大家好我是张金明,在蔚来汽车担任大数据平台研发工程师。这次和大家分享的是 Apache DolphinScheduler 在蔚来汽车一站式数据治理开发平台的应用和改造,接下来我将从背景、应用现状和技术改造三个方面去分享一下。
背景
业务痛点
在蔚来汽车构建一个统一的数据中台之前,我们面临这样一些业务痛点和困境:
数据缺乏治理,数仓不规范、不完整
- 没有统一的数据仓库,无全域的数据资产视图
- 存在数据孤岛;
工具散乱,用户权限不统一、学习成本高
- 用户需要在多个工具之间切换,导致开发效率降低
- 底层运维成本高;
数据需求响应周期长,找数难、取数难
- 无沉淀的数据资产与中台能力,重复处理原始数据;
- 业务数据需求从提出到获取结果的周期长
基于这些痛点和问题,我们构建了一个公司层面的业务中台,内部叫做 DataSight。 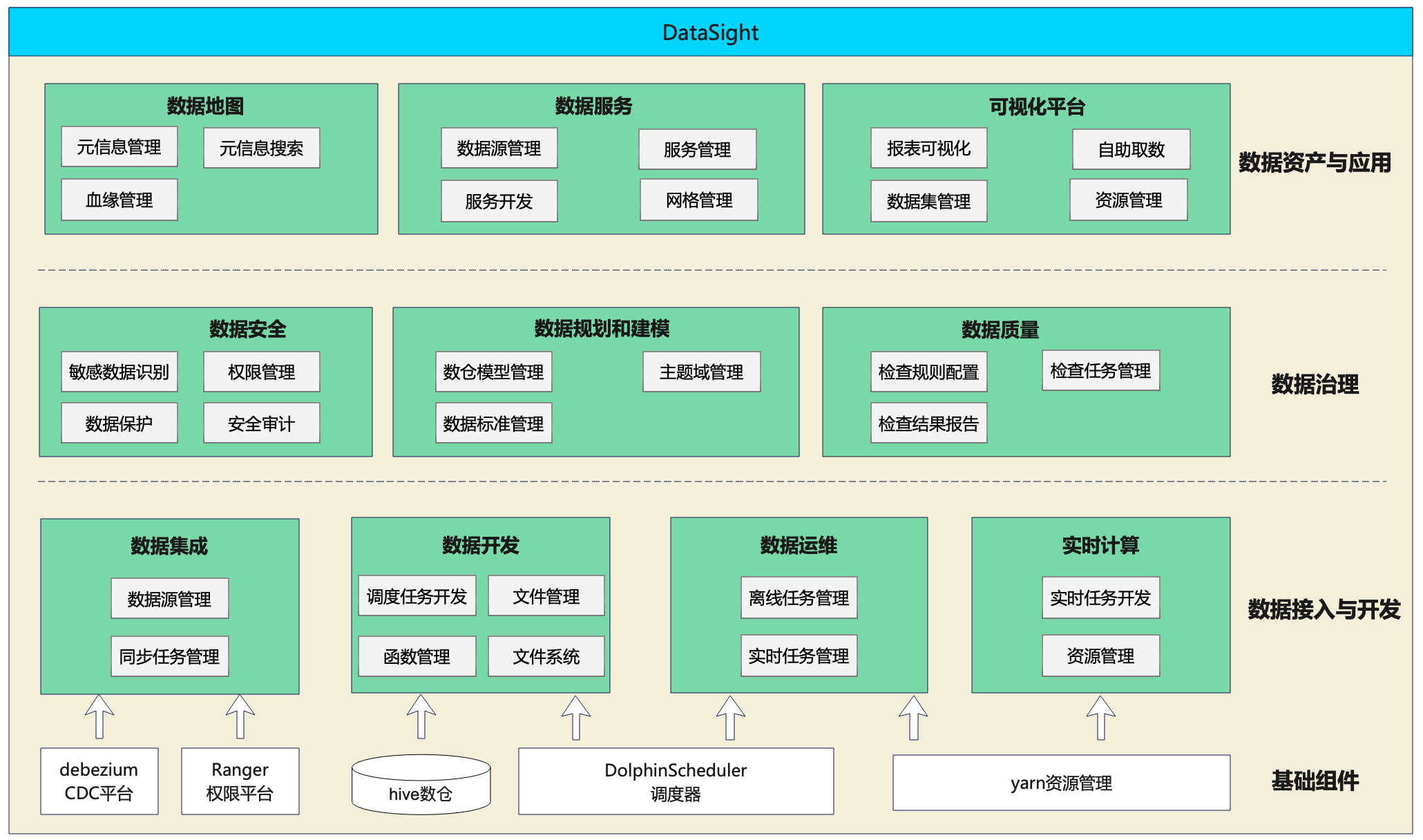
我们可以看到,最底下是我们的一些基础组件;往上一层,这些基础组件主要是支撑了一些数据接入与开发的模块;再向上是我们的数据治理,以及数据资产与应用层。其中,Apache DolphinScheduler 这个调度器在公司主要应用于交互的模块,就是数据开发和数据运维两个模块。
数据开发中,调度任务开发主要就是用到了 Apache DolphinScheduler,通过 API 和调度器进行交互。
应用现状
作业现状
目前,我们的机器共有 9 台,分别是两台 Master机器,是8c 和 32G;六台 Worker 机器,16c 和 64G,以及一台 Alert 机器,8c 和 32G。
版本是更新到了 Apache DolphinScheduler 2.0.7,后续的目标是升级到 2.0.8 版本,2.0 版本已经能够支撑我们的业务了,整体的稳定性还是比较好的。
我们其实是从 2022 年 4 月份开始才真正地在线上运行 Apache DolphinScheduler,直到今天大概运行了一年一个月多的时间,日均的调度工作流实例大概在 4w+,日均调度任务实例大概在 10w+ 左右,主要节点是 Spark 节点、SparkSQL、prestoSQL、Python 和 Shell,其中 Spark 节点占比约 70%。
目前这些节点已经能够支撑我们的大部分业务,后续我们可能会把 DolphinScheduler 自带的一些节点加到我们的数据开发模块里面来。
技术改造
为了适应我们业务的需求,我们对 Apache DolphinScheduler 进行了一些技术改造。首先是稳定性方面的工作。
稳定性
- 滚动重启+黑名单机制+精准路由
这个改造是因为我们遇到的一些痛点,首先,大家知道,DolphinScheduler 的 Worker 重启机制在重启时会把所有的任务给 kill 掉,然后去Restart 这个任务,把这个 kill 的任务分发到新的 Worker 机器上。这样会导致任务执行时间较长。这不符合我们的预期。
同时,我们也无法在特定的 Worker 上进行验证任务。
对此,我们的解决方案就是滚动重启,在重启某台机器之前先下线这台机器,也就是加上黑名单,这样的话,Master 机器就不会给这台下已经下线的机器去分发 worker 任务。这台机器会在上面的任务全部处理完毕后自动上线,也就是移出这个黑名单。接下来所有的 woker 节点都按照此种方式重启,达到平滑重启的目的。
这样做的好处在于不会阻塞每个任务的执行,集群在重启的时候稳定性能得到大幅提升。 
另外,我们还做了精准路由的工作。也就是在任务名后加特定后缀,实现精准路由到某台机器上。 
如图所示,我们在这个任务后面加一个 specific dispatch-worker02 的话,那这个任务一定会被分配到Worker02 这台机器上去。这样的好处在于,假设我们想要去某一个功能点,我们只需要把某一台 Worker 机器下线重启,需要测试的功能点按照这个方式就一定能够打到这台特定的机器上去,实现最小范围的灰度,有助于提高稳定性。
- 优化存储
在存储方面,我们痛点也很明显,就是 process instance和task instance 这两张表数据量是比较大的,由于我们每天的数据量比较大,目前已经达到了千万级别,造成 MySQL 的存储压力比较大。另外,部分 SQL 执行时间长,业务响应变慢;而且 DDL 时会造成锁表,导致业务不可用。
针对这些问题,我们的解决方案包括去梳理所有的慢 SQL,然后去添加合适的索引。与此同时,还有降低查询频率,特别是针对依赖节点。因为我们知道依赖节点每 5 秒钟查询一次数据库,所以我们根据依赖节点所在的 tasks instance ID 去做一个“打散”,偶数节点每 30 秒查询一次,奇数节点每 30 秒查询一次,把他们分开来降低对整个数据库的查询压力。
另外,为了减轻表数据量大的问题,我们也做了一个定期删除的策略,以及定时同步历史数据的策略。
定时删除就是我们利用 DolphinScheduler 自身的调度能力建立两个工作流去删除这两张表,保证 process instance 这张表保留两个月的数据,task instance 这张表保留一个月的数据。同时在删表的时候,我们要注意在非业务高峰期时去做这个动作,每次删表的时候,batch size 要控制好,尽量不要影响线上的任务。
定时同步历史数据,就是我们针对 process instance 这个表,依据 schedule time 按年去分表;针对 task instance 这张表,按 first submit time 按月去分表。
- Spark 任务优化
我们提交 Spark 任务的方式是通过 Sparks Submit 去提交的,它的缺点在于提交 Spark 任务后,常驻机器,导致机器内存过大,会有机器宕机的风险,worker 的运行效率较低。
我们优化了 Spark 任务提交和运行的逻辑,就是通过 Spark Submit 提交的时候添加 spark.yarn.submit.waitAppCompletion=false这个参数,这样任务提交完以后这个进程就消失了。考虑到要保证 worker 机器任务的线程和 Spark 和 Yarn 上的状态一致,我们间隔一定时间查询 Spark 任务状态,如图所示:
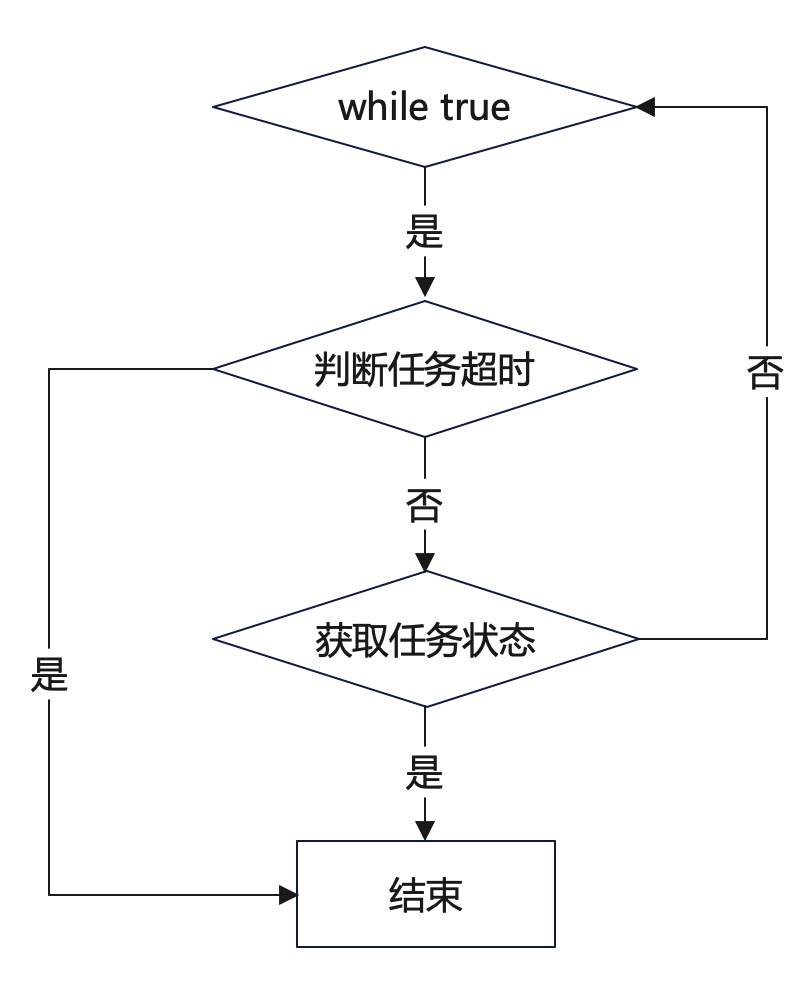
这里是一个 while true 循环,首先去判断这个任务是否超时。如果任务已经超时就会结束这个 Spark 任务,同时会 kill 掉集群上那个真正在跑的任务。
如果任务没有超时,我们会去获取任务的状态,如果任务状态是终止状态,就直接跳出这个循环,否则会间隔一定的时间,比如 30 秒,再继续这个 while true 循环。这种方式让整个 worker 机器所能承载的 Spark 任务大大增加。
易用性
接下来再看一些我们在易用性方面的改造工作吧!
- 依赖节点优化
我们的依赖节点之前的痛点在于,它的使用规则不太符合用户的需求,比如之前是单次查询不到上游即失败;日志内容显示信息不全,对用户不友好;用户无法自定义依赖范围。
针对这些问题,我们做的工作包括修改了查询逻辑为继续等待,就是说当这个任务查询不到上游的时候,我们会继续等待,而不是直接失败。同时我们会也有个极端的保证,就是这个依赖节点超过 24 小时以后就让它自动失败,然后给用户发一个报警。
针对依赖节点,我们也做了强制成功这样一个小trick,并支持用户自定义依赖范围。 
另外,我们还优化了依赖节点的日志输出,当用户点击依赖节点的日志的时候,可以比较清楚地看到依赖的上游所在的空间,这个空间内任务所对应的维护人是什么,以及工作流节点是什么和完成状态,让用户可以点对点地找到上游的同学,快速解决这个依赖节点卡住的问题。 
- 补数任务优化
针对补数之前的痛点,比如补数任务没有进度提示, 并行补数流程实例不严格按照时间顺序,停止并行补数任务逻辑比较麻烦等问题,我们的解决方案包括并行任务引入线程池,也就是把任务按照时间顺序一个一个抛到新建的线程池里,执行完毕以后退出这个线程池,然后再放一个新的进来,达到并行补数的状态。同时,执行时间按递增的顺序。 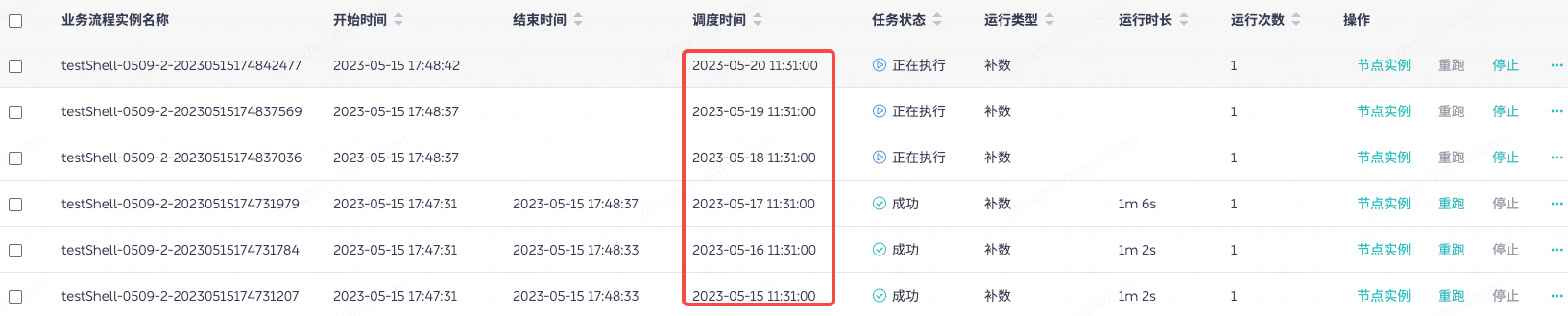
当我们想停止这个补数任务的时候也比较简单,直接把这个线程池 shutdown 就行。

- 多 SQL 执行
最后是关于多 SQL 执行方面的优化。我们之前面临的痛点包括:
- 多 SQL 需要多节点执行浪费集群资源;
- 自定义环境变量无法实现;
- 无法跟踪 SparkSQL 的运行日志。
我们的解决方案包括拆分这条 SQL,支持多条 SQL 同时执行。
与此同时,我们可以在 SparkSQL 任务执行之前拦截执行select engine_id() as engine_id语句。 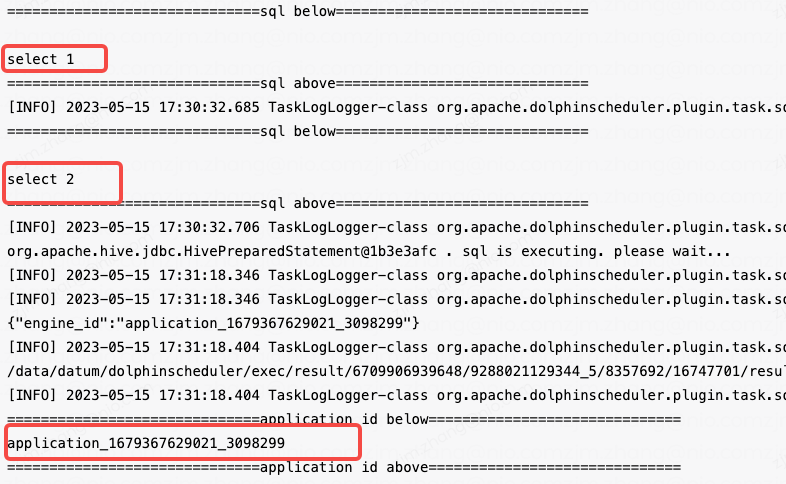 如上图所示,对于 SQL 1 和 SQL 2,之前我们会在两个任务里面去放着,但是现在可以在一个任务节点里面放下来,它会执行两次。同时我们可以清晰地看到这个 SparkSQL 所在的 application ID 是什么,用户能够清晰地根据这个 application ID 找这个业务所在的地址,了解这个作业的进度。
如上图所示,对于 SQL 1 和 SQL 2,之前我们会在两个任务里面去放着,但是现在可以在一个任务节点里面放下来,它会执行两次。同时我们可以清晰地看到这个 SparkSQL 所在的 application ID 是什么,用户能够清晰地根据这个 application ID 找这个业务所在的地址,了解这个作业的进度。
本文由 白鲸开源科技 提供发布支持!