_cypher=self.replace_token_in_string(cypher,combination)
replaced_answer=self.replace_token_in_string(answer,combination)
templet_cypher_pair.append([replaced_templet,replaced_cypher,replaced_answer])
return templet_cypher_pair
#验证从文本中提取到的信息是否足够填充模板,如果不够就跳过,节省运算速度。
#如模板:%ENT%和%ENT%是什么关系? 这句话需要两个实体才能填充,如果问题中只有一个,该模板无法匹配
def check_cypher_info_valid(self,info,cypher_check):
for key,required_count in cypher_check.items():
if len(info.get(key,[]))<required_count:
return False
return True
#根据提取到的实体,关系等信息,将模板展开成待匹配的问题文本
def expand_question_and_cypher(self,info):
templet_cypher_pair=[]
for templet,cypher,cypher_check,answer in self.question_templet:
if self.check_cypher_info_valid(info,cypher_check):
templet_cypher_pair+=self.expand_templet(templet,cypher,cypher_check,info,answer)
return templet_cypher_pair
#距离函数,文本匹配的所有方法都可以使用
def sentence_similarity_function(self,string1,string2):
print("计算 %s %s"%(string1,string2))
jaccard_distance=len(set(string1)&set(string2))/len(set(string1)|set(string2))
return jaccard_distance
#通过问题匹配的方式确定匹配的cypher
def cypher_match(self,sentence,info):
templet_cypher_pair=self.expand_question_and_cypher(info)
result=[]
for templet,cypher,answer in templet_cypher_pair:
score=self.sentence_similarity_function(sentence,templet)
result.append([templet,cypher,score,answer])
result=sorted(result,reverse=True,key=lambda x:x[2])
return result
#解析结果
def parse_result(self,graph_search_result,answer,info):
graph_search_result=graph_search_result[0]
#关系查找返回的结果形式较为特殊,单独处理
if "REL" in graph_search_result:
graph_search_result['REL']=list(graph_search_result["REL"].types())[0]
answer=self.replace_token_in_string(answer,graph_search_result)
return answer
#对外提供问答接口
def query(self,sentence):#sentence:谁导演的不能说的秘密
info=self.parse_sentence(sentence)#信息抽取
templet_cypher_score=self.cypher_match(sentence,info)
for templet,cypher,score,answer in templet_cypher_score:
graph_search_result=self.graph.run(cypher).data()
#最高分命中的模板不一定在图上能找到答案,当不能找到答案时,运行一个搜案语句,找答案时停止查找后面的模板
if graph_search_result:
break
answer=self.parse_resule(graph_search_result,answer,info)
#通过问题匹配的方式确定匹配的cypher
def cypher_match(self,sentence,info):
templet_cypher_pair=self.expand_question_and_cypher(info)
result=[]
for templet,cypher,answer in templet_cypher_pair:
score=self.sentence_similarity_function(sentence,templet)
result.append([templet,cypher,score,answer])
result=sorted(result,reverse=True,key=lambda x:x[2])
return result
if __name__=="__main__":
graph=GraphQA()
res=graph.query("谁导演的不能说的秘密")
print(res)