一、锁介绍
- 按性能可分为乐观锁(适用于读多写少的情况下,如果是写多,导致过多cpu空转,影响性能)和悲观锁(适用于写多的情况)
- 按数据库操作粒度可分为表锁、页锁、行锁
- 按数据库操作类型可分为读锁和写锁(悲观锁)、意向锁
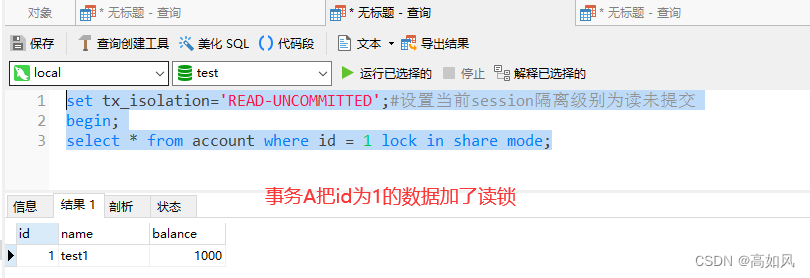
1、读锁(共享锁,S锁)
同一份数据,多个操作只能是读,会阻塞写,不会阻塞读,你可以在加了读锁之后在另一个事务中加读锁,一样是可以的,但是不要在update后面执行,因为update会加写锁,要等update事务结束才行,在任何隔离级别下都一样
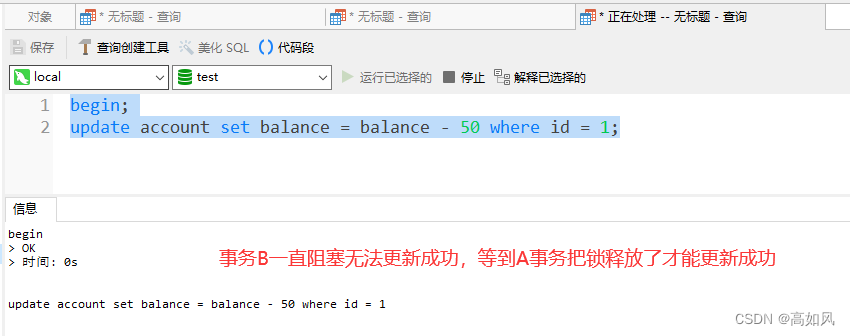
2、写锁(排它锁,X锁)
select可以通过在最后面加上for update来加写锁,写锁会阻塞其它写锁和读锁


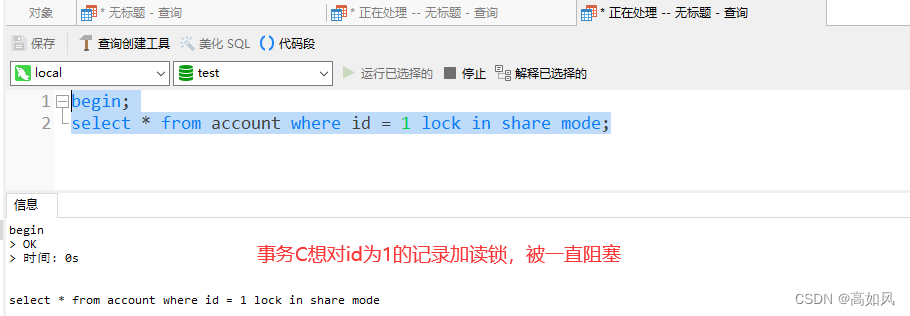
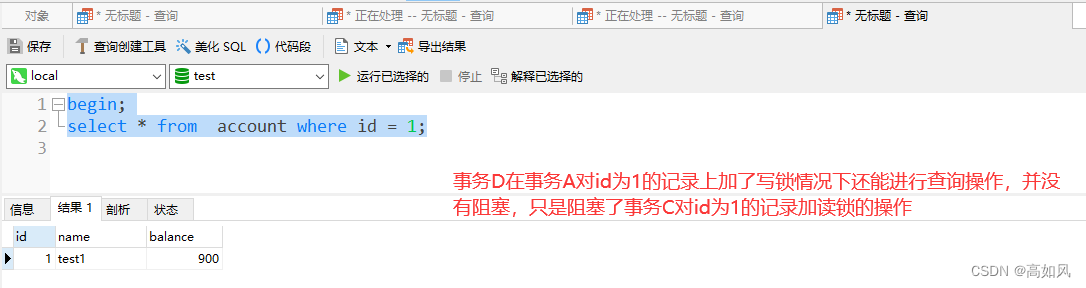
在非串行化事务隔离级别下,无论是加读锁还是写锁都可以正常读取数据
3、行锁
每次锁住一行数据,开销大,加锁慢,支持的并发度高,因为要找寻符合条件的行进行加锁,所以加锁慢,粒度小,并发度自然就高
锁是加载索引上的,如果没有走索引加锁,很有可能行锁升级为表锁(rr级别下可能会升级成表锁rc级别下不会升级成表锁)

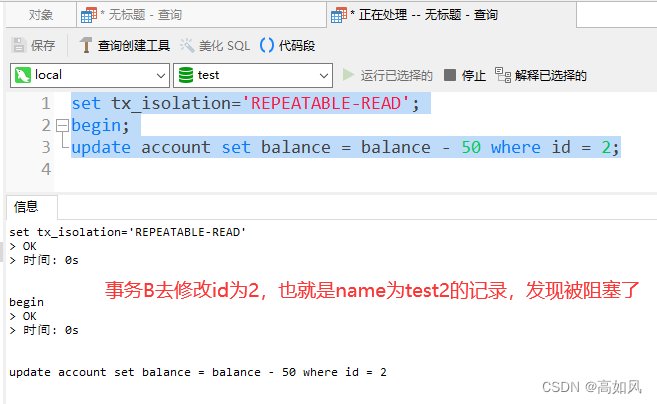
为什么rr级别下可能会升级成表锁rc级别下不会升级成表锁
由于加锁的字段是没有索引的,全表扫的是聚簇索引,为了在rr级别下是可重复读的,不会被其它事务修改而受影响,mysql会把扫描过的记录和主键之间的间隙都加锁,不一定能加上表锁,也有可能其它事务锁住了表中其它的数据记录
4、页锁
在BDB存储引擎下支持页锁,也就是底层数据结构的单个叶子节点的一页数据记录锁住,加锁范围相对较大,等待其它事务释放锁时间相对较长
5、表锁
每次加锁直接锁住整张表,开销小,加锁快,不会出现死锁,并发度低,一般用作数据迁移,下面看看如果一个表有其它事务在进行写操作(写锁),能不能正常对表加读锁或者写锁(可重复读级别下演示):
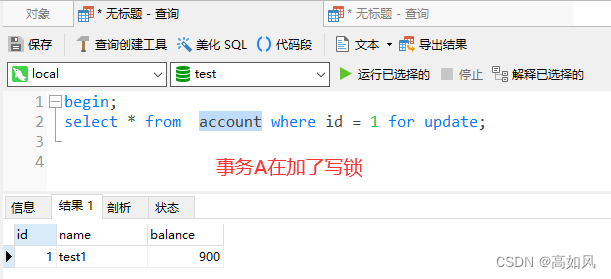

把读锁释放,事务B再次加写锁,看看什么情况:
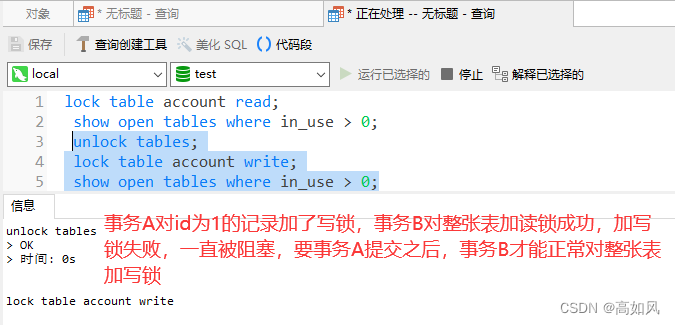
lock table 表名称 read(write),表名称2 read(write);#手动对整张表添加读锁或者写锁
show open tables;#查看上过锁的表
show open tables where in_use > 0;#查看上过锁的表
unlock tables;#删除表锁6、意向锁
在对表加表锁时需要判断表中是否存在其它事务加的锁而设的标志位,为了提高加表锁的效率,不必逐行去判断有没有加锁
意向共享锁:对表加锁时,表中有读锁的标志位
意向排它锁:对表加锁时,表中有写锁的标志位
7、间隙锁
间隙锁就是在锁定区间内,所有的空隙区间都无法插入新的数据(只有在可重复读级别下才存在间隙锁),举例说明:
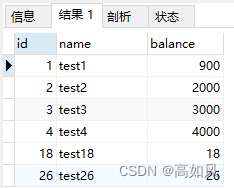
现有间隙区间(4,18),(18,26),(26,正无穷)三个区间
select * from account where id = 16 for update;
select * from account where id = 100 for update;第一条sql的间隙区间范围是 (4,18),其它事务在(4,18)区间内插入记录会陷入等待,第二条sql的间隙区间范围是(26,正无穷),其它事务在(26,正无穷)区间内插入记录会陷入等待
8、临建锁
就是行锁和间隙锁的组合,还是按照间隙锁的数据例子,有这样一条sql
select * from account where id = 16 for update;这样它的区间加锁范围就是4<id<=18都会加锁,这是区间就有(4,18]
myisam存储引擎,读操作之前会给所有表加读锁,在执行insert、update、delete会给涉及的表加写锁
innodb存储引擎,读操作不会给所有表加读锁(非串行化),在执行insert、update、delete会给涉及的表加写锁
二、锁优化
查看mysql所有数据库当前有多少锁等待
show status like 'innodb_row_lock%';1、锁基本数量参数
Innodb_row_lock_current_waits:当前正在等待锁定的数量
Innodb_row_lock_time:从系统启动到现在锁定时间总长度
Innodb_row_lock_time_avg:每次等待花的平均时间
Innodb_row_lock_time_max:从系统启动到现在等待最长一次花的时间
Innodb_row_lock_waits:系统启动到现在所有锁等待的数量
一般分析这三个参数
Innodb_row_lock_time_avg (等待平均时长)
Innodb_row_lock_waits (等待总次数)
Innodb_row_lock_time(等待总时长)
2、查看锁的具体详细信息
具体分析有多少锁等待,
#查看事务
select * from INFORMATION_SCHEMA.INNODB_TRX;
#查看锁,8.0之后需要换成这张表performance_schema.data_locks
select * from INFORMATION_SCHEMA.INNODB_LOCKS;
#查看锁等待,8.0之后需要换成这张表performance_schema.data_lock_waits
select * from INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
#查看锁等待详细信息
show engine innodb status;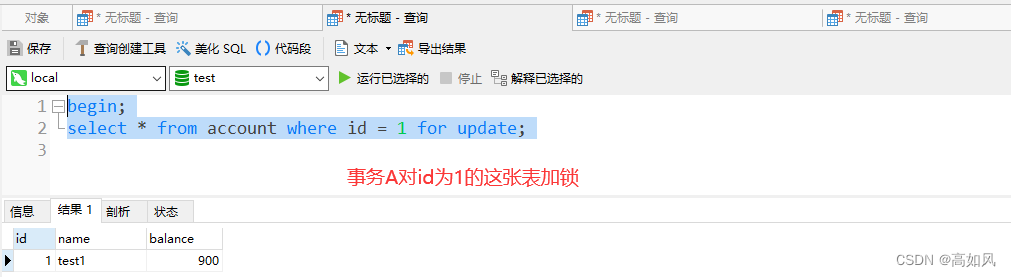
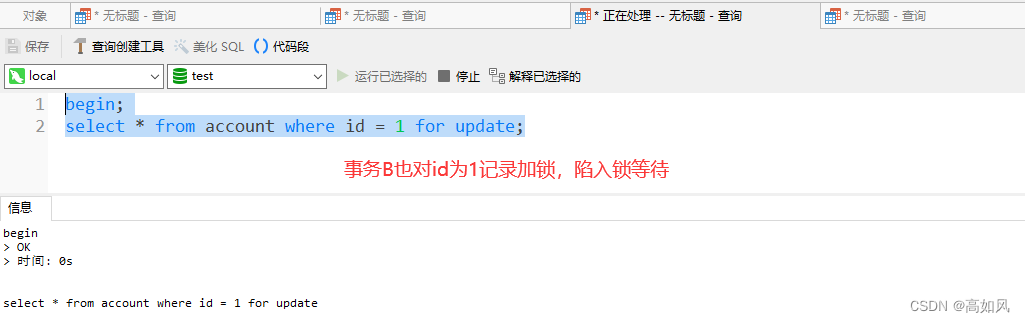
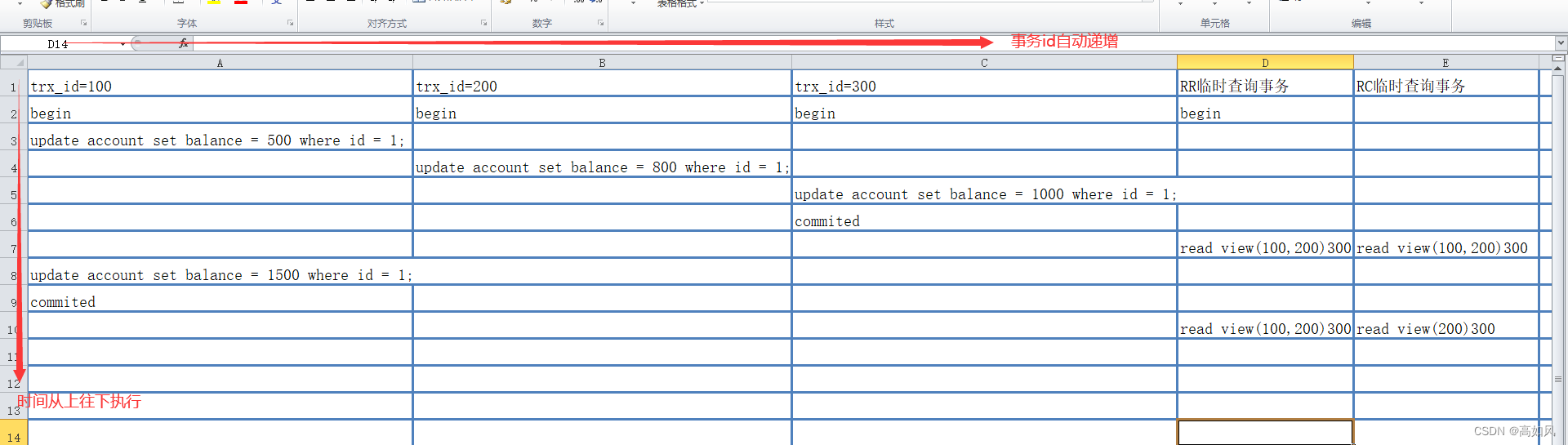
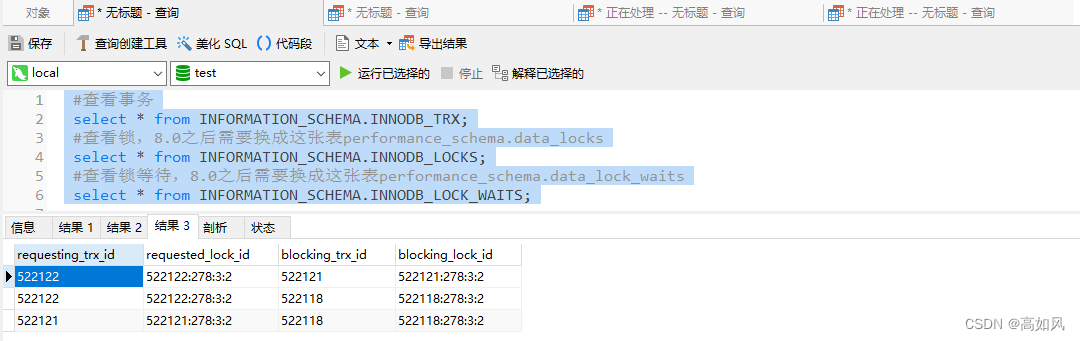
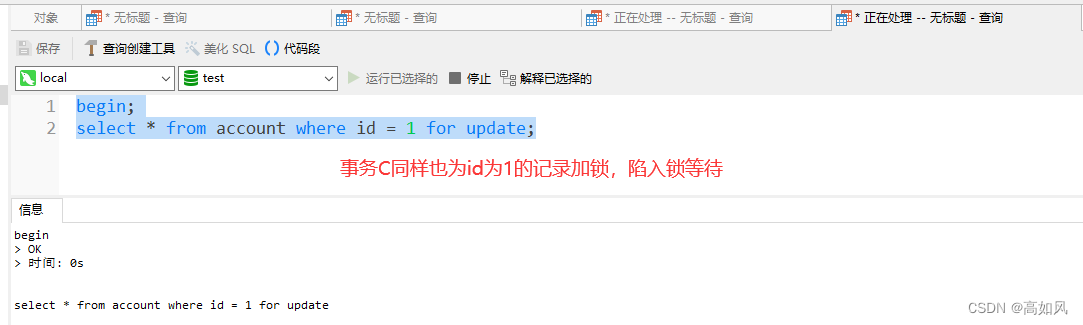 这时候去查询有三个事务,两个事务状态是锁等待,可以根据try_query字段查看哪句sql让事务陷入了锁等待
这时候去查询有三个事务,两个事务状态是锁等待,可以根据try_query字段查看哪句sql让事务陷入了锁等待
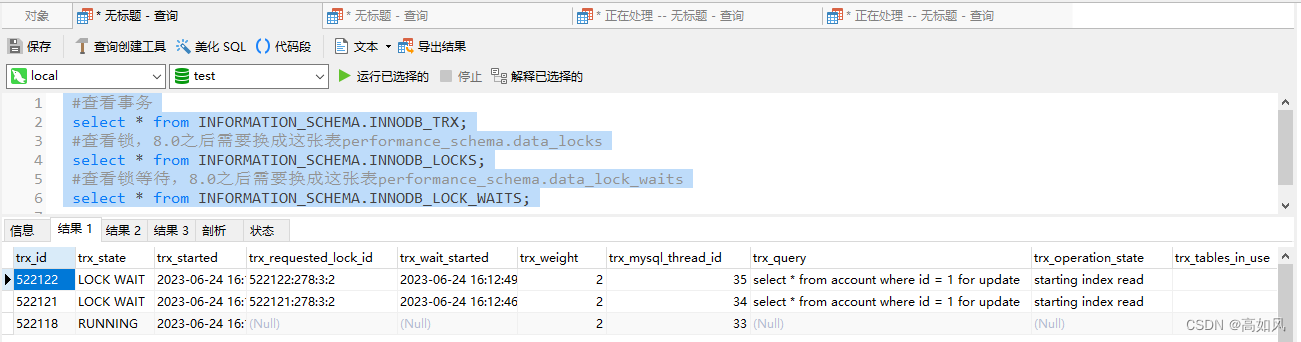 第二个结果集,锁id是相同的,而事务id不同,说明三个事务正在尝试获取同一把锁,lock_mode是X,也就是写锁,针对account表主键假的写锁(如果只有一个事务加锁,则一行记录都没有,因为没有锁等待)
第二个结果集,锁id是相同的,而事务id不同,说明三个事务正在尝试获取同一把锁,lock_mode是X,也就是写锁,针对account表主键假的写锁(如果只有一个事务加锁,则一行记录都没有,因为没有锁等待)
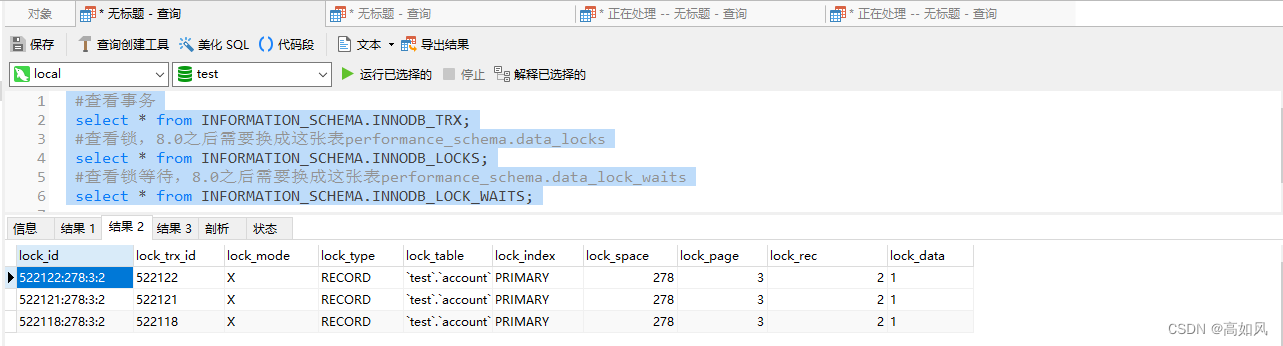 第三个结果集,意思是事务id为522122请求时被事务id为522121和522118的事务加锁阻塞;事务522121正请求时被事务id为522118的事务加锁阻塞
第三个结果集,意思是事务id为522122请求时被事务id为522121和522118的事务加锁阻塞;事务522121正请求时被事务id为522118的事务加锁阻塞
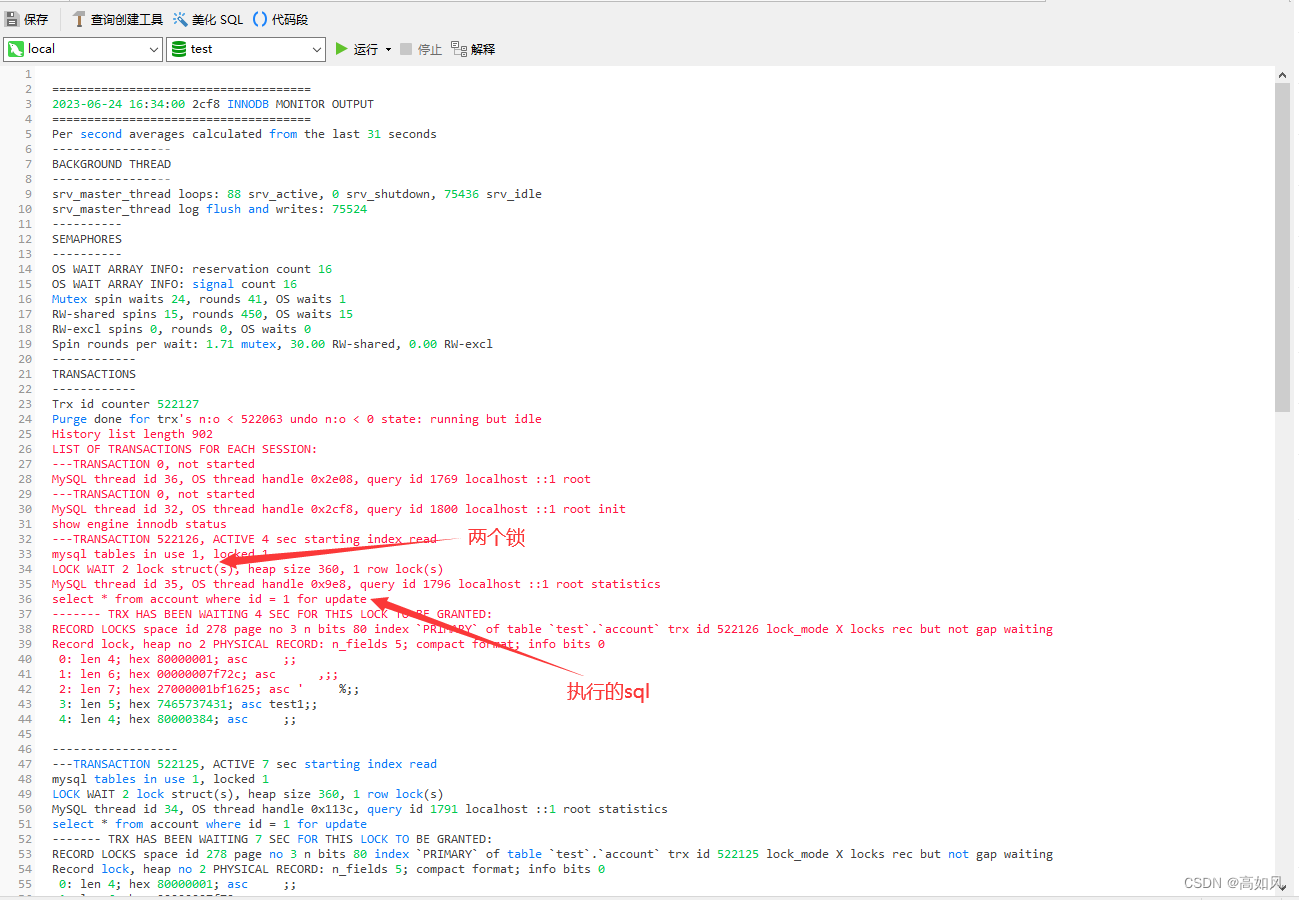
 查看show engine innodb status;的Status字段关键信息截图
查看show engine innodb status;的Status字段关键信息截图
3、死锁情况



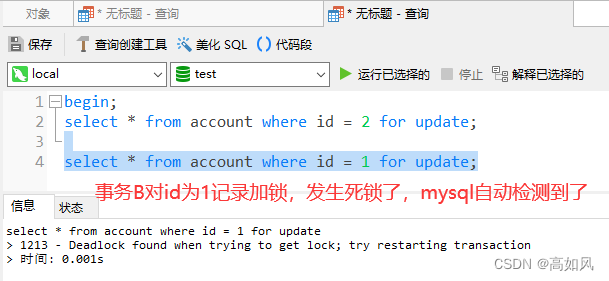
有些场景下mysql检测不到死锁我们可以使用之前的命令查询到trx_mysql_thread_id,手动kill
#释放锁,trx_mysql_thread_id可以从INNODB_TRX表里查看到
kill trx_mysql_thread_id;总结:
尽量可能用到索引加锁,否则行锁会升级成表锁
缩小索引加锁范围,减少锁的粒度,避免间隙锁
合理缩小事务,减少锁等待时间,加锁逻辑都放到事务最后执行
尽可能用低的事务隔离级别,意味着性能高
三、MVCC机制
临时事务:
begin/start transaction开始事务时并不会马上生成事务,查询操作会生成一个临时事务(待验证)
1、undo log版本链和read view机制详解
undo log每条日志版本都会加上trx_id和roll_pointer,以account表为例,具体如下
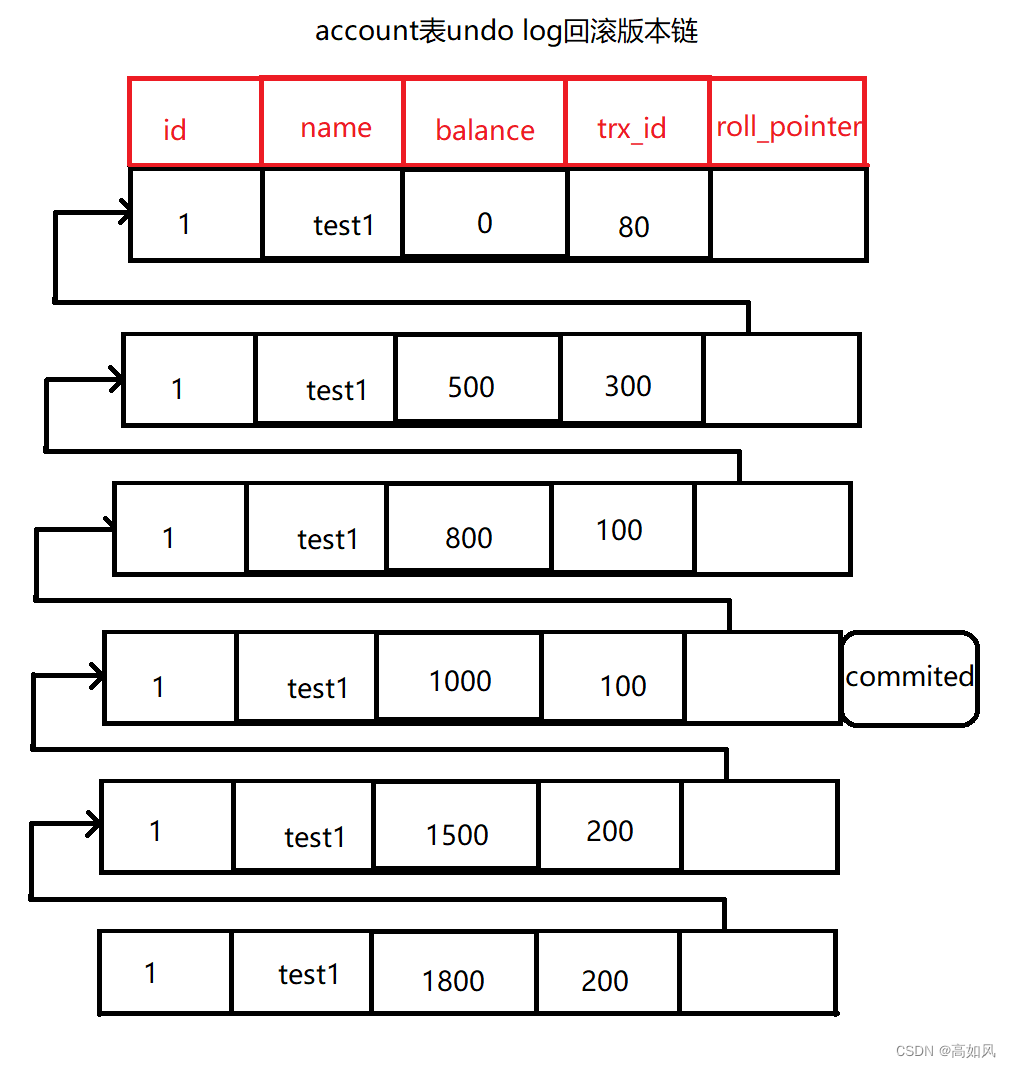
read view在可重复读级别下,从事务第一次查询开始就生成了read view,该视图在事务结束前都不会发生变化,而读已提交级别下,read view在同一事务内每查询一次,read view都会重新生成,视图生成规则:
由所有未提交的事务id数组加上已创建最大事务id组成,事务中任何查询sql结果都需要从undo log最新版本链中获取
2、版本链比对规则
- 如果在最新版本链往上找,找到的trx_id是trx_id<min_trx_id(说明是已经提交的数据,这个版本数据可见
- 如果在最新版本链往上找,找到的trx_id是trx_id>max_trx_id(如果trx_id是当前事务id,这个是可见的,如果不是当前事务id,说明是还未创建的事务)
- 如果在最新版本链往上找,找到的trx_id是min_trx_id<trx_id<max_trx_id,要分两种情况,因为有个未提交事务id视图数组;(如果在视图数组中,说明是未提交事务;如果在视图数组外,说明是已提交的事务生成的版本)