文章目录
- 初始化-AnchorGenerator()
- Anchor平移-grid_priors
- 计算有效anchor-valid_flags
- 参考文献
初始化-AnchorGenerator()
@TASK_UTILS.register_module()
class AnchorGenerator:
def __init__(self, strides, ratios, scales=None, base_sizes=None, scale_major=True, octave_base_scale=None, scales_per_octave=None, centers=None, center_offset=0., use_box_type=False):
# check center and center_offset
if center_offset != 0:
assert centers is None, 'center cannot be set when center_offset' \
f'!=0, {centers} is given.'
if not (0 <= center_offset <= 1):
raise ValueError('center_offset should be in range [0, 1], '
f'{center_offset} is given.')
if centers is not None:
assert len(centers) == len(strides), \
'The number of strides should be the same as centers, got ' \
f'{strides} and {centers}'
# calculate base sizes of anchors
self.strides = [_pair(stride) for stride in strides]
self.base_sizes = [min(stride) for stride in self.strides
] if base_sizes is None else base_sizes
assert len(self.base_sizes) == len(self.strides), \
'The number of strides should be the same as base sizes, got ' \
f'{self.strides} and {self.base_sizes}'
# calculate scales of anchors
assert ((octave_base_scale is not None
and scales_per_octave is not None) ^ (scales is not None)), \
'scales and octave_base_scale with scales_per_octave cannot' \
' be set at the same time'
if scales is not None:
self.scales = torch.Tensor(scales)
elif octave_base_scale is not None and scales_per_octave is not None:
octave_scales = np.array(
[2**(i / scales_per_octave) for i in range(scales_per_octave)])
scales = octave_scales * octave_base_scale
self.scales = torch.Tensor(scales)
else:
raise ValueError('Either scales or octave_base_scale with '
'scales_per_octave should be set')
self.octave_base_scale = octave_base_scale
self.scales_per_octave = scales_per_octave
self.ratios = torch.Tensor(ratios)
self.scale_major = scale_major
self.centers = centers
self.center_offset = center_offset
self.base_anchors = self.gen_base_anchors()
self.use_box_type = use_box_type
构造函数参数讲解
注意:这三个参数scale_major,center_offset,use_box_type我不是很清晰,如果你们看到了有懂的,可以评论告诉我一下,谢谢啦。
strides: (list[int] | list[tuple[int, int]]) 输入的各个特征图的stride步长,若为list[int],则经过_pair(stride)变为list[tuple[int, int]];若为list[tuple[int, int]],表示(w_stride,h_stride)。
ratios: (list[float]) 每个grid上生成多个anchor的ratio,ratio=height/width,基于base_size变化。
scales: (list[int] | None) 每个grid上生成多个anchor的scale,表示缩放比例,基于base_size变化,注意不可以与octave_base_scale、scales_per_octave同时指定。在RetinaNet模型中,指定了octave_base_scaleh和scales_per_octave,因此scales默认为None.
base_sizes: (list[int] | None) 每一特征层的anchor的基本大小。若为None,则默认等于stride(若stride的长宽不一致,则选择短边) 。
scale_major: (bool) 首先每个grid上会生成len(scales)*len(ratios)个base anchor。scale_major将确定base anchor的排列顺序!若为true,表示scale优先,即base anchors的每一行的scale相同;若为false,表示ratios优先,base anchors的每一行的ratio相同。在MMDetection2.0中,默认为True.
octave_base_scale: (int) The base scale of octave。
scales_per_octave: (int) Number of scales for each octave。octave_base_scale and scales_per_octave 用在retinanet中,注意不可以与scales同时指定,scale和octave_base_scale and scales_per_octave的转换公式为:scales = [2**(i / scales_per_octave) for i in range(scales_per_octave)]) * octave_base_scale。
centers: (list[tuple[float, float]] | None) AnchorGenerator类中默认为None,若为None,则每个anchor中心与网格的左上角对齐!yolohead会设计center,使得anchor中心与网格中心对齐。
center_offset: (float) The offset of center in proportion to anchors' width and height。
use_box_type: (bool) Whether to warp anchors with the box type data structure. Defaults to False.
# 计算base_size
self.strides = [_pair(stride) for stride in strides] #
self.base_sizes = [min(stride) for stride in self.strides] if base_sizes is None else base_sizes
下图是RetinaNet网络中的base_size和stride.

# 得到scales. 注意RetinaNet网络中scales为None
if scales is not None:
self.scales = torch.Tensor(scales)
elif octave_base_scale is not None and scales_per_octave is not None:
octave_scales = np.array([2**(i / scales_per_octave) for i in range(scales_per_octave)])
scales = octave_scales * octave_base_scale
self.scales = torch.Tensor(scales)
下图是RetinaNet网络中的octave_base_scale和octave_scales .
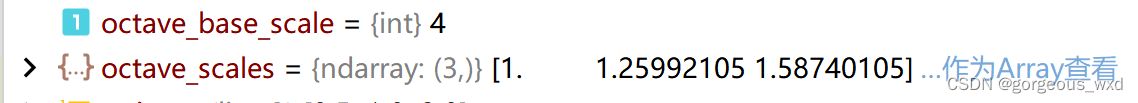
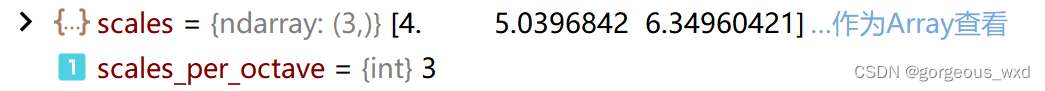
self.octave_base_scale = octave_base_scale # RetinaNet中为4
self.scales_per_octave = scales_per_octave # RetinaNet中为3
self.ratios = torch.Tensor(ratios) # RetinaNet中为[0.5, 1.0, 2.0]
self.scale_major = scale_major # RetinaNet中为True
self.centers = centers # RetinaNet中为None
self.center_offset = center_offset # RetinaNet中为0
self.base_anchors = self.gen_base_anchors() # 在下面会重点讲
self.use_box_type = use_box_type # # RetinaNet中为False
# gen_base_anchors 调用了 gen_single_level_base_anchors,得到多尺度的anchor. gen_single_level_base_anchors 会在下面详细讲。
def gen_base_anchors(self):
multi_level_base_anchors = []
for i, base_size in enumerate(self.base_sizes):
center = None
if self.centers is not None:
center = self.centers[i]
multi_level_base_anchors.append(self.gen_single_level_base_anchors(base_size,vscales=self.scales, ratios=self.ratios, center=center))
return multi_level_base_anchors
下面以RetinaNet为例,讲解一下
def gen_single_level_base_anchors(self, base_size, scales, ratios, center=None):
w = base_size
h = base_size
if center is None:
x_center = self.center_offset * w
y_center = self.center_offset * h
else:
x_center, y_center = center
# h/w = ratios
h_ratios = torch.sqrt(ratios)
w_ratios = 1 / h_ratios
if self.scale_major:
ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)
else:
ws = (w * scales[:, None] * w_ratios[None, :]).view(-1)
hs = (h * scales[:, None] * h_ratios[None, :]).view(-1)
base_anchors = [ x_center - 0.5 * ws, y_center - 0.5 * hs, x_center + 0.5 * ws, y_center + 0.5 * hs]
base_anchors = torch.stack(base_anchors, dim=-1)
return base_anchors
# 当前特征图的w和h
w = base_size
h = base_size
# 计算anchor中心点位置,默认为(0,0)
if center is None:
x_center = self.center_offset * w
y_center = self.center_offset * h
else:
x_center, y_center = center
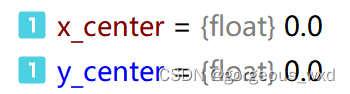
# 保证高宽比为ratios,注意下述操作是对tensor的操作
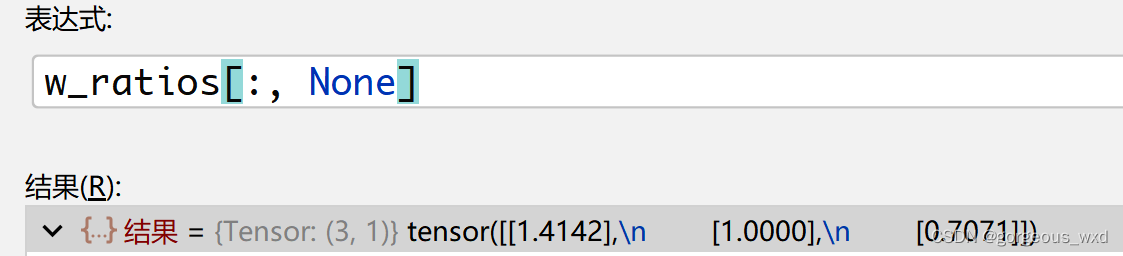
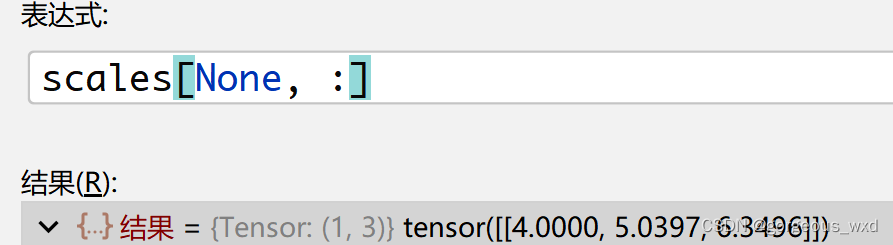
h_ratios = torch.sqrt(ratios)
w_ratios = 1 / h_ratios

ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)
注意:这里通过引入None,扩充维度。
# 生成当前层的base_anchor
base_anchors = [ x_center - 0.5 * ws, y_center - 0.5 * hs, x_center + 0.5 * ws, y_center + 0.5 * hs]
base_anchors = torch.stack(base_anchors, dim=-1)
需要注意scale_major变量的作用,用于确定base anchor的排列顺序。若为true,那先乘以ratios,再乘以scales。举个例子,scales=[1,2],ratios=[0.5,1],base size为(32,32)。那么
当scale_major为true, 则返回[ [(
32
2
,
32
2
32\sqrt2,\frac{32}{\sqrt2}
322,232), (32,32)] , [(
64
2
,
64
2
64\sqrt2,\frac{64}{\sqrt2}
642,264),(64,64)] ]
当scale_major为false,则返回[ [(32,32),(64,64)] , [(
32
2
,
32
2
32\sqrt2,\frac{32}{\sqrt2}
322,232),(
64
2
,
64
2
64\sqrt2,\frac{64}{\sqrt2}
642,264)] ]
Anchor平移-grid_priors
与anchor初始化一样,平移anchor的操作主要在single_level_grid_priors函数中,下面重点讲解这个函数。
def grid_priors(self, featmap_sizes, device='cuda'):
assert self.num_levels == len(featmap_sizes)
multi_level_anchors = []
for i in range(self.num_levels):
anchors = self.single_level_grid_priors(
self.base_anchors[i].to(device),
featmap_sizes[i],
self.strides[i],
device=device)
multi_level_anchors.append(anchors)
return multi_level_anchors # 返回list[num_levels * tensor(H*W*num_anchors,4)]
def single_level_grid_priors(self, base_anchors, featmap_size, stride=(16, 16), device='cuda'):
base_anchors = self.base_anchors[level_idx].to(device).to(dtype)
feat_h, feat_w = featmap_size
stride_w, stride_h = self.strides[level_idx]
shift_x = torch.arange(0, feat_w, device=device).to(dtype) * stride_w
shift_y = torch.arange(0, feat_h, device=device).to(dtype) * stride_h
shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)
all_anchors = base_anchors[None, :, :] + shifts[:, None, :]
all_anchors = all_anchors.view(-1, 4)
if self.use_box_type:
all_anchors = HorizontalBoxes(all_anchors)
return all_anchors
def _meshgrid(self, x, y, row_major=True):
# 获得网格点
xx = x.repeat(len(y))
yy = y.view(-1, 1).repeat(1, len(x)).view(-1)
if row_major:
return xx, yy # xx和yy的shape为(rows*cols,)
else:
return yy, xx
# 获取当前层的base_anchors
base_anchors = self.base_anchors[level_idx].to(device).to(dtype)

# 当前层的特征图大小和步长
feat_h, feat_w = featmap_size
stride_w, stride_h = self.strides[level_idx]

# 乘以stride,映射回原图
shift_x = torch.arange(0, feat_w, device=device).to(dtype) * stride_w
shift_y = torch.arange(0, feat_h, device=device).to(dtype) * stride_h


# 获取anchor的中心点
shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
shift_xx如下,每隔feat_w重复

shift_yy如下,每隔feat_h加stride

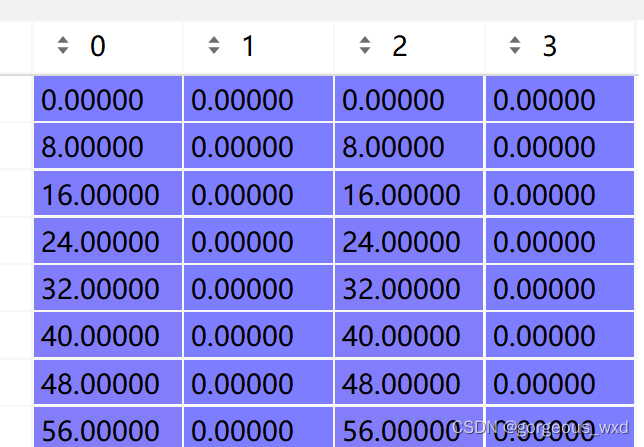
shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)
shifts如下,(0,1)和(2,3)一致,是因为左上角和右上角坐标移动的时候要同时移动。
非常简洁的代码实现
# 得到特征图上所有的anchors
all_anchors = base_anchors[None, :, :] + shifts[:, None, :]
base_anchors[None, :, :] 扩充维度为(1,9,4)
shifts[:, None, :] 扩成维度为(15200,1,4)
相加的时候,base_anchors(1,9,4)会广播为(15200,9,4),即将(9,4)赋值为15200份。shifts(15200,1,4)会广播为(15200,9,4),即将(1,4)复制为9份。
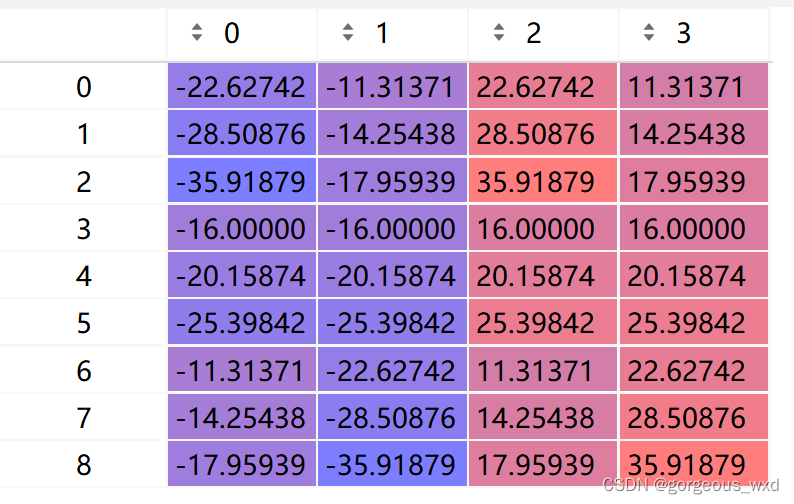
base_anchors如下
shifts[:, None, :]如下,相加的时候会将一行复制为9行。

# (15200,9,4)变为(136800,4)
all_anchors = all_anchors.view(-1, 4)
计算有效anchor-valid_flags
由于在数据预处理时,填充了大量黑边,所以在黑边上的anchor不用计算loss,可以忽略,节省算力。因此valid_flags返回有效的anchor索引。
def valid_flags(self, featmap_sizes, pad_shape, device='cuda'):
# pad_shape是有效的特征图大小,是指Pad后的size,collate之前
assert self.num_levels == len(featmap_sizes)
multi_level_flags = []
for i in range(self.num_levels):
anchor_stride = self.strides[i]
feat_h, feat_w = featmap_sizes[i]
h, w = pad_shape[:2]
valid_feat_h = min(int(np.ceil(h / anchor_stride[1])), feat_h) # 获得有效的特征图
valid_feat_w = min(int(np.ceil(w / anchor_stride[0])), feat_w) # 获得有效的特征图
flags = self.single_level_valid_flags((feat_h, feat_w),
(valid_feat_h, valid_feat_w),
self.num_base_anchors[i],
device=device)
multi_level_flags.append(flags) # 有效位置设置为1,否则为0
return multi_level_flags
def single_level_valid_flags(self,
featmap_size,
valid_size,
num_base_anchors,
device='cuda'):
feat_h, feat_w = featmap_size
valid_h, valid_w = valid_size
assert valid_h <= feat_h and valid_w <= feat_w
# 使用填桶法生成有效的位置
valid_x = torch.zeros(feat_w, dtype=torch.bool, device=device)
valid_y = torch.zeros(feat_h, dtype=torch.bool, device=device)
# 有效的位置填1
valid_x[:valid_w] = 1
valid_y[:valid_h] = 1
valid_xx, valid_yy = self._meshgrid(valid_x, valid_y)
valid = valid_xx & valid_yy # tensor(H*W,) bool
valid = valid[:, None].expand(valid.size(0),num_base_anchors).contiguous().view(-1)
# tensor(H*W*num_base_anchors,) bool
return valid

valid_x如下

valid_y如下

参考文献
- mmdetection源码阅读笔记:prior generator