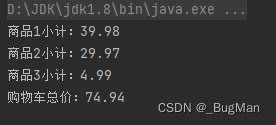
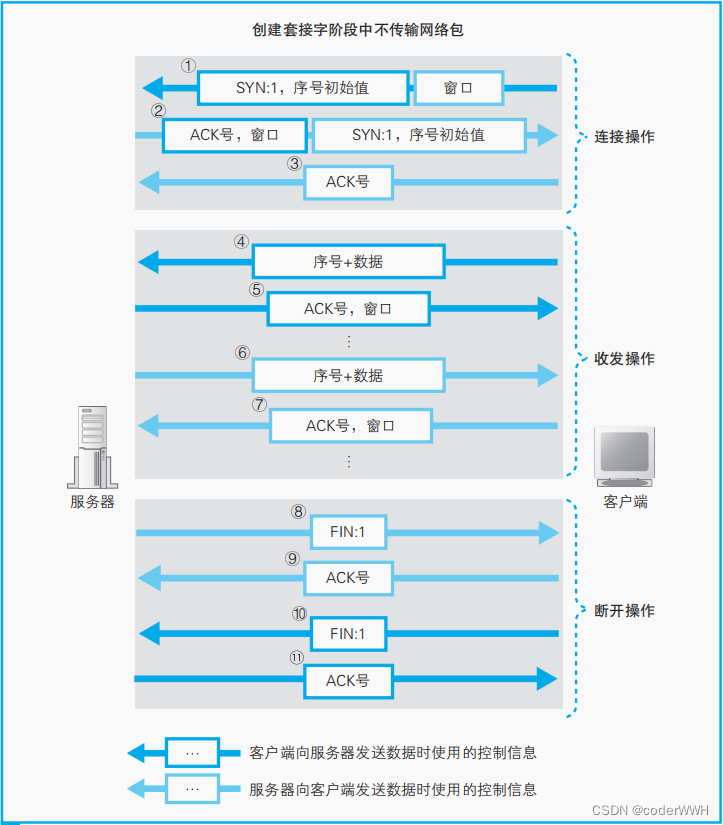
卷积层和池化层的实现
如前所述,CNN 中各层间传递的数据是 4 维数据。所谓 4 维数据,比如数据的形状是 (10, 1, 28, 28),则它对应 10 个高为 28、长为 28、通道为 1 的数据。用 Python 来实现的话,如下所示
>>> x = np.random.rand(10, 1, 28, 28) # 随机生成数据
>>> x.shape
(10, 1, 28, 28)
这里,如果要访问第 1 个数据,只要写 x[0]就可以了
如果要访问第 1 个数据的第 1 个通道的空间数据,可以写成下面这样。
>>> x[0, 0] # 或者x[0][0]
像这样,CNN 中处理的是 4 维数据,因此卷积运算的实现看上去会很复杂,但是通过使用下面要介绍的 im2col这个技巧,问题就会变得很简单。
基于 im2col 的展开
如果老老实实地实现卷积运算,估计要重复好几层的 for语句。这样的实现有点麻烦。这里不使用 for语句,而是使用 im2col(image to column)这个便利的函数进行简单的实现。
im2col是一个函数,将输入数据展开以适合滤波器(权重)。
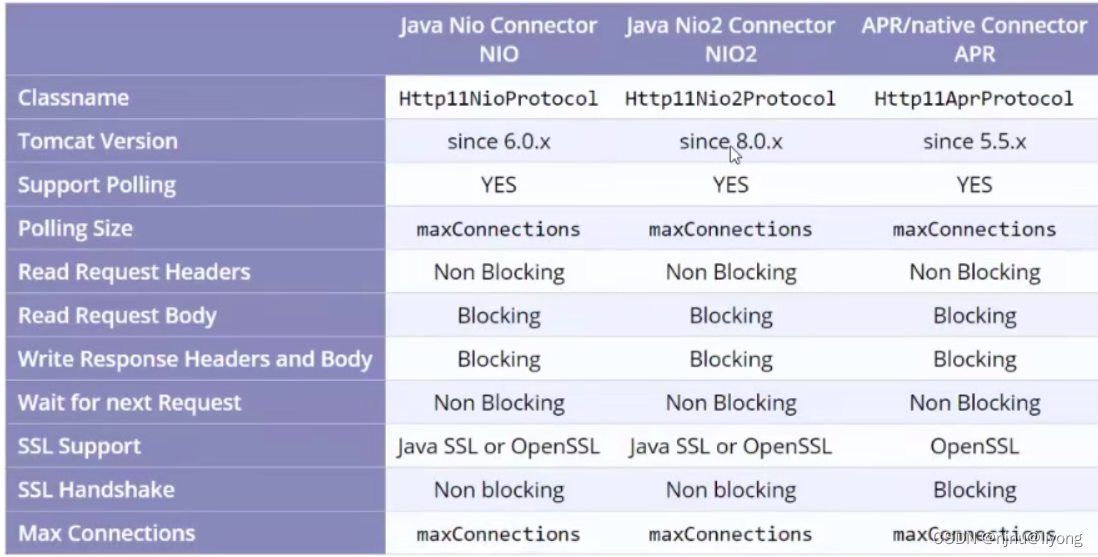
如下图所示,对 3 维的输入数据应用 im2col后,数据转换为 2 维矩阵(正确地讲,是把包含批数量的 4 维数据转换成了 2 维数据)。
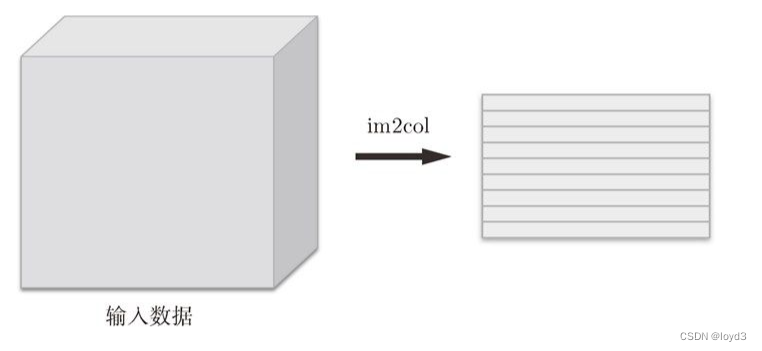
具体地说,如下图所示,对于输入数据,将应用滤波器的区域(3 维方块)横向展开为 1 列。im2col会在所有应用滤波器的地方进行这个展开处理。
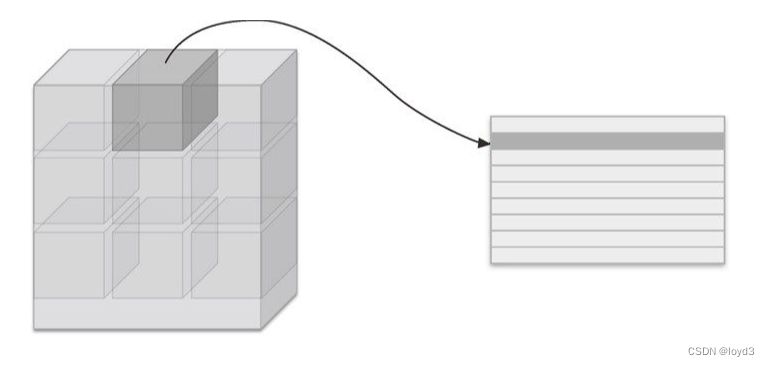
在上图中,为了便于观察,将步幅设置得很大,以使滤波器的应用区域不重叠。而在实际的卷积运算中,滤波器的应用区域几乎都是重叠的。在滤波器的应用区域重叠的情况下,使用 im2col展开后,展开后的元素个数会多于原方块的元素个数。因此,使用 im2col的实现存在比普通的实现消耗更多内存的缺点。但是,汇总成一个大的矩阵进行计算,对计算机的计算颇有益处。比如,在矩阵计算的库(线性代数库)等中,矩阵计算的实现已被高度最优化,可以高速地进行大矩阵的乘法运算。因此,通过归结到矩阵计算上,可以有效地利用线性代数库。
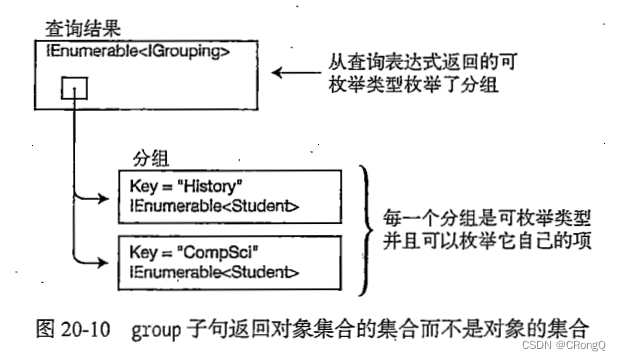
如下图所示,基于 im2col方式的输出结果是 2 维矩阵。因为 CNN 中数据会保存为 4 维数组,所以要将 2 维输出数据转换为合适的形状。以上就是卷积层的实现流程。

卷积运算的滤波器处理的细节:将滤波器纵向展开为 1 列,并计算和 im2col 展开的数据的矩阵乘积,最后转换(reshape)为输出数据的大小
卷积层的实现
im2col的实现如下
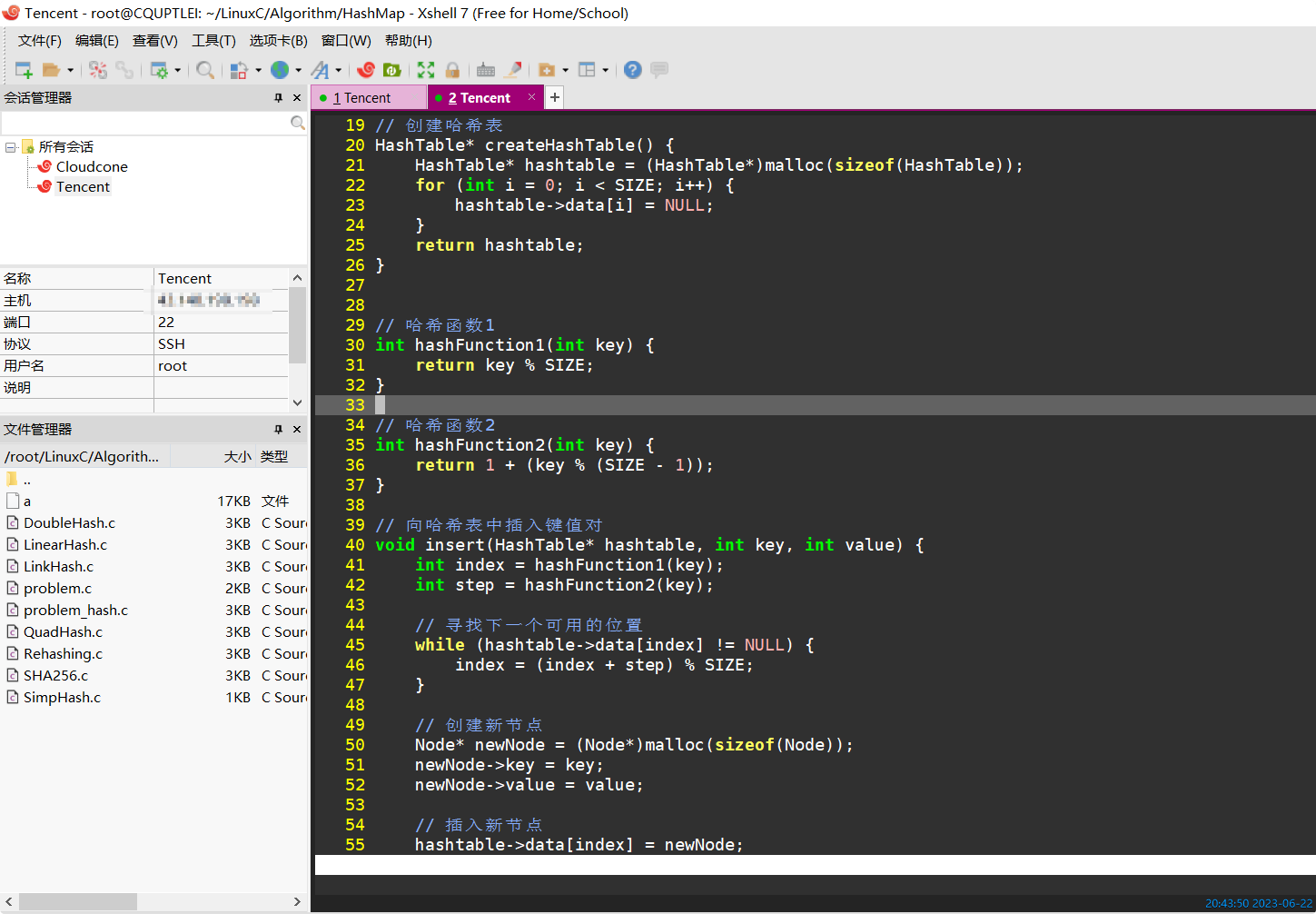
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
"""
Parameters
----------
input_data : 由(数据量, 通道, 高, 长)的4维数组构成的输入数据
filter_h : 滤波器的高
filter_w : 滤波器的长
stride : 步幅
pad : 填充
Returns
-------
col : 2维数组
"""
N, C, H, W = input_data.shape
out_h = (H + 2*pad - filter_h)//stride + 1
out_w = (W + 2*pad - filter_w)//stride + 1
img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1)
return col
input_data——由(数据量,通道,高,长)的 4 维数组构成的输入数据
filter_h——滤波器的高
filter_w——滤波器的长
stride——步幅
pad——填充
下面使用im2col来实现卷积层,这里将卷积层实现为名为Convolution的类
class Convolution:
def __init__(self, W, b, stride=1,pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = init(1+ (H + 2*self.pad - FH) / self.stride)
out_w = init(1+ (W + 2*self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T # 滤波器的展开
out = np.dot(col, col_W) + self.b
out = out.reshape(N,out_h,out_w, -1).transpose(0, 3, 1, 2)
return out
度上的元素个数,以使多维数组的元素个数前后一致。比如,(10, 3, 5, 5) 形状的数组的元素个数共有 750 个,指定 reshape(10,-1)后,就会转换成 (10, 75) 形状的数组。
展开滤波器的部分将各个滤波器的方块纵向展开为 1 列。这里通过 reshape(FN,-1)将参数指定为 -1,这是 reshape的一个便利的功能。通过在 reshape时指定为 -1,reshape函数会自动计算 -1维度上的元素个数,以使多维数组的元素个数前后一致。比如,(10, 3, 5, 5) 形状的数组的元素个数共有 750 个,指定 reshape(10,-1)后,就会转换成 (10, 75) 形状的数组
池化层的实现
池化层也要使用 im2col展开输入数据
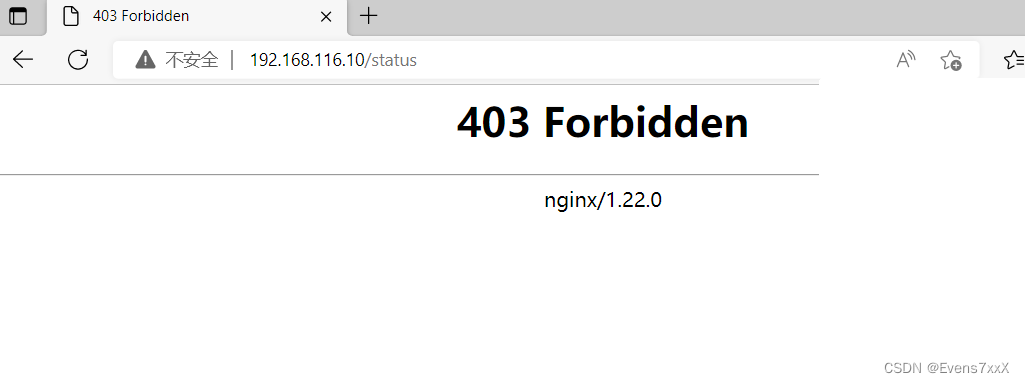
不过,池化的情况下,在通道方向上是独立的,这一点和卷积层不同。具体地讲,池化的应用区域按通道单独展开。
如下图:
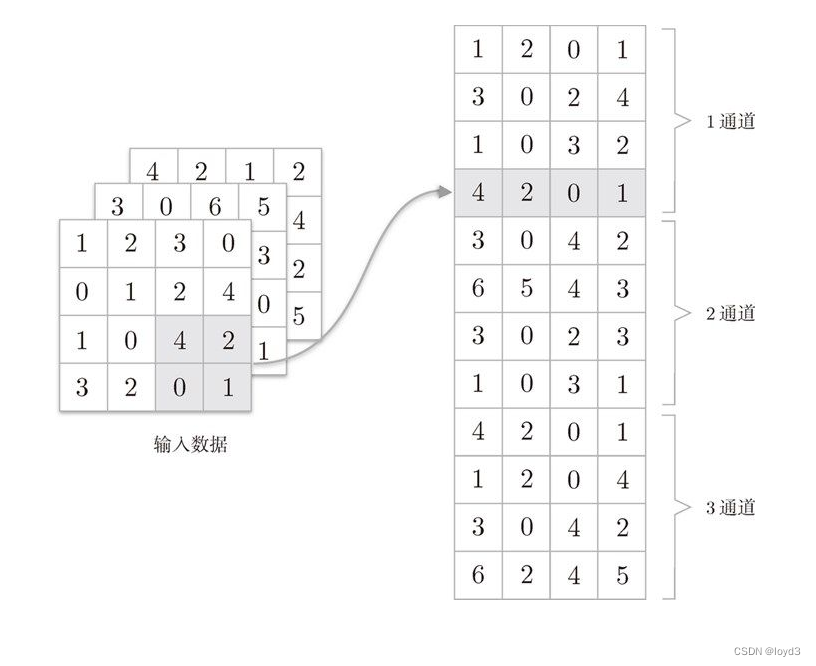
像这样展开之后,只需对展开的矩阵求各行的最大值,并转换为合适的形状即可
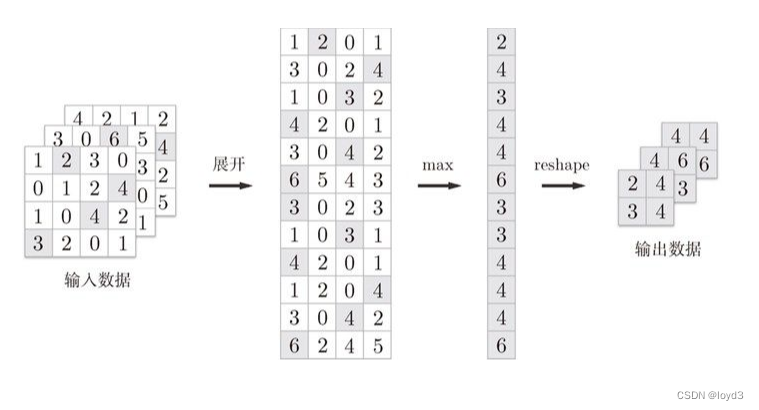
池化层的实现按下面 3 个阶段进行
- 展开输入数据。
- 求各行的最大值。
- 转换为合适的输出大小。
下面看Python的实际实现:
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
def forward(self, x):
N, C, H, W = x.shape
out_h = init(1+ (H - self.pool_h) / self.stride)
out_w = init(1+ (W - self.pool_w) / self.stride)
# 展开(1)
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h*pool_w)
# 最大值(2)
out = np.max(col, axis=1)
# 转换(3)
out = out.reshape(N, out_h, out_w, C).transpose(0,3,1,2)
return out