目录
- 前言
- 一、基础层
- 1-0、Input层
- 1-1、Dense层
- 1-2、Activation层(激活层)、Dropout层
- 1-3、Lambda层
- 1-4、Flatten层
- 二、嵌入层
- 2-1、Embedding层
- 三、池化层
- 3-1、MaxPooling1D层
- 3-2、MaxPooling2D层
- 3-3、AveragePooling1D层
- 3-4、AveragePooling2D层
- 3-5、GlobalMaxPooling1D层
- 3-6、GlobalAveragePooling1D层
- 总结
前言
最近的心情就像窗外的天气一样阴沉。。。
一、基础层
1-0、Input层
Input层:用来初始化一个keras张量。
# 常用参数解析
#
1、shape:整型元组格式,表示输入数据的维度,比如shape=(32, )表示预期输入向量集合是32维的。不清楚输入维度时可以设置为None。
2、batch_size:整型,表示batch大小,批次大小
3、name:给这层网络取名,名字要有唯一性,默认None时系统会自动取名字
4、dype:输入的数据类型,可以是float32,float64,int32
1-1、Dense层
Dense层:Dense就是常用的全连接层,所实现的运算是 o u t p u t = a c t i v a t i o n ( d o t ( i n p u t , k e r n e l ) + b i a s ) output = activation(dot(input, kernel)+bias) output=activation(dot(input,kernel)+bias)其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,dot表示点积运算,只有当use_bias=True才会添加。
tensorflow.keras.layers.Dense
1、units:大于0的整数,代表该层的输出维度。
2、activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
3、use_bias: 布尔值,是否使用偏置项
4、kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
5、bias_initializer:偏置向量初始化方法,为预定义初始化方法名的字符串,或用于初始化偏置向量的初始化器。参考initializers
6、kernel_regularizer:施加在权重上的正则项,为Regularizer对象
7、bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
8、activity_regularizer:施加在输出上的正则项,为Regularizer对象
9、kernel_constraints:施加在权重上的约束项,为Constraints对象
10、bias_constraints:施加在偏置上的约束项,为Constraints对象
输入
形如(batch_size, …, input_dim)的nD张量,最常见的情况为(batch_size, input_dim)的2D张量
输出
形如(batch_size, …, units)的nD张量,最常见的情况为(batch_size, units)的2D张量
实践代码:
from tensorflow.keras.layers import Input, Bidirectional, Dense, Conv1D, LSTM, Flatten, Concatenate, Attention, GlobalAveragePooling1D, Embedding
from tensorflow.keras.models import Sequential
model = Sequential()
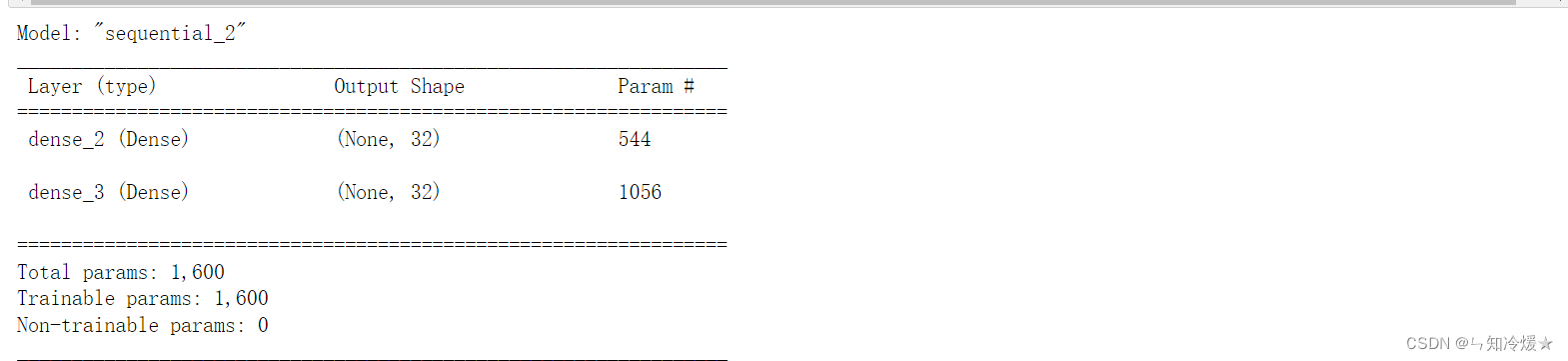
# 这里代表的意思是输入数组的shape为(None, 16)。 输出数组为 shape=(None, 32),
model.add(Input(shape = (16, )))
model.add(Dense(32))
model.add(Dense(32))
model.compile(optimizer='Adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics='acc')
model.summary()
结果:
1-2、Activation层(激活层)、Dropout层
Activation层: 激活函数,激活层对一个层的输出施加激活函数
常见预定义激活函数:softmax、elu、selu、softplus、relu、tanh、sigmoid、linear。
Dropout层: 为输入数据施加Dropout。Dropout将在训练过程中每次更新参数时按一定概率(rate)随机断开输入神经元,Dropout层用于防止过拟合。参数包括rate(断开神经元的比例)、seed(整数,即使用的随机种子)。
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Input, Bidirectional, Dense, Conv1D, LSTM, Flatten, Concatenate, Attention, GlobalAveragePooling1D, Embedding
from tensorflow.keras.models import Sequential
import tensorflow as tf
model = Sequential()
# 这里代表的意思是输入数组的shape为(None, 16)。 输出数组为 shape=(None, 32),
model.add(Input(shape = (16, )))
model.add(Dense(64, activation='tanh'))
model.compile(optimizer='Adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics='acc')
model.summary()
1-3、Lambda层
Lambda层: 自定义层最简单的方式就是通过Lambda层,即对上一层的输出进行任何自定义的函数操作
1、function:要实现的函数,该函数仅接受一个变量,即上一层的输出
2、output_shape:函数应该返回的值的shape,可以是一个tuple,也可以是一个根据输入shape计算输出shape的函数
3、mask: 掩膜
4、arguments:可选,字典,用来记录向函数中传递的其他关键字参数
1-4、Flatten层
Flatten层: Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Input, Bidirectional, Flatten,Dense, Conv1D, LSTM, Flatten, Concatenate, Attention, GlobalAveragePooling1D, Embedding
from tensorflow.keras.models import Sequential
import tensorflow as tf
model = Sequential()
# 这里代表的意思是输入数组的shape为(None, 16)。 输出数组为 shape=(None, 32),
model.add(Input(shape = (16, )))
model.add(Dense(64, activation='tanh'))
model.add(Flatten())
model.compile(optimizer='Adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics='acc')
model.summary()

二、嵌入层
2-1、Embedding层
Embedding层:只能作为模型的第一层
参数:
1、input_dim:大或等于0的整数,字典长度,即输入数据最大下标+1
2、output_dim:大于0的整数,代表全连接嵌入的维度
3、embeddings_initializer: 嵌入矩阵的初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
4、embeddings_regularizer: 嵌入矩阵的正则项,为Regularizer对象
5、embeddings_constraint: 嵌入矩阵的约束项,为Constraints对象
6、mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,模型中后续的层必须都支持masking,否则会抛出异常。如果该值为True,则下标0在字典中不可用,input_dim应设置为|vocabulary| + 1。
7、input_length:当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
输入:
形如(samples,sequence_length)的2D张量
输出:
形如(samples, sequence_length, output_dim)的3D张量。(即将内部的每个变量扩展延升了)
实践代码:
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Input, Bidirectional, Flatten,Dense, Conv1D, LSTM, Flatten, Concatenate, Attention, GlobalAveragePooling1D, Embedding
from tensorflow.keras.models import Sequential
import tensorflow as tf
model = Sequential()
#
model.add(Embedding(1000, 64, input_length=10))
# the model will take as input an integer matrix of size (batch, input_length).
# the largest integer (i.e. word index) in the input should be no larger than 999 (vocabulary size).
# now model.output_shape == (None, 10, 64), where None is the batch dimension.
input_array = np.random.randint(1000, size=(32, 10))
model.compile('rmsprop', 'mse')
model.summary()
结果:

三、池化层
3-1、MaxPooling1D层
参数
1、pool_size:整数,池化窗口大小
2、strides:整数或None,下采样因子,例如设2将会使得输出shape为输入的一半,若为None则默认值为pool_size。
3、padding:‘valid’或者‘same’
输入shape
形如(samples,steps,features)的3D张量
输出shape
形如(samples,downsampled_steps,features)的3D张量
实践代码:
from tensorflow.keras.layers import Input, Bidirectional, Dense, Conv1D, LSTM, Flatten, Concatenate, Attention, GlobalAveragePooling1D, Embedding,MaxPool1D,MaxPool2D,AveragePooling1D, AveragePooling2D,MaxPooling1D
from tensorflow.keras.models import Sequential
import tensorflow as tf
# demo1
x = tf.constant([1., 2., 3., 4., 5.])
x = tf.reshape(x, [1, 5, 1])
# 简单理解:最大池化是,滑动窗口大小为2,步长为1,没有填充。
max_pool_1d = MaxPooling1D(pool_size=2, strides=1, padding='valid')
print(max_pool_1d(x)) # shape = (1,4,1) array=[[[2],[3],[4],[5]]]
# demo2
x = tf.constant([1., 2., 3., 4., 5.])
x = tf.reshape(x, [1, 5, 1])
max_pool_1d = MaxPooling1D(pool_size=2, strides=1, padding='same')
print(max_pool_1d(x)) # shape = (1,5,1) array=[[[2],[3],[4],[5],[5]]]
输出:

3-2、MaxPooling2D层
参数
pool_size:整数或长为2的整数tuple,代表在两个方向(竖直,水平)上的下采样因子,如取(2,2)将使图片在两个维度上均变为原长的一半。为整数意为各个维度值相同且为该数字。
strides:整数或长为2的整数tuple,或者None,步长值。
border_mode:‘valid’或者‘same’
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape
‘channels_first’模式下,为形如(samples,channels, rows,cols)的4D张量
‘channels_last’模式下,为形如(samples,rows, cols,channels)的4D张量
输出shape
‘channels_first’模式下,为形如(samples,channels, pooled_rows, pooled_cols)的4D张量
‘channels_last’模式下,为形如(samples,pooled_rows, pooled_cols,channels)的4D张量
3-3、AveragePooling1D层
keras.layers.pooling.AveragePooling1D(pool_size=2, strides=None, padding=‘valid’)
对时域1D信号进行平均值池化
参数
pool_size:整数,池化窗口大小
strides:整数或None,下采样因子,例如设2将会使得输出shape为输入的一半,若为None则默认值为pool_size。
padding:‘valid’或者‘same’
输入shape
形如(samples,steps,features)的3D张量
输出shape
形如(samples,downsampled_steps,features)的3D张量
3-4、AveragePooling2D层
keras.layers.pooling.AveragePooling2D(pool_size=(2, 2), strides=None, padding=‘valid’, data_format=None)
为空域信号施加平均值池化
参数
pool_size:整数或长为2的整数tuple,代表在两个方向(竖直,水平)上的下采样因子,如取(2,2)将使图片在两个维度上均变为原长的一半。为整数意为各个维度值相同且为该数字。
strides:整数或长为2的整数tuple,或者None,步长值。
border_mode:‘valid’或者‘same’
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape
‘channels_first’模式下,为形如(samples,channels, rows,cols)的4D张量
‘channels_last’模式下,为形如(samples,rows, cols,channels)的4D张量
输出shape
‘channels_first’模式下,为形如(samples,channels, pooled_rows, pooled_cols)的4D张量
‘channels_last’模式下,为形如(samples,pooled_rows, pooled_cols,channels)的4D张量
3-5、GlobalMaxPooling1D层
keras.layers.pooling.GlobalMaxPooling1D()
对于时间信号的全局最大池化
输入shape
形如(samples,steps,features)的3D张量
输出shape
形如(samples, features)的2D张量
3-6、GlobalAveragePooling1D层
keras.layers.pooling.GlobalAveragePooling1D()
为时域信号施加全局平均值池化
输入shape
形如(samples,steps,features)的3D张量
输出shape
形如(samples, features)的2D张量
参考文章:
keras.Layers官网.
tensorflow.keras.layer介绍.
总结
滴滴,您的被爱体验卡已到期,请问需要付费嘛?

![[附源码]Python计算机毕业设计Django物品捎带系统](https://img-blog.csdnimg.cn/be555bd9512949f69022449c0c5939d6.png)