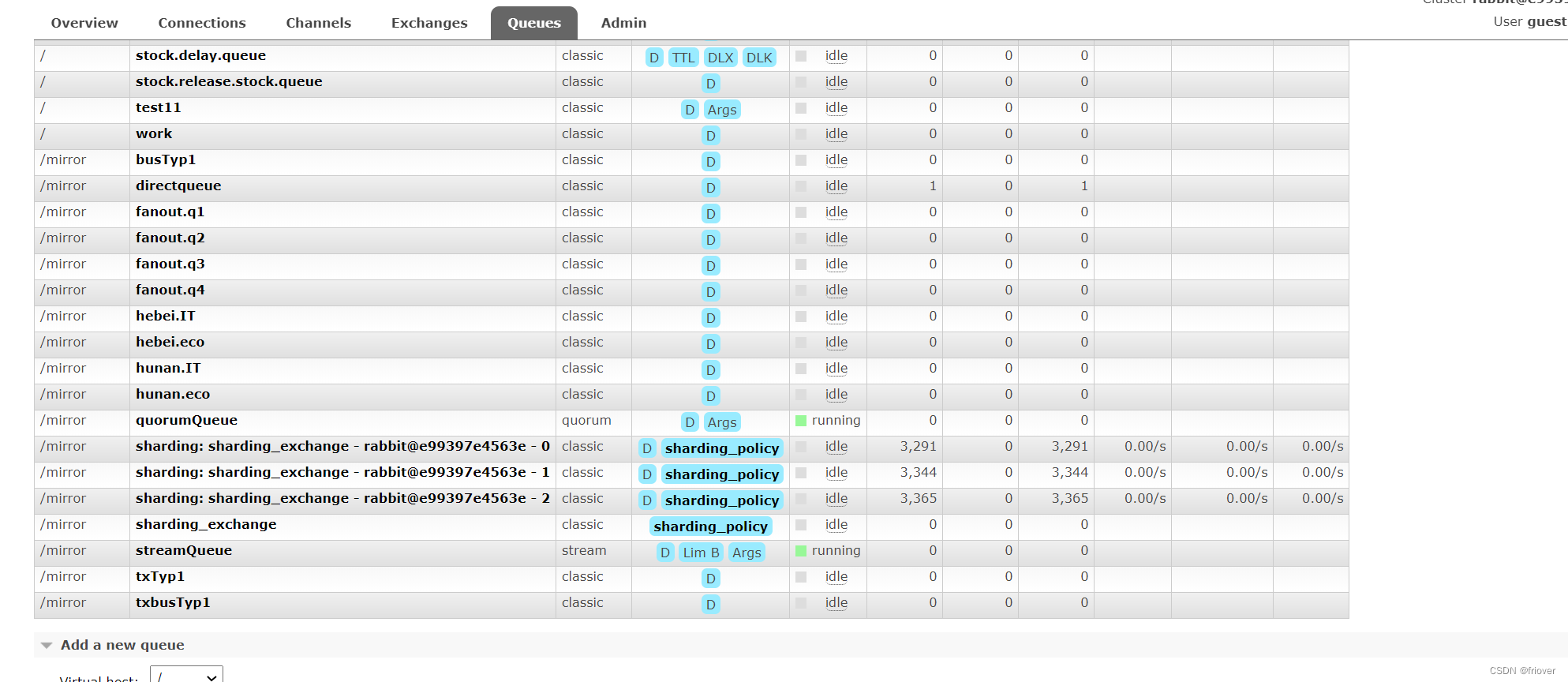
1 GAN基本概念
1.1 GAN介绍
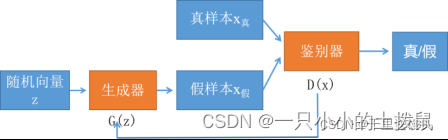
GAN的英文全称是Generative Adversarial Network,中文名是生成对抗网络。它由两个部分组成,生成器和鉴别器(又称判别器),生成网络(Generator)负责生成模拟数据;判别网络Discriminator)负责判断输入的数据是真实的还是生成的。生成网络要不断优化自己生成的数据让判别网络判断不出来,判别网络也要优化自己让自己判断得更准确。它们之间的关系可以用竞争或敌对关系来描述。
在GAN的原作中,作者将生成器比喻为印假钞票的犯罪分子,判别器则类比为警察。犯罪分子努力让钞票看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。那么类比于图像生成任务,生成器不断生成尽可能逼真的假图像。判别器则判断图像是否是真实的图像,还是生成的图像,二者不断博弈优化。最终生成器生成的图像使得判别器完全无法判别真假。
1.2 GAN的基本架构图
生成器负责依据随机向量产生内容,这些内容可以是图片、文字,也可以是音乐,具体什么取决于你想要创造什么;判别器负责判别接收的内容是否是真实的,通常他会给出一个概率,代表内容的真实度。

对抗是指GAN的交替训练的过程,对于原始的GAN,以图片生成为例子,由高斯分布随机采样得到的噪声通过生成器得到了生成的假图片,将假图片和真图片一起随机抽取送入判别器判别,让它学习区分两者,给真的高分,给假的低分,当判别器能够熟练判断现有的数据后,再让生成器以从判别器处获得高分为目标,不断生成更好的假图片,直到能骗过判别器,重复这一过程,直到判别器对任何图片的预测概率都接近0.5,也就是无法判别图片的真假,就可以停止训练了。对抗式过程的最终目标是尽可能逼真地模拟数据集的分布。
我们训练一个GAN的最终目标就是获得一个足够好的生成器,也就生成一个足够已经乱真的内容
1.3 GAN原理简述
生成器和判别器都是神经网络,它们在训练阶段都相互竞争。重复这些步骤,在这个过程中,生成器和鉴别器在每次重复后在各自的工作中变得越来越好。
Generator
GAN中的Generator是一种神经网络,给定一组随机的值,通过一系列非线性计算产生真实的图像。该生成器产生假图像 Xfake,其中随机向量Z,服从多元高斯分布采样。 生成器的输入是服从多元正态分布或高斯分布采样,并生成一个等于原始图像Xreal大小的输出。如下是一个以随机矢量为输入,生成假数字图像的生成器的流程图。

生成器的作用是: 欺骗的判别器、产生逼真的图像、训练完成后能实现高性能生成效果。

Discriminator
在GAN中判别器基于判别建模的概念,它试图用特定的标签对数据集中的不同类进行分类。因此,在本质上,它类似于一个监督分类问题。此外,判别器对观察结果的分类能力不仅限于图像,还包括视频、文本和许多其他领域(多模态)。以下是判别器将生成器生成的图像,分类判断真假的流程图。

判别器的作用是解决一个二值分类问题,学习区分真假图像:预测观察结果是由生成器(假的)生成,还是来自原始数据分布(真实的),在此过程中,它学习一组参数或权重。随着训练的进行,权重也在不断更新。

2 GAN的样本生成过程
GAN模型不是一上来就能实现具体功能的,需要经历一个训练的过程。我将其训练前后状态称为“原始的GAN模型”和“成熟的GAN模型”,原始的GAN模型要经过一个训练的过程成为一个成熟的GAN模型,而这个“成熟的GAN模型”才是我们实际应用的GAN模型。这个训练过程具体是训练生成网络(Generator)和判别网络(Discriminator)。
生成器G是一个生成图片的网络,它接收一个随机的噪声 z ,通过这个噪声生成图片,生成的图片记做G(z)。判别器D判别一张图片是不是“真实的”。它的输入是 x , x 代表一张图片(其中,x 包含生成图片和真实图片,对于生成图片有 x=G(z) ,输出D(x)代表 x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表图片0%是真的(或者说100%是假的)
2.1 训练过程
生成器和鉴别器一对博弈关系:鉴别器惩罚生成器,鉴别器收益,生成器损失;生成器进化,使鉴别器对自己惩罚小,生成器收益,鉴别器损失。
具体过程:生成器生成假数据,然后将生成的假数据和真数据都输入判别器,判别器要判断出哪些是真的哪些是假的。判别器第一次判别出来的肯定有很大的误差,然后我们根据误差来优化判别器。现在判别器水平提高了,生成器生成的数据很难再骗过判别器了,所以我们得反过来优化生成器,之后生成器水平提高了,然后反过来继续训练判别器,判别器水平又提高了,再反过来训练生成器,就这样循环往复,直到达到纳什均衡。
2.2 损失函数
生成模型捕获数据的分布,并以尝试最大化判别器出错的概率的方式进行训练。另一方面,判别器基于一个模型,该模型估计它获得的样本是从训练数据而不是从生成器接收的概率。GAN 被表述为一个极小极大游戏,其中判别器试图最小化其奖励V(D, G),而生成器试图最小化判别器的奖励,或者换句话说,最大化其损失。

对于生成网络G,其输入的 z
它可以用以下公式在数学上描述。
生成网络的损失函数:
上式中,G 代表生成网络,D 代表判别网络,H 代表交叉熵,z 是输入随机数据。D(G(z)) 是对生成数据的判断概率,1代表数据绝对真实,0代表数据绝对虚假。H(1,D(G(z))) 代表判断结果与1的距离。显然生成网络想取得良好的效果,那就要做到,让判别器将生成数据判别为真数据(即D(G(z))与1的距离越小越好)。
判别网络的损失函数:
上式中,是真实数据,这里要注意的是,
代表真实数据与1的距离,
代表生成数据与0的距离。显然,识别网络要想取得良好的效果,那么就要做到,在它眼里,真实数据就是真实数据,生成数据就是虚假数据(即真实数据与1的距离小,生成数据与0的距离小)。
优化原理:生成网络和判别网络有了损失函数,就可以基于各自的损失函数,利用误差反向传播(Backpropagation)(BP)反向传播算法和最优化方法(如梯度下降法)来实现参数的调整),不断提高生成网络和判别网络的性能(最终生成网络和判别网络的成熟状态就是学习到了合理的映射函数)。
采用Binary Cross-Entropy(BCE)损失函数对判别器进行训练。
以深度卷积神将网络为例(DCGAN)
生成网络:卷积神经网络+反卷积神经网络(前者负责提取图像特征,后者负责根据输入的特征重新生成图像(即假数据))。
判别网络:卷积神经网络+全连接层处理(传统神经网络)(前者负责提取图像特征,后者负责判别真假。)
GAN的应用