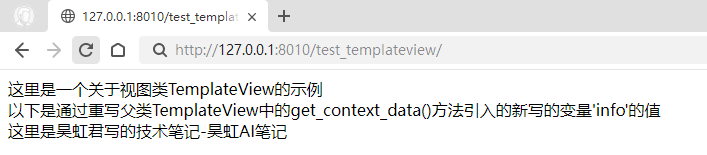
想必大家平时也没有很注意UVM1.1版本和UVM1.2版本的不同之处,只有在用一些以前UVM1.1能支持的功能,到了UVM1.2却出现编译报错,找不到对应的变量或者函数或者类的时候,才意识到这两个版本的差异。笔者也是遇到了1个打印问题,去研究下UVM1.2的Release Notes,并整理了这一篇文章,说明了比较重要的修改内容和影响,当然还有一些小修小改在这里就不提了,希望能帮助到大家。
1. Configuration的修改
UVM1.1中的set_config_[int, string, object]()和get_config_[int, string, object]()方法在UVM1.2中已弃用。根据UVM编码指导,用户应该使用uvm_config_db::[set,get]() API来替代。UVM1.2使用typedef也预先定义了一些便捷类型给大家使用,比如:
typedef uvm_config_db#(uvm_bitstream_t) uvm_config_int;
typedef uvm_config_db#(string) uvm_config_string;
typedef uvm_config_db#(uvm_object) uvm_config_object;
typedef uvm_config_db#(uvm_object_wrapper) uvm_config_wrapper;但是uvm_config_db里的uvm_bitstream_t类型默认长度是4096bits,会占用0.5KB的内存,对资源高效利用非常不友好,如果有整型类型的数据需要set()或get()的话,最好使用所配置值的实际类型。
另外需要注意的是UVM1.1的set_config_object和get_config_object可以通过参数指定是否自动clone,在切换到uvm_config_object后,已经没有提供这个参数了
2. 定义全新的uvm_coreservice_t类,将各全局组件打包起来
UVM1.2新定义了一个uvm_coreservice_t类,它把UVM1.1中分散的uvm_factory和uvm_report_server包起来了,也打包了新增的uvm_tr_database和uvm_visitor。这样用户以后就不需要直接引用这些单独的组件,因为在uvm_coreservice_t类的singleton中提供了API来获取到这些组件。以获取uvm_factory的object为例,UVM1.2里的标准流程为:
uvm_coreservice_t cs = uvm_coreservice_t::get();
uvm_factory f = cs.get_factory();
不过由于uvm_factory类是singleton类型的,直接使用uvm_factory f=uvm_factory::get()其实也蛮方便的。同样的,对于uvm_report_server的object的获取,也可以直接使用:
uvm_report_server rs=uvm_report_server:: get_server();另一点就是UVM1.2很神奇,user可以扩展uvm_coreservice_t类型,然后通过UVM_CORESERVICE_TYPE把UVM自带的uvm_coreservice_t给替换掉,不过我觉得99%人不会用这个吧。
3. 将原来的类拆成抽象类和”default”子类
在UVM1.1中,uvm_factory和uvm_report_server基类可以被用户直接定制。而在UVM1.2中,这些基类都是抽象类,原先基类的功能被转移到从抽象类扩展出来的”default”子类中。这些”default”子类定义如下:
class uvm_default_factory extends uvm_factory;
...
endclass
class uvm_default_report_server extends uvm_report_server;
...
endclass
因此,如果有用户在UVM1.1中是在uvm_factory或uvm_report_server基础上扩展出子类,那么在UVM1.2中需要更新到从对应”default”类上扩展。比如:
UVM1.1的写法:class user_factory extends uvm_factory;
UVM1.2的写法:class user_factory extends uvm_default_factory;4. 舍弃uvm_pkg::factory来获取uvm_factory对象
在UVM1.1中,可以直接使用uvm_pkg::factory来引用singleton的uvm_factory,也就是说uvm_pkg::factory和uvm_factory::get()两者是等价的。
但在UVM1.2中,删掉了uvm_pkg::factory方式,必须通过uvm_factory::get()方式。
5. Factory override功能的增强
在使用factory override去覆写uvm_factory返回的类型。典型的流程是创建1个从基本test扩展的test,并在扩展test中指定覆盖对象。因此,当创建object或component时,用户肯定要知道返回的具体类型是什么。Factory按类型override的语法如下:
<original_type>::type_id::set_type_override(<substitute_type>::get_type(), replace);在UVM1.1中,如果<substitute_type>和<original_type>一样,那么什么都不会发生,之前的任何override都继续有效。但在UVM1.2中,如果<substitute_type>和<original_type>一样,它会移除掉对<original_type>的所有的覆写,也相当于是撤销factory override功能。不过好的TB永远不应该使用这个特性。例子如下:
// Perform an override
set_type_override_by_type(old_type::get_type(), new_type::get_type());
// Undo the override (撤销override)
set_type_override_by_type(old_type::get_type(), old_type::get_type());
6. message宏打印的增强
UVM1.2在message处理上做了一些改动,把之前`uvm_xxx_context的宏的里CNTXT名字替换成RO名字,这个RO传递的是uvm_report_object类型或它子类的object。对于标准的message宏(uvm_info等)倒没有做任何改动。
另外,UVM1.2提供了一系列新的begin-end宏来创建具有相同severity的message对象。
`uvm_info_begin(ID, MSG, VERBOSITY, RM = __uvm_msg)
`uvm_info_end
`uvm_warning_begin(ID, MSG, RM = __uvm_msg)
`uvm_warning_end
`uvm_error_begin(ID, MSG, RM = __uvm_msg)
`uvm_error_end
`uvm_fatal_begin(ID, MSG, RM = __uvm_msg)
`uvm_fatal_end
`uvm_info_context_begin(ID, MSG, VERBOSITY, RO, RM = __uvm_msg)
`uvm_info_context_end
`uvm_warning_context_begin(ID, MSG, RO, RM = __uvm_msg)
`uvm_warning_context_end
`uvm_error_context_begin(ID, MSG, RO, RM = __uvm_msg)
`uvm_error_context_end
`uvm_fatal_context_begin(ID, MSG, RO, RM = __uvm_msg)
`uvm_fatal_context_end
这些message宏也有ID和VERBOSITY,因此set_report_action和其它message函数仍然可以对它们进行处理。用这些message宏的一个好处就是现在可以通过是使用额外的宏向message对象里添加字段,这些额外的宏有:
`uvm_message_add_tag(NAME, VALUE, ACTION=(UVM_LOG|UVM_RM_RECORD))
`uvm_message_add_int(VAR, RADIX, LABEL = "", ACTION=(UVM_LOG|UVM_RM_RECORD))
`uvm_message_add_string(VAR, LABEL = "", ACTION=(UVM_LOG|UVM_RM_RECORD))
`uvm_message_add_object(VAR, LABEL = "", ACTION=(UVM_LOG|UVM_RM_RECORD))
上述两者宏结合起来的使用例子如下:
`uvm_info_begin("MY_ID", "This is my message...", UVM_LOW)
`uvm_message_add_tag("my_color", "red")
`uvm_message_add_int(my_int, UVM_DEC)
`uvm_message_add_string(my_string)
`uvm_message_add_object(my_obj)
`uvm_info_end
主要对message对象的每次添加字段都允许指定自己的操作(ACTION=xxx)。TB很少需要对message的各个部分指定不同的操作,但是这个功能也算是给了一种使用新方式了。
7. objection管理
UVM1.2向uvm_objection增加了set_propagate_mode()函数,以允许对objection的raise和drop绕过UVM hierarchy的所有中间层,并立即向上传播到uvm_top。UVM编码指南也是建议objection只应该在testcase level中raise和drop,testcase和uvm_top之间没有中间层,因此好的TB永远也不需要使用set_propagate_mode()这个特性。
如果没有使用set_propagate_mode()把m_prop_mode设置为1,那么1个组件raise objection会传播给parent,parent再继续向上传播,直至uvm_test_top。虽然这样的传播可能是有用的,但如果它们没有被TB使用,那么它们只是一个不必要的性能损失。因此如果TB不打算使用这个功能,那么可以通过将传播模式m_prop_mode设置为0来提高性能,这样1个组件raise objection的话,只会传播给uvm_test_top,UVM hierarchy中间节点的组件完全没感知到。
另外,UVM1.2舍弃了uvm_sequence_base::starting_phase的方式,也就是不能直接在sequence里使用starting_phase,然后调用starting_phase.raise_objection(this),因为直接使用starting_phase是不受writes-after-reads保护的,如果phase的objection在raise和drop之间被改变了值,这将导致奇怪的行为(包括fatals或hang)。对应的,它是在uvm_sequence_base类中增加了set_automatic_phase_objection()函数来完成之前starting_phase的功能的,而且更简便。用户只需要调用set_automatic_phase_objection(1)函数,那么sequence在启动的时候会自动raise和drop objection。举个例子:
// 如果在my_sequence的new函数了调用了set_automatic_phase_objection(1)
function my_sequence::new(string name="unnamed");
super.new(name);
set_automatic_phase_objection(1);
endfunction : new
// 那么从时间轴角度来看,objection的自动raise和drop节点像下面一样:
start() is executed
--! Objection is raised !--
pre_start() is executed
pre_body() is optionally executed
body() is executed
post_body() is optionally executed
post_start() is executed
--! Objection is dropped !--
start() unblocks
不过使用set_automatic_phase_objection(1)函数去自动控制objection违反了UVM编码指南,其实还是不建议使用的。大家还是直接在testcase level去控制objection最好。
8. 枚举名的改动
UVM1.2将uvm_sequencer_arb_mode枚举变量的元素名改了。原先是:
SEQ_ARB_FIFO (Default)
SEQ_ARB_WEIGHTED
SEQ_ARB_RANDOM
SEQ_ARB_STRICT_FIFO
SEQ_ARB_STRICT_RANDOM
SEQ_ARB_USE
现在是:(其实就是在元素名前加上UVM_)
UVM_SEQ_ARB_FIFO (Default)
UVM_SEQ_ARB_WEIGHTED
UVM_SEQ_ARB_RANDOM
UVM_SEQ_ARB_STRICT_FIFO
UVM_SEQ_ARB_STRICT_RANDOM
UVM_SEQ_ARB_USER
9. 新增record的宏
Transaction记录是通过在UVM中使用宏来进行的,以允许特定工具或EDA供应商将跟踪的信息写入数据库。在UVM1.1中,宏是:
`uvm_record_attribute // never call directly
`uvm_record_field
与message的改动类似,除了以上的宏,UVM1.2新增了一些宏来记录特定类型,用户可以指定要记录的名称和值。有以下这些新增宏:
`uvm_record_int
`uvm_record_string
`uvm_record_time
`uvm_record_real
10. uvm_event变为参数化类
UVM1.2的uvm_event是一个参数化类,且uvm_event类被拆成两个类,1个是抽象uvm_event_base类,然后uvm_event#(T)从这个抽象类扩展出来。
其实这个改动是很小的,UVM1.1的uvm_event相当于是UVM1.2的uvm_event#(T= uvm_object)。
11. 支持command line用string配置枚举值
UVM1.2支持在command line上按string名称设置枚举值。这个功能是通过uvm_enum_wrapper#(T)类的from_name()函数实现的,在执行自动配置是由`uvm_field_enum宏使用,因此可以用set using uvm_config_db#(string)或uvm_cmdline_processor::+uvm_set_config_string去设置枚举变量的值。
UVM1.2也支持在command line上设置default sequence。命令格式为:
<sim command> +uvm_set_default_sequence=path.to.sequencer,main_phase,seq_type12. 枚举类型名字变换
枚举类型uvm_severity_type名字改成uvm_severity。
13. phase增加callback接口
增加了phase状态切换的callbacks,增加uvm_phase_cb和uvm_phase_cb_pool来提供额外的phase APIs接口。
14. uvm_object子类的强制构造函数
UVM1.2需要从uvm_object扩展的任何类都指定以下形式的构造函数:
class my_obj extends uvm_object;
...
`uvm_object_utils(my_obj)
function new(string name = "my_obj")
super.new(name);
...
endfunction
...
endclass
也就是说必须在构造函数里传递string名字,否则编译会报错。然而在UVM1.1中,这种类型构造函数并不是UVM强制的,它们是可选的。如果没有指定构造函数,则由SystemVerilog提供默认的构造函数。如果用户想用UVM1.1的这种方案,那么需要定义UVM_OBJECT_DO_NOT_NEED_CONSTRUCTOR宏,但是不建议,因为UVM1.3版本将彻底使用强制的方案。
针对UVM1.2的这个强制要求,UVM也提供了add_uvm_object_new.pl脚本去帮助处理,有需要的可以用下。
15. 引入uvm_integral_t新整型类型
为了提升memory性能,UVM1.2引进了uvm_integral_t新类型,它的定义如下:
typedef logic signed [63:0] uvm_integral_t;相比uvm_bitstream_t的4096-bit位宽,uvm_integral_t只用了64-bit,大大减少memory的开销。 对这种新类型的支持也添加到uvm_printer、uvm_packer、uvm_recorder和uvm_comparer,以及由“uvm_field_*”宏提供的自动配置中。
为了提供一致的API,uvm_printer::print_int()函数已经被不推荐使用了,取而代之的是uvm_printer::print_field_int(),它最多可以打印64-bit的整型数据。
16. Message系统的管理采用基于对象的方式
UVM1.2对Message系统的管理进行了修改,将系统彻底改造为使用基于对象的方法传递message,而不是多次传递多个字段,这同时扩展了message传递的API功能。uvm_report_server::process_report已经被uvm_report_server::execute_report_message替代了。uvm_report_server::compose_message已经被uvm_report_server::compose_report_message替代了。在对uvm_recorder的支持上,也增加了uvm_tr_stream和uvm_tr_database两个类。
对message系统的更改对大部分用户其实还好,只是UVM1.2用了另一种方式实现了之前UVM1.1的功能。
顺便说一下,平时跑testcase结束的时候,UVM会自动打印出” UVM Report Summary”,也就有几个UVM_INFO/ UVM_WARNING/ UVM_ERROR/ UVM_FATAL之类的,这个在UVM1.1是强制的,但在UVM1.2下,如果UVM_VERBOSITY设置为UVM_NONE,那testcase结束时将不会打印出” UVM Report Summary”,这一点大家需要注意的。特别在跑regression的时候,我们经常会将UVM_VERBOSITY设置为UVM_NONE。
结语
UVM1.2虽然把UVM1.1的一些旧功能舍弃了,但提供了UVM_NO_DEPRECATED宏,如果用户没有定义这个宏的话(默认是没有定义这个宏),那么UVM1.1被丢弃的功能仍然可以在UVM1.2中使用。但建议用户如果使用UVM1.2的话,要定义上UVM_NO_DEPRECATED宏。约束自己早点把代码迁移到UVM1.2上,而不是一直在UVM1.1上。UVM之所以提供了UVM_NO_DEPRECATED宏,就是想暂时给用户留点迁移代码的时间,在UVM1.3版本上,UVM1.1的旧功能将彻底丢弃了。
从UVM1.1版本过渡到UVM1.2版本引起的许多向后兼容性问题可以通过在用户代码中进行相当简单的搜索和替换来解决。另外,UVM官方提供了uvm11-to-uvm12.pl的脚本来帮助过渡。下面的命令将更新位于当前工作目录和任何子目录中的所有SystemVerilog源文件:
uvm11-to-uvm12.pl --write有关脚本的使用详情,可以加—help命令行选项查看。
不过这个脚本可能无法自动识别所有向后不兼容的情况,用户可能需要手动修复一些情况。这些问题中的大多数都会导致编译报错,所以它们很容易被识别出来。