文章目录
- Transformer
- Transformer的衍生
- BERT
- Pre-training
- BERT与其他方法的关系
- 怎么用BERT做生成式任务?
- GPT
- Pre-training
- Fine-Tuning
- Transformer工具
- 开源库
- 特点
- LLM系列
- 推理服务
大语言模型势不可挡啊。
哲学上来说,语言就是我们的一切,语言所不能到达的地方我们也不能达到。就人类来说,语言或许已经不仅仅是一种工具那么简单,其不仅是人类在物理世界进行活动时不可或缺的媒介,也是我们自身构建精神世界时的一砖一瓦。语言的重要性已经无需多言了。
教会计算机人类的语言(用人类的语言进行思考)是一项艰巨的任务,或许从计算机发明之初这一征程就已经开始了,然而直到现在我们还有很长的路要走。最近,大语言模型大放异彩让我们看到了更大的希望。
大语言模型(Large Language Model,LLM),即规模巨大(参数量巨大)的语言模型,LLM不是一个具体的模型,而是泛指参数量巨大的语言模型。如下图所示,不同的LLM具不同的架构,例如Encoder-only、Encoder-Decoder和Decoder-only等。 这种分类方式又和语言模型中一极其重要的模型有关——Transformer。
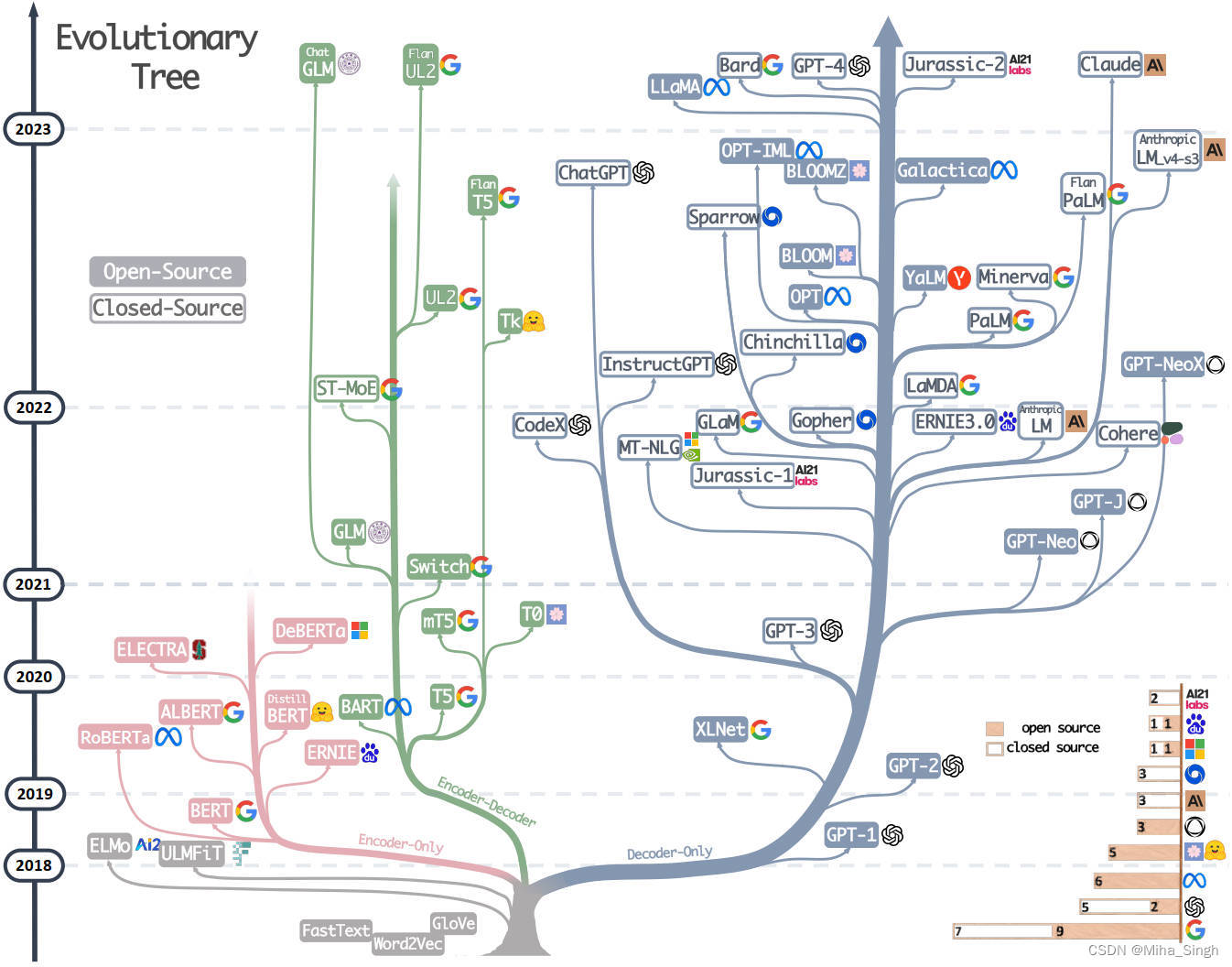
Transformer是2017年提出的一个语言模型,最初被用于解决机器翻译的问题,但随着研究的深入,Trf(指代Transformer)在不同问题,甚至不同领域上大放异彩,在自然语言领域的文本表征、分类、生成、问答等问题上都成为了强劲的解决方案,在视觉领域也很出色。
这篇文章作为我简单学习和梳理Transformer和LLM的一个记录。先列一个提纲:
- Transformer(Trf)必备:掌握其结构,流程,输入数据的形式和处理,训练和优化的方式;
- Trf的衍生:gpt,bert等;
- 现有的Trf工具:如hugging face、fairseq等,如何使用;
- LLM系列:LLM是什么,LLM流程,技术难点;
- 推理服务。
Transformer
Trf的模型结构如下图所示。
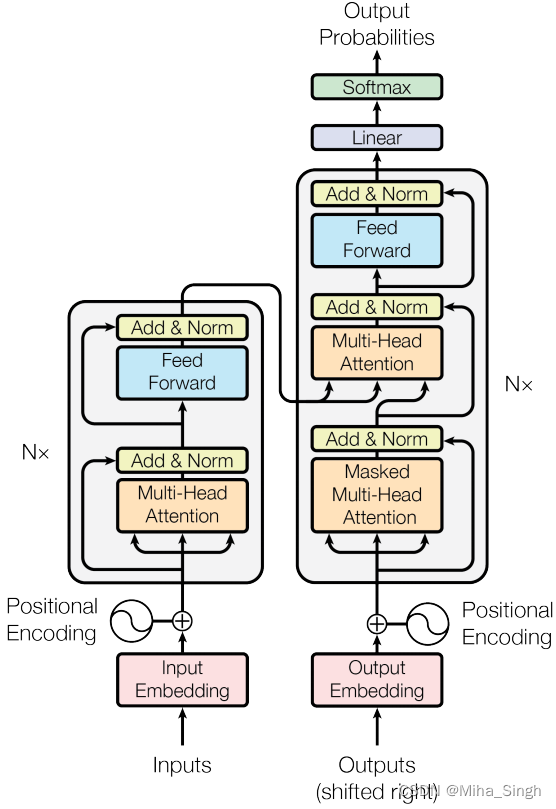
Trf 的组成:编码器和解码器。编码器由相同的层堆叠,每层的结构有两部分,多头注意力和前馈。解码器亦由相同的层堆叠,每层的结构为多头注意力、编码器-解码器注意力和前馈。
编码器中的每个元素对整个序列来说都是可见的。解码器的每一层中有两个多头注意力,一个是解码器的输入部分作为qkv的自注意力,一个是上一个解码器层的输出作为q,最后一个编码器层的输出作为kv的编码-解码注意力。编码器层和解码器层的每一个部分都是残差块的形式而且包括了一个layer norm。
在计算注意力时一般都会涉及到掩码,主要有两种掩码:一种是关于padding的掩码,即将不同长度的序列padding到统一长度,计算注意力时需要掩盖那些padding的位置,另一种是解码器中元素可见性的掩码,即位置i的元素只能看见自身和前面的元素。
就解码器而言,输入和输出的元素个数是一样的,但输入包含了SOS,输出是不包含SOS的,因此把最后一个的预测作为下一个位置的预测。
在训练的时候,解码器是可以并行的,以teacher forcing的方式训练,推断的时候则是串行的方式,预测了一个后并入输入。
在编码器和解码器的输入处都有位置编码,位置编码和token嵌入相加。Trf采用的是三角式位置编码,除此之外还有很多类型的位置编码,如相对位置编码、旋转位置编码(RoPE)和可学习的位置编码等。
关于原始文本到token的一个转换。英语系的语言是天然的分割的,中文的字之间则没有天然的界限。在输入前,首先要做对的是对原始文本进行清洗,清洗其中无意义的符号、多余的标点、纠错、归一化(如统一大小写,繁简体等)等,这样原始文本就是干净的文本了。对文本进行分词后并不直接输入文本,就英语而言,一般会将word转化成sub word,sub word即模型中的token;中文则一般把单字作为token。sub word作为token能够降低OOV出现的概率。如何把word转化为sub word又有很多相关的方法,如Word Piece、ULM和BPE等。
还有太多没写了,想到了再写。
参考资料:
- The Annotated Transformer;
- Transformer的Decoder的输入输出都是什么?;
- transformer的细节到底是怎么样的?。
Transformer的衍生
自Trf提出后,大量以Trf为基础的模型应用到自然语言的各个问题场景上,如文本分类、标注、命名实体识别、文本生成和问答等。这其中就有两大代表:BERT和GPT。据我浅显的了解,语言模型的预训练始于Trf及其衍生模型的盛行。
BERT
Bidirectional Encoder Representations from Transformers,BERT,出自2019年的论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。BERT的模型结构是Trf的编码器部分。就我所知,与其说BERT是一个新的模型,不如说其是一种利用Trf的编码器的方式。
BERT这种方式可以拆成两部分:Pre-training(预训练)和Fine-Tuning(微调)。BERT的预训练是在无标签的数据上学习token嵌入。微调则是预训练完后,针对具体的任务来利用训练好的编码器,例如对于文本分类任务,在编码器后接一个MLP预测文本类别。
Pre-training
预训练的任务分成两种:MLM(Masked LM)和NSP(Next Sentence Prediction)。
-
MLM,即随机替换一段文本中的某些token为[MASK],用编码后的嵌入来预测掩盖处的位置的实际的token(与CBOW利用上下文预测中间的词很像哦)。
- 实际操作:随机掩盖15%的token,将原token替换为[MASK]。由于在微调时可能并不存在[MASK],微调和预训练可能会存在一点不匹配。因此BERT中并不完全替换那15%的token,而是把选择的那些token的80%替换为[MASK],10%替换为随机的token,10%保持不变。
- 这样做的原因:1)微调时是没有[MASK]的,这会造成数据偏差;2)防止模型只在看到[MASK]才提取token间的关系,填入随机的token使模型(编码器的注意力部分)能够学习到token间的关系。最后计算损失的时候是在[MASK]的token上计算。玩笑的说,只用[MASK]替换了80%的token是为了迷惑模型,添加噪声,使其必须依赖上下文的环境来学习embedding。
*只计算[MASK]位置(15%80%)的损失。
-
NSP,即将两个句子拼接后送入编码器,预测这两个句子是否相邻。为什么要做这个任务呢?因为预测两个句子之间的关系体现在很多语言任务中,如文章中段落的匹配、蕴含关系的判断和基于文章的问题与段落的匹配等。
在把句子打包输入进编码器时,BERT是这样操作的。在第一个句子的前面添加一个[CLS],不同的句子间用[SEP]分隔,输入的最后也添加[SEP]。得到输入的toekn序列后,输入时每个位置的嵌入 = token嵌入+位置嵌入+segment嵌入,如下图所示。segment嵌入标识该token属于第一个句子还是第二个句子。BERT论文中显示位置编码是统一编号的,并没有按照所属句子区分位置编号。在判断两个句子的关系时,用编码器的输出中[CLS]对应的嵌入进行预测。
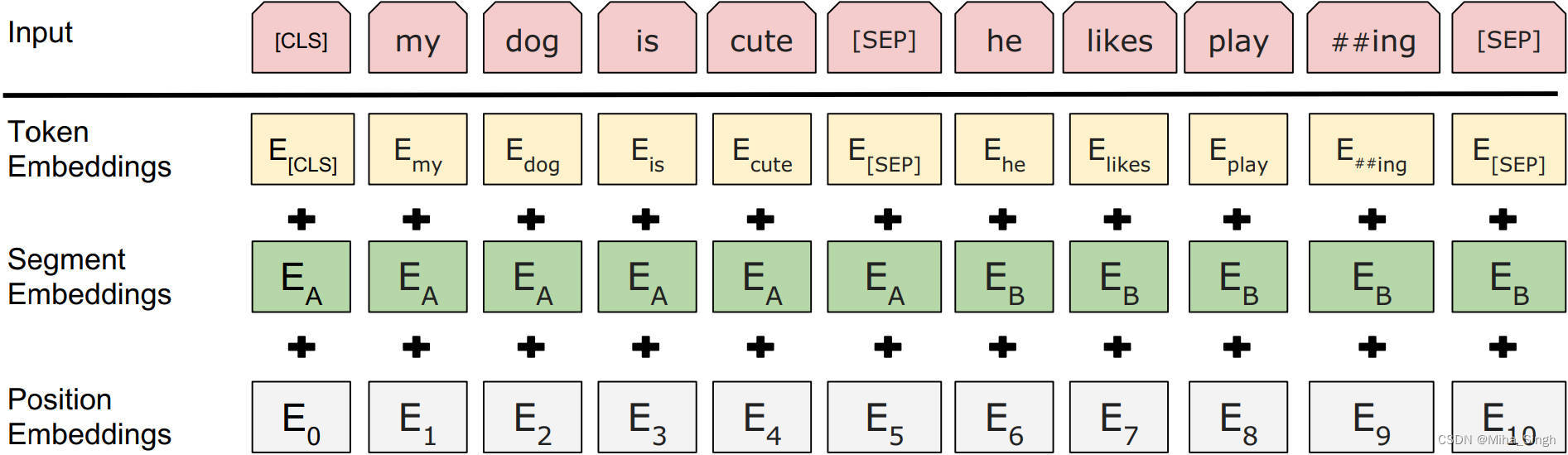
预训练时,MLM和NSP两个任务是一起训练的,而不是分步训练的,因此预训练的损失也是两个任务损失之和。BERT预训练中的样本如下图所示:
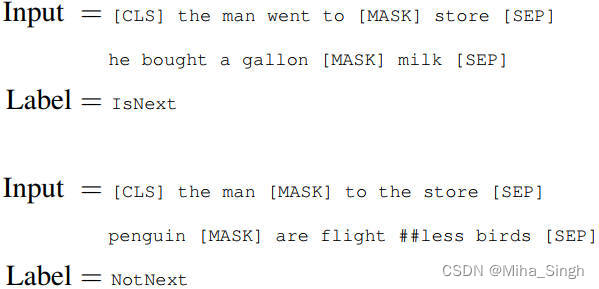 ### Fine-Tuning
### Fine-Tuning
预训练完后,嵌入表和编码器的参数都学习好了,之后便可使用这些来完成下游任务。因此,如何完成下游的任务是在编码器的输出的基础上完成的。在编码器的输出部分,包含了输入的每个token的表示、一些特殊token(如[MASK]、[SEP])的表示。因此,可以据此构建token-level的任务,以每个token的表示来预测,如序列标注或者问答等;也可用[CLS]的表示来做分类任务。
BERT与其他方法的关系
-
BERT与CBOW。word2vec中的CBOW是以窗口内的单词预测窗口中心词,即用上下文预测预测中间的词。这样一看,其实BERT的MLM和CBOW还是很像的,不同点:
- BERT没有窗口的限制,可以看到完整的上下文;
- MLM中目标词是通过注意力计算得到的,CBOW是平均;
- CBOW会在句子的每个词上训练,但是MLM的目标是采样得到的;
-
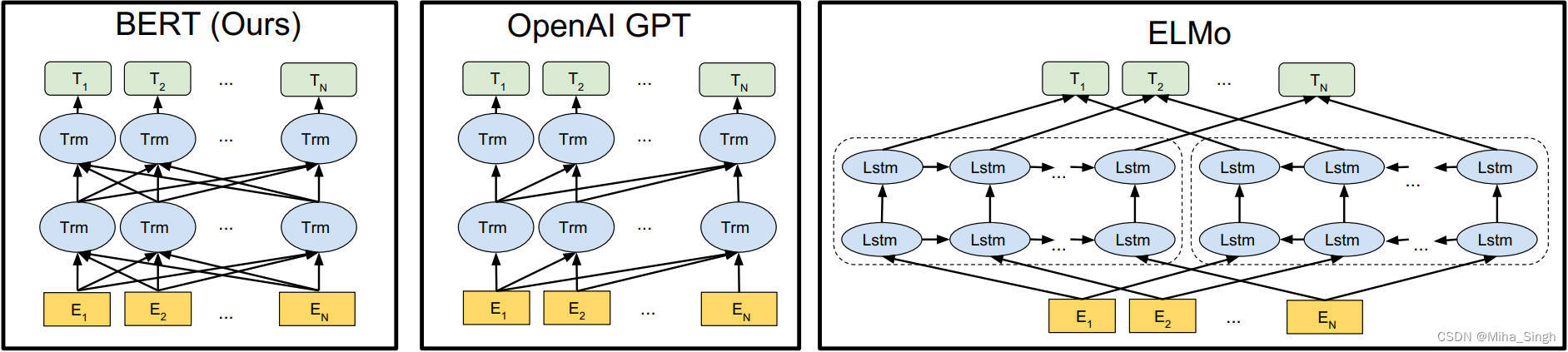
BERT与GPT。与BERT一样,GPT也是基于Trf的。不同点:
- 架构不同。GPT采用的是Trf的解码器部分,BERT是编码器部分。GPT更适合生成式任务,根据上文更准确预测下一个出现的词,而BERT则更好理解整个文本的语义;
- 输入序列中的可见性不同。如下图所示,BERT中每个元素对序列中其他元素都是可见的,即BERT中的Bidirectional。由于GPT一般用于生成式任务,因此其具有trf中解码器部分的特点,位置 i i i看不到其后面的内容;
- 其他的不同,如训练数据的不同、微调方式的不同(例如,BERT为不同的微调任务选择了不同的学习率、GPT微调任务的学习率都一样)和GPT只在微调时用了特殊token(如[CLS]和[SEP])等;
-
BERT与ELMo。ELMo(Embeddings from Language Models)是一个双向词表征模型。
- BERT和ELMo都是双向的,但是二者的双向并不相同,ELMo的方向是通过LSTM捕捉的,但是双向是通过分别捕捉从左向右和从右向左达到的;
- BERT采用的是Trf中编码器、注意力和位置编码,ELMo则是LSTM;
怎么用BERT做生成式任务?
都知道BERT是Trf的编码器部分,常用来对捕捉文本的语义,但是否能用来做生成式任务呢?
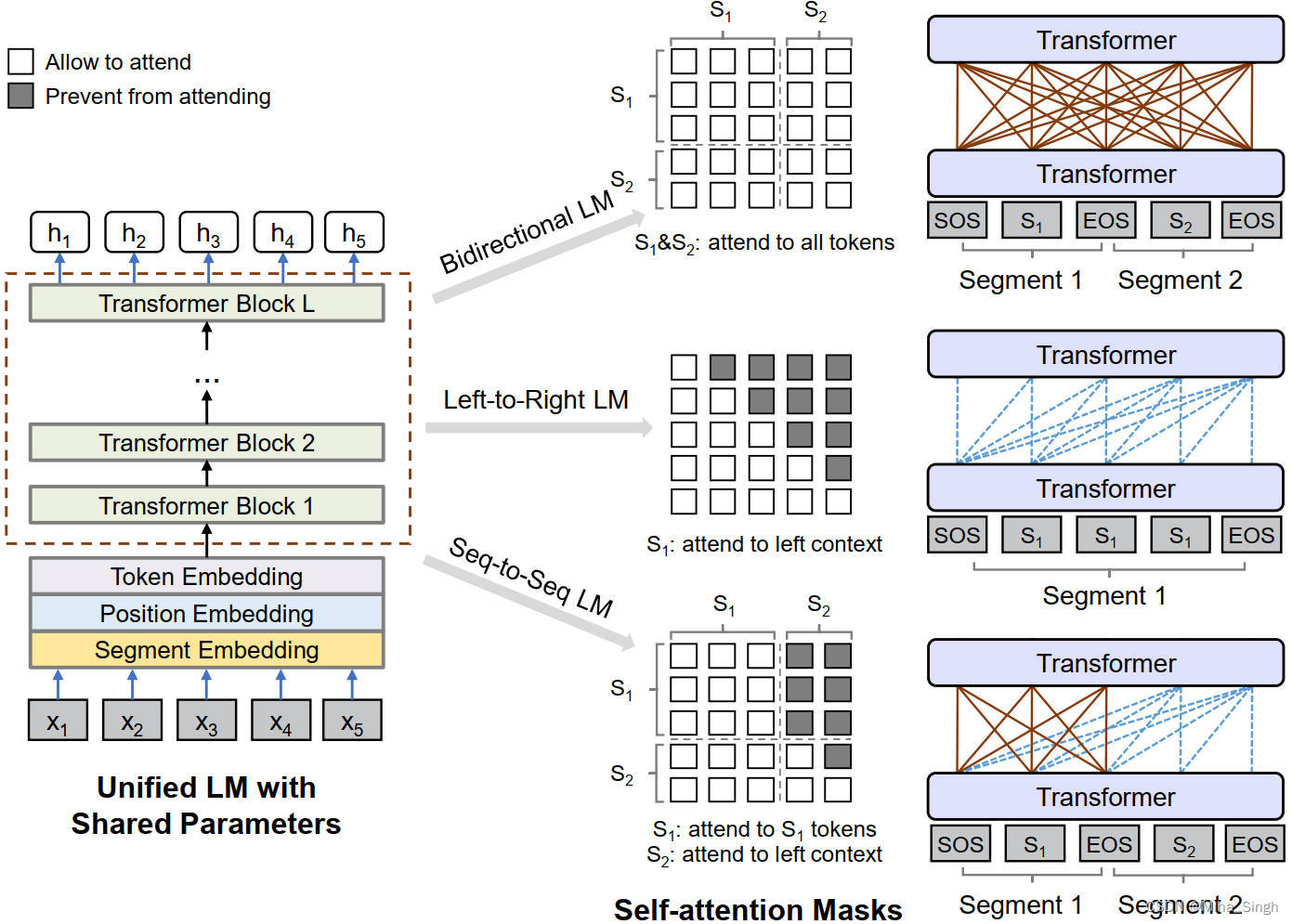
微软2019年在《Unified Language Model Pre-training for Natural Language Understanding and Generation》中提出了UniLM(Unified pre-trained Language Model),该模型采用了BERT的模型结构,但与不同的是提出了不同的预训练任务:单向的LM、双向的LM和Seq-to-Seq的LM。
关于如何应用BERT做生成式任务还需要更深入的了解。
GPT
Generative Pre-Training,GPT,出自OpenAI于2018(比BERT还早)年的论文《Improving Language Understanding by Generative Pre-Training 》。GPT采用的是Trf的解码器部分,也是一种语言模型预训练的方式,由预训练和微调组成。GPT中的层与Trf中解码器的层并不完全一样,去除了编码器-解码器注意力,其模型结构如下图:
Pre-training
GPT中的预训练采用的是无监督的语言建模方式,即最大化句子(
U
\mathcal{U}
U)出现的似然概率,
Θ
\Theta
Θ为模型参数:
L
(
U
)
=
∑
i
P
(
u
i
∣
u
i
−
k
,
⋯
,
u
i
−
1
;
Θ
)
L(\mathcal{U}) = \sum_i P(u_i | u_{i-k}, \cdots, u_{i-1}; \Theta)
L(U)=i∑P(ui∣ui−k,⋯,ui−1;Θ)
从上式中可以看出,即用
i
i
i之前的token预测
i
i
i,与Trf中编码器是一致的,即根据上文预测下一个单词。看一下预训练的计算过程:
h
0
=
U
W
e
+
W
p
h
l
=
transformer_block
(
h
l
−
1
)
,
∀
i
∈
[
1
,
n
]
P
(
u
)
=
softmax
(
h
n
W
e
T
)
h_0 = U W_e + W_p \\ h_l = \text{transformer\_block}(h_{l-1}),\ \forall i \in [1, n] \\ P(u) = \text{softmax}(h_n W_e^T)
h0=UWe+Wphl=transformer_block(hl−1), ∀i∈[1,n]P(u)=softmax(hnWeT)
其中
U
=
(
u
−
k
,
⋯
,
u
−
1
)
U=(u_{-k}, \cdots, u_{-1})
U=(u−k,⋯,u−1)表示前
k
k
k个token的向量,可以看作是token的独热编码,
W
e
W_e
We是token的嵌入矩阵,因此
U
W
e
UW_e
UWe就像查表操作,
W
p
W_p
Wp表示位置编码矩阵,
h
0
h_0
h0就是GPT的输入了。经过多个
transformer_block
\text{transformer\_block}
transformer_block的处理后得到解码器的输出。再看最后一步,也是我目前有点疑惑的地方,按照我的理解
h
n
W
e
T
h_n W_e^T
hnWeT应该是一个矩阵才对,这个怎么表示下一个词的概率呢?
Fine-Tuning
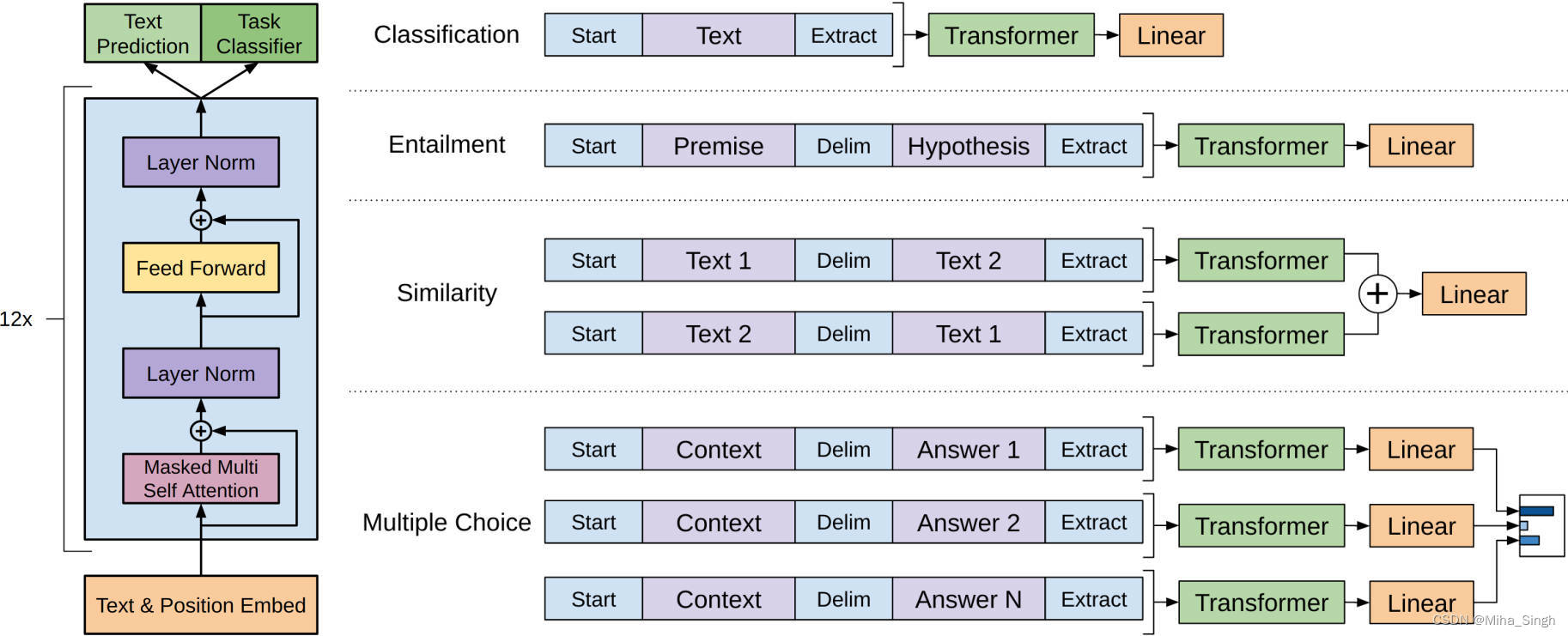
通过预训练学习token嵌入、位置嵌入和模型参数后,就可以在此基础上进行微调了,GPT的微调是监督任务。GPT的微调任务如上如所示,包含了文本分类、蕴含判断、句子对相似性和多项选择等(在论文的实验部分对微调任务种类进行了介绍,可以看到相比BERT,GPT的微调任务是很多的)。在这些有监督的任务上,GPT使用最后一层的最后一个token的表征作为task-specific层的输入。实际上,GPT也把预训练任务作为微调时的辅助任务,因此微调的损失包含了分类损失和似然损失。
关于GPT微调任务的一个疑惑点是其Masked-Multi-Head-Attention是怎么做的,难道也是只能看到前面的token?但是微调的这些任务并不是生成式的任务,因此可能只有GPT的预训练任务是生成式的。
随着ChatGPT的发布,GPT吸引了足够多的目光,关于大模型的应用也来到了幕前,开始了商业化的征途。这里介绍的GPT只是GPT的起点——GPT-1,后续OpenAI提出的GPT系列在此基础上不断改进,出现了:
- GPT-2:《Language Models are Unsupervised Multitask Learners》;
- GPT-3:《Language Models are Few-Shot Learners》;
- InstructGPT:《Training language models to follow instructions with human feedback》。
Transformer工具
Trf犹如一块好钢,被锻造成了不同的利剑,成为了各个门派的大杀器,如何运用这样一块好钢来处理自己的问题是很重要的——怎么把Trf用在我们自己的问题上呢?
一种方法是自己实现Trf相关的种种模块,然后根据自己的需求进行调用。一切从头看起来是一项很有艰巨且很有挑战的工作,并且要达到在实际中可用的程度需要较高的工程能力。不过能自己实现其中的某些模块是很重要的,如自注意力、多头注意力、带掩码的注意力等、注意力剪枝、padding/mask的技巧等。
开源库
当然,也有一些现成的开源工具是可以使用的,比如:
- Hugging Face的Transformer库;
- Facebook的fairseq;
- NVIDIA的Megatron-LM;
- 哈佛NLP团队的openNMT-py;
特点
以上是几个比较常见的Trf实现库,这些开源工具不止实现了初始的Trf,还包括了后续提出的比较经典的模型。这些工具还有一个特点,与其他的软件包一样,使用者完全使用的是工具的代码、API等,现有的很多大语言模型工具的开源实现的重点是模型的权重文件。由于Trf系的模型参数量较大,且模型的预训练对模型的效果非常重要,训练的技巧和成本都很高。因此,权重文件就成了语言模型库的核心,形成了一种”热拔插“式的服务。
大语言模型的使用场景,使得工具的性能也成为了必须考虑的一点,例如剪枝、量化、分布式训练以及部署等。
LLM系列
大语言模型即参数量巨大的语言模型,但是多大才算大呢?看看现有的一些大语言模型的参数量:
| 模型 | 参数量 | 模型大小 | 训练数 | 输入长度 | 训练硬件及时间 | 发布时间 |
|---|---|---|---|---|---|---|
| GPT | 117M | 479MB | 7K本书,5GB,40K词汇量 | 512 | 8*P600*30d | 2018 |
| BERT | 340M | 2019 | ||||
| GPT-2 | 1.5B | 6.43GB | 8M网页,50K+词汇量 | 1024 | 256*TPU v3*- | 2019 |
| GPT-3 | 175B | 45TB | 2048 | 2020 | ||
| T5 | 11B | 45.2GB | 2020 |
以上只列了一小部分经典的大语言模型,一些新的或者商用的大模型已经远不止这个规模了。可以发现,大模型的大:1)参数量巨大;2)训练数据量巨大;3)训练成本大。据我浅显的了解,目前的LLM都是在Trf的基础上构建的,参照论文《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》,有如下划分:
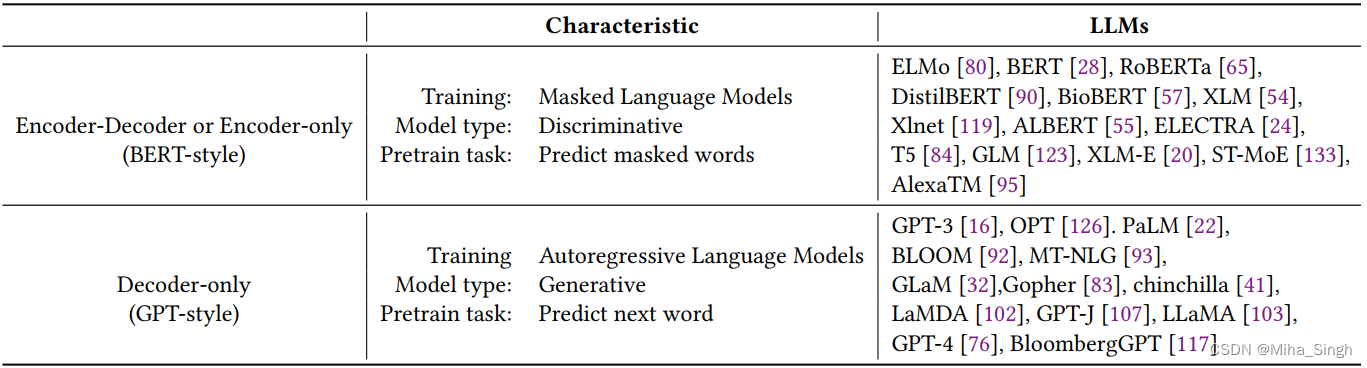
可见,对LLM划分时的几个特点:1)模型结构;2)生成式or判别式;3)与训练任务。关于LLM模型架构有很多探讨,不同的架构可以用于不同的任务,但是一般会有其比较擅长的场景。采用何种架构,对不同架构从效果、性能及特点等方面的分析是认识LLMs的一个重要手段,这方面的一些参考资料:
- 科学空间-为什么现在的LLM都是Decoder-only的架构?;
- What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?;
除了以编 / 解码器进行划分,也有一些以Autoregressive(AR)和Non-Autoregressive(NAR)进行划分。
推理服务
当模型已经训练好,准备投入生产环境中时,构建高效的推理服务也是一个值得深入研究的问题,也是我一直都想拓展、深入的一个方向。推理的几个目标:
- 低成本。LLMs模型参数量巨大,计算量巨大,对存储和计算的要求都比较高。为了存储参数,需要较高的内存和显存;为了计算速度,也需要性能强劲的CPU / GPU。此外,在一些边缘设备、嵌入设备或者移动设备等上面进行推理时,还需要考虑功耗的问题;
- 高效率。即推理速度快、服务的响应延迟小。为了达到这个目的,特别是在(硬件)资源受限的情况下,需要对模型做一些单独的处理,如剪枝、量化和蒸馏等,还可以在推理引擎上进行优化,如算子融合和优化、贴合硬件的优化和分布式并行等;
- 易扩展。真实场景下,问题的解决方案是比较复杂的,也不是单个模型或者一次部署就能解决的,因此对不同类的模型和算子等的支持也是比较重要的。这就涉及到推理服务器(框架)的选择了。
推理服务更多的是一个系统型的工作,涉及到的内容繁杂,要做到大规模、高性能的推理服务,需要对模型的实现与优化、算子实现与优化、训练框架、模型编译、CUDA和推理框架等有深入的了解。
一些参考:
- 老潘的AI部署以及工业落地学习之路;
- Full Stack Optimization of Transformer Inference: a Survey。