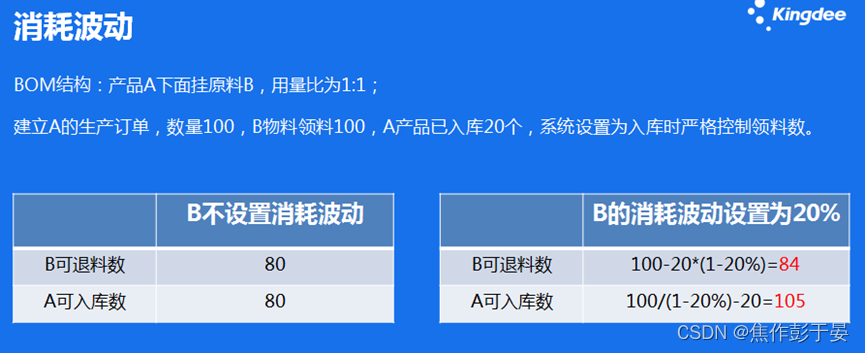
一、介绍
索引是数据库对象之一,用于提高字段检索效率,使用者只需要对哪个表中哪些字段建立索引即可,其余什么都不做,数据库会自行处理。
索引提供指向存储在表的指定列中的数据值的指针,如同图书的目录,能够加快表的查询速度。但同时也增加了插入、更新和删除操作的处理时间。
二、索引的使用
2.1 实验数据准备
-- 创建表
CREATE TABLE student (
id int(11) NOT NULL COMMENT '主键',
name varchar(50) DEFAULT NULL COMMENT '姓名',
age int(11) DEFAULT NULL COMMENT '年龄'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 基于存储过程插入5万条数据
CREATE PROCEDURE p_index()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 50000 DO
INSERT INTO student(id,name,age) VALUES(i,CONCAT('张三',i),10+i);
SET i = i+1;
END WHILE;
END;
-- 执行
CALL p_index();
-- 等待一会执行完毕,查询条数
SELECT COUNT(*) FROM student; -- 50000条
查询数据看耗时:
-- 基于id查询
SELECT * FROM student WHERE id = 49007;
> OK
> 时间: 0.019s
-- 基于name查询
SELECT * FROM student WHERE name = '张三49007';
> OK
> 时间: 0.023s
2.2 索引操作
1.创建索引
create index 索引名 ON 表名(字段名); -- 索引名:index_name
2.查询索引
show index from 表名;
3.删除索引
drop index 索引名 on 表名;
4.修改索引
alter table 表名 add index 索引名(字段名);
2.3 测试索引
① 为student表创建一个索引
create index index_student_id ON student(id);
② 测试索引对查询效率的提升
SELECT * FROM student WHERE id = 49007;
> OK
> 时间: 0.001s -- 可以看出效率明显提升
三、索引分类
3.1 唯一索引
唯一索引(unique key),索引列中的值必须是唯一的,但是允许为空值。
-- 方式1:建表的时候指定
CREATE TABLE table_name(
字段1 类型,
字段2 类型,
...
unique key (索引名(字段名));
);
-- 方式2:建表后设置
create unique index index_name on 表名(字段名);
3.2 主键索引
主键索引(primary key)是一种特殊的唯一索引,不允许有空值。也就是说,建表时指定了主键字段,该字段本身就设置了索引。
3.3 普通索引
使用create index创建的就是普通索引。
3.4 组合索引
前面我们都是为单个字段创建索引,其实一个索引可以包含多个字段,我们称之为叫:组合索引,也叫联合索引。
create index 索引名 ON 表名(字段1,字段2,...);
-- 组合索引的最左优先(匹配)原则:
-- 组合索引的第一个字段必须出现在查询子句中,这个索引才会被用到。如果有一个组合索引(col_a,col_b,col_c),下面的情况都会用到这个索引:
where col_a = "some value";
where col_a = "some value" and col_b = "some value";
where col_a = "some value" and col_c = "some value"; -- 本质等价于 where col_a = "some value";
where col_a = "some value" and col_b = "some value" and col_c = "some value";
where col_b = "some value" and col_a = "some value" and col_c = "some value"; -- mysql会自动优化成第三条的样子
-- 下面的情况就不会用到索引:
where col_b = "aaaa";
where col_b = "aaaa" and col_c = "ccc";
3.5 全文索引
全文索引(fulltext index),主要对字符串类型建立基于分词的索引,主要是基于CHAR、VARCHAR和TEXT的字段上,虽然可以使用like进行模糊匹配,但是其效率远低于全文索引。
① 全文创建
-- 方式1:建表时创建:
create table 表名(
字段名1 类型,
字段名2 类型,
...
fulltext index 索引名(字段名)
);
-- 方式2:建表后创建
create fulltext index 索引名 on 表名(字段名);
② 全文使用
select ... from 表名 where match(全文索引字段名) against('检索内容');
3.6 explain
可以通过执行explain语句查看执行计划来判断是否使用索引。
explain select ... from table_name where ...;
四、聚簇索引和非聚簇索引
- 聚簇索引:索引数据和行数据存储在一起。
- 非聚簇索引:索引数据和行数据分开存储。
InnoDB引擎使用的是聚簇索引:数据和索引文件是.idb,该文件中即存储了索引也存储了数据本身。
MyISAM引擎使用的是非聚簇索引:索引文件.MYI和数据文件.MYD,分开存储。
在InnoDB引擎中,插入数据时一定会和索引值进行绑定,索引值默认是主键,如果没有主键找唯一键,如果没有唯一键找mysql自动生成的行id(rowid)。
五、索引建议
- 在经常需要搜索查询的列上创建索引,可以加快搜索的速度。
- 在作为主键的列上创建索引,强制该列的唯一性和组织表中数据的排列结构。
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的。
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
- 在经常使用WHERE子句的列上创建索引,加快条件的判断速度。
- 为经常出现在关键字ORDER BY、GROUP BY、DISTINCT后面的字段建立索引。
六、浅谈索引底层原理
在讨论MySQL索引时,我们必须先简单了解相关的数据结构,才能更好的学习索引。
这个网站上可以在线演示各种数据结构。
地址:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
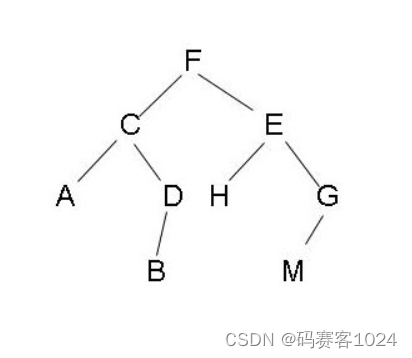
6.1 二叉树
二叉树(Binary tree)是树形结构的一种类型。树中的节点,最多可以有两个子节点,称为:左子树和右子树。如下图,就是一个二叉树结构。
6.2 二叉查找树(Binary Search Tree)
二叉查找树(Binary Search Tree)又称为:二叉排序树(Binary Sort Tree)和 二叉搜索树。
二叉查找树具有如下特点:
(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
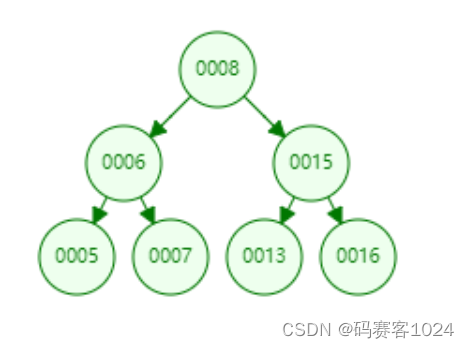
这样的结构好处是,有序,并且是折半查找,效率相对较高。例如:要找元素7
① 从根节点8开始,7比8小,所以去8的左子树找
② 遇到元素6,7比6大,所以去6的右子树找
③ 遇到元素7,匹配成功
可以看出,从7个元素中去找某一个元素,最多也就是3次,即:最多用树的高度次就能找到元素。
但是,在极端情况下,树会变成链表,如图:
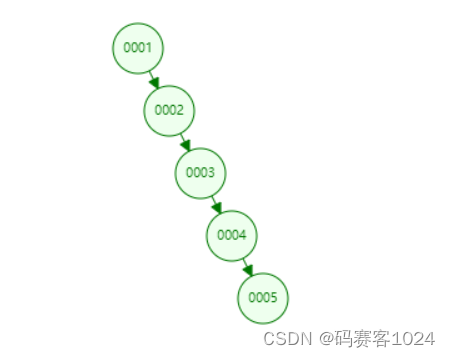
因为后添加的元素大,所有,只能一直添加到右子树上,这就导致了整个树不平衡,形成了类似链表的结构,查找的效率就不高了。
为了解决这个问题,又有了红黑树。
6.3 红黑树
红黑树(Red Black Tree) 是一种自平衡二叉查找树。
他的主要思想是保证左右子树尽量平衡(即:左右子树高度尽量一致),但是红黑树不是严格意义上的平衡二叉树(AVL),因为它的左右子树高差有可能大于 1。
6.4 B树
在前面我们见到的几种树结构,每个节点只能有2个子节点,随着数据量的增加,会导致树的高度越来越大,从而造成查询的效率变低,那就可以让每个节点拥有多个子节点,以此减少树的高度,从而提升效率。 B树就是这样做的,其可以拥有多于2个子节点,并保持数据有序,即:多叉有序树。
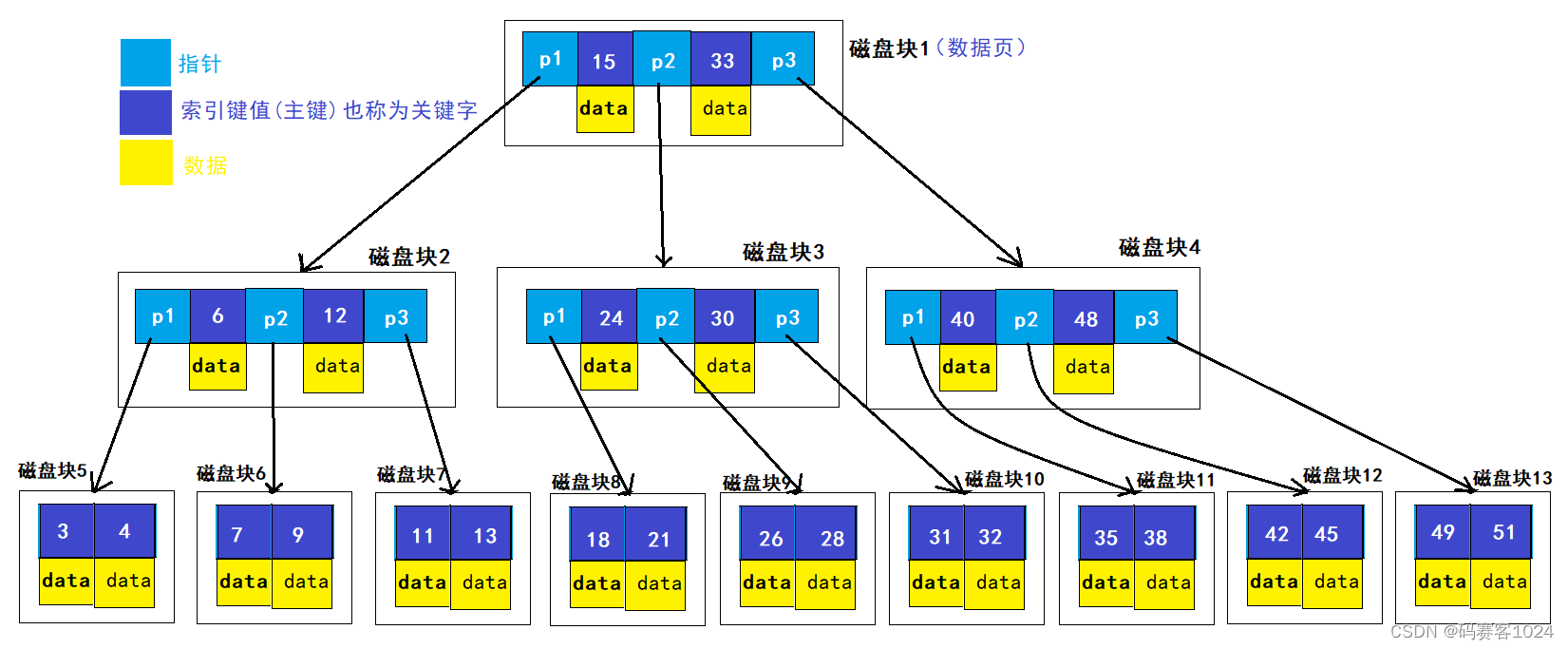
上图中提到了磁盘块的概念,其实更准确的应该叫做:数据页,他是mysql与磁盘交互的最小单位,是mysql内部的数据结构,大小为16kb。mysql每次从磁盘中读取数据默认最小是16kb,要么不读,读了就是16kb(数据页的大小可以修改)。
因此,在16kb中如果既需要保存"索引关键字",又需要保存"数据",显然存储的数据个数是有限的,假设不考虑其他开销,一份数据+一个索引关键字占1k,16kb就是16份数据,按照上图的三层树能够存储的数据是:161616 = 4096,显然存储的数据量还是不多。
6.5 B+树
B+树在B树的基础上做了修改,他将数据保存在了叶子节点(叶子节点拥有全量数据),其余非叶子节点不保存数据,仅保存索引关键和指针信息。
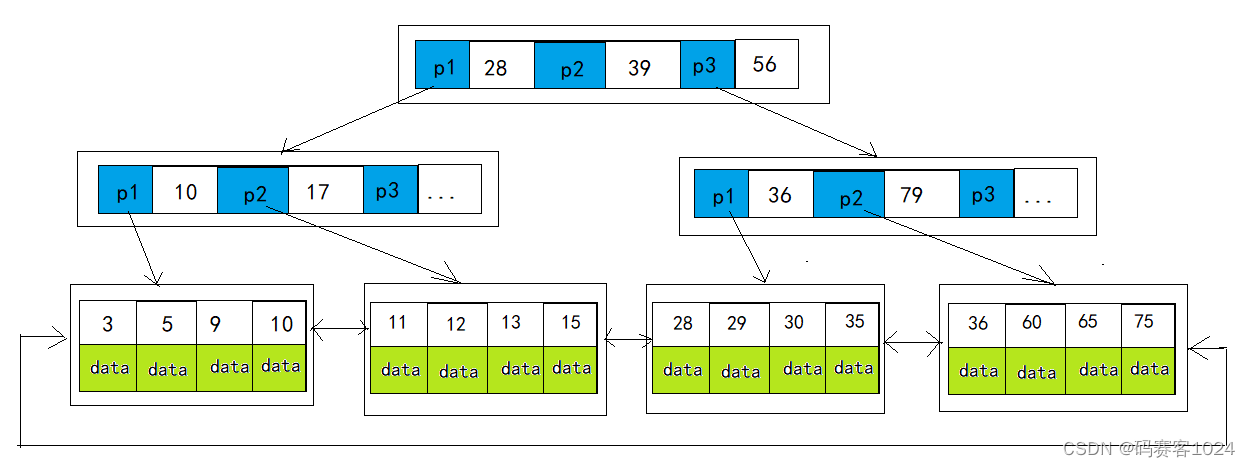
如上图,这样做的好处是能够保存更多的"索引关键字范围",从而在树高不变的情况下保存更多的数据。假设还是3层的树高,如果一个索引关键字+指针信息占10字节,那么16KB中就可以保存:161024/10=1638.4个 ,3层也就是:16381638*16 = 26830440 个。
由此得出结论:
- B+树的非叶子节点,也称索引节点,不存储数据,只存储索引值,相比较B树来说,B+树一个节点可存储更多的索引值,使得整颗B+树变得更矮,减少I/O次数,磁盘读写代价更低。
- B+树的叶子节点,是顺序存储的,并且数据页和数据页之间使用指针连接,范围查询性能更优。
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索。
七、回表
场景1:一张表设置了主键索引,此时,会创建一个B+树来保存数据,使用主键作为查询条件时,则仅需查找一次B+树。
例如:select * from user where id = 1;
场景2:一张表既设置了主键索引,又设置了其他字段为索引字段(例如:name字段),此时,会创建两个B+树来保存数据,第一个B+树和场景1一致,第二个B+树则是存储索引关键字和主键id的值,当使用name字段作为检索条件时,会先查找第二个B+树,基于关键字找到主键id,再用id值到第一个B+树中查找到数据。这种情况就称为:回表。
例如:select * from user where name = 'msk1024';
那么如何解决回表问题呢?
答案是:索引覆盖,最简单的方式就是创建联合索引。
案例:
-- 表t1有a,b,c三个字段,其中a是主键,b上建了索引
SELECT * FROM t1 WHERE a = 1; -- 这样不会产生回表,因为所有的数据在a的索引树中均能找到
SELECT * FROM t1 WHERE b = 2;
-- 这样就会产生回表,因为where条件是b字段,那么会去b的索引树里查找数据,
-- 但b的索引里面只有a,b两个字段的值,没有c,那么这个查询为了取到c字段,
-- 就要取出主键a的值,然后去a的索引树去找c字段的数据。查了两个索引树,这就叫回表。
-- 索引覆盖就是查这个索引能查到你所需要的所有数据,不需要去另外的数据结构去查。
-- 其实就是不用回表。怎么避免?不是必须的字段就不要出现在SELECT里面。或者b,c建联合索引。但具体情况要具体分析,索引字段多了,存储和插入数据时的消耗会更大。