文章目录
- 代码和数据
- 段
- 代码与可执行文件中对应的位置
- 可执行文件中的段在内存中的布局
- 加入动态链接库的内存空间布局
- 堆栈段的作用
- 过程活动记录
- 函数调用过程记录举例
- static和auto关键字
- 汇编嵌入C代码
代码和数据
代码和数据的区别可以理解为编译时和运行时的分界线。
代码:即C语言编写的
编译器的工作绝大部分是翻译代码
数据:运行时的可执行文件中保存的二进制数据。
段
目标文件和可执行文件由几种不同的格式,一般称作ELF格式,在UNIX中为a.out格式。
所有不同格式都有一个不同概念,那就是段segment。
段对Unix目标文件来说:他是二进制文件中的简单的区域划分,内容块。里面保存了某种特定类型的相关所有信息。
section:是ELF文件中的最小组织单位。一个段一般包含几个section。
而段在Intel x86模型中,表示一种设计结果,设计地址空间并非一个整体而是分成一些64K大小的区域,称为段。
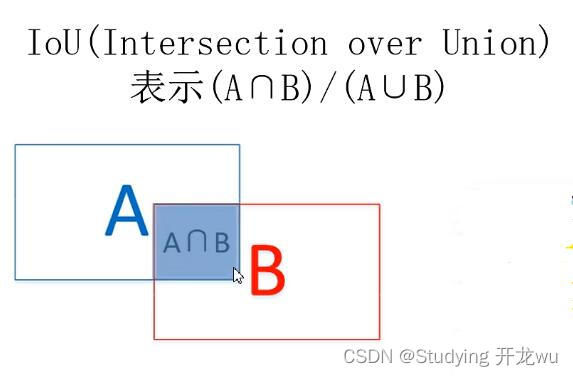
当对一个可执行文件执行size命令时,比如size a.out就会打印出该文件的3个段,text, data, bss段的大小。
代码与可执行文件中对应的位置
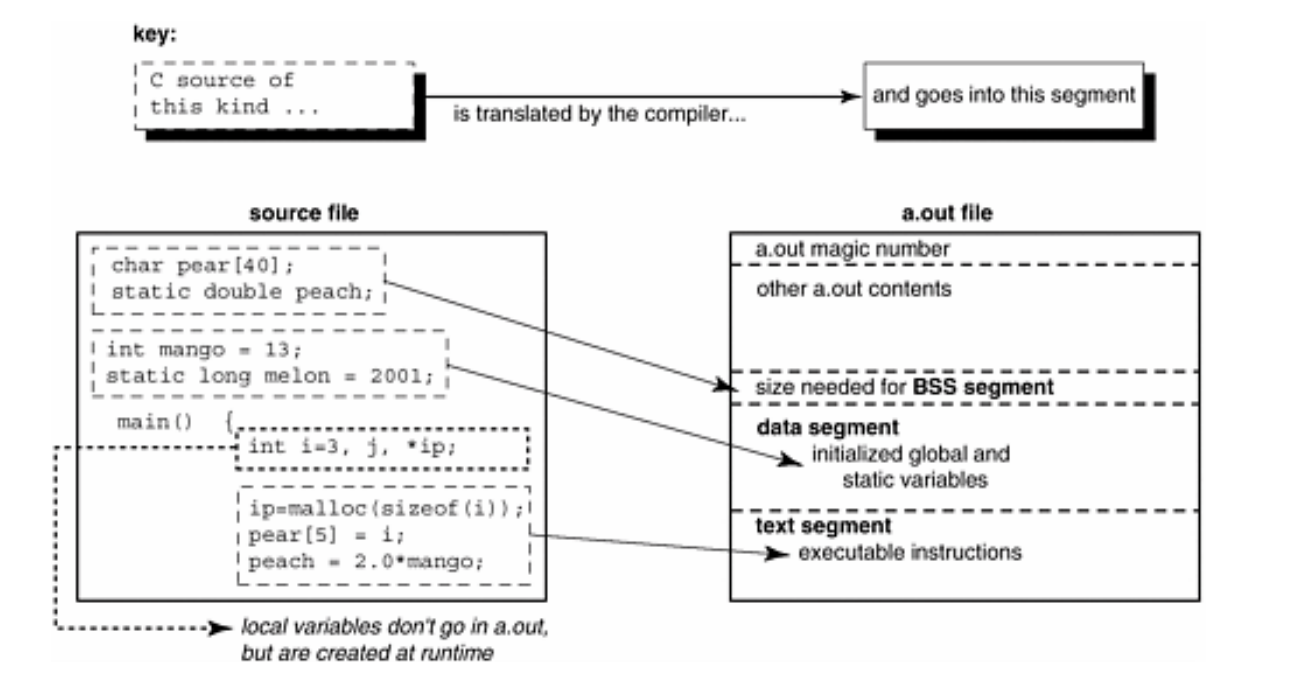
BSS段:未初始化的全局和静态变量
data段:初始化后的全局和静态变量
text段:指令
可执行文件中的段在内存中的布局
下图我们可以看到可执行文件段对应到程序内存中的段。
在可执行文件中,段是一块数据内容。
在进程内存中,段是一片连续的虚拟地址。
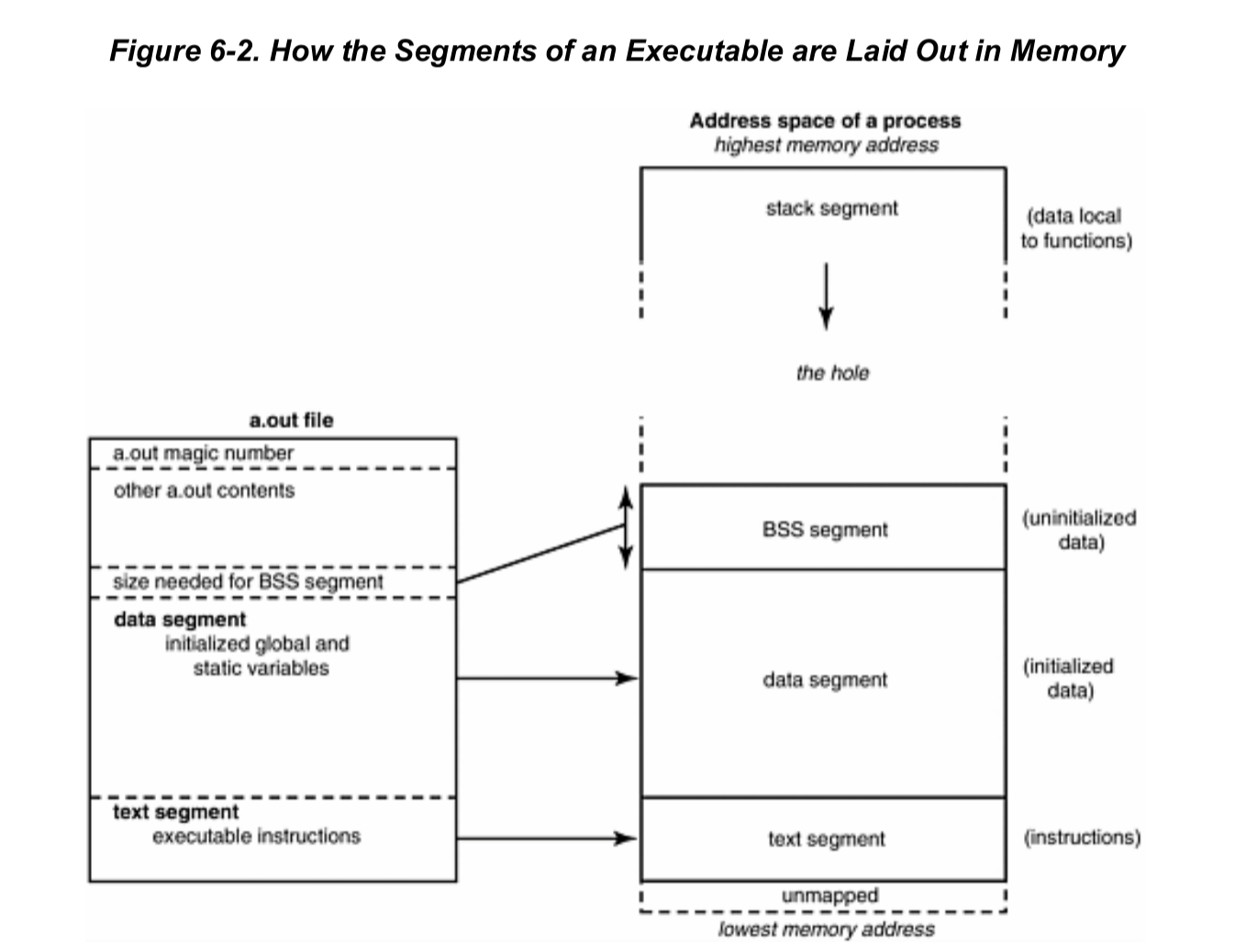
text文本段包含的是代码转换成的二进制指令,他直接被拷贝到内存中
数据段包含初始化的全局和静态变量,一般情况下这个段是最大段。
BSS段是未初始化的数据。
堆栈段:存储局部变量,临时数据以及函数形参。
堆:用于动态分配内存。
虚拟地址的最低地址并未被映射,比如0x000001。他位于进程的地址空间但是并未赋予物理地址,对这里的引用都是非法的。一般他是从地址0开始的几K个byte。用于捕捉使用空指针和小整型值指针应用内存情况。
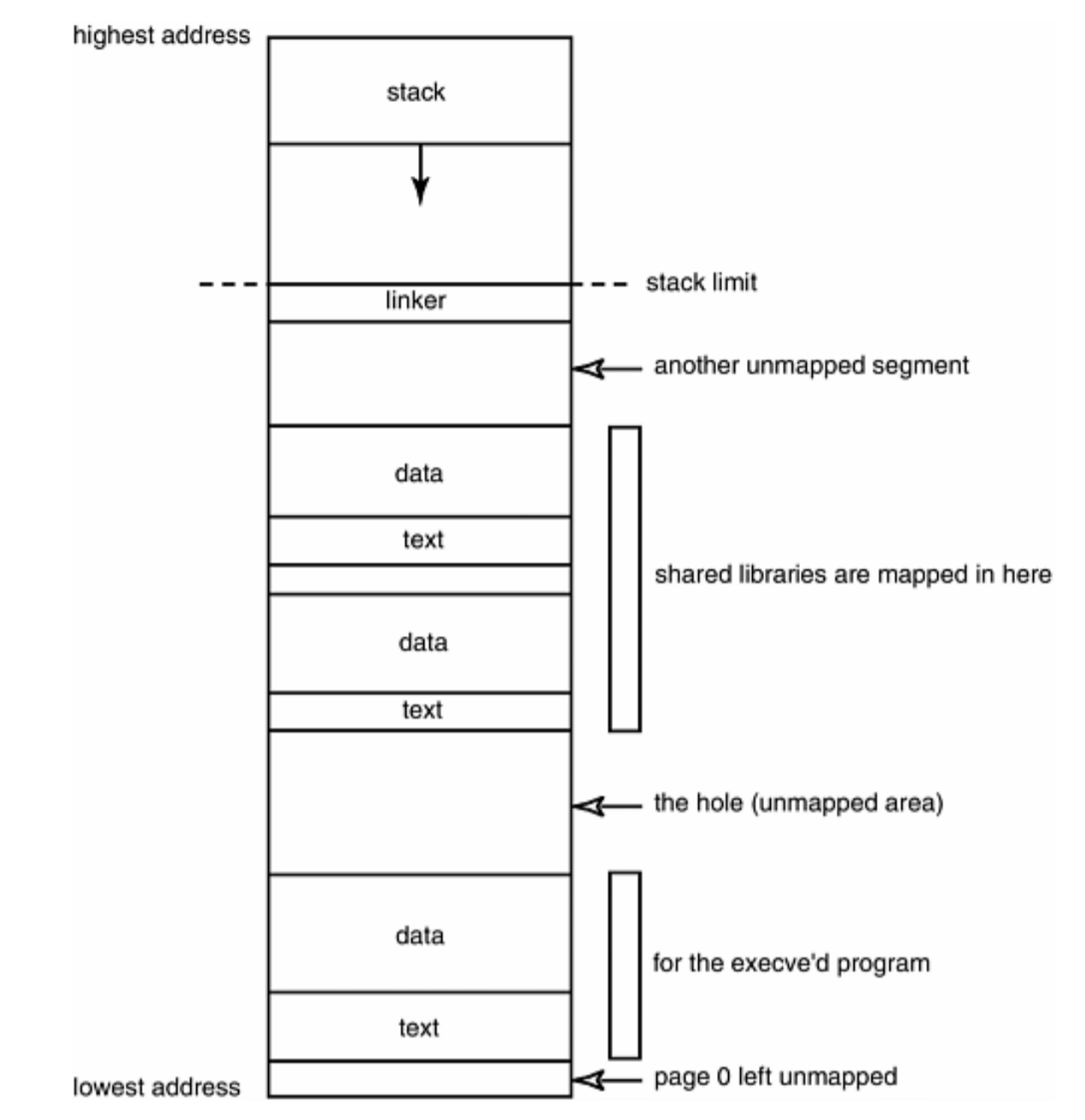
加入动态链接库的内存空间布局
堆栈段的作用
堆栈段包含一种单一的数据结构:堆栈。
程序运行时系统维护一个指针,通常位于寄存器中,称为sp,用于提示堆栈当前的顶部位置。
堆栈主要由以下3个用途:
- 堆栈为函数内部声明的局部变量提供存储空间。
- 进行函数调用时,堆栈存储于此有关维护性信息,叫做过程活动记录。他包含函数的调用地址,也就是调用函数结束后跳回的地方,以及一些寄存器的值。
- 堆栈也可以被用作暂时存储区。比如通过alloca函数分配的内存就存储在堆栈中。所以alloca申请的函数无需释放
在绝大多数处理器中,堆栈是向下增长,也就是朝着低地址方向生长。
过程活动记录
C语言 自动提供的服务之一是跟踪调用链——哪些函数调用了哪些函数,以及函数return后返回到何处等。
解决这个问题使用的机制就是堆栈中的过程活动记录。
每个函数调用时都会产生一个过程活动记录。他是一种数据结构,用于支持过程调用。
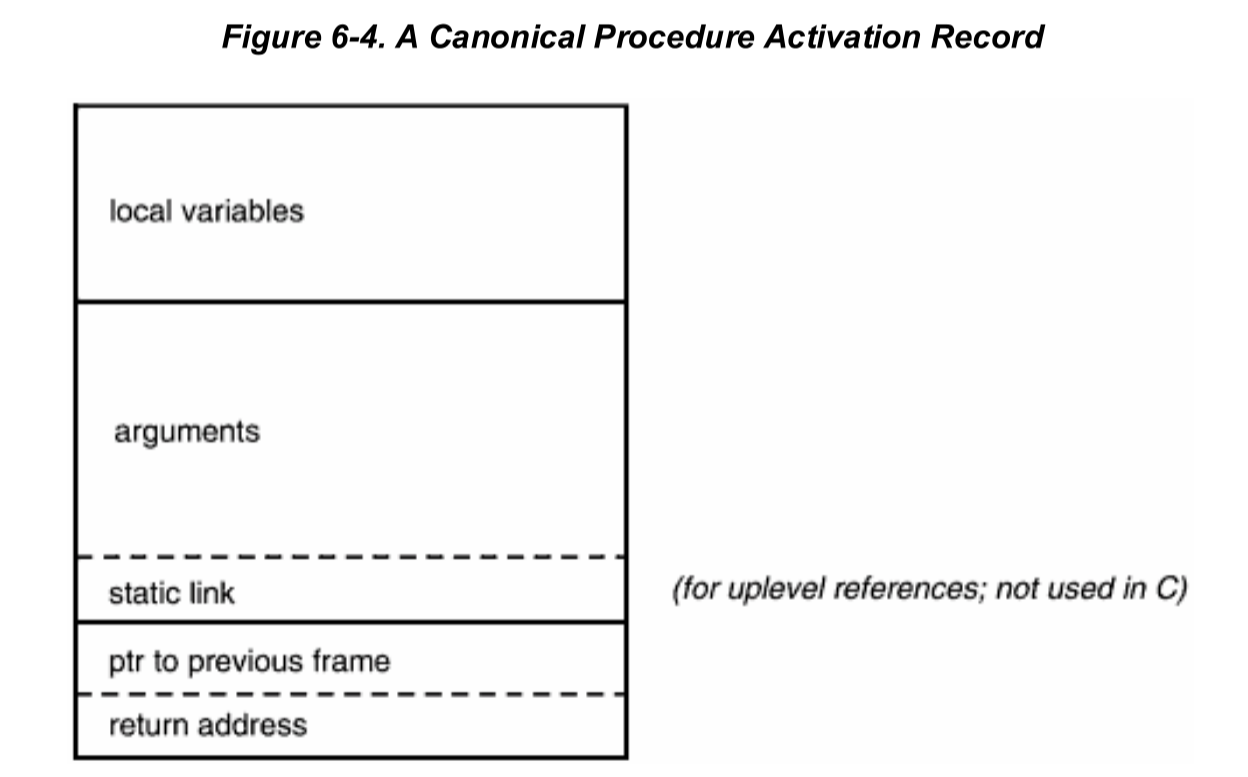
C 语言不允许函数内部嵌套定义函数。
函数调用过程记录举例
void a (int) {
if(i > 0)
a(--i);
else
printf("i is zero");
return;
}
int main() {
a(1);
}
程序控制流如下
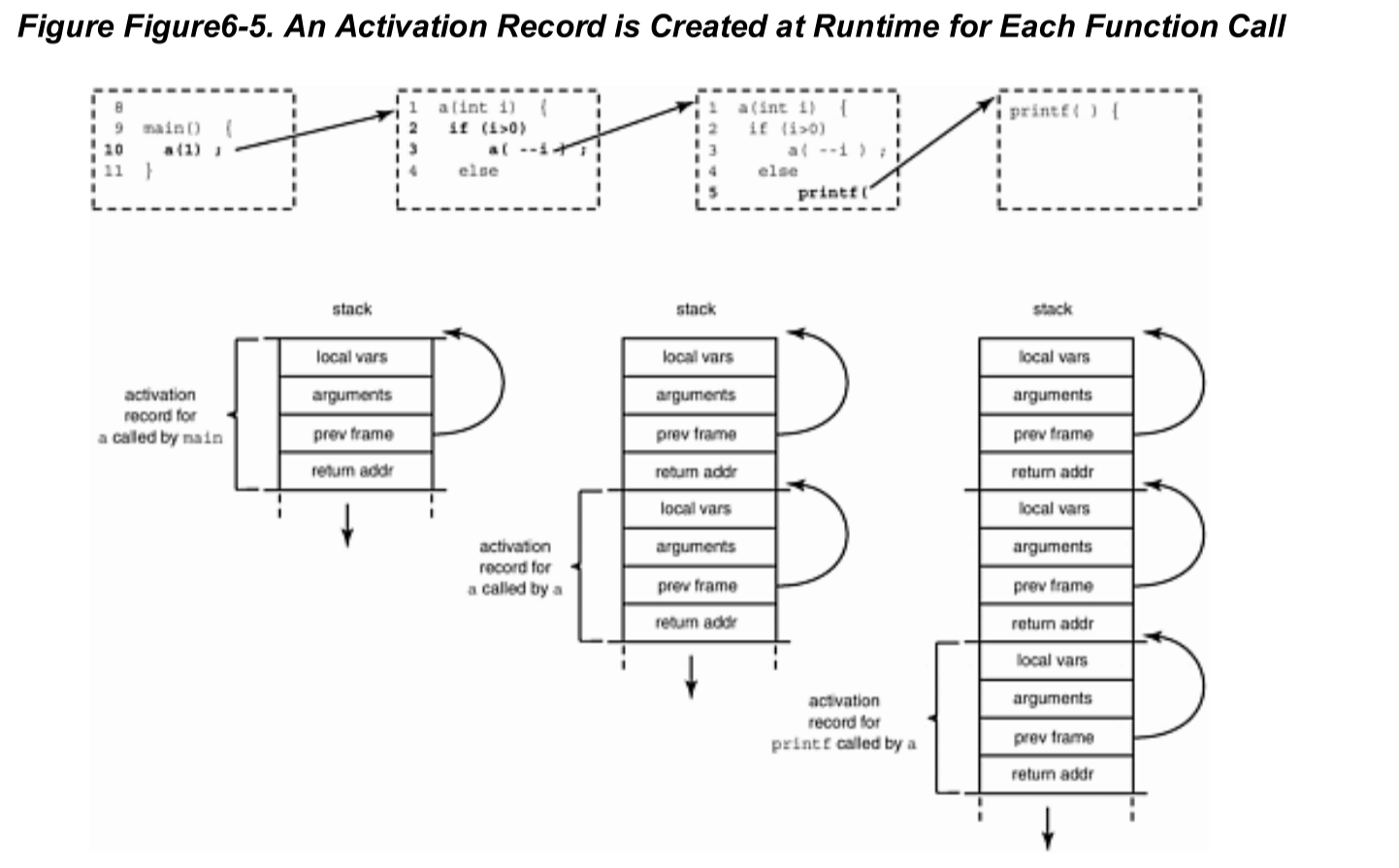
其中,prev frame表示前一个活动记录。比如函数a调用时,prev frame就指向前一个main函数的记录的返回值地址。
当一个函数调用另一个函数时,堆栈的状态就会如图所示,堆栈向下生长。
当函数执行完,会通过prev frame指针找到上一条记录的返回值地址中。
通过这个过程我们可以看到堆栈调用函数是后进先出的,一个函数内部调用另一个函数。
可以参考这里
C语言过程活动记录
static和auto关键字
我们看下面这个例子
char* func() {
char ch_arr[] = "apple";
return ch_arr;
}
当进入该函数时,ch_arr在栈中分配。函数结束时,变量就会被释放,他的资源会被回收。
这时将这个指针返回,我们再使用的时候,就会有问题,因为他已经被释放,所以他引用的资源可能无效也可能是其他值。这个结果是可怕的。
如果我们想返回一个指针在函数内部定义的,我们可以把这个变量声明为static。
这样就能保证该变量被保存在data段中而不是堆栈中,该变量的生命周期就和程序一样长。当函数退出时,该变量仍然可以保持。
存储变量auto在实际中完全用不到,他是默认给局部变量的。
汇编嵌入C代码
可以把汇编代码嵌入到C代码中。
这通常只适用于深入操作系统核心且依赖机器的任务。
 编译器并不会对内联汇编代码做多少检查,所以很容易创建出崩溃的程序。
编译器并不会对内联汇编代码做多少检查,所以很容易创建出崩溃的程序。
但是这是一种很好的学习机器指令集的方法。