在日常开发中,我们对一些代码的调用或者工具的使用会存在多种选择方式,在不确定他们性能的时候,我们首先想要做的就是去测量它。大多数时候,我们会简单的采用多次计数的方式来测量,来看这个方法的总耗时。
但是,如果熟悉JVM类加载机制的话,应该知道JVM默认的执行模式是JIT编译与解释混合执行。JVM通过热点代码统计分析,识别高频方法的调用、循环体、公共模块等,基于JIT动态编译技术,会将热点代码转换成机器码,直接交给CPU执行。
也就是说,JVM会不断的进行编译优化,这就使得很难确定重复多少次才能得到一个稳定的测试结果?所以,很多有经验的同学会在测试代码前写一段预热的逻辑。
1、JMH介绍
JMH,全称 Java Microbenchmark Harness (微基准测试框架),是专门用于Java代码微基准测试的一套测试工具API,是由 OpenJDK/Oracle 官方发布的工具。何谓 Micro Benchmark 呢?简单地说就是在 method 层面上的 benchmark,精度可以精确到微秒级。
一般用于代码的性能调优,精度甚至可以达到纳秒级别,适用于 java 以及其他基于 JVM 的语言。和 Apache JMeter 不同,JMH 测试的对象可以是任一方法,颗粒度更小,而不仅限于rest api。
使用时,我们只需要通过配置告诉 JMH 测试哪些方法以及如何测试,JMH 就可以为我们自动生成基准测试的代码。
2、JMH 应用场景
-
评估一个方法的不同实现,当你想对比两种不同的数据结构哪种性能更好。
-
评估第三方库的执行性能,当你想比较两种不同的工具包的实现哪个更优(比如Jackson和Gson实现)。
-
度量方法的执行耗时及输入的相关性,当你找到项目热点方法或者代码,想对其进一步进行优化时,也可以使用JMH进行定量分析;
3、JMH 相关概念
-
BeachMark:基准测试,主要用来测试一些方法的性能,可以根据不同的参数以不同的单位进行计算(可以使用平均时间作为单位,也可以使用吞吐量作为单位,可以在BenchmarkMode值进行调整)。
-
MIcro Benchmark:简单地说就是在method层面上的benchmark,精度可以精确到微秒级。
-
OPS:Operation Per Second:每秒操作量,是衡量性能的重要指标,数值的性能越好。类似的有:TPS、QPS。
-
Throughput:吞吐量。
-
Warmup:预热,因为JVM的JIT机制的存储,如果某个函数被调用多次之后,JVM会尝试将其编译称为机器码从而提高执行速度。为了让结果更加接近真实情况就需要进行预热。
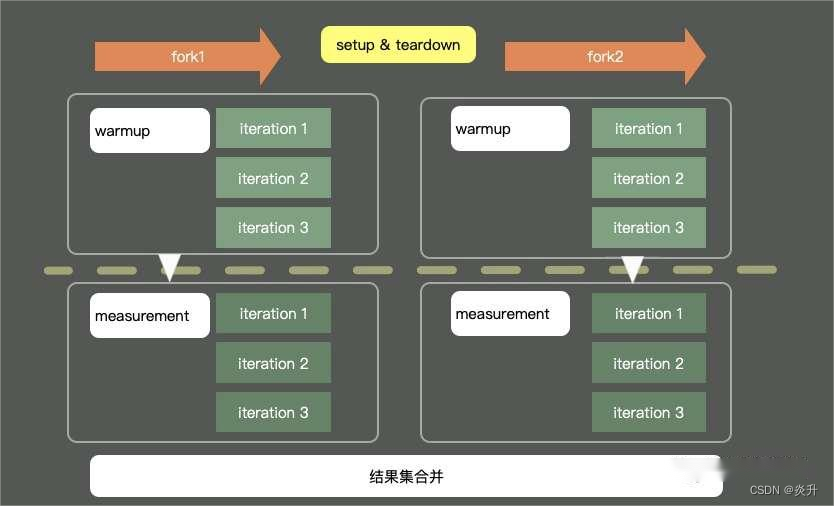
4、JMH 注解介绍
4.1、@BenchmarkMode
微基准测试类型。JMH 提供了以下几种类型进行支持:
| 类型 | 描述 |
|---|---|
| Throughput | 每段时间执行的次数,一般是秒。吞吐量模式。例如”1秒内可以执行多少次调用“,单位是操作数/时间。 |
| AverageTime | 调用的平均时间,例如”每次调用平均耗时x毫秒“,单位是时间/操作数。 |
| SampleTime | 在测试中,随机进行采样执行的时间。最后输出采样结果分布,例如”99%的调用在xx毫秒以内“。 |
| SingleShotTime | 在每次执行中计算耗时。只运行一次。往往把warmup次数设置为0,用于冷启动性能。 |
| All | 所有模式 |
4.2、@Warmup
在基准测试前先进行的预热行为,iterations = 3就是指预热轮数。
例:@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
即预热5次数、每次1秒
4.3、@Measurement
正式度量计算的轮数。
iterations进行测试的轮次time每轮进行的时长timeUnit时长单位
指定迭代次数与运行时间。例:
@Measurement(iterations = 6,time = 1, timeUnit = TimeUnit.SECONDS)
即执行六次,每次1秒
4.4、@Threads
每个进程中的测试线程。Fork面向进程,Threads则是面向线程。
如果配置Threads.MAX,则使用和处理器核数相同的线程数。
4.5、@Fork
进行 fork 的次数。如果 fork 数是3的话,则 JMH 会 fork 出3个进程来进行测试。
4.6、@OutputTimeUnit
基准测试结果的时间类型。一般选择秒、毫秒、微秒。
4.7、@Benchmark
方法级注解,表示该方法是需要进行 benchmark 的对象,用法和 JUnit 的 @Test 类似。
4.8、@Param
属性级注解,@Param 可以用来指定某项参数的多种情况。特别适合用来测试一个函数在不同的参数输入的情况下的性能。
只能修饰字段,用来测试不同的参数对程序性能的影响,可以配合@State使用
4.9、@Setup
方法级注解,这个注解的作用就是我们需要在测试之前进行一些准备工作,比如对一些数据的初始化之类的。和单元测试JUnit类似,用于基准测试前的初始化动作。
4.10、@TearDown
方法级注解,这个注解的作用就是我们需要在测试之后进行一些结束工作,比如关闭线程池,数据库连接等的,主要用于资源的回收等。
4.11、@State
当使用@Setup参数的时候,必须在类上加这个参数,不然会提示无法运行。
就比如我上面的例子中,就必须设置state。
State 用于声明某个类是一个“状态”,然后接受一个 Scope 参数用来表示该状态的共享范围。因为很多 benchmark 会需要一些表示状态的类,JMH 允许你把这些类以依赖注入的方式注入到 benchmark 函数里。Scope 主要分为三种。
- Thread: 该状态为每个线程独享。
- Group: 该状态为同一个组里面所有线程共享。
- Benchmark: 该状态在所有线程间共享。(默认)
5、图形化结果分析
使用JMH测试的结果,可以二次加工,进行图形化展示。结合图表数据,更加直观。通过运行时,指定输出的格式文件,即可获得相应格式的性能测试结果。
比如下面这行代码,就是指定输出JSON格式的数据。
Options opt = new OptionsBuilder()
.resultFormat(ResultFormatType.JSON)
.build();
JMH支持以下5种格式的结果:
-
TEXT 导出文本文件。
-
CSV 导出csv格式文件。
-
SCSV 导出scsv等格式的文件。
-
JSON 导出成json文件。
-
LATEX 导出到latex,一种基于ΤΕΧ的排版系统。
一般来说,我们导出成CSV文件,直接在Excel中操作,生成相应的图形就可以了。
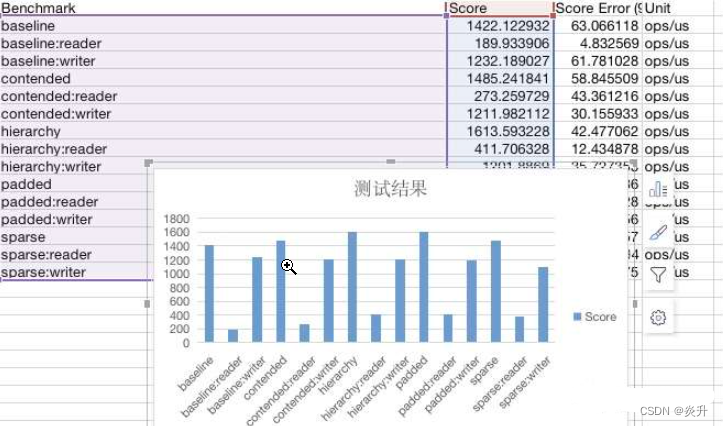
另外介绍几个可以做图的工具:
JMH Visualizer这里有一个开源的项目(https://jmh.morethan.io/) ,通过导出json文件,上传之后,可得到简单的统计结果。个人认为它的展示方式并不是很好。
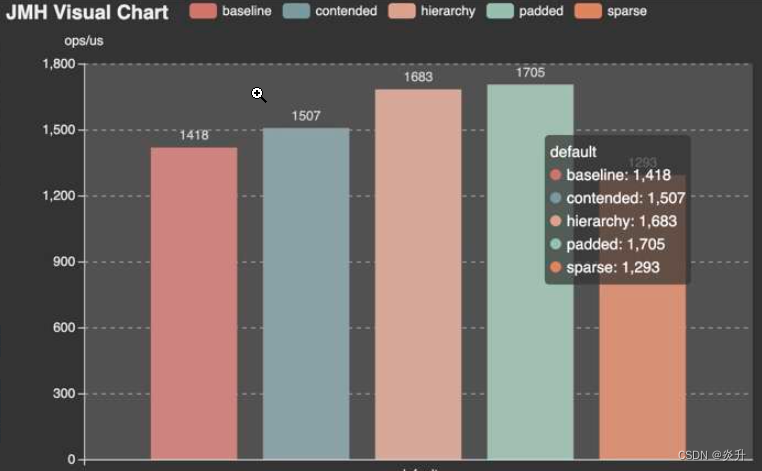
jmh-visual-chart
相比较而言,下面这个工具(http://deepoove.com/jmh-visual-chart) ,就相对直观一些。





![[附源码]Python计算机毕业设计Django校园帮平台管理系统](https://img-blog.csdnimg.cn/2f83f9c90409425daffdf885597f9685.png)

![[附源码]计算机毕业设计面向高校活动聚AppSpringboot程序](https://img-blog.csdnimg.cn/b77492b393d94f8a808c7dce383ad822.png)



![[附源码]计算机毕业设计旅游度假村管理系统Springboot程序](https://img-blog.csdnimg.cn/88c036e5de324b3e841780aee091eaba.png)